



近五年国内外元数据研究进展(1)
吴 丹
(武汉大学信息管理学院)
【摘 要】文章对2005年以来国内外关于元数据研究的成果进行了系统的梳理与总结,探讨了国内外元数据研究的主要特点与有代表性的研究成果,对国内外元数据研究领域的十大热点问题进行了归纳分析,指出元数据研究未来发展的方向与趋势,以期利用元数据更好地发现、获取、检索、利用网络信息。
【关键词】元数据 研究进展 发展趋势
Metadata Research in the Past Five Years: An Overview
Wu Dan
(School of Information Management,Wuhan University)
【Abstract】This paper provides an overview of metadata research in and outside of China in the past five years.Through systematically examining and reviewingmetadata researches,especially paying at-tention to the projects,initiatives and achievements since 2005,tenmajor active topics in metadata research have been identified and summarized.This paper endswith the discussion of future trends ofmetadata research,and points out the importance ofmetadata in improving people's ability to discover,access,retrieve and utilize online information.
【Keywords】metadata research overview development trend
随着互联网迅速延伸和扩展,网络信息资源的数量、种类和范围都明显地激增。数字化、多媒体和网络化的信息资源成为人们获得和利用信息的主流。据国外媒体报道,目前Google索引的网页数量已经突破1万亿个,比银河系的星体还多出一倍。根据中国互联网络信息中心于2010年1月发布的《第二十五次中国互联网络发展状况统计报告》数据显示,截至2009年12月,中国的网站数已达到232万个,网页数量达到336亿个(2)。面对海量的信息资源,如何对其进行组织、管理与利用是所有的信息资源的利用者和管理者都十分关心的问题。信息组织工具的发展经历了从构建纸质图书的传统卡片目录,到设计电子资源的机读目录,再到当前的组织网络信息资源的元数据。在新环境下,元数据及其相关标准日益引人注目,其对网络化信息的交流、数字图书馆的应用以及搜索引擎检索性能的提高等都产生着重要的影响。本文对自2005年至今的近五年来国内外元数据研究成果进行系统的梳理与总结,探讨元数据研究的主要特点及其有代表性的研究成果,对元数据研究领域的十大热点问题进行归纳分析,指出元数据研究未来发展的方向与趋势,以期利用元数据更好地发现、获取、检索、利用网络信息。
1 元数据发展回顾
元数据(Metadata)是组织数字化信息的基本工具。该词最早出现于美国航空航天局(National Aeronautics and Space Administration,NASA)的《交换格式目录》中。元数据最常看到的定义是“元数据是关于数据的数据”(Metadata is data about data)。国际图联(International Federation of Library Associations&Institutions,IFLA)将元数据定义为“描述数据的数据,元数据为能协助对网络电子资源的辨识、描述与指示其位置的任何数据”。(3)美国图书馆协会(The American Library Association,ALA)对元数据的定义为:“元数据是结构、编码数据,描述信息款项的特征,辅助描述数据的标识、发现、评估和管理。”(4)
元数据并不是一个全新的概念。图书馆的书目记录就是一种元数据。书目记录中通常都包含诸如题名、作者、出版者、主题和载体描述之类的标识信息,这是印刷环境中最明显的元数据应用。经过了100多年的发展,图书馆的卡片目录发展为机读目录(Machine-Readable Catalogue,MARC),这是最早意义上的元数据格式。MARC元数据是用于在计算机条件下描述、存储、交换、控制和检索著录数据的标准。随着计算机技术的发展,MARC格式由原来的图书资料格式陆续发展出期刊、视听资料、电子档案等多种格式,以适应不同类型信息的处理。MARC的修订与应用,使得书目著录能够为计算机所识别,图书馆可以通过MARC这一标准实现资源共享。但是,MARC元数据需要在专门的软件系统中使用,其修订程序复杂、缓慢,且编制一条机读记录需要经过严格的专业训练。故其只适用于图书馆,只适用于完整的、静止的信息内容处理,不易于处理动态多媒体信息,不适应互联网环境。随着新的信息资源的产生,对其进行描述的元数据必将出现新的单元。
自20世纪90年代中期以来,随着互联网的不断发展,网络上信息资源正呈现不断增多的趋势。但在海量信息环境中有效查找和检索变得越来越困难。这种情况下,涌现了各种各样的元数据,包括以都柏林核心元数据(Dublin Core,DC)为代表的现代元数据的方案。现代元数据在著录与管理方法上与传统的元数据体系不同,它们所描述的对象涉及网页、多媒体等各类资源,且描述重点更注重描述对象的内容、内部结构或标准,以及应用与管理方面,而不是像传统元数据那样有很多外形特征的描述。此外,SGML,HTML,XML等标记语言的发展为现代元数据的产生创造了条件。现代元数据很多是直接使用资源描述框架(Resource Description Framework,RDF)作为应用元数据的标准,使用XML语言来实现编码,这样既保证了元数据的结构化,也具有良好的可读性。同时,由于标记语言有文档结构与内容分离的特点,这大大提高了元数据的可重用性与兼容性。
现代元数据的发展虽然时间不长,但成果已相当丰硕。在国外,许多研究元数据的机构都推出了各种功能的元数据规范。在众多元数据项目中,都柏林核心元数据DC是应用最广、影响最大的一个国际性项目。DC元数据全称为都柏林核心元素集(Dublin Core E lements Set),它是一个简单的、有效地描述网络资源,并被广大用户所接受的元数据集。DC包含15个核心元素和44个修饰词。15个核心元素可以分为三大部分:内容描述部分(题名、主题、说明、来源、语种、关联和覆盖范围);知识产权部分(创建者、出版者、其他责任者和权限);外形描述部分(日期、类型、形式和标识符)。44个修饰词又可分为元素修饰词和编码体系修饰词两种。由于DC元数据具有简练、易于理解、可扩展、能与其他元数据形式进行连接等特性,能较好解决网络资源的发现、控制和管理问题,使之成为广泛应用的网络资源描述元数据集。1998年,因特网工程任务组(Internet Engineering Task Force,IETF)正式接受DC这一网络资源的编目方式,将其作为一个正式标准(RFC2413)予以发布。
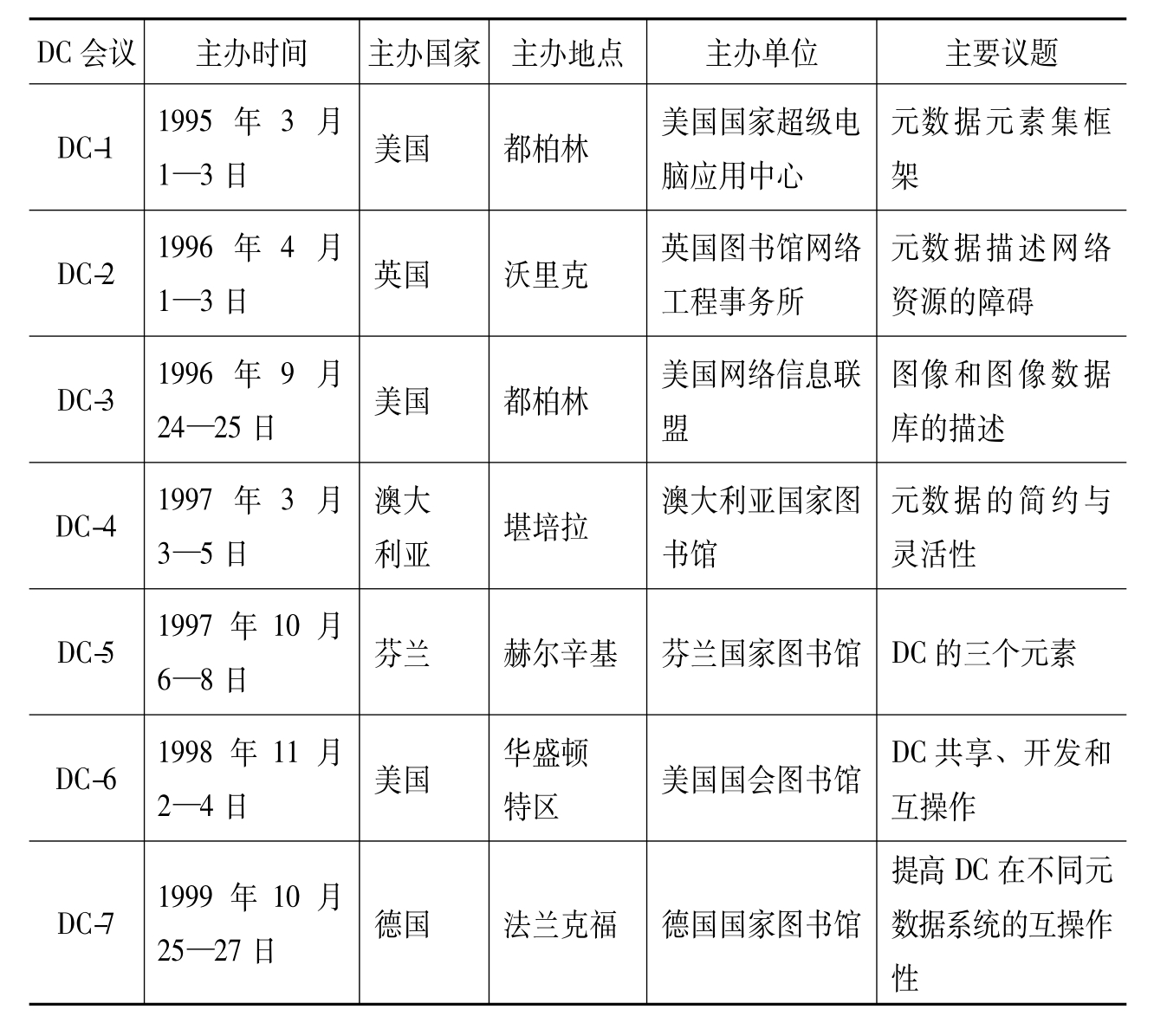
对DC元数据的最初研究可以追溯到1994年10月在芝加哥召开的WWW会议。此后自1995年起,平均每年召开1~2次DC正式研讨会,至今已举办过18次,各次会议均有不同的研究重点,由浅入深、由泛到专地对DC理论及应用问题进行探讨。这些会议对DC的发展起到了至关重要的作用,从各次研讨会的主要议题(详见表1(5))也能看出整个现代元数据的发展历程与趋势。
表1 DC历次会议及其主要议题
续表
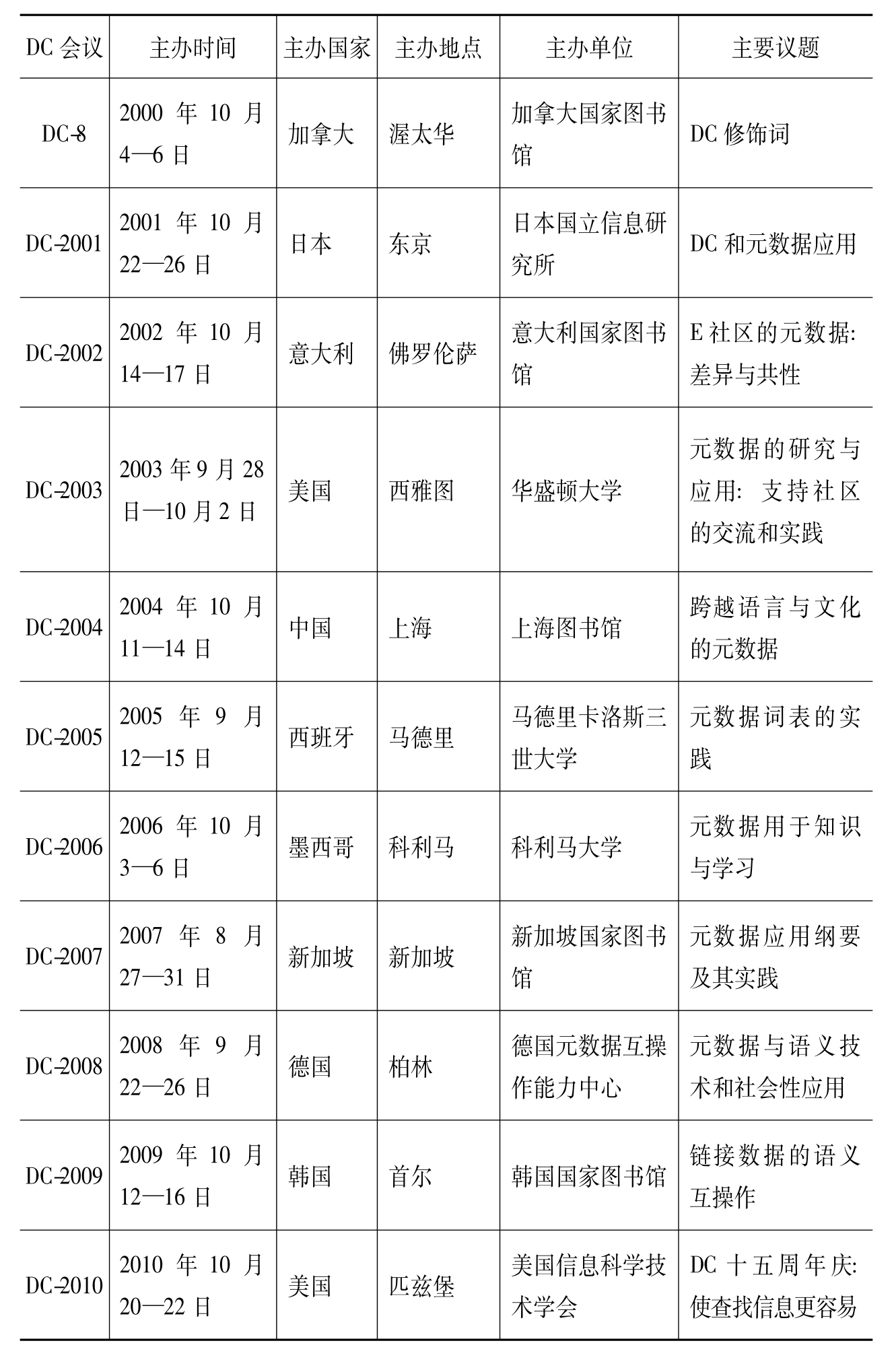
从表1可以看出,国际组织现已对元数据研究达成共识,DC年会已然成为元数据领域的顶级会议,且得到各个国家的支持。从会议的议题变化可以看出,早前的DC会议主要侧重于DC元数据本身的完善,后来发展为研究DC的应用,再后来扩展到整个现代元数据研究,近几年随着语义网和社会网络的兴起,该会议的议题逐渐转向语义网和社会网络中的元数据研究。
元数据应用最多的领域包括数字信息、数字图书馆、数字档案、数字博物馆、教育信息系统、地理信息系统、空间信息系统、多媒体信息系统等。同时,元数据在电子政务、电子商务、远程教育、电子出版和数字科研等领域也得到广泛应用。因此,一些研究数字图书馆、地球空间信息等的会议也有专门的关于元数据研究的主题。如美国数字图书馆年会(JointConference on Digital Libraries,JCDL)、欧洲数字图书馆年会(European Conference on Digital Libraries,ECDL)、亚洲数字图书馆年会(International Conference on Asian Digital Libraries,ICADL)等国际知名数字图书馆会议都把元数据当作其重要的研究内容之一。
2 近五年来元数据研究文献综述
为了全面了解国内外学者对元数据研究的现状,笔者分别对有关该主题的图书、期刊论文、学位论文、研究项目与有关网站等进行了调研,获取了从2005年至今国内外元数据研究的主要成果,并对其进行分析。
2.1 国内外元数据图书信息
对于外文图书,笔者分别利用Google Books(6)、亚马逊网上书店(7)、美国国会图书馆(8)的高级检索功能,对2005年至今主题中含有“metadata”的图书进行了检索。检索结果如下:Google Books上的图书有70种,亚马逊网上书店的图书有132种,美国国会图书馆收录的图书有91种。
对于中文图书,笔者分别利用指针图书搜索引擎(9)、当当网上书店(10)、中国国家图书馆(11)的高级检索功能,对2005年至今主题中含有“元数据”的图书进行了检索。检索结果如下:指针图书搜索引擎找到5本,当当网上书店的图书有18本,中国国家图书馆收录的图书只有2本。
2.1.1 外文元数据图书概况
按照从亚马逊网上书店检索的结果,132本图书中,其类型包括:印刷型图书92本、HTML网页型图书30本、PDF电子图书6本、Kindle电子图书4本。从数量上来看,近五年元数据的研究成果还是较丰富的。笔者对较权威的美国国会图书馆收录的元数据图书进行了分析,其91本图书按照出版时间分布如表2所示:
表2 2005—2010年美国国会图书馆收录的有关元数据的图书(截至2010年5月18日)

从元数据图书的年代分布来看,从2005年到2008年,国外每年出版的有关元数据的图书基本保持在20本左右,但到2009年有一个明显的下降,这在某种程度上说明元数据研究在2008年以后出现了下滑情形。
从内容上来看,外文元数据著作可以分为如下几类:
(1)综合性的元数据著作。这类图书探讨元数据研究的基本问题,涉及元数据研究的各个方面,可以作为教材来使用。最经典的是Murtha Baca编的《元数据基础》(12),该书在1998年出版了第一版,2000年进行了网络版的修订,2008年出版了第2版。该书全面介绍了元数据的类型、角色、特点,讨论了各种资源的元数据标准,以及元数据的构建方法、工具、协议等。2008年的新版增加了在文化机构中基于标准的版权元数据(rightsmetadata)的内容,以及一章关于元数据创建与维护的实践原则。该书是一本很好的学习元数据的入门书,在美国很多高校被选作教材。另一本较新的书是Marcia Lei Zeng和Jian Qin于2008年在Facet Publishing出版的《元数据》(13),这也是一本全面介绍元数据基础、元数据构建技术、元数据服务以及元数据研究的著作,该书全面展示了元数据的基础知识和高级主题,涉及该领域的各个方面。
(2)讨论元数据在数字图书馆中的应用的著作。如Jia Liu在2007年出版的《元数据及其在数字图书馆中的应用》(14)一书介绍了元数据的基础、类型、编码标准、实现流程、元数据研究项目,以及元数据在数字图书馆中的作用和具体应用项目。该书以数字图书馆为实例进行说明,其实用性较强。另外一本类似的书是Susan S.Lazinger和JeanWeihs于2006年出版的《元数据及其对图书馆的影响》(15),该书介绍了各种元数据框架,纸质资源和数字资源的元数据创建方法,元数据如何集成到目录与数据库中,探讨了元数据对当前在线参考咨询、档案、数字保存、职业教育以及未来创新的影响。
(3)讨论新环境下的元数据的著作。如《元数据与语义网》(16)一书是一个论文集,其中的几篇文章从元数据层面探讨了实现语义网的框架与技术,如DC元数据应用纲要的形式化问题、本体构建及其在语义网中的应用、根据已有的元数据及相关资源自动抽取新的元数据等。再如《标签——用户为社会网络创建的元数据》(17)一书中探讨了标签(tagging)这种Web 2.0环境下诞生的产物可以作为用户参与创建的元数据,该书全面讨论了标签的价值、标注系统的结构、标签与分类系统、标签的导航与可视化、标注系统的界面、标注系统的开发技术等问题。
2.1.2 中文元数据图书概况
