



第三节 模糊网络计划的遗传算法
在网络进度计划及其工期优化的计算方法上,近几年发展起来的遗传算法,是一种模拟生物进化的自适应随机搜索方法,由于它对问题本身的限制较少,对问题目标函数和约束条件既不要求可微也不要求连续,仅要求该问题是可计算的;同时,它的搜索始终遍及整个解空间,能找到近乎全局最优解,因而在网络计划优化方面具有广泛的应用价值。
一、遗传算法的基本原理
遗传算法是由美国Michigan大学的J.Holland等人创立的,它采用解的种群作为工作单元,使用模仿生物进化的适者生存原则指导搜索并改进目标。每一个解的质量,通过依赖于问题目标函数的适应值函数来进行评估,搜索过程通过代数变更(进化)来进行,每代中的个体遗传到下一代的可能正比于它的适应值。它使用三个基算子:复制、交叉和变异。复制是指种群中的个体直接复制到下一代中,交叉是从种群中选择两个个体进行交配,组合两个个体的特性形成一个(或几个)新个体,复制和交叉将好的特性进行遗传,而变异则是模仿突变理论改变种群少数个体中的个别基因,以增加种群的多样性,获得更宽的搜索范围。
(一)遗传算法的两个决策步骤
1.将求解问题模型化为符合遗传算法的框架,可行解空间的定义,适应值函数的表现形式,解的字符串表达式方式。
2.遗传算法参数的设计,种群规模,复制、交叉、变异的概率选择,进化最大代数,终止准则设定等。
(二)遗传算法的主要过程
求函数F(x)极小值的遗传算法的主要过程如下:
1.编码表示
给出解空间S上点x的编码形式,每个X表示一个n维向量,其中每个分量都可以用一个二进制串表示,从而一个点x的编码y由n个二进制串构成。
某工程项目在T工期上的工序持续时间编码为:
![]()
经过上述步骤每个变量形成一个基因链,将各个变量的基因链组合在一起,形成码链,对应于遗传学中的染色体。
将二进制基因链恢复为对应的实数,称为译码。
2.初始化
选择一个整数N作为群体的规模参数,然后从S上随机地选取N个点x(i,0),i=1,2,…,N,这些点组成初始群体:
P(0)={x(1,0),…,x(N,0)}
一般说来,这些初始解的素质都很差,遗传算法的任务是从第一代群体出发,模拟进化过程,择优汰劣,最后得出最佳的群体和个体,以满足优化要求。
3.适应值
计算群体P(k)中每个个体x(i,k)的适应值F(x(i,k)),其中k表示代数,初始代k=0,适应函数F(x)可以取为:
![]()
式中:Cmax为输入参数。
将个体的变量取值代入适应函数计算出其适应值,适应值越大,表示该个体有较高的适应性。适应值用以评价个体的优劣,为群体进化提供依据。
4.选择策略
对每个个体x(i,k),计算其生存概率Pki:
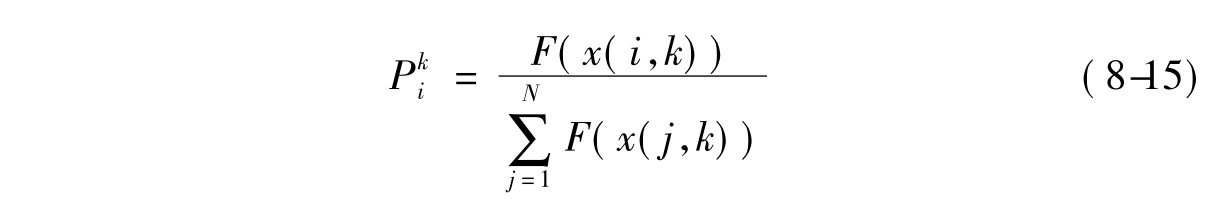
然后设计一个随机选择策略,可以采用转轮选择或排序选择等方法,使得每个个体x(i,k)被选择进行繁殖的概率为Pki。
5.遗传算子
先利用选择策略从群体P(k)中选择进行繁殖的个体组成父代P(k+1),然后对P(k+1)进行重组,即作用杂交和变异算子来形成下一代新的个体。
杂交是以概率Pc交换两个父代个体间对应的分量。杂交算子有多种,如一点、两点和多点杂交算子。
(1)一点杂交
