



4.1.1 频度/逆文档频度法
在该方法中,特征频度(Term Frequency,TF)指训练集中某特征tk在文本集中出现的次数。它认为特征在文本集中出现的次数越多,对文本分类的贡献越大。一般特征集中大部分是低频特征,据此,如果设定TF的阈值来过滤掉其中一部分特别低频特征,以便取得较大的降维度[3],尤其是当高频特征在文本集分布不均匀时,对分类作用较大,反之作用将减少。
文档频度(Document Frequency,DF)指训练集中出现特征tk的文本数。它认为特征在越多的类内文本中出现,分类作用越大。用DF方法对大量的低频特征进行降维也很有效,但是对于在多类间出现的高频特征其作用恰好相反。曾有相关研究表明,采用DF进行特征选择也可以得到很好的降维效果[4]。
综上所述,频度法计算比较简单,非常适合海量文本的特征表示。实际使用中,一般可以结合两者各自的优点综合使用。典型的是TF-IDF权值计算方法[5—6],其原理见公式4-2。
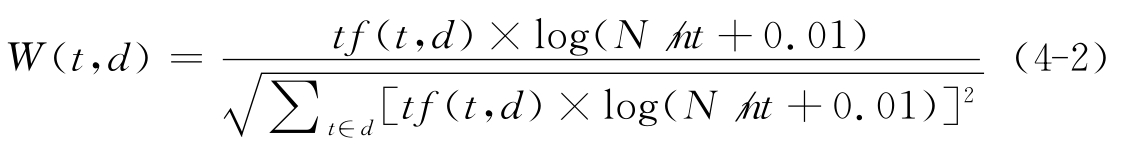
其中,W(t,d)为词t在文本d中的权重,而t f(t,d)为词t在文本d中的词频,N为训练文本的总数,nt为训练文本集中出现词t的文本数,分母为归一化因子。
经分析可以发现,上述TF-IDF公式并没有考虑文本的结构特性对特征项权重的影响,事实上,同一个关键词出现在文档中的不同位置,它所能表达文档内容的能力是有差别的。李凡研究了结构层次权重系数的概念[7],对一个文本文档,可以按照其文本结构进行分层,即可以将文本依次分为标题、摘要、正文、参考文献(或者链接)等部分,并按照不同的结构域在文档的重要程度,对不同域的特征项给予不同程度的加权。在其实验系统中,验证的结果比单纯使用该方法其分类效果有所提高。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