根据中文图书的检索结果来看,当当网上书店的元数据图书最多,但基本上是关于某个领域的元数据研究著作,如地理信息元数据、电子商务企业核心元数据、农业科学数据核心元数据等。而专门以元数据为内容的著作则非常少,三个检索工具的检索结果基本一致。这方面的书在中国国家图书馆的两个检索结果中分别是由肖珑、赵亮主编,北京图书馆出版社2007年出版的《中文元数据概论与实例》(18),该书对中文元数据进行了系统、全面的论述,概述了元数据的基本概念、作用以及在国内外的发展状况,论述了元数据体系中最重要、应用最广泛的描述元数据及其规范的结构框架、设计方法、应用规则及其开放和互操作机制等。另一本书是由缪其浩主编,上海科学技术文献出版社2005年出版的《元数据与图书馆》(19),这是《图书馆杂志》的理论学术年刊,选择了“元数据在图书馆的应用”为核心内容,汇集了当代图书馆元数据应用领域中前沿研究的重要著述,共计论文20篇。
从数量上来看,中文元数据研究的专著很少,近五年发展速度非常慢。和以前一样,很多研究者都把元数据作为信息组织或信息描述相关书籍中的一部分,这与元数据研究越来越突出的地位是不相符的。此外,从教学方面来讲,国外很多高校都在本科或硕士层面开设了元数据课程,国内的一些高校如武汉大学、中国人民大学等也开始将元数据作为一门独立的课程,但元数据专著的缺乏使得我们很难找到一本合适的教材。
2.2 国内外元数据研究论文信息
对于外文期刊论文,笔者利用《图书馆、信息科学与技术文摘》(Library,Information Science&Technology Abstracts,LISA)数据库进行了检索,查找2005年至今的“descriptor”字段(该字段是人工标引的受控词)中含有“元数据”的文献,计有505篇,其中经过同行评议的期刊论文291篇,会议简报4篇,书评16篇。
对于外文学位论文,笔者利用ProQuest Digital Dissertation(PQDD)数据库进行了检索,查找2005年至今的“title”字段中含有“元数据”的论文,计有44篇。
对于中文期刊论文,笔者利用中国知网CNKI《中国期刊全文数据库》进行检索,查找2005年至今的“题名”中含有“元数据”的文献,计有977篇。
对于中文学位论文,笔者利用中国知网CNKI《中国优秀硕士学位论文全文数据库》和《中国博士学位论文全文数据库》进行检索,查找2005年至今的“题名”中含有“元数据”的文献,分别有196篇和8篇,共计204篇。
2.2.1 外文元数据论文概况
按照从LISA数据库检索的结果,505篇期刊文献按年度分布的检索结果如表3:
表3 2005—2010年L ISA数据库中主题为元数据的论文数量(截至2010年5月18日)

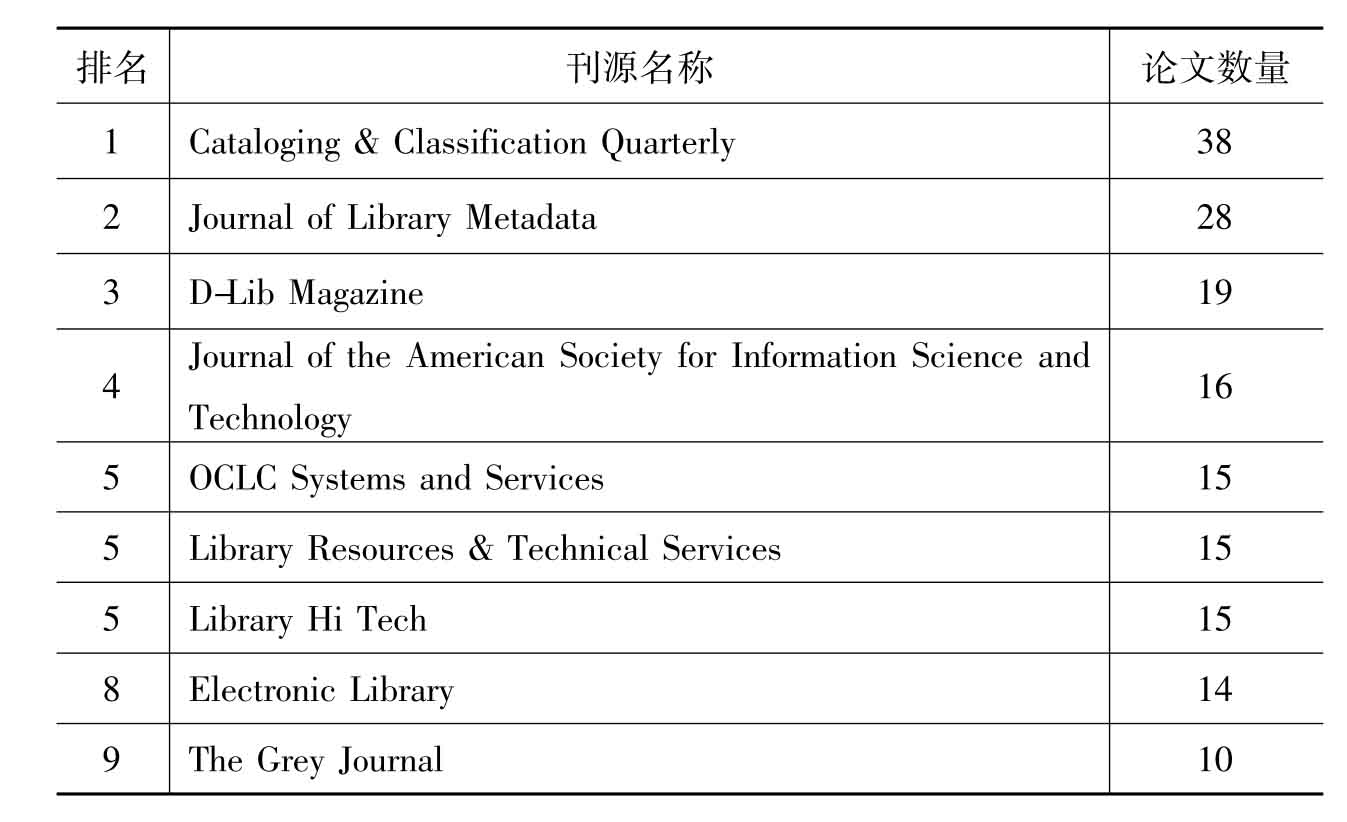
可见,元数据研究的发文量在2006年以后是呈下降趋势的,这与我们检索到的外文图书的结果是一致的,说明在国外元数据研究已经过了高峰期,开始进入稳定期。此外,笔者还统计了国外元数据论文的刊源分布,见表4:
表4 2005—2010年L ISA数据库中元数据论文的刊源分布(截至2010年5月18日)
续表
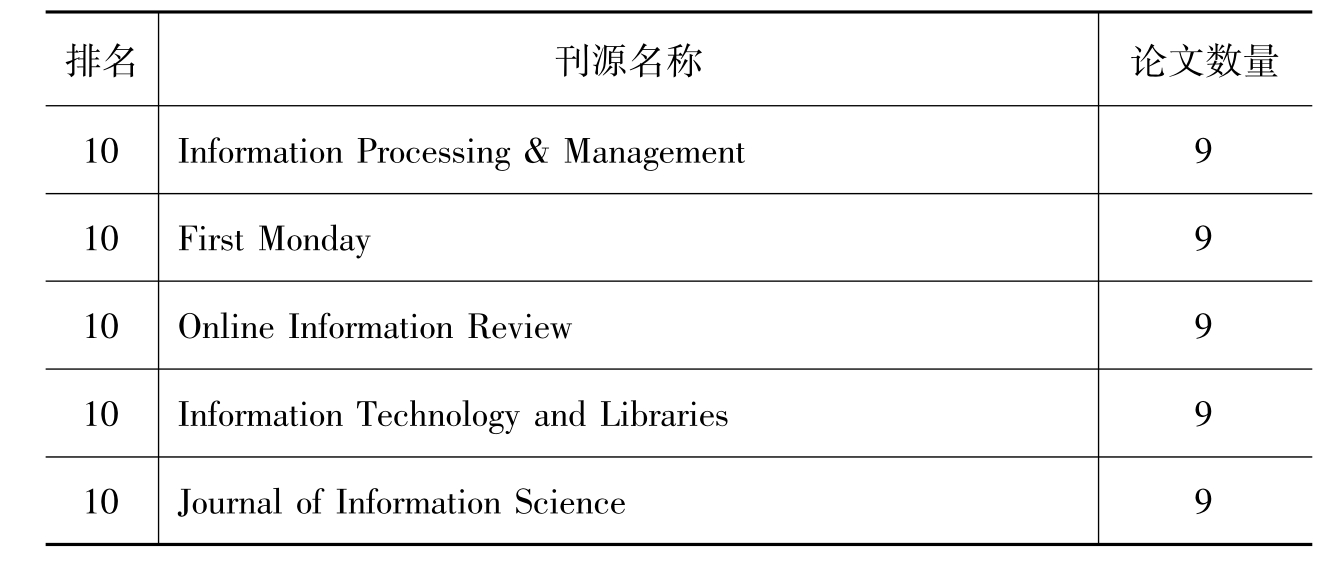
从外文学位论文的研究情况来看,从PQDD检索到的44篇学位论文中有25篇为博士学位论文,19篇为硕士学位论文。25篇博士学位论文中,有15篇是来自计算机领域,只有4篇是来图书馆学专业。这4篇博士论文分别是:美国北得克萨斯州大学A lemneh2009年的论文《文化遗产机构中的保存元数据研究》(20)、英国南安普顿大学A l-Khalifa 2007年的论文《基于自由分类法与领域本体的文档语义元数据自动标注研究》(21)、加拿大麦吉尔大学Lai2007年的论文《数字图像元数据研究》(22)、英国城市大学Polydoratou2006年的论文《元数据注册系统的使用与功能》(23)。可见,由于元数据的研究多是集中在某一具体的应用中,因此专门以元数据为系统研究的学位论文并不多。
2.2.2 中文元数据论文概况
按照从CNKI数据库检索的结果,977篇期刊文献按年度分布的检索结果如表5:
表5 2005—2010年CNK I数据库中题名为元数据的期刊论文数量(截至2010年5月18日)

如表5所示,中文元数据研究的发文量近五年来一直呈现一种平稳分布的趋势,每年的发文量基本持平,且这一数量约为外文元数据发文量的两倍,说明在我国元数据研究近几年仍然处于高峰期。此外,从领域分布来看,我国元数据研究主要集中在表6所示的几个领域:
表6 2005—2010年CNK I数据库中元数据期刊论文按领域分布(截至2010年5月18日)

我国关于元数据的研究主要集中在图书情报领域、计算机领域和空间地理领域,还有其他如管理科学、通信、控制等领域。以图书情报领域的发文量来看,与国外的研究相比略显不足。
此外,从元数据研究的学位论文情况来看,遗憾的是,在查到的8篇博士学位论文中,没有1篇是图书情报领域的。这说明我国图书馆学对元数据的研究还不够深入。
2.3 国内外元数据研究项目信息
对于外文元数据研究的相关项目,笔者分别调研了美国最主要的科学科研资助机构——美国国家科学基金(The National Science Foundation,NSF)(24)和美国博物馆和图书馆的主要资金资助者——博物馆与图书馆服务学会(Institute ofMuseum and Library Service,IMLS)(25),对2005—2009年这两个机构有关元数据的研究项目的资助情况进行了检索。检索结果如下:NSF资助的有关元数据的研究项目有24项,IMLS资助的项目有35项。
对于中文元数据研究的相关项目,笔者分别调研了我国最大的两个科研资助机构——国家自然科学基金(26)和国家社会科学基金(27)。检索结果如下:国家自然科学基金资助的项目有9项,而国家社科基金资助的项目则是零。
2.3.1 国外元数据研究项目概况
笔者对2005—2009年美国NSF和IMLS资助的元数据项目按照年度进行了统计分析,如表7所示:
表7 2005—2009年NSF和IM LS资助的元数据项目年度统计(截至2010年5月18日)
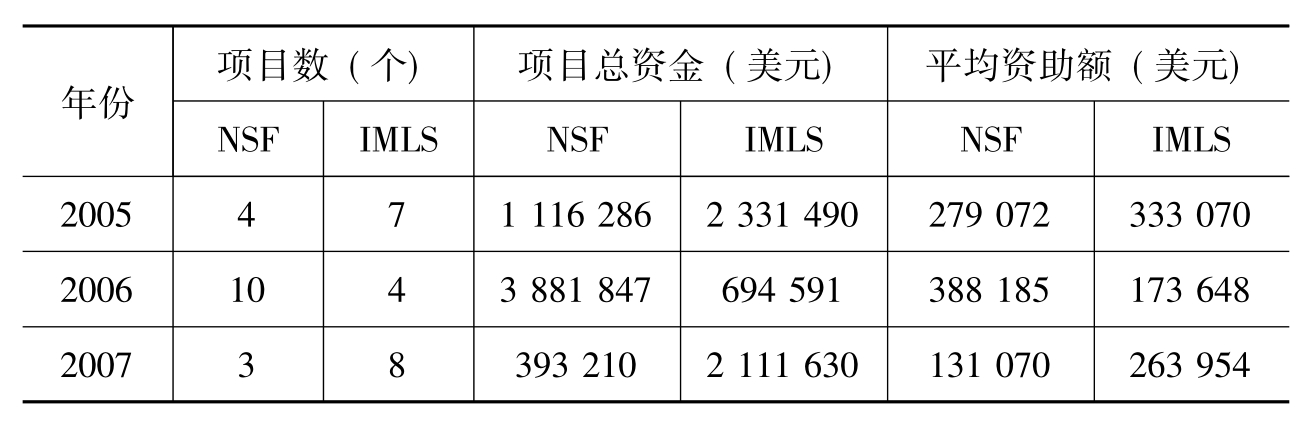
续表
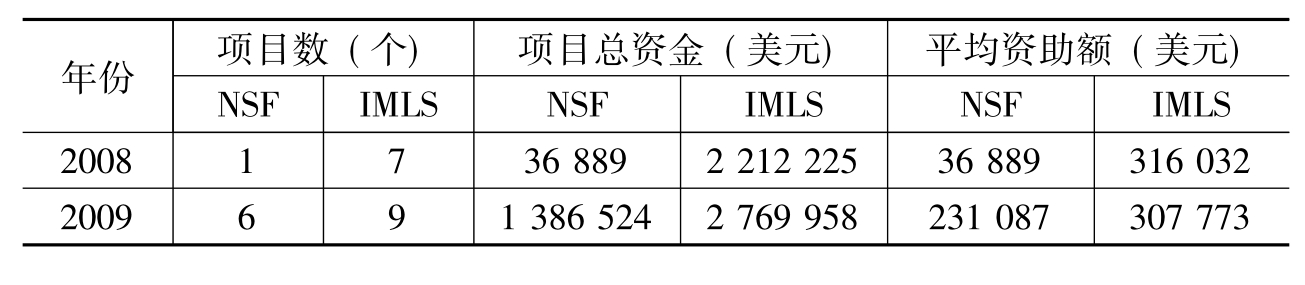
从数量上看,NSF资助的力度在2006年达到最高,而恰恰相反的是,IMLS在2006年则最少。从金额上看,NSF在2006年之后的资助力度有所下降,而IMLS则除了2006年之外,其余四年都比较均衡。总的来说,美国的研究者关于元数据的研究获得了大量的政府资助,NSF的资助总额为680万美元,IMLS的资助总额为1 000万美元。可见在信息技术发达的美国,对元数据及相关研究得到了多方支持。
2.3.2 国内元数据研究项目概况
与国外的研究项目相比,我国在元数据领域的研究略显滞后。仅从立项数上来看,国家社科基金在近五年内没有关于元数据的研究项目,国家自然科学基金有9项,2005—2007年各一项,2008—2009年各两项,总资助金额仅为210万元(见表8)。可见我国的元数据研究还是主要在计算机或空间地理等自然科学领域,而图书情报领域对元数据的研究仅仅是涉及,还不够深入,这与前面我们调研的专著、期刊论文、博士论文所反映出来的情况是一致的。同时,相比国外的政府资助,我国在该领域的资助力度上与美国的差距非常大,这恐怕也是导致我国在该领域研究上与国外有差距的原因之一。
表8 2005—2009年我国自然科学基金关于元数据的立项项目(截至2010年5月18日)

3 近五年来元数据研究热点问题
基于上述文献调研,笔者对近五年的中外文元数据图书、论文、项目进行了分析,发现国内外学者对于元数据的研究成果主要集中在元数据标准规范建设、领域元数据、新型元数据、元数据维护、元数据管理、元数据互操作、元数据自动抽取、用户参与的元数据构建、元数据与语义网、元数据应用十大方面。这其中,有些研究问题从元数据诞生起就一直备受关注,例如元数据标准规范建设、元数据管理、元数据维护、元数据互操作等;而有些热点问题则是近五年随着网络环境的变化、信息资源种类的丰富、媒体形式的多样化等而新出现的,例如新型元数据、用户参与的元数据构建、元数据与语义网等。
3.1 元数据标准规范建设
元数据标准是描述某些特定类型资料的规则集合,一般会包括语义层次上的著录规则和语法层次上的规定。语法层次上的规定有:描述所使用的元语言,文档类型定义使用的语法,含有内容的元数据的格式(也可以包括内容数据,即content)及其描述方法。元数据标准的设计与实现是数字图书馆建设过程中首要的、基础性的工作。从元数据诞生之日起,元数据的标准建设就一直是学者们研究的热点问题,目前国外已经产生并得到实际应用或试验的元数据标准有几十种。元数据标准建设的高峰期是在2005年以前,2005年之后,元数据的标准建设研究主要集中在对已有标准的完善与修订,以及各种标准的推广,使之成为国家标准和国际标准。
3.1.1 已有元数据标准的修订
从1995年最初提出起,都柏林核心元数据(DC)一直被不断地完善。2008年1月14日,都柏林核心元数据倡议(Dublin CoreMetadata Initiative,DCM I)发布了DC的最新版,即DC1.1。DC广泛被接受为国际和各国国家标准是在2000年后。如2003年2月,DC成为ISO国际标准(ISO15836—2003);而美国承认DC为美国国家标准是2007年5月(ANSI/NISO Z39.85—2007);互联网工程任务推动小组(InternetEngineering Task Force,IETC)也于2007年8月启动了对DC成为互联网标准的讨论(28)。
元数据对象描述模式(Metadata Object Description Schema,MODS)是美国国会图书馆于2002年6月开发的一种新的文献编目元数据,它是继MARC之后开发的第二种以MARC为基础的文献编目元数据。MODS是重视图书馆应用而开发的元数据,也是在MARC格式著录元素的基础上利用XML语言表达,并希望能在很多领域应用的元数据。MODS元数据标准在2005年3.1版后,多次修订,当前版本已是3.3,同时2010年4—5月还征集了对3.4版本的讨论。MODS3.4版的变化主要有:①对于名称和标题元素有更清晰的外部链接;②当几个上位元素有多个实例时,指定一个主要的;③把多语言的名称或翻译连在一起;④增加了一个数据共享限制标识;⑤对所有元素增加语种、程序和翻译;⑥对所有上位元素增加显示标签;⑦对子元素指定权威的授权信息;⑧为授权数据增加链接;⑨对名称元素指定性;⑩对更多类型的资源实例增加属性值;〇1对资源增加外部程序;〇12增加了“供应(supplied)”属性。此外,MODS3.4还在结构、一致性及其他方面做了修改(29)。
在线信息交换元数据(Online Information Exchange,ONIX)是世界出版行业针对图书出版发行和销售的供应链制定的元数据标准。其最初构想是在1999年由美国出版商协会(Association of American Publishers,AAP)主持召开的会议上提出的。2000年1月,AAP出版了ONIX产品信息标准第一版(ONIX Produce Infor-mation Standards1.0)。2001年7月推出ONIX2.0版,在稳定了相当长时间之后,于2005年2月推出了ONIX2.1。目前的最新版ONIX3.0于2009年4月推出。ONIX包括一系列针对书籍、期刊和授权条款的元数据标准。所有的ONIX标准旨在支持利用计算机到计算机之间的通信来创建、分发、许可或以其他出版形式提供不论是纸本或数字的知识产权。ONIX都用XML表示。ONIX书籍元数据标准被推动为国际标准,并被包括美国、英国、澳大利亚、德国、加拿大等十五国采用(30)。
艺术品描述类目(Categories for the Description ofWorks of A rt,CDWA)元数据标准是针对描述艺术品的需求而设计的,艺术品具有物理形态,也可能同时具有数字化了的图像。通过建立一个概念框架来描述和查询艺术品、建筑、图片和其他文化艺术品。CDWA由艺术信息任务工作组提出,由J.Paul Getty Trust资助,于2009年3月11日进行了修订。新版CDWA有532类和子类,其中有一些核心类代表了描述艺术品所必需的基本信息。文化对象目录(Cataloging CulturalObjects,CCO)则是CDWA核心元素的子集。CDWA Lite1.1版于2006年7月提出,它是基于CDWA和CCO的描述艺术和文化作品核心记录的XML模式(XML Schema),可以供基于OAI收割协议的联合目录等典藏库搜集(31)。
视频资料核心类目(Core Categories for Visual Resources,VRA)由美国视频资源协会(Visual Resources Association)的数据标准委员会制定,是为在网络环境下描述艺术、建筑、史前古器物、民间文化等艺术类可视化资源而建立的元数据标准。VRA Core 4.0于2007年4月发布。VRA Core 4.0包括一个元数据元素集(如名称、地点、日期等)和用层次结构表示这些元素的初步设想。这个元素集为视觉文化作品的描述和相关的图片提供了明确的组织方法(32)。
3.1.2 新的元数据标准的制订
