



(一)基本原理
1.最优分类面
SVM方法是从线性可分情况下提出的。考虑如图5-8所示的二维两类线性可分情况,图中实心点和空心点分别表示两类训练样本,H为把两类数据没有错误地分开的最优分类线, H1、H2分别为过两类样本中离分类超平面最近的点且平行于分类线,H1和H2之间的距离叫做间距(margin)。如果该分类线将两类数据没有错误的分开且最近的点与分类线间的距离最大,则这样的分类线称为最优分类线(在多维空间成为最优超平面)。我们可以看到最优分类超平面所要求的第一个条件,即将两类数据无错误地分开,就是保证经验风险最小,第二个条件使分类间距最大就是使推广能力的界的置信区间最小,从而使真实风险最小。
图5-7 计算某工区孔隙度在0°、45°、90°、135°方向上的变差函数
图5-8 二类线性可分最优超平面示意图
设线性可分的样本集(xi,yi),i=1,2,…, l,x∈Rn,y∈{+1,-1},分类线方程为ω·x+b=0,我们可以对它进行归一化,且满足以下条件:
yi[(ω·xi) +b]≥1,i=1,2,…,l (5-1)
使分类间隔最大实际上就是对推广能力的控制,这是SVM的核心思想之一。在n维空间中,设样本分布在一个半径为R的超球范围内,则满足条件‖ω‖2≤A的正则超平面构成的指示函数集f(x,ω,b) =sgn{(ω·x) +b}[sgn(*·* ) 为符号函数]的VC维满足下面的界h≤min([R2A2],n) +1。因此使‖ω‖2最小就是使VC维的上界最小,从而实现SRM准则中对函数复杂性的选择。
实际上求最优分类超平面的问题归结为如下的约束优化问题:
这个优化问题的解由如下的Lagrange函数的鞍点给出:
其中,αi>0为Lagrange系数。我们的问题是对ω和b求Lagrange函数的极小值。我们可以把原问题转化为如下较简单的对偶问题:
即最优分类超平面的权向量是训练样本向量的线性组合。可以看出这是一个不等式约束下二次函数极值问题,存在唯一的最优解。且根据条件,这个优化问题的解满足:
αi[yi(ωTxi+b) -1]=0,i=1,…,l (5-5)
yi(ωTxi+b) -1=0 (5-6)
解得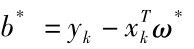 。也称b*为分类阈值,它由一个支持向量得到的,也可通过两类中任意一对支持向量取中值。通常为了稳健性,可以根据所有的支持向量的总和取平均阈值。
。也称b*为分类阈值,它由一个支持向量得到的,也可通过两类中任意一对支持向量取中值。通常为了稳健性,可以根据所有的支持向量的总和取平均阈值。
2.广义最优分类超平面
然而很多情况下,数据并不是线性可分的,这种情况就是某些训练样本不能满足式(5-1)的要求,因而一般可以在约束条件中加一个松弛因子ξi≥0来实现,这样式(5-1)就变为:
yi[(ω·xi) +b]-1+ξi≥0 (5-7)
对于足够小的σ>0,只要使:
最小就可以使错分样本数最小。对应线性可分情形下使分类间距最大,在线性不可分情形下引入约束:
‖ω‖2≤ck (5-9)
在约束条件式(5-7)和式(5-9)下使式(5-8)求极小,就得到了线性不可分情形下的最优分类面,这种分类面称为广义最优分类超平面。为了方便,通常取σ=1。
为了使计算进一步简化,将求最优分类超平面的问题转化为如下的凸二次规划问题:
C为某个指定的常数,它起控制错分样本惩罚程度的作用,实现在错分样本的比例与算法复杂度之间的折中。同样,式(5-10)转化为其对偶得到的形式和式(5-4)几乎完全相同,只是αi的约束条件变为:0≤αi≤C,i=1,2,…,l。
3.核函数
支撑向量机在线性可分或几乎线性可分时,直接在原始空间中建立超平面作为分类面。然而实际应用中的大多数问题都是复杂的、非线性的,这时就必须寻求复杂的超曲面作为分界面。为了构造具有好的推广能力的分界面,支撑向量机通过在另一个高维空间中运用处理线性问题的方法建立一个分类超平面,从而隐含在原始空间建立一个超曲面。更重要的是,只需知道其内积运算,这样又避免了高维空间的计算复杂度。
考虑在Hilbert空间中内积的一般表达:
(zi,z) =K(x,xi)
其中,z是输入空间中的向量x在特征空间中的象,K(* ,* )称为核函数。根据Hilbert-Schmidt理论,K(* ,* )可以是满足下面一般条件的任意对称核函数。关于这一点有如下的解释。
定理 Mercer条件
要保证L2下的对称函数K(u,v)能以正的系数ak<0展成
