



10.7 实验结果
10.7.1 叙词本体构建
首先,我们根据《中国图书馆分类主题词表》构建了“科学与科学研究”类目下的一部分叙词,由于是实验系统,因此我们并没有将所有的分类和术语都创建起来。而是选择了其中的一部分。其结构如图10-40所示:
在图10-40中,左边区域为叙词本体的类属结构:科学_科学研究——→情报学与情报工作——→情报学,情报检索;而中间区域则是类目下的实例,这里就是属于该类目的叙词,从图10-40可以看到,情报学下有24个叙词,而信息检索下有15个叙词;最右边是中间叙词所对应的关系,包括用(Y),代(D),属(S),分(F),参(C),族(Z)以及值属性,如中文术语等。

图10-40 用Protégé构建的叙词本体结构
10.7.2 信息抽取结果
实验系统从中国期刊网上抽取了近期的四百多篇关于情报学学科的文献,提取了最能描述文献主题的几个特征内容,包括标题,关键词,摘要以及学科导航。将抽取的结果保存到数据库中,如图10-41所示。
通过将这些文献信息与文献信息所对应的中国期刊网上的文献描述页面进行对比,可以看出抽取的结果是符合要求的。描述文献主题的标题,关键词,摘要以及学科导航是通过分析文献描述页面的特征,对页面代码进行HTML解析获取的。如果中国期刊网的文献描述页面上反映文献标题、关键词、摘要以及学科导航的特征发生了变化,则会导致抽取到的结果出错或者抽取不到信息。这是实验系统的一个缺陷,在信息抽取部分依赖于中国期刊网上文献描述页面中反映文献标题、关键词等信息的具体特征。通过对2008年和2009年中国期刊网文献描述页面进行调查分析,可以看出该页面的特征在2009年已经发生了变化。在当前,机器也无法考虑到这些特征变化的所有可能性,所以工作人员应该要根据文献页面特征的变化,及时地将变化捕捉,以保证信息的抽取准确、完整。实验系统信息抽取的信息源也只是局限在了中国期刊网。所以实验系统信息抽取部分应该要扩展信息源,对信息源及其特征进行仔细的分析,实现一个能抽取多个信息源的文献信息的功能较完善的组件。然而,在实验时间有限的情况下,在信息抽取部分我们建立了一个简单的模型,功能虽然比较局限且有待改进,但是已经满足了我们实验的需要。

图10-41 信息抽取结果
这些信息对之后的新词提取和关系提取都是很关键的。新词主要来自于关键词与标题中的词汇,而关系则主要是通过分析摘要中语句的结构来识别的。
10.7.3 新词提取效果
通过分离关键词以及对标题进行分词,得到了标题和关键词中所有的词汇并保存到数据库中。数据库保存了每一个词汇所在的文献编号以及出现的频率。频率的计算采取的方法是按照不同特征记以不同的权重。如果词语出现在标题中,记做1.0;如果出现在关键词中,记做0.5;如果出现在摘要,记做0.3。通过程序运行提取出了530个词汇。这里的词汇只包含满足叙词要求的名词类词语或短语,并且是非通用词汇。
评价实体抽取主要有准确率(P),查全率(R)以及F值三个指标。我们也可以将这三个指标应用到词语抽取上。这三个指标的定义如下:
 1
1
3
其中,N1表示正确识别的词语个数,N2表示被误识别到该类词语的个数,N3表示术语该类词语但是被误识别为其他类词语的个数。
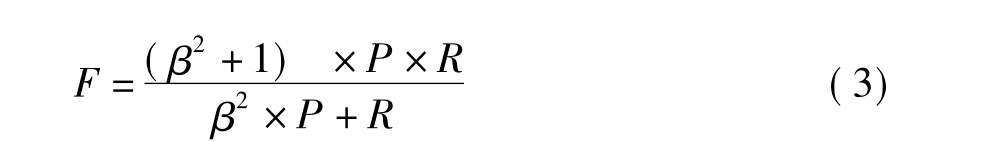
其中,参数β用来为准确率(P)和查全率(R)赋予不同的权重,当β取1时,准确率和查全率赋予相同的权重,实验中我们取β= 1。
通用词汇表是作者本人通过常识总结出的333个词语,由于知识水平和专业水平的限制,因此总结并不算全面,因此出现的词汇中仍然会有一些通用词汇。通过人工检查,仍有31个词汇不符合标准,因此正确率为:
P=(530-31)/530=94.15%。
关键词是文献作者在非常明确文献内容的前提下写的词汇或短语,即使其是新术语,系统也会认为其是一个术语,并且同时会判断这个新术语是否同时也出现在标题和摘要中,如果是,那么修改术语的出现频率,并将标题中的这个术语去掉后再进行分词。这样就可以避免将同一个术语进行多次分词,形成数个术语。通过这种处理方式,将叙词术语认定为是其他实体的可能性就降低了很多。但是也不排除分词系统辨别词性过程中,受分词文档的限制将一些名词认定为是非名词。通过人工对所抽取文献的标题进行分析,得出了有30个词语并未被系统识别出来。因此其查全率为:
R=(530-31)/(530-31)+30= 94.33%
F=(1+1)×94.15%×94.33%/(94.15%+94.33%)=94.24%
测试结果反映出抽取词汇的结果较令人满意。
通过比较频率,在本文中我们认为频率等于或大于5.0的词语可以认为该词达到一定广泛应用程度。而在这500多个词语当中,频率超过了5.0的仅有22个词汇,而每一个词语至少在4篇文献中出现过。由于构建的叙词本体的规模还不够,通过对比这些词汇与已有叙词本体,发现绝大多数都是新词,共有20个新词汇。
10.7.4 关系提取效果
这里的关系只抽取了新词与新词之间,新词与叙词本体中已有词之间的关系。而并没有提取叙词本体已有词之间的关系,因此存在着很大的局限性。这里也只对上述的两个关系进行检测。关系抽取的结果如图10-42所示。
在本系统中,如果一对词汇同时在两篇文献的摘要中出现过,那么就认为这一对词汇具有相关关系。使用这种方法,系统共抽取出了22个关系。其中有12组词汇对仅在两篇文献的摘要中出现过,而有7组在三篇文献的摘要中出现过,有2组同时出现在四篇文献中,只有1组同时出现在五篇文献的摘要中。通过句法结构的匹配,只有2个关系是“代”的关系。
通过人工分析这两组词汇对所在的语句,如图10-43所示。
这两组词汇对并不存在这样的“代”关系。由此可见,如果模板的正则表达式定义得不够规范,就会出现上面的情况,将不是属于这种关系的词汇对映射成了该关系。另外,模板方法还存在另外一个问题,即是模板的定义过于死板,一定要语句的结构与模板完全符合才能够匹配,因此很容易因为语句的不够规范,而漏掉很多该关系。并且实验系统中所用的模板过少,这样也会导致很多关系的漏选。所以在关系抽取部分关系的抽取方法仍需要改进,在采用了模板方法的情况下可以考虑结合其他方法同时使用,并且可以研究出模板自动学习的方法以丰富和更新模板库。

图10-42 关系抽取结果

图10-43 人工分析结果
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。