除了上述已有的元数据标准改版外,还有一些国家在近五年也出台了一些国家标准元数据。例如,受荷兰AdvicesOverheid.nl和该国内政、关系部委托及资助,兰德公司(欧洲部)在2005年研究和评估了在荷兰全国范围内引入元数据标准来描述网上政府信息的可行性。该研究以都柏林核心(DC)元数据标准为基础,探讨了政府信息元数据的国家标准研究和建立时的三大议题:政府信息提供者对元数据的考虑和需求;对都柏林核心和其他元数据标准成为荷兰国家标准时的能力与局限性的审查;最后是对实现时会出现的诸多问题的探讨。该研究对政府信息提供者,例如网站和数据库的各级管理人员有借鉴的作用(33)。
2000年6月7日至9日,在北京香山召开了第一次“中文文献资源共建共享合作会议”。来自中国内地、台湾、香港、澳门和新加坡、美国、荷兰等国家和地区的42家中文资源收藏单位的62位代表参加了会议。此次会议上代表们提出,设立专门的中文元数据标准是建设中文数字资源库的重要基础,是网上中文资源健康发展的基石。会议决定由中国国家图书馆牵头制定《中文元数据方案》。《中文元数据方案》于2002年3月公布。
此外,《我国数字图书馆标准与规范建设》项目(ChineseDigital Library Standards,CDLS)(34)主要针对数字图书馆系统的数字资源建设与服务,制定我国数字图书馆标准规范发展战略与标准规范框架,制定数字图书馆核心标准规范体系,建立数字图书馆标准规范开放建设与开放应用机制,促进我国数字图书馆的快速、经济和可持续发展。项目一期从2002年10月开始,到2005年9月结束。项目二期从2006年开始至今。CDLS由中国科技信息研究所、中国科学院文献情报中心和中国国家图书馆联合发起,现在已有将近20个单位参与项目的研发和建设。CDLS的子项目包括:①总体框架与发展战略;②开放建设机制;③数字资源加工规范;④基本元数据规范;⑤专门元数据规范;⑥数字对象唯一标识符;⑦数字资源检索协议规范;⑧元数据规范开放登记系统;⑨资源集合元数据规范;⑩高层元数据规范;⑪数字资源描述标准规范的完善与扩展建设;⑫数字图书馆集成服务描述标准规范研究;⑬数字图书馆知识组织系统标准规范研究;⑭数字资源唯一标识符应用系统的完善建设;⑮数字图书馆标准规范推广宣传应用。CDLS目前已形成了164项技术报告(包括各种元数据规范和著录规则),2个推荐规范和2个候选规范,以及2个工作草案。该项目的研究成果有望成为我国数字图书馆建设的各项元数据标准规范。
3.2 领域元数据研究
元数据除了是数字图书馆建设的重要基础性工作之外,也是其他领域数字资源建设的重要工作。因此,在电子政务、教育、地理空间、气象等领域也产生了一些领域元数据研究。
3.2.1 电子政务领域
在电子政务领域,Alasem(2009)(35)描述了英国、澳大利亚、新西兰、加拿大和爱尔兰等国家的电子政务元数据。电子政务元数据可以用来发现和检索政府信息,以及协助政府管理电子资源。DC标准在电子政务元数据中被广泛地采用。其中,英国e-GMS元数据元素集和澳大利亚AGLS数据元素集在2006年都有新一版扩充。Alasem还提出了电子政务元数据的发展路线图:①阶段1:建立元数据工作组,通过下面的活动来规划、设计、开发、评价和实现国家元数据标准:识别描述性、管理性和保存性元数据的目标,研究和评价现有的国际和国家元数据标准。②阶段2:识别以下利益相关方的需求:政府信息和服务的提供方,用户包括公民和公司,网上工作组,一般会议和会面,调查和专题组,反馈分析;并识别要被元数据描述的政府资源,如网页、网上服务站点和政府离线资源等。③阶段3:研究当前地方政府网站,并根据政府资源的提供方和用户需求而识别的当前主要问题。④阶段4:确定适合的元数据元素,包括:从国际标准中选取;从国家标准中选取;定义新的元素。我国于2007年9月发布了《政务信息资源目录体系》(GB/T21063—2007)国家标准,《政务信息资源目录体系第3部分:核心元数据》(GB/T21063.3—2007)(36)是其重要组成部分,其中给出了政务信息资源核心元数据的定义。其中指出,政务信息资源核心元数据包括6个必选的元数据实体和元数据元素及6个可选的元数据实体和元数据元素。6个必选的元数据实体和元数据元素分别是信息资源名称、信息资源摘要、信息资源提供方、信息资源分类、信息资源标识符、元数据标识符。6个可选的元数据实体和元数据元素分别是信息资源发布日期、关键字说明、在线资源链接地址、服务信息、元数据维护方和元数据更新日期。《政务信息资源目录体系》从2008年3月1日起开始实施。
3.2.2 地理空间领域
在地理空间领域,空间信息应用领域的元数据侧重对空间信息的描述,也称地理空间元数据。我国国家标准《地理信息元数据》(GB/T 19710—2005)的目的是提供描述数字地理数据特征的结构,定义通用的地理信息元数据。周新忠等(37)在分析我国地理空间元数据应用现状的基础上,结合地理空间元数据的应用特点,分析了地理空间元数据的标准化、互操作、自动生成等趋势是地理空间元数据发展的必然,并论述了与这些发展趋势相关的实施方法和技术,以及这些趋势之间的辩证关系。
3.2.3 气象领域
在气象领域,气象预报元数据(Climate and Forecast,CF)最初是为数值天气预报(NWP)和气候模型输出而设计的元数据公约。其核心目标是服务于世界各研究单位参与大气模型比较计划(A tmospheric Model Intercomparison Project,AM IP)及政府间气候变化专门委员会(IntergovernmentalPanel on ClimateChange,IPCC)评估报告等活动的全球数据交换。CF被稳步扩展到提供适当元数据来描述观测数据,如地面气象观测和卫星测高数据等。CF已成为许多大气和气候科学项目的数据标准(38)。胡文超等(39)对元数据及元数据标准在国内及气象部门内的研究进展情况进行分析,讨论了目前气象业务发展中气象数据管理和共享中存在的问题,并对元数据的需求提出一些展望。
3.2.4 生物医药领域
在生物医药领域,GeM InA系统(40)标识、规范和整合NIAID的A-C类的病毒和细菌病原体的爆发元数据,从而提供调查和监测工具来描述每一病原体的“谁”(宿主),“什么”(疾病,症状),“时间”(日期),“地点”(位置)和“如何”(病原菌,环境源,存储库,传输方法)。该数据库将对病毒和细菌病原体对宿主和传染病的相互作用提供更深入的文本挖掘,整合爆发元数据、疫情监测工具、本体发展、元数据管理和有代表性的基因组序列鉴定及标准的发展。
3.2.5 古籍研究领域
在古籍研究领域,张婧(41)在对拓片元数据标准总体情况进行梳理的基础上,采用比较研究的方法,对《拓片与古文书数位典藏计划暨辽金元拓片数位典藏计划拓片Metadata需求规格书》(台湾地区)、《北京大学古籍数字图书馆拓片元数据标准(草案)》以及国家科技部重大基础课题“我国数字图书馆标准规范建设”子项目“专门元数据规范”的拓片元数据规范研究成果三家代表性拓片元数据标准进行比较分析,总结了三部标准规范的各自特点,最后提出拓片元数据信息的提取与拓片元数据标准的设计同等重要。
3.3 新型元数据研究
描述型元数据是用来描述与识别信息资源的元数据,在关于元数据类型的研究文献中,描述型元数据研究占据了主体地位。但随着网络环境的变化,元数据的研究进展之一就体现在新的描述型元数据的出现,主要包括情景敏感元数据、分面元数据、科学元数据(42)。
3.3.1 情景敏感元数据
为了描述用户注意行为,注意元数据(Attention Metadata)及其拓展情景敏感元数据(Contextualized Attention Metadata,CAM)应运而生。美国计算机学会(ACM)从2006年开始召开相关国际会议(International ACM Workshop on Contextualized Attention Metadata,CAMA),目前已召开两届,分别是2006年信息与知识管理国际会议(CIKM)的一个专题研讨会“情景敏感元数据:收集、管理和拓展丰富的使用信息”(43);2007年国际数字图书馆会议(JCDL)的一个专题研讨会“情景敏感元数据:数字资源的个性化获取”(44)。此外,2009年德国计算机会议(Informatik)的一个专题研讨会是“注意元数据的应用(Exploitation of Usage and Attention Metadata,EUAM 09)”(45)。研究人员对CAM的概念、研究意义、数据的获得、应用、发展前景等进行了讨论。Jehad Najjar等人(46)对注意元数据的定义是:“注意元数据是指用户在使用普通网站、W iki、Blog、文本交流、电子邮件等资源过程中,被用户注意的和引起用户注意的任何内容。”近几年,这方面的研究主要集中在情景敏感系统的研究以及注意元数据的应用上。如Joona等(47)探讨了一个代表用户当前或潜在注意分配的任务模型,并基于该模型构建了A tGentive原型系统,该系统支持通过观察用户在某一情景下的特定行为,生成支持用户使用的情景选择,帮助用户找到完成任务最好的办法。Joe(48)提出了一种通过多渠道为一个新网站测量受众注意的方法,他选择了美国国会图书馆于2007年3月发布的一个新网站——the Chronicling America Site,分析该网站开通最初两周内的公众访问数据,目的是提高网站被用户的关注度。Martin等(49)设计了一个从各种不同用户观察部件获取分布式情景敏感元数据的系统,对从各途径获取的情景敏感元数据进行共享,以支持基于情景的、个性化的信息检索服务的集成。Eleftheria等人(50)利用视频会议软件lash-Meeting提供的与学习用户相关的情景敏感数据功能,可视化地显示了全球范围内各个地区的用户参与情况、用户重播某个视频会议的情况等内容。W iley.D.等人(51)认为自动收集起来的CAM数据由于可以分析出用户个人的兴趣,因此,如果将这些兴趣放到一个较大的虚拟网络社区中,那么通过兴趣爱好相似度的分析,可以在兴趣爱好相似的用户之间建立联系,使其共享共同感兴趣的资源并组成虚拟社区。国内在情景敏感元数据方面基本没有创新性的研究,只有李书宁等(52)有一篇这方面的综述文章,全面介绍国外情景化注意元数据的研究现状,包括对情景化注意元数据的相关理论、收集方法、应用领域和隐私保护等方面的问题,并对情景化注意元数据的未来研究进行展望。
3.3.2 分面元数据
分面元数据(Faceted Metadata,FM)方法是基于分面分类理论、采用元数据进行描述的一种网络信息组织方法。国外对分面元数据的研究最具代表性的人物当属美国加州大学伯克利分校信息管理与信息系统学院的MartiHearst教授。她主持设计的Flamenco搜索系统(Flamenco Search)采用分面元数据来对美术和工程图片信息进行组织。她使用多种方法,对包括美术作品的对象、日期、艺术家和内容进行分类,并为这些类别建立交叉关系。当用户点击某一类的时候,会立即看到许多与该类别相关的信息。该系统还能让人们立即看到类别中的多种子类。此外,该系统还可以把美术作品按10年分组,例如,你可以比较1740—1780年,花卉是如何被描绘的。通过这种方法,人们可以做比较和对比,发现新的种类和关系。目前这个系统在不断更新和完善中。系统初期有两个图片检索系统。一个是美术图片(Fine arts images)检索系统,资源来自于旧金山美术博物馆(The Fine A rtsMuseums ofSan Francisco);另一个是工程图片(A rchitecture images)检索系统,资源来自于伯克利分校的工程资源图书馆(The UC Berkeley A rchitecture Visual Resources Library)。2007年又增加了一个新的图片检索系统:诺贝尔奖获得者图片检索系统,资源来自诺贝尔官方网(nobelprize.org),采用的都是分面元数据的组织方式(53)。此外,分面元数据还用于电子商务、电子政务等网站的建设。如Fenareti等(54)探讨了多面元数据分类结构用于希腊电子政务服务框架。同样,国内在分面元数据方面也几乎没有创新性研究,只有郭世新等(55)有一篇这方面的综述文章,介绍了分面元数据的概念和国外的发展情况,以及分面元数据相关的技术,如分面图(FACETMAP)、分面元数据的描述语言(XFML、DTD、RDF等)的发展情况,总结了分面元数据系统的两点共同特性,即搜索与浏览界面相结合,对图片检索具有更好的效果。
3.3.3 科学元数据
科学数据是科研活动中产生的一个成果,通过构建合理的面向科学数据的元数据模型,科学家可以更好地共享和检索数据资源。英国研究委员会中心实验室理事会(Council for the Central Laboratory of theResearch Council,CCLRC)构建了科学元数据模型(ScientificMeta-DataModel)(56),按照逻辑结构可以细分为6个主要元素:主题、研究描述、获取条件、数据描述、数据定位和相关资料。其中,主题元素由与研究相关的关键词构成;研究描述介绍了与研究有关的信息,例如是谁在何时、何地完成了这项研究;获取条件提供了谁有权获取这些数据、用户的信息需求以及如何获取数据等信息;数据描述更加详细地提供了数据持有者是如何组织数据等这类信息;数据定位为查找数据提供导航结构信息;相关资料则提供了与该项研究有关的参考资料、研究学会、研究团体等信息的链接。同时,这6个要素又构成了科学元数据模型的层级目录,使得该框架下的元数据被分散放置在不同的类目和子类目中,如科学行为这个类目中就包含政策、项目、调查、评估和实验等几个子类目。该元数据模型的层级目录是由一个标准的关系数据库来实现的,一旦用户需要的某个特殊数据集可以与模型中现有的元数据匹配,目录就会为用户提供与这个元数据有关的全部链接,并帮助用户获取所需的元数据集。我国从2003年开始实施国家科学数据共享工程,2005年制定了《科学数据共享元数据》(57),提供了科学数据共享元数据内容标准框架,定义了科学数据共享核心元数据、公共元数据和参考元数据。在该标准的指引下,各个领域也纷纷制定了各领域的科学数据共享元数据,如《国土资源科学数据共享核心元数据》、《水利科学数据共享元数据》、《交通运输科学数据共享元数据》、《海洋科学数据共享元数据》、《医药卫生科学数据共享元数据》等16个领域的科学数据共享元数据。
