



20.2.4 贝叶斯参数学习
最大似然学习引出了某些很简单的过程,但是对于小数据集它有一些严重的不足。例如,在看到一颗樱桃糖后,最大似然假设的结果为这个包是100%的樱桃糖(也就是θ= 1.0)。除非有一个假设先验指出糖果包里要么都是樱桃糖要么都是酸橙糖,否则这就不是一个合理的结论。参数学习的贝叶斯方法对参数的可能值设置一个假设先验,并且随着数据的到达而更新这个分布。
图20.2(a)中的糖果例子有一个参数θ:随机选取的一颗糖是樱桃口味的概率。从贝叶斯的角度看,θ是一个随机变量Θ的(未知)取值;假设先验就是先验分布 P(Θ)。这样,P(Θ= θ)就是包里樱桃糖的比例为θ的先验概率。
如果参数θ可以取0到1之间的任意值,则P(Θ)必须是一个连续分布,它的取值只在0到1之间且不为0,该分布的积分为1。均匀密度P(θ) = U[0, 1]( θ)是一个候选。(参见第十三章。)已知均匀密度是β分布(beta distribution)家族的一个成员。每个β分布由两个超参数 [15]a和b来定义,如下式:
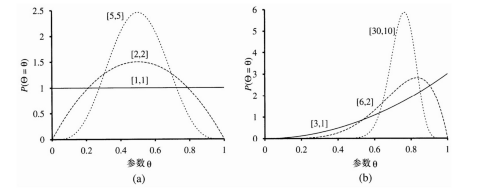
θ的取值范围是[0, 1]。归一化常数α 取决于a和b。(参见习题20.8。)图20.5显示了对于a和b的各种值的分布情况。分布的均值为a / (a+b),所以较大的a值暗示着一种信念,即Θ更接近于1而不是0。较大的a+b的值使得分布的峰值更突出,暗示着关于Θ值的更大把握。因此,β函数族就提供了一系列有用的可能假设先验。
图20.5 当[a,b]取不同值时,β[a,b]分布的例子
在β函数族的灵活性之外,它还具有另一个很好的特性:如果Θ有一个先验β[a, b],那么在观察到一个数据点之后,Θ的后验分布也是一个β分布。β函数族被称为布尔变量分布族的共轭先验 [16]。让我们看一下它是如何起作用的。假设我们观察到一颗樱桃糖,则
P(θ|D1=cherry)= α P(D1=cherry|)P(θ)
= α'θ⋅β[a,b](θ)=α'θ⋅θa−1(1−θ)b−1
= α 'θa(1 −θ)b−1= β[a+1, b]( θ)
因此,在看到一颗樱桃糖后,我们简单地增加参数a的值得到后验概率;同样,在看到一颗酸橙糖后,我们增加参数b的值。这样,我们可以将超参数a和b视为虚拟计数,在某种意义上说先验β[a, b]的行为表现正如我们是从均匀先验β[1, 1]开始的,并且实际看到了a − 1颗樱桃糖以及b − 1颗酸橙糖。
通过考察 a 和 b 按照固定比例递增的一系列β分布,我们可以生动地看到参数Θ的后验分布如何随着数据的到达而变化的。例如,假如实际的糖果包中有 75%为樱桃味的。图 20.5(b)显示了序列β[3, 1],β[6, 2],β[30, 10]。显然,分布收敛到真实值Θ附近的一个狭窄峰值。另外,对于大数据集,贝叶斯学习(至少在这个例子中)的收敛给出与最大似然学习相同的结果。
图20.2(b)中的网络有3个参数: θ,θ1和θ2,其中θ1是红色糖纸包着樱桃糖的概率,θ2是红色糖纸包着酸橙糖的概率。对于贝叶斯假设先验而言,必须覆盖所有的3个参数——也就是说,我们需要指定P(Θ,Θ1,Θ2)。通常,我们假定参数独立性:
P(Θ,Θ1,Θ2) = P(Θ) P(Θ1) P(Θ2)
在这个假定条件下,每个参数都可以有自己的β分布,并可以随着数据的到达分别进行更新。
一旦我们有了未知参数可以表示为诸如Θ这样的随机变量的思想,将它们合并到贝叶斯网络中就是很自然的。为此,我们还需要为描述每个实例的变量制作副本。例如,如果我们已经观察到3颗糖,那么我们就需要Flavor1,Flavor2,Flavor3和Wrapper1,Wrapper2,Wrapper3。参数变量Θ决定了每个Flavori变量的概率:
P(Flavori= cherry|Θ= θ ) = θ
类似地,糖纸的概率取决于Θ1和Θ2。例如,
P(Wrapperi=red|Flavori=cherry, Θ1=θ1)=θ1
现在,整个贝叶斯学习过程可以被形式化表示为一个适当构造的贝叶斯网络中的推理问题,如图20.6所示。对一个新实例的预测只需要简单地在网络中加入新的实例变量。这种学习和预测的形式化方法明确了一个事实:贝叶斯学习不需要额外的“学习理论”。并且,本质上也只有一种学习算法,即贝叶斯网络的推理算法。

图20.6 与一个贝叶斯学习过程相对应的贝叶斯网络。参数变量Θ,Θ1和Θ2的后验分布可以从它们的先验分布以及变量Flavori和Wrapperi的证据中导出
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。