K(u,v)即描述了在某个特征空间中的一个内积,其充分必要条件是,对使得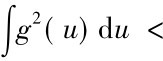 ∞的所有g≠0,条件
∞的所有g≠0,条件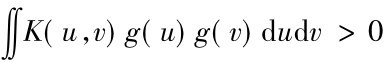 成立。
成立。
可用于构造支撑向量机的Hilbert空间中内积的结构好的性质是:对于满足Mercer条件的任何核函数K(u,v),存在一个特征空间(z1,z2,…,zk,…),在这个特征空间中这个核函数生成内积式(5-11)。
所以对于任何满足Mercer条件的函数都可以在某个特征空间中构造最优分类超平面。因而对于支撑向量机算法而言,我们只需要知道其核函数就可以了,这为我们处理高维空间问题提供了便利。核化的思想现在已经运用到了许多的其他问题上,取得了好的效果。
由于核函数的引入,使我们的最优分类超平面的意义有了新的简化形式,即用核函数K(xi,xj)代替最优分类面中的内积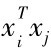 ,就相当于把输入空间变换到了某一新的特征空间,即在输入空间中非线性决策函数:
,就相当于把输入空间变换到了某一新的特征空间,即在输入空间中非线性决策函数:
等价与特征空间中线性决策函数:
此时式(5-4)的优化函数变为:
构造式(5-12)类型的决策函数的学习机器叫做支撑向量机(SVM),需要注意的是在支撑向量机中,构造的复杂度取决于支持向量的数目,而不是特征空间的维数,支撑向量机的示意图如图5-9所示。
图5-9 支撑向量机示意图
(二)支撑向量机预测储层参数的一般方法
支撑向量机的学习模型是一种监督学习过程,由测井数据预测储层参数最常用的过程描述如下。
(1)沿测井资料的目的层计算出反映其特性的若干测井属性(振幅、频率、相位等)。
(2)通过该层的井中测试储层参数结果(孔隙度、渗透率)建立井中测井属性与井中测试结果的关系。
(3)利用这一关系推断出未知井所有井中储层参数的结果。
我们首先获取学习样本的信息,对于由测井属性预测孔隙度和渗透率的问题,对得到的测井数据,首先选择一口或多口井,依据深度开一个窗口,在此窗口内每个一定的深度有一组测井属性数据,我们以此点深度和测井数据组成训练样本点xi,以此点对应的孔隙度或渗透率为yi,如果以多口井为训练样本,我们在训练样本点xi加上此井的水平坐标。
支撑向量机通过对训练样本的学习获得一定的预测能力,训练后将预测的测井属性数据作为输入、输出结果便是这一深度的孔隙度或渗透率。支撑向量机处理流程如图5-10。
Kalkomey提出了一个假相关概率模型,所谓假相关是指在已知样本处两种实际上并没有联系的属性之间的绝对相关值很大,通过从理论上对出现假相关的因素进行分析,得出结论:测井(地震)属性与储层参数之间出现假相关的概率随着用于学习的样本数目(既有地震属性或测井属性,又有储层参数的控制点数)的减少而增大;随着参与预测的地震属性或测井属性数目的增加而增大,且地震属性之间并不完全相互独立时(实际情况基本如此),概率更大;随着学习样本处地震属性与储层参数之间的绝对相关值的减小而增大。如果我们的随机抽样满足自由度为n-2的t-分布,则用单一测井(地震)属性进行预测时出现假相关的概率为:
式中,n是用于学习的样本点数;R是学习样本处测井(地震)属性与储层参数之间的绝对相关值。
图5-10 支撑向量机预测流程
当用k个相互独立的测井(地震)属性进行预测时,出现假相关的概率为
从式(5-16)中可见,参与预测的地震属性数目从k-1个增加到k个时的惩罚函数为
Psc(1-Psc)k (5-17)
根据上述公式,我们可以定量计算出表征选择一个与储层参数并不相关的地震属性作储层预测时风险大小的参数。
在实际工作中,井位数目是客观存在的,我们无法改变;但在选用测井(地震)属性参数方面,则有必要做一些细致的分析工作,对测井(地震)属性参数进行优选,选取与储层物性相关性较大的参数,尽量减少测井属性参数,以减少伪相关性。笔者认为,要对储层进行精细描述,必须认真做好以下几点。
(1)对层位作精细解释。针对不同的地质任务,解释人员在层位追踪方面可能会有不同的考虑,因此他们提供的解释方案可能不满足测井(地震)属性提取的要求。原则上讲,解释的层位最好不要串相位;否则,尽管对时窗内的统计信息尚可容忍(开设的时窗必须大于所串的相位),但对沿层提取的信息将可能产生一些假象甚至误导。