3.4 元数据维护
描述数字资源的元数据在数字图书馆和档案馆中起到十分重要的作用。由于数字资源是不断发展的,与之相对应的元数据也在不断地变化,这就导致了元数据的发展能否与数字资源发展保持协调一致的问题。此外,许多与数字资源有关的应用软件的功能都是建立在元数据基础上的,元数据的变化将直接影响到这些应用软件的质量,因此,如何及时、准确地维护元数据引起了研究者的关注。
3.4.1 数字图书馆元数据维护
图书馆花相当大的精力来建立、保存,以及转换MARC和非MARC记录中的描述性元数据。但它们很少花同样的时间和精力来对非MARC元数据进行维护。这在更新和编辑现有的描述性元数据时表现得更明显。LeBlanc和Kurth(58)基于J.A.Zachman的信息系统架构提出了具备识别和记录目录元素,即元数据维护的模型,并规划跨部门和跨单位的计划。这个模型认为经验和技巧既然一直是图书馆维护目录的重要组成部件,它们也应该在元数据维护中发挥作用。
Kurth和LeBlanc(59)研究了对描述数字馆藏的元数据目录进行日常管理时需要的主要实体和关系。在参考其他相关数据模型的基础上,他们起草了一个支持维护馆藏的元数据的数据模型。此外,他们还讨论了对图书馆元数据维护操作模式的影响。
元数据在描述数字物体时起到了关键作用。Jin Ma(60)介绍了在宾夕法尼亚州立大学图书馆数字化项目中元数据实现的六个步骤:分析元数据的要求,采用元数据方案,创建元数据内容,提供和获取,评价元数据及元数据的维护。同时作者还讨论了一系列关于元数据的技术、管理和组织问题。
2005年5月发布的PREM IS保存元数据的数据字典是第一个建立从国际跨领域层次建立保存元数据规范的共识的过程(61)。PREM IS维护行动是由美国国会图书馆成立的,负责协调对数据字典和相关的XML模式的发布和维护的机构。这个机构还设立了鼓励机制来吸引社会的数据字典的反馈和包括讨论如何在用户自己的数据档案系统中实现PREM IS保存元数据的数据字典。
3.4.2 网络资源的元数据维护
由于网络资源是动态变化的,这就要求记录它们的元数据也随之更新,于是,网络资源的元数据维护问题也成为人们研究的焦点。Vuong等人(62)针对这个问题构建了关键情景元素(Key element-Context,KeC)模型,该模型确定了网络资源元数据维护的3个子任务,即进程监测、变化发现和元数据更新。进程监测是通过周期性的监测来获取网络资源目标的最新版本,并以此来发现元数据的变化;变化发现是通过比较网络内容目标的不同版本来判断是否有变化发生;一旦监测到变化,这些内容目标的元数据就要相对地进行更新。
AMMGO(63)是北卡罗莱纳大学元数据研究中心的一个元数据维护项目。这个项目的目标是满足日益增加的维护北卡罗莱纳州健康信息(NCH I)网站的元数据的需求。NCH I是个为北卡罗莱纳居民提供相关健康、疾病和保健信息的网站。通过结合元数据自动生成和质量管控的技术,这个项目希望能让NCH I的分类员能有时间更多地关注那些需要人的智能的元数据问题。这个项目有两个阶段:①自动元数据应用评估来明确需要加强的部分;②自动元数据质量评价来明确自动元数据维护过程的有效性。
3.5 元数据管理
元数据管理是指对元数据的浏览、添加、删除、修改、下载和查询等数据管理的基本操作。近五年,国内外学者对元数据管理的研究主要集中在元数据管理方法和元数据管理系统的设计与实现上。
3.5.1 元数据管理综述
从元数据管理的综述类文章看,Phokion(64)以数据库中元数据和数据交换为核心,对数据交换和元数据管理近几年的发展做了总结,重点讲述了模式映射(Schema Mapping)在数据库中的设计、集成、数据交换和元数据管理中的显著作用,还展望了一些重要的未来发展方向。Paolo等(65)认为当前的知识密集型应用对元数据管理提出了很重要的挑战,重点表现在发布、获取控制(access control)、获取的统一性(uniformity of access)和随时间的演化,通过指出元数据管理的一般要求,描述了以管理RDF元数据为核心的、能满足所提的要求的、一个简单的模型和对应的服务。
国际大型数据库杂志(The International Journal on Very Large Data Bases,VLDB)在2008年有一期专题讲元数据管理。这一期的特邀主编是Tiziana Catarci和Renée J.M iller(66)。专题的重点在讨论元数据的建立、搜集、管理和理解上的最新进展,凸现了当前影响使用和分享已有数据的最大的挑战就是缺乏元数据和对它们的有效管理。专题中的4篇文章第一篇讲述了独立于具体模型的模式翻译,从而使模式翻译的规则可以适用于不同的应用领域。第二篇讲述了通过P2P协同来缓解元数据缺乏的问题。作者研发了Pic Shark系统来利用模式映射的技术来匹配标注和其他半结构的注释(semi-structured annotations)。利用网络资源,这个系统可以实现大规模跨领域的协同。第三篇讲述了支持个人信息集成和应用在语义桌面系统中的层次模型的设计。重点讲述了利用元数据实现用语义组织来描述个人信息的技术。通过使用大量的注释和显性地表述语义关系,这个模型可以提供丰富的数据操作功能,包括结构化查询和浏览,以及可视化。第四篇讲述了元数据集成中冲突解决的方法搜寻和专家反馈中的系统支持。该系统叫FICSR,它可以根据两个输入的分类和它们之间的映射,生成一个集成的分类,并把映射里出现的冲突用辅助结点和加权的边表示出来,用户可以查询冲突和对冲突提供反馈,从而改变和最终消除冲突。
3.5.2 元数据管理方法
从元数据管理方法的文章看,科罗拉多州立大学(Colorado State University,CSU)图书馆的元数据最佳实务工作队(The Metadata BestPractices Task Force,MBPTF)开发了一套元数据核心元素集和相应的数据字典,以便为中央数字化仓储库的各种数字对象提供协同的元数据管理方法。他们介绍了工作队的注重数字化过程和过去CSU元数据的做法的工作理念和使用过程,包括回顾有关的机构元数据的项目和例子,并描述工作队正在进行的工作和今后的评估计划(67)。
在数据生命周期的环境中谈元数据和起源管理是元数据管理的新的要求。元数据描述的是数据赋予的意义,而起源描述的是数据产生的过程,两者对正确描述一个信息都有重要的意义。现在科学信息的产生和管理都依赖于科学合作,并通过集成的知识和资源来解决问题,由此可见对元数据和起源的管理很重要。元数据和起源的管理对利用软件对科学信息进行自动分析也很重要。Ewa Deelman等(68)总结了几类对元数据管理有重要意义的元数据特性,它们是逻辑文件与数据、逻辑数据集元数据、授权元数据、用户元数据、用户定义的元数据特性、标示特性、建立及变形历史元数据、外部目录元数据。存储元数据管理的技术包括关系数据库、XML数据库、网格数据库服务和RDF三元存储。张魁(69)从电子文件系统设计与电子文件形成、运行和维护几个阶段对电子文件生命周期中的元数据管理进行了论述。
还有其他一些元数据管理方法,如黄如花等(70)结合开放存取资源元数据管理的现状,提出了加强开放存取资源元数据管理的对策与建议。刘仲等(71)提出目录路径属性与目录对象分离的元数据管理方法,扩展了现有的对象存储结构。该方法能够有效避免因为目录属性修改而导致的大量元数据更新与迁移;通过减少前缀目录的重叠缓存提高了元数据服务器Cache的利用率和命中率;通过减少遍历目录路径的开销和充分开发目录的存储局部性,减少磁盘I/O次数;通过元数据服务器的动态负载均衡避免单个服务器过载。实验结果表明,该方法在提高系统性能、均衡元数据分布以及减少元数据迁移等方面具有明显的优势。语义元数据在语义网格中扮演着关键的角色,它为实现服务的查找、匹配、发现过程提供必要的信息描述和决策支持。孙莉等(72)探讨了语义元数据的产生背景、功能分类以及基于本体的语义元数据的管理需求和通用框架,对现有典型系统的基于本体的语义元数据管理进行了深入的分析和比较,提出了基于本体的语义元数据管理未来研究内容。
3.5.3 元数据管理系统
语义传感器网络用传感器网络获得的元数据来描述物理世界。Kawashima等(73)提出MeT系统的设计和实现。MeT是一个面向真实世界的语义传感器网络元数据管理系统。MeT或是静态地应用语义来生成元数据,或是动态地使用推理规则,然后通过这些元数据构造物理对象之间的关系。用户可以通过图形用户界面或者通过通信机器人Robovie来查询有关实物。杜楠等(74)提出了一种基于混合式技术的元数据管理系统,探讨了两种常用的元数据管理方式:集中式元数据管理和分布式元数据管理。详细分析了基于这两种元数据管理方式的混合模型的结构,并对系统中对象存储的作用以及对元数据服务器的结构和功能进行了详细描述。最后,对元数据管理中重要的元数据标准进行了分析,运用该系统使得元数据的管理,数据处理、分析和过程的综合再现更加高效、方便和安全。胡昊等(75)对基于XML的多源异构数据融合、遥感数据存储、数据持久化以及用户访问控制技术进行了分析和设计;讨论了元数据管理系统的实现技术、设计思想和系统构架,注重系统的可移植性、可维护性和可扩展性;实现了基于J2EE技术的元数据管理系统。张秀坤(76)针对信息系统中建立的数据仓库的元数据进行科学有效的管理,提出了一种基于知识的元数据管理工具的系统框架,并在元数据管理方面进行了一些探索性的研究。朱培毅(77)设计了一个基于XML的图书元数据管理系统。高伟国等(78)以“辽宁省大连市委办公系统软件工程中的公文系统”开发实践为例,从数据存储、数据交换、数据展现等几个方面多角度探讨元数据在电子政务公文系统中的应用和实现机制。
3.6 元数据互操作
互联网和数字馆藏资源的快速增长一直伴随着元数据模式的广泛应用。但每一个模式的设计都是基于特定用户群、资源类型、主题领域、项目需求等因素。在建设大型数字图书馆或仓储库时,元数据记录通常根据不同的元数据模式产生,从而造成困难。因此元数据互操作的问题自元数据诞生之日起就得到了研究者们的广泛关注,近五年也是如此。
3.6.1 元数据互操作综述
元数据互操作是实现对异构媒体库媒体对象进行统一访问中很重要的问题。目前存在着许多互操作技术,它们对解决存在于不同的仓储库中的元数据间的结构和语义的异构性有着不同的潜力。除了对元数据互操作领域的一个总体概述外,Haslhofer,B.和K las,W.(79)对现有的互操作性技术进行了分类,描述它们的特点,通过分析其解决异构性的潜力来比较它们的质量。根据它们的工作,领域专家和技术人员可以得到一个对互操作的概述和对现有元数据互操作技术的分类,从而帮助其基于特定元数据的集成方案来选择适当的方法。Haslhofer,B.和K las,W.的分析还明确表明,当无法对某一个元数据标准达成共识时,元数据映射是集成方案中比较适用的技术。LoisMaiChan和Marcia Lei Zeng(80)分析了已被用来实现元数据模式互操作性的一些方法,其目的是帮助和改进元数据之间的转换和交换,使跨领域联合收获和联合检索成为可能。从方法论的角度来看,互操作性的实现可以从下面不同的层次来考虑:模式层、记录层和仓储库层。在这两篇文章中,第一篇文章解释了元数据模式在个别项目或综合仓库情况下被创建的一些考虑;此外,还讨论了在模式层的使用方法。第二篇文章讨论了记录层和仓储库层的元数据互操作。
张东(81)提出了元数据互操作的3个层面,即语义层面、描述规则和语法层面,从而揭示了元数据互操作的本质,认为元数据互操作问题的根本解决有赖于未来语义网本体技术的构建。朱超(82)从语义互操作、语法互操作和结构互操作及应用协议4个角度讨论元数据现有的主要互操作模式,并对每种解决思路作出比较评价。申晓娟等(83)从元数据互操作背景、主要实现方法、映射实例评析方面进行探讨,并提出建立有效的元数据互操作机制的构想。毕强等(84)从语义互操作、结构与语法互操作、协议互操作3个角度,探讨了元数据的互操作性及解决方案。孔庆杰等(85)从语义、结构、语法、检索协议等角度对元数据互操作问题进行深入分析,并对现存技术途径解决方案的局限性进行概括总结。
3.6.2 具体应用的元数据互操作
(1)数字图书馆元数据互操作。2001年推出的OAI元数据收割协议(OAI-PMH)增加了人们对元数据的质量问题,特别是有关数字图书馆的互操作中元数据质量和使用元数据收割来建立数字信息资源的“联合目录”的认识。专家提供了广泛的意见和建议,并建立了衡量共享元数据的质量指标。Jackson等(86)着眼于利用过去6年间伊利诺伊大学建立和收获的元数据记录,对共享的元数据质量的变化做定量和定性的分析报告。郑志蕴等(87)分析元数据互操作产生的原因,从技术角度总结和研究元数据互操作的主要解决途径,指出存在的问题,给出利用网格技术实现元数据互操作的思路。毕强等(88)探索基于元数据本体的数字图书馆系统间的互操作策略,以期用来解决目前数字图书馆系统间互操作所面临的问题,即不同本体之间的互操作,跨语言、跨文化的互操作,数字图书馆的发现与安全性等,并提出下一代数字图书馆系统间互操作框架。
