



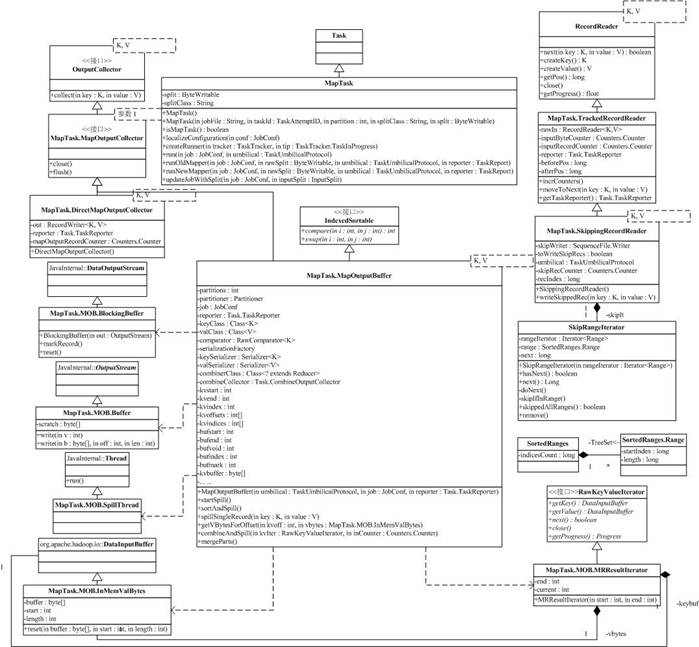
接下来我们来分析Task的两个子类,MapTask和ReduceTask。MapTask的相关类图如下:
 源代码分析(MapTask)%20-%20-%20JavaEye技术网站.mht!http://caibinbupt.javaeye.com/upload/attachment/109037/b5d1cd5d-cfb9-3633-a196-8a5f49c77b87.jpg">
源代码分析(MapTask)%20-%20-%20JavaEye技术网站.mht!http://caibinbupt.javaeye.com/upload/attachment/109037/b5d1cd5d-cfb9-3633-a196-8a5f49c77b87.jpg">
MapTask其实不是很复杂,复杂的是支持MapTask工作的一些辅助类。MapTask的成员变量少,只有split和splitClass。我们知道,Map的输入是split,是原始数据的一个切分,这个切分由org.apache.hadoop.mapred.InputSplit的子类具体描述(前面我们是通过org.apache.hadoop.mapreduce.InputSplit介绍了InputSplit,它们对外的API是一样的)。splitClass是InputSplit子类的类名,通过它,我们可以利用Java的反射机制,创建出InputSplit子类。而split是一个BytesWritable,它是InputSplit子类串行化以后的结果,再通过InputSplit子类的readFields方法,我们可以回复出对应的InputSplit对象。
MapTask最重要的方法是run。run方法相当简单,配置完系统的TaskReporter后,就根据情况执行runJobCleanupTask,runJobSetupTask,runTaskCleanupTask或执行Mapper。由于MapReduce现在有两套API,MapTask需要支持这两套API,使得MapTask执行Mapper分为runNewMapper和runOldMapper,run*Mapper后,MapTask会调用父类的done方法。
接下来我们来分析runOldMapper,最开始部分是构造Mapper处理的InputSplit,更新Task的配置,然后就开始创建Mapper的RecordReader,rawIn是原始输入,然后分正常(使用TrackedRecordReader,后面讨论)和跳过部分记录(使用SkippingRecordReader,后面讨论)两种情况,构造对应的真正输入in。
跳过部分记录是Map的一种出错恢复策略,我们知道,MapReduce处理的数据集合非常大,而有些任务对一部分出错的数据不进行处理,对结果的影响很小(如大数据集合的一些统计量),那么,一小部分的数据出错导致已处理的大量结果无效,是得不偿失的,跳过这部分记录,成了Mapper的一种选择。
Mapper的输出,是通过MapOutputCollector进行的,也分两种情况,如果没有Reducer,那么,用DirectMapOutputCollector(后面讨论),否则,用MapOutputBuffer(后面讨论)。
构造完Mapper的输入输出,通过构造配置文件中配置的MapRunnable,就可以执行Mapper了。目前系统有两个MapRunnable:MapRunner和MultithreadedMapRunner,如下图。
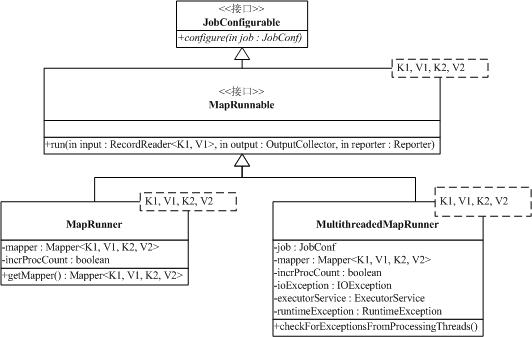
原有API在这块的处理上和新API有很大的不一样。接口MapRunnable是原有API中Mapper的执行器,run方法就是用于执行用户的Mapper。MapRunner是单线程执行器,相当简单,首先,当MapTask调用:
MapRunnable<INKEY,INVALUE,OUTKEY,OUTVALUE>runner =
ReflectionUtils.newInstance(job.getMapRunnerClass(),job);
MapRunner的configure会在newInstance的最后被调用,configure执行的过程中,对应的Mapper会通过反射机制构造出来。
MapRunner的run方法,会先创建对应的key,value对象,然后,对InputSplit的每一对<key,value>,调用Mapper的map方法,循环结束后,Mapper对应的清理方法会被调用。我们需要注意,key,value对象在run方法中是被重复使用的,就是说,每次传入Mapper的map方法的key,value都是同一个对象,只不过是里面的内容变了,对象并没有变。如果你需要保留key,value的内容,需要实现clone机制,克隆出对象的一个新备份。
相对于新API的多线程执行器,老API的MultithreadedMapRunner就比较复杂了,总体来说,就是通过阻塞队列配合Java的多线程执行器,将<key,value>分发到多个线程中去处理。需要注意的是,在这个过程中,这些线程共享一个Mapper实例,如果Mapper有共享的资源,需要有一定的保护机制。
runNewMapper用于执行新版本的Mapper,比runOldMapper稍微复杂,我们就不再讨论了。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