对于被选中用于繁殖的每一对个体,按照杂交概率随机选取一个交叉位置,交换这对个体在该位置以后的基因码链,形成两个新的染色体。如下列左侧两个母体,随机选择在第四位以后交叉(用|表示),则得到右侧的两个新染色体:
1000|101 1000|000
1110|000 1110|101
(2)两点杂交
随机地选取两个交叉位置,交换两个母体处于交叉位置之间的基因码链,形成新的染色体。例如:
10|0010|1 10|1000|1
11|1000|0 11|0010|0
(3)多点杂交
随机地选取多个交叉位置,将两个母体的基因码链分为若干段,将有关段的基因码链进行交换,形成新的染色体。例如三点杂交为:
10|00|10|1 10|10|10|0
11|10|00|0 11|00|00|1
杂交概率一般取0.6~0.9。
由y1=(a1,a2,…,aN)和y2=(b1,b2,…,bN)杂交生成的个体位于由y1和y2给出的平行多面体的顶点上。
杂交完成后,再作用变异算子,它是以概率Pm改变串上的每一位。变异操作用以模拟生物在自然环境中由于偶然原因而引起基因突变,它将染色体中某位基因按变异概率进行取反运算,即由1变为0或者由0变为1,如将下列染色体左侧第三位基因进行变异得到新的染色体:
1000101 1010101
同自然进化一样,发生变异的概率是很小的,一般取为: 0.001~0.1。
6.停止准则
遗传算法循环执行计算适应值、选择复制和应用杂交和变异算子这几个步骤,直到满足某个停止准则,例如算法已找到了一个能接受的解,或已迭代了预置代数。
二、应用遗传算法的步骤
在准备应用遗传算法求解问题时,要完成以下四个步骤:
1.确定表示方案
2.确定适应值度量
3.确定控制算法的参数和变量
4.确定指定结果的方法和停止运行的准则
在常规的遗传算法中,表示方案是把问题的搜索空间中每个可能的点表示为确定长度的特征串。表示方案的确定需要选择串长L和字母表示规模K。二进制串是遗传算法中常用的表示方法。在染色体串和问题的搜索空间中的点之间选择映射有时容易实现,有时又非常困难。选择一个便于遗传算法求解问题的表示方案经常需要对问题有深入的了解。
适应值度量为群体中每个可能的确定长度的特征串指定一个适应值,它经常是问题本身所具有的。适应值度量必须有能力计算搜索空间中每个确定长度的特征串的适应值。
控制遗传算法的主要参数有群体规模N和算法执行的最大代数目M,次要参数有复制概率Pr、杂交概率Pc和变异概率Pm等参数。
至于指定结果和停止执行算法,对于不同的问题有相应的方法。
一旦这些准备工作完成,就可以执行遗传算法。遗传算法的主要计算步骤如下:
1.随机产生一个由确定长度的特征串组成的初始群体。
2.对串群体迭代地执行下面的步(i)和步(ii),直到满足停止准则。
(i)计算群体中每个个体的适应值;
(ii)应用复制、杂交和变异算子产生下一代群体。
3.把在任一代中出现的最好的个体串指定为遗传算法的执行结果。这个结果可以表示问题的一个解(或近似解)。
根据时间—费用模糊网络计划遗传算法模型,以模糊截集α作为风险标准的大小,经过计算(见图8-6计算程序流程图)可得时间—费用优化的曲线。
图8-6 计算程序流程图
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