(2)文化遗产数据集元数据互操作。元数据互操作性是一个活跃的研究领域,特别是文化遗产数据集中的各类记录由各种元数据模式来描述。Kakali等(89)提出了一个基于本体的元数据互操作性的办法。这个方法以最佳的方式利用了元数据模式的语义。特别是他们建议利用CIDOC/CRM本体作为中介模式,并描述了映射DC类型词汇到CIDOC/CRM,展示了基于本体的元数据集成的真实的努力。王芳等(90)提出基于OAI-PMH协议的数字档案馆互操作的框架及功能,分析数字档案元数据EAD的结构及其与DC的映射,讨论EAD记录向OAI转换的技术原理,尤其是关于转换后保持记录上下文关系的原理,针对转换过程中存在的问题与困难提出几点解决办法。
(3)公共部门信息系统元数据互操作。最近几年,对管理和公共部门信息的系统间互操作性出现了全球日益增长的需求。Bountouri(91)探讨了公共部门信息的文件需要,并集中讨论了元数据互操作性问题。这项工作研究了公共部门信息的各个元数据标准和国际公认的准则,并提出两个不同的方法来获取互操作性。第一个方法开发应用配置文件(profile),而第二个是利用语义集成方法来建立一个本体。根据元数据集成过程中互操作性的使用范围和应用对这两种方法的结果进行了比较。
(4)科学数据库元数据互操作。为了更有效地使用分布式和异构的科学数据库,必须检测出并去掉语义异构性。Jian-hui Li等(92)建议用元数据注册库来管理元数据和元数据模式。元数据注册库可以用来存储数据共享和交换中必要的数据特性。他们描述了元数据注册库的作用和实现该库的一些经验。
(5)数据仓库元数据互操作。潘定等(93)对数据仓库中的元数据互操作性技术的研究和应用进行了综述,讨论了元数据管理需求、体系结构模式,分析了元数据管理标准,详细讨论了存储库结构、交换方式、变更管理以及模型管理等元数据交换的关键实现技术。
3.7 元数据自动抽取
网络环境下,面对如此浩瀚的网络信息资源,仅靠专业人员来完成元数据的组织和管理,无疑是很大的挑战。如果仅靠用户来生成,也存在很多弊端。因此,元数据的自动生成便成为近五年来元数据研究的一个重要方向。元数据自动生成技术大致有以下几种:元数据提取技术、元数据收割技术、元数据分面技术和其他技术(94)。
3.7.1 元数据自动抽取方法
Xia Lin等(95)提出了一个在生成元数据过程中整合多种来源的语义信息的方法。这个新的框架能确定手动和自动生成的关键词的主题。自动生成的关键词包括从对文本集进行语义分析生成的关键词和用户以前查询式里的关键词。他们设计了一个人机界面以方便利用那些主题来创建元数据。该框架和接口促进了元数据生成中的人机协作。Yunhua Hu等(96)提出了一种从一般文件提取标题的机器学习方法。一般文件指的是可以属于任何一个特定类型的文章,包括演讲、书籍章节、技术文件、手册、报告和书信。此前提出的标题抽取方法主要集中在研究论文的标题提取。作为一个案例研究,Yunhua Hu等从MS Office的Word和PowerPoint等文件中提取标题。这种方法的特点是利用文本格式如字体大小来建立模型特征。这些格式信息可以从一般文件中提取,而且有相当精确的提取效用。从Word中提取标题的查准率和查全率分别是0.810和0.837,而从Power Point中提取的查准率和查全率分别是0.875和0.895。同时,在一个领域的模型还可以应用到其他领域,并且使用文件中提取的标题还大大提高了搜索效率。
3.7.2 Web元数据自动抽取
(1)一般网络(基于HTML的文档)元数据的抽取。主要借助于Java等高级语言进行提取。以Java为例,首先根据HTML网页表格的特点,使用Java语言和开源项目HTML Parser(包括Filter方式和Visitor方式)针对网页中的表格标记进行分析;然后使用Web信息元数据生成器(generator)针对网页实施一次扫描,用以形成Web信息元数据描述文档。于志敏等人(97)提出了一种用矩阵表示一个文本的表示形式(整个文本用一个文本分块矩阵W J来表示。文本矩阵中的每一行表示文本的每一段,文本有几段,文本矩阵则有几行),并给出了网页元数据提取的规则和算法。
(2)语义网上DC元数据的抽取。通俗地说,“语义网”是按照能表达网页内容的“词语”连接起来的全球信息网;或者说是用机器很容易理解和处理的方式链接起来的全球数据库,是现有万维网的变革和延伸。经XML和RDF/XML描述后的DC元数据具有语义标注,在网络资源抓取器、XML解析器和XML包扫描器等协同工作下,可实现语义网上数据的自动抽取功能。当抽取时,先由网络资源抓取器,从语义表示上抓取带语义标注的资源文件,并将抓取的文件分类。如果是XML类文件,交SAX或DOM解析,抽取其中的元数据;如果是XML包的宿主文件,交XML包扫描器扫描,截取其中的XML包,再由SAX或DOM解析,抽取其中的数据信息。关于XML包的扫描技术有两种:一种是按已知文件格式进行定位扫描,另一种是按字节流的顺序扫描(98)。Sue等(99)设计了一个对网络资源元数据进行自动化创建的系统。该系统主要创建4类描述性的元素——书目、语义、关键字、结构。此外,他们评估了影响元数据产生质量的因素,并根据研究结果,提出了元数据自动生成工具应给用户提供的必要辅助。
3.7.3 数字图书馆元数据自动抽取
Biblio是一个可以从半结构化和结构化扫描文章中自动提取元数据的自适应系统。系统使用基于实例的机器学习以适应客户定义的文件和元数据类型。利用扫描杂志文章和扫描法律文件而建立的两个语料库,研究者实验测试了系统结果。杂志文章是半结构化,而法律文章多为质量差的传真扫描文件。实验结果显示,系统在半结构化文档中元数据抽取的准确性大致与手工编码系统相当,而在法律文件中的抽取表现则很差(100)。表格广泛存在于数字图书馆中。在科学文件中,表格被广泛用于简明表示实验结果或统计数据。然而,目前的搜索引擎不支持表格搜索。这是因为从无结构的文章中自动提取表格很困难,缺乏普遍接受的表格元数据规范,以及现有的检索模型在搜索表格时有许多问题。Ying Liu等(101)描述了TableSeer,一个表格搜索引擎。Table Seer可用于搜寻数字图书馆,检测文章中的表格,提取表格元数据,建立索引和排名表,并提供一个用户友好的搜索界面。他们提出了一个涵盖广泛的表格元数据集,以期为科学家和其他用户所采用来描述表格信息。总体而言,Table Seer消除了手工从数字图书馆中抽取表格数据的负担,使用自动抽取表格的方法。
3.7.4 地理空间元数据自动抽取
地理空间元数据长期以来对地理空间数据集的管理起着重要作用。通常被用来在内部组织、维护和记录地理资源,元数据也可以作为载体为外部揭示数据资产,促成网上地理信息的交流活动。尽管这种地理空间代理有许多好处,但它也同时有很多问题和障碍。James K.Batcheller(102)通过对专有的地理信息系统(Geographic Information System,GIS)进行改进,提出了旨在减少生成地理空间元数据相关的工作量为目标的方法。通过与数据准备、管理和文档相结合的方法,来减轻地理空间元数据生成的障碍,同时促进数据的安全保障系统管理。目前的原型,基于对23个DC核心元素在地理空间模型的扩展,可以生成20项基本元数据元素。虽然不可能完全不需要手工操作,但这样一个数据集计算环境对地理空间元数据的自动化生成有重要作用和潜力。袁平等(103)设计了一种针对GIS空间数据的元数据自动提取生成技术体系,该体系的主要思路是利用W indows系统提供的编程接口、应用系统的接口插件、ODBC或JDBC接口、Geotiff格式的卫星遥感影像文件等工程文件、直接提取等途径,从计算机操作系统、数据处理/应用系统、数据库管理系统、GIS系统等提取CSDGM标准对应的数据项。
3.8 用户参与的元数据构建
标注正在迅速成为人们组织和管理数字信息的主要方式之一。标注在用户的个人计算机和网上都是对传统信息组织工具的一个补充,标签对信息管理、信息架构和界面设计有着广泛影响,其覆盖范围大大超出这些技术领域而延伸到我们的生活中。社会化标注系统已经在互联网上成为Web 2.0现象的一部分。
3.8.1 学术标注系统的标签分析
学术社会标注系统,如Connotea和CiteULike,为研究人员提供了一个用关键字(标签)来组织个人在线参考文献集合,并与他人分享这些文献的方法。这些系统的效果之一是产生一个描述集合资源的、大型的、公开访问的元数据仓储库。鉴于生命科学信息的快速增长和利用元数据来提高信息的价值,这些仓储库为应用开发提供了具有潜在价值的新资源。Benjamin等(104)描述了两个通过协同标注生成的科学元数据标记仓储库。这项调查有助于了解当前协同构建的元数据应如何使用的问题,以及对新的社会标注系统的设计提出建议。
Elizeu等(105)分析了一种用于提高知识共享空间导航的模型,以两个用于管理科学学术文章的合作标签社群——CiteULike和Bibsonomy为研究对象,提出了其使用模式,重点研究了三个问题:①根据用户喜好,分析了标签活动的分布;②定义了新的计算用户兴趣相似度的指标,并用这些指标揭示了标签社群的结构,结果显示,社群的结构属性显示了一个清晰的用户兴趣分割,即大量用户具有自己独特的兴趣,而只有一部分核心用户具有共同的兴趣;③基于兴趣的标签社群的结构可以用于促进社群的内容检索与导航。
李爱国(106)介绍了RefWorks、Connotea和CiteULike三种学术标签系统的主要功能,比较分析三者之间的异同点。通过比较发现RefWorks是较好的书目信息创建工具,Connotea是组织参考文献、发现新线索、与他人共享知识的利器,而CiteULike则是一种组织学术论文的免费在线服务。
3.8.2 将大众标注标签转化成语义元数据
越来越广泛应用的社会标签对元数据研究既是机遇又是挑战。如何充分利用这一新的信息内容来增进信息的表示和检索,一个关键的挑战是从社会标签中抽取语义关系,形成语义元数据。M iao Chen等(107)利用Flickr标签为例证,通过实验提出了一种利用丰富的社会语义来增强主题元数据的方法。该过程包括4个步骤:①收集Flickr标签;②通过互信息来计算标签间的共现;③利用谷歌搜索结果来跟踪标签对的背景信息;④应用自然语言处理和机器学习技术来提取标签间的语义关系。实验从谷歌搜索结果中建立了上下文背景句子集,然后用自然语言处理和机器学习算法来处理。这种新方式在获取标签间的语义关系的准确率上相当不错。
社会标注系统由许多普通用户用自由形式的字符串(标签)来注释对象,该系统最近成为标记和组织大量数据集合的一个强大的方法。Heymann和Garcia-Molina(108)在对这类系统的调查中发现了一个将标注系统中的标签转换成可导航的、具有等级结构的标签分类词表的简单但非常有效的算法,并提出一个初步的模型来解释为什么这类系统如此有效。
语义网本体是自适应E-Learning系统中建立学习资源元数据的主要途径之一。这种方法的局限性是它通常不对标注者提供支持,或标注者在学习本体元数据领域和技术时要花很大精力。Bateman等(109)针对这些不足,通过整合应用在备受欢迎的社会标注网站如del.icio.us的技术和通过对自然语言本体的扩展,实现了一个简单的元数据编辑系统,同时保持轻便本体的表达力。这种方法的目的是对元数据的新的创造者(如学生)生成机器可操作的学习对象的元数据时有所帮助。
社会标注系统如Flickr,Del.icio.us,Technorati,Connotea和Library Thing,提供一个以社区为导向的对网络信息和资源进行分类的方法,从而使这些信息可以被浏览、发现和再利用。虽然社会标注网站提供简单的、用户相关的标签,但在元数据的质量和与传统索引系统相比的可扩展性上还是有问题。Hunter等(110)提出了一个混合的方法来把通过传统的编目方法生成的权威元数据和社区标注的标签合并。该HarvANA系统使用可扩展的标准RDF模型来表示注释和标签,并利用OAI-PMH从分布社区服务器中收获注释和标签。收获的注释和权威元数据集成在一起存储在一个集中的元数据库中。这项简化的、可互操作、可扩展的方法使图书馆、档案馆和仓储库能充分利用社会的热情参与者来标注和注释,增强这些馆和库的元数据,提高它们的数据发现服务。Hunter等还介绍了利用澳大利亚国家图书馆Picture Australia集中建筑图片库建立的社会标注系统来对HarvANA系统进行评价。
A l-Khalifa与Davis(111)提出了将大众标注标签转化为语义元数据的设想,他们开发了一种称为大众标注工具架构(Folks Annotations Tool A rchitecture,简称FAsTA)的映射工具。该工具处理匹配的过程一共有两步:一是标签抽取;二是传递的标准化与语义注释的标准化。具体过程为:①从书签网络资源中抽取大众标注的标签;②将这些标签传递到标准化过程中,并对它们进行一系列的过滤,以达到清理标签的目的。其中,过滤的程序包括小写标签过滤、非英语标签过滤、词干过滤、歧义标签过滤、标签分组过滤;③标准化的过程是自动完成的,对清理标签冗余非常有用;④对标准化的标签进行语义注释处理,即每个标准化的标签被映射成相应的语义元数据,该语义元数据可以作为网络资源的描述符。A l-Khalifa与Davis采用调查问卷法对该映射框架所产生的元数据的代表性、可用性和正确性进行了定性分析,而且,评估结果证明了该映射框架的可行性与有效性。