(2)对提取的测井(地震)属性进行筛选。剔除没有明显特征变化的属性,同时也要考虑这些信息是否真正与所要研究的目标具有内在联系。此外,为了提高可信度,必须对测井(地震)属性进行相关分析,将相关值较大的地震属性进行合并,以保证用于预测的地震属性具有相对独立性。它会影响预测算法的稳定性。
(3)了解工区范围内是否具有明显的相变特征,若有,则应考虑分块预测。
(三)测井属性的优选与标准化
通过前面的分析可知,要提高预测的准确率,减少伪相关性,必须对测井(地震)属性进行优选。
同时,由于并非所有测井(地震)属性都对特定的储层目标具有敏感性,所以也应该进行测井(地震)属性的优选工作。以往在做这项工作时,通常是选取一些曲线形态起伏较大的属性。实际上,这样做并不总是有效,因为不同的属性代表不同的含义,而这些含义可能与需要进行判别的目标是有区别的,因此可能导致误选。比如,在对井区的资料进行油气分布预测时发现,对某些属性而言,在不同油气井之间的差异要大于某些油气井与干井之间的差异,若将这些属性用于油气判别,其结果自然是不会太理想的。常用的优选方法如下。
(1)基于相关的属性归类。首先对提取的所有地震属性进行相关分析,将相关值较大的属性进行合并,合并方法可以采用综合参数法。这样得到了一些反映这些(彼此相关的)属性共同特征的参数,这些参数两两之间近似于相互独立,保证了模式算法的稳定性。
(2)基于样本的属性优选。根据已知储层信息进行不同类别的学习样本粗选,并统计分析选取样本处各类属性的均值和方差。显然,“均值”代表了某信息的集中位置,而“方差”则表示其离散程度。如果某些属性在不同类别的样本上的均值差异较大并且对同类样本的方差较小,就说明这些属性对不同类别的学习样本在一维线性空间可区分,也必然在支撑向量机的超平面上更可分,因而它就成为首选的属性参数,即是减小了式(5-16)中的k。
(3)基于统计的典型样本优选。在一般情况下,所选取样本的典型性是不够的,往往还会导致判别结果过于乐观。通过最大方差变化率的分析,可以找出不够典型的样本。具体做法是对逐次去除某个样本前后的方差的变化率进行统计分析,如果某个样本对大部分属性参数都引起了较大的方差变化率,那么该样本一定是个“捣乱样本”,应该将其剔除。
在样本基本典型化以后,再采用非线性模式识别方法进行储层预测。这一步虽然减少了用于学习的样本数n,但由于提高了测井(地震)属性与储层参数的相关性,相当于增大了式(5-15)中的R,而R比n对假相关概率的影响还要大,所以从总体上还是减小了出现假相关的概率。但如果样本太少时,由于其方差变化率不具备统计性,这一步骤也就没有意义了。
每种测井曲线采用不同的单位,数据的量纲和量级都不同,因此,当这些数据作为样本的分量直接输入后,对支撑向量机的学习训练的影响程度是不同的。例如,支撑向量机可能突出量级特别大的数据指标的作用,而甚至排斥某些数量及较小的数据指标的作用。为了均衡不同测井取向对数据的影响,通常在数据进行学习训练前需对每种数据分别标准化。
设一分类问题有n个待分类样本,有m个特性指标,则数据矩阵如下:
并规定 ≥0,我们用极差规格化
≥0,我们用极差规格化
其中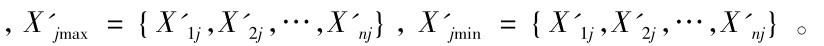
对于标准化后的数据,当作为几种不同的测井属性参数用于学习和预测样本时,它们可能与预测参数的密切程度不同,因此可根据它们与所要预测参数的关系,对它们分别加权。但这种加权是人为的影响,对将来的预测结果有一定的经验因素。
标准化后数据分布于[0,1],对于支撑向量机的核函数参数的选择,我们给出了核函数参数的取值范围,即0.3≤σ≤1。
(四)测井曲线预测流动单元
在对取芯井流动单元划分后,必须过渡到非取芯井的流动单元识别。而非取芯井用来进行流动单元识别的信息中,测井数据比较有效。在对红河55井区的45口井中,因全部解释了孔渗数据,可以根据这些参数计算FZI值。为了估计根据测井资料计算的FZI值与岩芯资料计算的FZI值的符合度,利用支撑向量机对8口取芯井的测井计算的FZI值和岩芯计算的FZI值进行了对比(图5-11)。
图5-11 HH53井岩芯流动单元与测井流动单元划分对比图
在单井上,流动单元判别结果与岩芯分析孔渗数据及岩性剖面具有较好的一致性,如HH53井和HH69井等,从这些图件可知,孔隙度和渗透率的拟合度很高,而岩芯流动单元与测井解释所得的流动单元大部分是相同的,测井解释的流动单元在相同的岩性里面,测井数据变化平缓的时候,流动单元类型是一致的。但是,岩芯的流动单元可能在某一深度点的流动单元发生了变化。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











