



5.1.1 英国国家语料库
英国国家语料库(British National Corpus,BNC)是牛津大学出版社、朗文出版公司、钱伯斯-哈洛普出版公司、牛津大学计算机服务中心、兰卡斯特大学英语计算研究中心(UCREL)以及大英图书馆等单位于20世纪90年代联合开发建设的大型语料库,耗资140万英镑,旨在加强英国信息技术的一项大规模的战略计划的一部分。整个工作于1991年1月开始,1994年完成,并于同年10月25日正式启用。该项目具体的负责人包括S.Murison Bowie、T.Benbow、J.H.Clear(牛津大学出版社)、D.Summers(朗文)、Geoffrey N.Leech、R.Garside(兰卡斯特大学)、S.Hockey(牛津大学计算中心)、L.D.Burnard(牛津文章档案库)、T.Cannon(英国图书馆)等学者。目前,该语料库的牛津大学出版社的光盘版(2.0)和兰卡斯特大学的网络版(http://bncweb.lancs.ac.uk/),涵盖书面语和口语的抽样内容,总词数达到98313429,其中书面语为87903571词,3140个文本;口语为10409858词,908个文本。BNC是单语语料库,其所搜集的语料是英国英语语料,创作性文本(Imaginative Texts)取自1960~1991年的文本;信息性文本(Informative Texts)为1975~1994年的文本;口语为1990~1994年的采样语料。
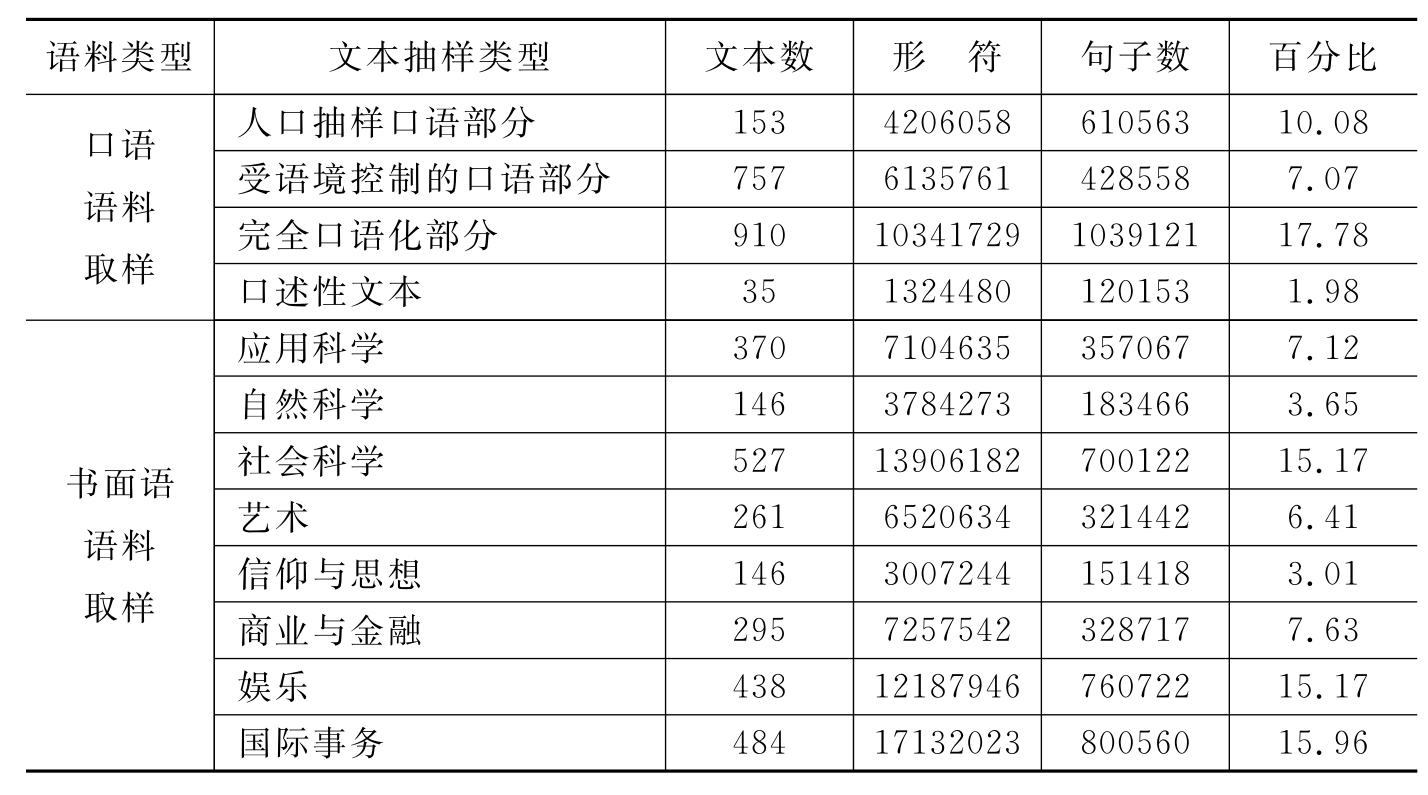
BNC语料库具有抽样的代表性,能够真正地反映语言的实际用法。由于本论文是研究科技英语文本中词语行为特征的异质性问题,所以笔者有针对性地选取了《应用科学》与《自然科学》两个书面语语料库的子库作为分析的语料,形符10888908,文本数为516个(见表5.1)。
BNC语料库最大的优势主要体现在它是经过三级标注,赋码错误率极低的文本语料库。这里所说的赋码是指在文本中给每一个词的词类特征和其他的相关语言特征附注计算机识别的语码符号。BNC采用了国际标准化标注语SGML体系下的文本标注规范系统TEI(Text Encoding Initiative)和目前互联网上通用的可扩展的简化文本标注规范系统XML。BNC使用由Roger Garside和Ian Marshall研制开发的CLAWS4增强版词性赋码器进行了自动标注(http://ucrel.lancs.ac.uk/claws/)。同时还使用由Steven Figelstone开发的模板赋码器(Template Tagger)对CLAWS4错标的语法码或多个备选码进行筛选。此外,对于少数的外来语易错的赋码,BNC语料库的设计者采用了人工标注的方法,以降低标注的错误率。BNC语料库的语法标注的准确率达到了98%~99%以上。因此,BNC语料库为词语行为特征研究提供了便利的操作平台。
表5.1 英国国家语料库的取样覆盖面
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