人们对在社会标注系统上表示和分享标注数据有着日益增加的兴趣,但是传统的标注并不特别适合协同。作为自由文字关键词,它们受语言和人为变化的影响,如大小写、单复数和拼写错误。同时标注因人而异,没有在同义词、词形变化和其他因素上进行统一。这使得标注实际上没有语义。Hak Lae Kim等(112)描述了在语义层上描述标签的方法,并讨论了对现有标签本体的比较和它们的优缺点。
3.9 元数据与语义网
元数据是实现语义网的基本组成部分。近五年来,随着语义网研究的加强,对元数据的语义方面的研究也不断加强。
3.9.1 DC的语义化
从2008年起,DCM I在定义它的特征时增加了形式定义域和值域。为了不影响RDF中已经实现的“简单DC”,这些增加的特性还没有加到DC命名空间(dc:namespace http://purl.org/dc/elements/1.1/)的15个元素里。相反,一个新的命名空间dcterms:namespace(http://purl.org/dc/terms/)被建立起来,并同时包含有与15个DC元数据元素集1.1版同名的元素集。这15个新的元素集成为DCMES1.1版中元素的子元素,而且它们的定义域和值域的赋值在DCM I元数据词表(DCM IMetadata Terms)中有详细描述(113)。
3.9.2 知识组织系统中的元数据
A listairM iles(114)讨论了将简单知识组织系统(Simple Knowledge Organization System,SKOS)发展成W3C推荐中的三个问题。第一,SKOS的核心目标和范围是什么?第二,基于SKOS的软件模块有哪些?它们如何相互作用?第三,SKOS的更广泛的技术和社会背景是什么?它们对设计目标有什么影响?A listair M iles认为SKOS的范围应限定为受控结构词表的形式表示在检索中的应用,并描述了激发SKOS设计的一些假设和设想。
Corey A.Harper(115)探讨当按SKOS项目的快速指南来在语义网上发布叙词表时,如何用XSLT样式表把国会图书馆主题词表(LCSH)规范记录从MARC/XML或MADS/XML格式转换到RDF文档。创建一个RDF数据存储库来表示LCSH的内容将对开发能充分利用国会图书馆主题词表中概念间关系的应用系统有长远的影响。
3.9.3 Web 3.0
语义网和Web 2.0的结合是社会语义网(social semantic network)又叫Web 3.0。在社会语义网络中,可以形式化表示的部分语义能通过语义网技术来表示和推理,同时也能通过社会的、面向社区的Web 2.0的技术来维护,这种组合是很有力的。社会语义网使得人类社会不同群体里特殊语义上的微妙变化可以通过Web 2.0用户友好的协同机制而得到管理,同时还能利用语义网来保持精确的表达和推理能力。通过利用网上数据间的语义关系,新的应用系统可以用来自动找寻和合成信息,执行基本推理,以及通过改变表示来适应不同的用户需求。
Peter等(116)讨论了社会语义网如何可以在E-科学(E-Science)的情况下为社会科学研究人员提供帮助。他们描述了一个建在社会语义网技术的叫“ourSpaces”的虚拟研究环境。此环境利用最近发展的科学技术来产生增强的社会图表示,并在本体和自由分类法相集成的基础上建立一个元数据框架。他们还描述了一个查询这种混合元数据表示的自然语言接口。
MatthiasMenger和Maria Rüther(117)介绍了由德国联邦环境局开发的语义网服务SNS的目的、技术和前景。该服务已被集成并应用到若干环境和地理信息系统中。SNS提供了分享受控环境词汇和增强检索环境信息系统的性能。
3.10 元数据应用
国内外学者对元数据应用的研究进展主要体现在如下方面:数字图书馆、文化遗产保存、数字研究、电子政务、教育资源组织等。
3.10.1 元数据在数字图书馆中的应用
元数据可以用于支持数字图书馆的可视化界面,叫做元数据增强的可视化界面(Metadata Enhanced Visual Interfaces)。Shiri(118)对21个基于元数据构建的数字图书馆可视化界面从以下角度进行了探讨:①支持信息获取和检索功能;②使用的元数据元素;③可视化技术的利用。结果显示,基于元数据的数字图书馆可视界面正变得越来越普遍,可视化技术越来越成为支持用户信息检索的普遍设计战略。
数字图像文件和元数据是数字化档案管理中两个重要的因素。但由于元数据和图像文件是相互独立的,数字化档案管理就变得很困难。Cjien-cheng Liu和Chao-chen Chen(119)利用对文件中嵌入的元数据扩展来达到开发元数据存储和交换的目的,以开发嵌入元数据框架(Embedded Metadata Framework,EMF)作为在数字档案系统里嵌入元数据的参考平台。
3.10.2 元数据在文化遗产保存中的应用
保存历史文化遗产需要对文物的当前状态和所处环境进行认真的监测。利用DC核心元素,Fenella和M ichael(120)建立了一个以纺织品长期保存为目标的网上纺织品数据库标准。动态元数据和分类标准也纳入到此标准里,以便灵活地记录文物和所处环境的不断变化和文物在其生命周期里的老化。DC是记录有关文物和环境条件的变化状态信息的数据集的基础。有了DC作为共同的元数据标准,这些长期保存的关键知识可以被科学家和保护者利用来确定减缓老化速度的最佳条件,以及与其他文物保存进行比较。
3.10.3 元数据在数字研究中的应用
Jacques等(121)分析了法国研究界对元数据的实践和需求,以博士学位论文为研究对象,因为博士论文的生命周期是完全由科研机构来控制的。他们利用建立针对数字研究(E-Research)的研究政策为例,对几个仓储库的基本功能进行案例分析,以期为ARTIST——一个合作式的数字研究平台的元数据建设和完善新的功能提供帮助。进化领域数字信息和数据仓储库(DRIADE)是一个正在进行的通过获取、保存、共享和再使用进化生物学领域异构数据的系统。元数据是DRIADE信息体系结构的基本组成部分之一。Jane Greenberg等(122)报告了关于DRIADE的总体目标。DRIADE的研发分三个阶段,并有一个元数据应用纲要。他们探讨了多种方法开发应用纲要的问题,其中包括需求评估、内容分析、映射分析。他们还讨论了通过DRIADE与其他方法相结合来实现科研与数据更紧密集成的可行性。
3.10.4 元数据在电子政务中的应用
E fthimios等(123)介绍了开发描述电子政务(E-Government)数字信息资源的元数据元素集的过程。他们设计了一个能尽可能利用现有电子政务元数据应用纲要标准的元数据模式,能方便政务资源的分类和储存,同时还能增强用户对公共信息的访问。他们对欧盟标准委员会CEN/ISSS开发的最初方法进行了扩展,建议分4个步骤来开发应用纲要:确定用元数据描述的资源,确定会使用元数据的用户群,确定每个用户群对元数据的使用,指定特定使用所对应的元数据元素。他们所提供的是一个能发现和访问分布在不同公共信息网站上的电子政务服务和信息的一揽子政务网上门户,为对电子政务资源感兴趣的研究人员、管理者等提供了一个路线图。
由互联网产生的连接开放服务为各个行政部门在网上形成联盟以提供综合增值服务提供了新的机会。然而,由于缺乏识别和对进一步服务的系统描述,这种复合电子政务的研发通常是临时的和不系统的。Fenareti等(124)演示了如何系统地利用拟议的服务描述表(Service DescriptionWorksheet)来开发复合的电子政务服务。电子政务服务可以被分类、检索和集成更大的群体。这一目标驱动的方法可以用来了解不同组织的需要,并利用声明性描述来表示各种功能特性的合作过程,适合在公共部门进行原型开发项目。在希腊的电子政务服务框架里,研究者分析了各种服务,填充了工作表数据库,并设计了相应的过程模型。
3.10.5 元数据在教育资源组织中的应用
许多作者认为,为了实现在多媒体学习单元的连贯性和灵活性,将不同的构件结构化成一个图是非常可取的。在一节课的图中,教育资源按照各自的元数据被封装成学习对象(Learning Object,LO),并通过不同类型的修辞和语义关系相互关联。这些图的学习对象被存储在仓储库中,并可被元数据检索出来。Olivier Motelet等(125)提出了结合检索学习对象的过程和编辑课程图形的方法。这一新框架扩展了传统的关键词和元数据搜索,利用储存在课程图结构中隐含的信息优势,使学习对象的检索更有效,查询表达更直观。对学习材料的检索由两个过程组成:①用户首先定义一系列教材内资料的拓扑位置,以及与其他部分的关系;②用户然后发出一个传统的关键词查询指令,在信息检索系统中考虑图的结构来进行检索。实验表明这种方法非常有效。Abdul等(126)建立了一个学习对象仓储(LOs),以调查学习对象的使用情况。他们重点考虑了学习对象的描述,并使用元数据与词表来增强这个描述,以提高学习对象的使用与重用。他们的初步调查表明,目前使用的各种元数据模式无法充分支持对学习对象的一些特殊特征的描述,例如粒度、可重用性等。然而,来自不同模式的特征可以结合起来,有效地支持学习对象的特殊性。为了平衡DC元数据设计的灵活性和其扩展元素与修饰词,他们集成了IEEE-LOM的一些元素来扩展DCM I-EDS元数据。他们主要探讨了集成IEEE-LOM和DCM I-EDS两种元数据模式的问题,建议增加用于描述粒度与可重用性的新术语。
4 元数据发展趋势
通过上述总结、分析可以看出,近五年来元数据研究进展主要集中在外文文献上,其特点可以概况为:①由于网络和数字图书馆的飞速发展,现有的一些元数据标准在某些方面不太适应,需要根据新的环境进行修订,因此一些广泛使用的元数据如DC、MODS、ONIX、CDWA、VRA等在近五年都有新的版本产生。同时,各个国家在各个领域也都制定了一些新的元数据标准。此外,在新环境下,新的元数据类型不断出现,如描述自然科学数据资源的科学元数据,描述某种情景下用户行为的情景敏感元数据,将元数据与分面分类法相结合的分面元数据等。②元数据尽管产生于图书馆领域,是数字图书馆建设的重要基础性工作,但近几年其他领域也非常重视元数据研究,如在电子政务、教育、地理空间、气象、生物医药、古籍研究、电子通信等领域也产生了一批专门针对该领域的元数据研究。③为了使元数据的发展能与数字资源发展保持协调一致,对元数据的维护,尤其是网络资源元数据维护的研究越来越吸引学者的注意;由于元数据格式进一步多元化,元数据体系变得更加复杂,为了使元数据的功能更加完善,对元数据的管理提出了新的要求。④元数据各种格式之间的整合、互操作仍然是研究者重点关注的问题,同时也是未来的重点研究方向。⑤网络环境下,仅靠专业人员来完成元数据的生成是巨大的挑战,因此,元数据的自动生成和依靠用户参与来创造元数据成为近五年来元数据研究的一个重要方向。⑥元数据在网络信息组织中的应用更加广泛和深入,尤其是Web 2.0环境下,利用元数据来构建本体和语义网是非常重要的研究内容。
然而,我国在元数据研究领域与国外还有一定的差距,尤其是在新的网络环境下,对于元数据的创新研究还有待加强。因此,我们有很多要学习和借鉴的地方。我国在元数据方面的研究存在的问题可以总结为:①缺乏创新性的理论研究。我国元数据研究的论文数量不少,但纵观这些文章,大多数是介绍性的、翻译性的,或综述性的,在元数据理论创新上很欠缺。②元数据国家标准的制定与推广亟待加强。尽管我国正在进行数字图书馆标准规范的研究,但还没有出台国家标准,各个数字图书馆的建设仍然存在“信息孤岛”的现象。因此对于元数据国家标准的制定还需加快速度,同时,还应注重标准规范的推广与应用。③对于新的网络环境下元数据的新发展研究较欠缺。新的网络环境下,出现的一些新型元数据,如情景敏感元数据等,我国在这方面的研究几乎还没有。关于Web 2.0环境下元数据的一些新变化,如元数据自动抽取、元数据与语义网、社会标注等新的应用,我们应该抓住契机。
2010年恰逢DC元数据诞生15周年,研究者们希望借此机会对过去15年元数据的研究与应用进行总结,同时探索未来元数据的发展方向,通过元数据的设计与开发使其更努力地工作(make metadata work harder),以此来服务于人们的信息需求。下面我们以2010年10月即将在美国匹兹堡召开的DC-2010年年会的会议议题来总结元数据的未来发展趋势(127):
(1)元数据的原则、指导方针和最佳实践;
(2)元数据的质量、标准化、改善和映射;
(3)元数据概念模型和框架(例如RDF、DCAM,OAIS);
(4)元数据应用纲要;
(5)跨领域、跨语言、跨时间、跨结构、跨规模的元数据互操作;
(6)跨领域元数据使用(例如记录、保存、巩固、机构库、出版等);
(7)领域元数据建设(例如合作、文化遗产保存、教育、政府、科学研究领域等);
(8)书目标准(例如RDA、FRBR、主题词表等)作为语义网词汇;
(9)元数据的可获取性;
(10)元数据在科学数据、电子科学与网格中的应用;
(11)社会标签和用户参与建设的元数据;
(12)知识组织系统(例如本体、分类法、自由分类法、叙词表等)和简单知识组织系统(SKOS);
(13)本体设计与开发;
(14)元数据和本体的集成;
(15)元数据生成(方法、工具和实践);
(16)搜索引擎和元数据;
(17)语义网元数据和应用;
(18)元数据词汇注册和登记服务。
所有这些发展方向和主题揭示着元数据的研究已经深入到当代信息处理的方方面面,日益起着支撑和引导的作用。但同时元数据的研究还远未成熟,我国在其将来的发展中迎头赶上,是大有可为的。
【作者简介】

吴丹,管理学博士,讲师。管理学与理学双学士、工学硕士,2008年毕业于北京大学情报学专业,2006—2007年赴美国匹兹堡大学信息科学学院联合培养,后进入武汉大学从事博士后研究。为本科生开设元数据、信息系统、信息检索课程。研究方向为信息检索、多语言信息处理、信息组织、元数据、数字图书馆等。2000年以来在国内外发表专业论文50余篇,其中被SCI检索3篇,被EI检索10余篇。独立撰写和参与编写著作3部。主持国家社会科学基金、教育部人文社会科学研究等纵向项目8项。
【注释】
(1)本文系第四十五批中国博士后科学基金的研究成果之一,项目编号: 20090451078。
(2)中国互联网络信息中心[EB/OL].[2010-05-18].http:// www.cnnic.net.cn.
(3)Digital Libraries:Metadata Resources[EB/OL].[2010-05-18].http://archive.ifla.org/II/metadata.htm.
(4)Metadata:A lways More than You Think[EB/OL].[2010-05-18].http://www.ala.org/ala/mgrps/divs/pla/plapublications/platechnotes/metadata.cfm.
(5)DC Conference[EB/OL].[2010-05-18].http://dublincore.org/workshops.
(6)Google Books[EB/OL].[2010-05-18].http://books.google.com.
(7)Amazon[EB/OL].[2010-05-18].http://www.amazon.com.
(8)Library of congress[EB/OL].[2010-05-18].http://www.loc.gov/ index.html.
(9)指针图书搜索[EB/OL].[2010-05-18].http://www.zhizhen.com.
(10)当当网[EB/OL].[2010-05-18].http://www.dangdang.com.
(11)中国国家图书馆[EB/OL].[2010-05-18].http://opac.nlc.gov.cn.
(12)Murtha,B..Introduction to Metadata[M].2nd ed.USA:Getty Research Institute Publication,2008.
(13)Marcia,L.Z.,Jian,Q..Metadata[M].UK:Facet Publishing,2008.
(14)Jia L..Metadata and ItsApplications in theDigital Library:Approachesand Practices[M].USA:Libraries Unlimited,2007.
(15)Susan,S.L.,Jean,W..Metadata and Its Impact on Libraries[M].USA:Libraries Unlimited,2006.
(16)M iguel-Aagel,S.,M iltiadis,D.L..Metadata and Semantics[M].USA:Springer,2008.
(17)Gene S..Tagging:People-powered Metadata for the SocialWeb[M].USA:New Riders,2008.
(18)肖珑,赵亮.中文元数据概论与实例[M].北京:北京图书馆出版社,2007.
(19)缪其浩.元数据与图书馆[M].上海:上海科学技术文献出版社,2005.
(20)A lemneh,D.G..An Examination of theAdoption ofPreservationMetadata in CulturalHeritage Institutions:An Exploratory Study Using Diffusion of Innovations Theory[D].USA:University ofNorth Texas,2009.
(21)A l-Khalifa,H.S..Automatic Document-levelSemantic Metadata Annotation Using Folksonomies and Domain Ontologies[D].UK:University ofSouthampton,2007.
(22)Lai,C.W..Metadata forPhonograph Records:Facilitating New Forms of Use and Access[D].Canada:M cGillUniversity,2007.
(23)Polydoratou,P..Use and Functionality of Metadata Registry Systems[D].UK:The City University,2006.
(24)National Science Foundation[EB/OL].[2010-05-18].http:// www.nsf.gov.
(25)Institute ofMuseum and Library Service[EB/OL].[2010-05-18].http://www.imls.gov/applicants/applicants.shtm.
(26)国家自然科学基金委员会[EB/OL].[2010-05-18].http:// www.nsfc.gov.cn/Portal0/default124.htm.
(27)全国哲学社会科学规划办公室[EB/OL].[2010-05-18].http:// www.npopss-cn.gov.cn.
(28)Dublin Core Metadata Element Set,Version 1.1[EB/OL].[2010-05-30].http://dublincore.org/documents/dces.
(29)Description ofMODS 3.4 Changes[EB/OL].[2010-05-30].http:// www.loc.gov/standards/mods/mods-outlineChanges-3-4.html.
(30)ONIX 3.0 Released in April 2009[EB/OL].[2010-05-30].http:// www.editeur.org/83/Overview.
(31)Categories for the Description of Works of A rt(CDWA)[EB/OL].[2010-05-30].http://www.getty.edu/research/conducting_research/standards/ cdwa/introduction.html.
(32)VRA Core 4.0[EB/OL].[2010-05-30].http://www.vraweb.org/ projects/vracore4.
(33)Designing a NationalStandard for Discovery Metadata Improving Access to Digital Information in the Dutch Government[EB/OL].[2010-05-30].http:// www.rand.org/pubs/technical_reports/TR185.
(34)中国数字图书馆标准规范建设[EB/OL].[2010-05-30].http:// cdls.nstl.gov.cn.
(35)Abdurrahman,A..An Overview of E-governmentMetadata Standards and Initiatives Based on Dublin Core[J].Electronic Journal of e-Government,2009,7(1):1-10.
(36)国家标准化管理委员会.政务信息资源目录体系第3部分核心元数据(GB/T21063.3—2007)[S].北京:中国标准出版社,2007.
(37)周新忠等.关于地理空间元数据技术发展趋势的理论探讨[J].测绘科学,2007(2):172-175.
(38)Pamment,J.A..Climate and Forecast(CF)Metadata Conventions:A Community Driven Metadata Standard[C].Data Management Advisory Group(DMAG)Workshop,17-18 February 2009,Thame,Oxfordshire,United Kingdom.
(39)胡文超,等.气象元数据应用研究进展[J].干旱气象,2008(4): 12-15.
(40)Schrim l,L.M.,A rze,C.,Nadendla,S.,et al..GeM InA,Genomic Metadata for Infectious Agents,A Geospatial Surveillance Pathogen Database[J].Nucleic AcidsResearch,2010(38):754-764.
(41)张婧.拓片元数据标准比较研究[J].中国图书馆学报,2010(1):52-55.
(42)姜晓曦,孙坦.2007年国外元数据研究进展[J].图书馆建设,2009(4):107-112.
(43)CAMA 2006 Website[EB/OL].[2010-06-10].http:// www.cs.kuleuven.be/groups/hmdb/cama2006.
(44)CAMA 2007 Website[EB/OL].[2010-06-10].http:// www.cs.kuleuven.be/groups/hmdb/cama2007.
(45)EUAM 2009 Website[EB/OL].[2010-06-10].http:// euam.fit.fraunhofer.de.
(46)Jehad,N.,Martin,W.,Erik,D..Attention Metadata:Collection and Management[EB/OL].[2010-06-10].http://citeseerx.ist.psu.edu/viewdoc/ download?doi=10.1.1.61.7010&rep=rep1&type=pdf.
(47)Joona,L.,Claudia,R.,Inge,M..Modeling Tasks:A Requirements Analysis Based on Attention SupportServices[EB/OL].[2010-06-10].http:// www.cs.kuleuven.be/groups/hmdb/cama2007/papers/cama07-Laukkanen.pdf.
(48)Joe,P..Measuring Audience Attention Across Multip le Channels for A NewWeb Site[EB/OL].[2010-06-10].http://www.cs.kuleuven.be/groups/ hmdb/cama2007/papers/cama07-pagano.pdf.
(49)Martin,M.,Andreas,D..Sharing Contextualized Attention Metadata to Support Personalized Information Retrieval[EB/OL].[2010-06-10].http:// www.cs.kuleuven.be/groups/hmdb/cama2007/papers/cama07-memmel.pdf.
(50)Eleftheria,T.,Peter,J.S.,Kevin,A Q..Attention Metadata Visualizations:Plotting Attendance and Reuse[EB/OL].[2010-06-10].http:// www.cs.kuleuven.be/groups/hmdb/cama2007/papers/cama07-elia.pdf.
(51)W iley,D.,Ball,J..OsmoseRSS:A System for Absorbing Attention Metadata[EB/OL].[2010-06-10].http://portal.acm.org/ftgateway.cfm? id=1183605&type=pdf.
(52)李书宁,张晓林.国外情景化注意元数据的研究进展[J].现代图书情报技术,2008(2):1-7.
(53)Flamenco Demos[EB/OL].[2010-06-10].http://flamenco.berkeley.edu/demos.html.
(54)Fenareti,L.,Yannis,C.,Demetrios,S.,et al..E-governmentServices Composition Using Multi-faceted Metadata Classification Structures[J].Electronic Government,2007:116-126.
(55)郭世新,刘磊.分面元数据及其技术探讨[J].大学图书馆学报,2008(3):23-27.
(56)Sufi,S.,Matthews,B..AMetadataModel for theDiscovery and Exploitation of Science Studies[M]//Knowledge and Data Management in Grids.US: Springer,2007:135-149.
(57)科学数据共享工程[EB/OL].[2010-06-10].http://www.sciencedata.cn/index.php.
(58)Leblanc,J.,Kurth,M..An OperationalModel for LibraryMetadataMaintenance[EB/OL].[2010-06-10].http://www.accessmylibrary.com/article-1G1-180907166/operational-model-library-metadata.html.
(59)Kurth,M.,Leblanc,J..Toward a Collection-based Metadata MaintenanceModel[C].Proceedings of the2006 InternationalConference on Dublin Core and Metadata Applications:Metadata for Knowledge and Learning,Mexico,October 03-06,2006:31-41.
(60)Jin,M.,ManagingMetadata forDigitalProjects[J].Library Collections,Acquisitions,and Technical Services,2006,30(1-2):3-17.
(61)Brian,F.L..Premis with a Fresh Coat ofPaint:H ighlights from the Revision of the Premis Data Dictionary for Preservation Metadata[J].D-Lib Magazine,2008,14(5/6).[2010-06-10].http://webdoc.sub.gwdg.de/edoc/aw/ d-lib/dlib/may08/lavoie/05lavoie.html.
(62)Vuong,B.Q.,Lim,E.P.,Chang,C.H.,et al..Key Element-contextModel:An Approach to EfficientWeb MetadataMaintenance[C].Proceedings of ECDL'2007.Brussels,Hungary:Brussels,2007:63-74.
(63)Ammgo Project[EB/OL].[2010-06-10].http://ils.unc.edu/mrc/ ammgo.
(64)Phokion,G.K..SchemaMappings,Data Exchange,and MetadataManagement[C].Proceedings of the Twenty-fourth ACM SIGMOD-SIGACT-SIGART Symposium on Principles ofDatabase Systems,Baltimore,Maryland,2005:61-75.
(65)Paolo,M.,et al..Requirements and Services for Metadata Management[J].InternetComputing,2007,11(5):17-25.
(66)Catarci,M iller.Guest Editorial:Special Issue on Metadata Management[J].The International Journal on Very LargeData Bases,2008,17(6).
(67)Patricia,J.R.,Shu,L.,Nancy,H.,et al..Colorado State University Libraries[J].Journal of LibraryMetadata,2008,8(4):315-339.
(68)Ewa,D.,Bruce,B.,Ann,C.,et al..Chapter12:Metadata and ProvenanceManagement[EB/OL].[2010-06-10].http://arxiv.org/ftp/arxiv/papers/ 1005/1005.2643.pdf.
(69)张魁.电子文件生命周期中的元数据管理[J].兰台世界,2006(5):28-29.
(70)黄如花,刘贵玉.开放存取资源元数据管理的对策[J].情报理论与实践,2009(10):5-8.
(71)刘仲,周兴铭.基于目录路径的元数据管理方法[J].软件学报,2007(2):236-245.
(72)孙莉,於建华,徐燕萍,吴素芹.基于本体的语义元数据管理[J].计算机工程与设计,2008(16):4371-4373.
(73)Kawashima,H.,H irota,Y.,Satake,S.,et al..MeT:A Real World Oriented MetadataManagementSystem forSemantic SensorNetworks[C].Proceedings of the 3rdWorkshop on DataManagement for Sensor Networks:in Conjunction with VLDB,Seoul,Korea,September 11-13,2006:13-18.
(74)杜楠,彭宏.混合式的元数据管理系统研究[J].计算机工程与设计,2009(15):3624-3626,3630.
(75)胡昊,李小文,刘素红.基于J2EE的元数据管理系统的设计与实现[J].计算机应用研究,2007(5):198-199,203.
(76)张秀坤.基于知识的元数据管理系统的研究[J].长春工程学院学报:自然科学版,2006(4):64-66.
(77)朱培毅.基于XML的图书元数据管理系统设计[J].全国新书目,2006(15):73-75.
(78)高国伟,王延章,王宁.基于元数据管理模型的电子政务公文系统应用研究[J].现代图书情报技术,2008(6):28-33.
(79)Haslhofer,B.,K las,W..A Survey ofTechniques forAchievingMetadata Interoperability[J].ACM Computing Surveys,2000,42(2):1-37.
(80)Lois,M.C.,Marcia,L.Z..Metadata Interoperability and Standardization—A Study of Methodology Part I and Part II:Achieving Interoperability at the Schema Level[J/OL].D-Lib Magazine,2006,12(6).[2010-06-10].http://www.dlib.org/dlib/june06/chan/06chan.html.
(81)张东.论元数据互操作的层次[J].情报理论与实践,2005(6): 648-650.
(82)朱超.关于元数据互操作的探讨[J].情报理论与实践,2005(6): 648-647,655.
(83)申晓娟,高红.从元数据映射出发谈元数据互操作问题[J].国家图书馆学刊,2006(4):51-55.
(84)毕强,朱亚玲.元数据标准及其互操作研究[J].情报理论与实践,2007(5):666-670.
(85)孔庆杰,宋丹辉.元数据互操作问题技术解决方案研究[J].情报科学,2007(5):754-758.
(86)Jackson,A.S.,Han,M.,Groetsch,K.,et al..Dublin CoreMetadata Harvested through OAI-PMH[J].Journal of Library Metadata,2008,8(1):5-21.
(87)郑志蕴,宋瀚涛,牛振东.数字图书馆元数据互操作机制的研究[J].计算机应用,2005(3):699-702.
(88)毕强,韩毅.语义网格环境下基于元数据本体的数字图书馆互操作研究[J].图书情报工作,2009(15):17-20,82.
(89)Kakali,C.,Lourdi,I.,Stasinopoulou,T.,et al..Integrating Dublin CoreMetadata for Cultural Heritage Collections Using Ontologies[C].Proceedings of the 2007 InternationalConference on Dublin Core and Metadata Applications:Application Profiles:Theory and Practice,Singapore,August27-31,2007:128-139.
(90)王芳,王小丽.基于OA I协议的数字档案馆元数据互操作问题研究[J].现代图书情报技术,2007(3):18-24.
(91)Bountouri,L.,Papatheodorou,C.,Soulikias,V.,etal..Metadata Interoperability in Public Sector Information[J].Journal of Information Science,2009,35(2):204-231.
(92)Jian-Hui,L.,Jia-X in,G.,Ji-Nong.D.et al..A Metadata Registry for Metadata Interoperability[J].Data Science Journal,2007(6):379-384.
(93)潘定,沈钧毅.数据仓库元数据互操作性技术研究进展[J].情报科学,2005(10):1595-1599.
(94)周亚.2001—2008年国内元数据自动抽取研究综述[J].科技情报开发与经济,2009(23):140-142.
(95)Lin,X.,Li,J.,Zhou,X..ThemeCreation forDigitalCollections[C].Proceedings of the 2008 InternationalConference on Dublin Core andMetadata Applications,Berlin,Germany,2008:34-42.
(96)Yunhua,H.,Hang,L.,Yunbo,C.,et al..Automatic Extraction of Titles from GeneralDocuments Using Machine Learning[J].Information Processing&Management,2006,42(5):1276-1293.
(97)于志敏,谢丽聪,韩晓芸.Web元数据信息提取技术的研究[J].微计算机信息,2008(33):232-233.
(98)郭瑞华,张玉莉.语义Web上DC元数据的描述及抽取技术[J].现代情报,2005(6):212-214.
(99)Sue,Y.S.,M ichael,B.S..Can a System Make Novice Users Experts? Analysis ofMetadata Created by Novices and Experts with Varying Levels of Assistance[J].International Journal of Metadata,Semantics and Ontologies,2008,3(2):122-131.
(100)Carl,S.,M ichael,E.,Darryl,G.,et al..Biblio:Automatic Metadata Extraction[J].International Journalon DocumentAnalysisand Recognition,2007,10(2):113-126.
(101)Liu,Y.,Bai,K.,M itra,P.,et al..Table Seer:Automatic TableMetadata Extraction and Searching in Digital Libraries[C].Proceedings of the 7th ACM/IEEE-CS JointConference on Digital Libraries,Canada,2007:91-100.
(102)James,K.B..Automating Geospatial Metadata Generation—An Integrated DataManagement and Documentation Approach[J].Computers&Geosciences,2008,34(4):387-398.
(103)袁平,韩景润,党海飞.空间元数据自动生成技术研究[J].地理信息世界,2005(1):11-15.
(104)Benjamin,M.G.,Joseph,T.T.,Mark,D.W..Social Tagging in the Life Sciences:Characterizing a New Metadata Resource for Bioinformatics[J].BMC Bioinformatics,2009(10):313.
(105)Elizeu,S.,Matei,R.,Adriana,I..Tracking Usage in Collaborative Tagging Communities[EB/OL].[2010-06-10].http://www.cs.kuleuven.be/ groups/hmdb/cama2007/papers/cama07-elizeu.pdf.
(106)李爱国.三种学术标签系统的比较分析[J].图书情报工作,2007(2):114-116.
(107)Chen,M.,Liu,X.,Qin,J..Semantic Relation Extraction from Sociallygenerated Tags:A Methodology for Metadata Generation[C].Proceedings of the 2008 International Conference on Dublin Core and Metadata Applications,Berlin,Germany,2008:117-127.
(108)Heymann,P.,Garcia-Molina,H..Collaborative Creation of Communal H ierarchical Taxonomies in Social Tagging Systems[EB/OL].[2010-06-10].TechnicalReport.Stanford.http://ilpubs.stanford.edu:8090/775.
(109)Bateman,S.,Brooks,C.,M ccalla,G..Collaborative Tagging Approaches for OntologicalMetadata in Adaptive Elearning Systems[C].Proceedings of the Fourth InternationalWorkshop on Applications of SemanticWeb Technologies for E-Learning(SW-EL 2006)in Conjunction with 2006 International Conference on Adaptive Hypermedia and AdaptiveWeb-Based Systems(AH2006),Dublin,Ireland,2006:3-12.
(110)Hunter,J.,Khan,I.,Gerber,A..Harvana:Harvesting Community Tags to Enrich Collection Metadata[C].Proceedings of the 8th ACM/IEEE-CS JointConference on Digital Libraries(JCDL'08),Pittsburgh,USA,2008:147-156.
(111)A l-Khalifa,H.S.,Davis,H.C..FAsTA:A Folksonomy-based Automatic MetadataGenerator[C].Proceedings ofEC-TEL 2007-Second European Conference on Technology Enhanced Learning.German:Springer,2007:414-419.
(112)Hak,L.K.,Simon,S.,John,G.B.,et al..The State of the Art in Tag Ontologies:A Semantic Model for Tagging and Folksonomies[C].Proceedings of the 2008 International Conference on Dublin Core and Metadata Applications.Berlin,Germany,2008:128-137.
(113)DcmiWebset[EB/OL].[2010-06-15].http://dublincore.org/documents/dces.
(114)A listairM..SKOS:Requirements for Standardization[C].Proceedings of the 2006 International Conference on Dublin Core and Metadata Applications: Metadata for Knowledge and Learning.Manzanillo,Colima,Mexico,2006:55-64.
(115)Corey,A.H..Encoding Library ofCongress SubjectHeadings in SKOS: Authority Control for the SemanticWeb[C].Proceedings of the 2006 International Conference on Dublin Core and Metadata Applications:Metadata for Knowledge and Learning.Manzanillo,Colima,Mexico,2006:89-94.
(116)Peter,E.,Richard,R.,A lison,C.,et al..Building a Social Semantic Web for Escience[EB/OL].[2010-06-10].Association for the Advancement of A rtificial Intelligence.http://www.csd.abdn.ac.uk/~pedwards/research/pubs/ aaai-sss2009.pdf.
(117)MatthiasM.,Maria,R..The Semantic Network Service—Supporting Heterogeneous Environmental Information Systems[C].Proceedings of the2006 InternationalConference on Dublin Core and Metadata Applications:Metadata for Knowledge and Learning.Manzanillo,Colima,Mexico,2006:286-291.
(118)A li,S..The Use of Metadata in Visual Interfaces to Digital Libraries[M]//Research and Advanced Technology for Digital Libraries,Springer Berlin,Heidelberg,2007:489-494.
(119)Cjien-cheng,L.,Chao-chen C..Archiving and Management of Digital Images Based on an Embedded Metadata Framework[C].Proceedings of the 2009 International Conference on Dublin Core and Metadata Applications:Metadata for Know-ledge and Learning.Seoul,Korea,2009:71-84.
(120)Fenella,G.F.,M ichael,B.T..Developing CulturalHeritage Preservation Databases Based on Dublin Core Data Elements[C].Proceedings of the 2006 International Conference on Dublin Core and Metadata Applications:Metadata for Knowledge and Learning.Manzanillo,Colima,Mexico,2006:233-243.
(121)Jacques,D.,Jean-Paul,D.,Muriel,F.,et al..Metadata Towards an E-research Cyberinfrastructure:theCase of French phd Theses[C].Proceedings of the 2006 InternationalConference on Dublin Core and Metadata Applications:Metadata for Knowledge and Learning.Manzanillo,Colima,Mexico,2006:133-148.
(122)Jane,G.,Sarah,C.,Jed,D..The DRIADE Project:Phased Application Profile Development in Support ofOpen Science[C].Proceedings of the 2007 International Conference on Dublin Core and Metadata Applications:Metadata for Knowledge and Learning.Singapore,2007:35-42.
(123)Efthimios,T.,Nikos,M.,Constantina,C..M etadata for Digital Collections ofE-governmentResources[J].The Electronic Library,2007,25(2): 176-192.
(124)Fenareti,L.,Yannis,C.,Demetrios,S.,etal..E-GovernmentServices Composition Using Multi-faceted Metadata Classification Structures[C].Proceedings of the 6th InternationalConference on ElectronicGovernment,Regensburg,Germany,2007:116-126.
(125)Olivier,M.,Benjamin,P.,Georges,D.,et al..Enhancing Educational-materialRetrievalUsing Authored-Lesson[M]//String Processing and Information Retrieval.Springer Berlin,Heidelberg,2007:254-263.
(126)Abdul,H.A.,Abdus,S.C.,Christopher,S.G.K..Integrating Dublin Core and Learning ObjectMetadata forDescribing LearningObjects forEnhanced Reusability[C].Proceedings of the 2007 International Conference on Dublin Core and Metadata Applications:Metadata for Knowledge and Learning.Singapore,2007: 106-115.
(127)DC-2010Website[EB/OL].[2010-06-15].http://dc-2010.org.
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











