



1)描述性统计分析
回收样本中,69%的被调查者为男性,31%为女性;年龄分布上,处于23~26岁之间的占全部样本的67%,也就是说绝大部分的被调查者处于毕业5年之内;被调查者的学历大部分是本科,占58%,其次是大专,占32%,还有少量的硕士和中专学历;他们中户口落户嘉兴的略多于没有落户的,86%的人参加工作的年限低于3年;在租金支出占月收入的比重一项中,83.3%的被调查者表示此项比例低于20%,其中低于10%的占全部样本的10.3%,而此项比例高于30%的很少,只有1.3%。
总体居住满意度指标的表现上,78.8%为基本满意,很不满意和非常满意都为3%。各分项满意度指标的表现上,除“房间布局”和“房间私密性”两项指标的表现是不太满意居于多数外,其余各指标表现均是基本满意占多数。其中“房间私密性”的很不满意的比例达到了22.2%,是我们这次调查中很不满意表现最多的两个指标之一,另外一个指标为“厨房卫生间的设置”,为23.2%。其余指标中,只有“厨房卫生间的设置”和“就医”两个指标的基本满意比例略低于50%。大部分的指标的满意等级分布大致相同。在各分类项目中,项目“物业管理”表现为满意级别(基本满意加上非常满意)的比例最高,达到了80.82%,其次是项目“外在环境”为79.43%,最低的是项目“建筑及设计”的满意等级表现。
2)信度分析
信度表示对一种现象的测度的稳定性和一致性的程度。它主要是评价问卷的精确性、稳定性和一致性,即测量过程中随机误差造成的测定值的变异程度的大小。信度越高,代表同一量表内不同题项所测量到的分数受到误差的影响越小,因此说明同一量表不同题项之间的分数并没有受被调查者一致性行为的影响。信度有外部信度和内部信度,外部信度指在不同时间进行测量时调查结果的一致性程度,一般用“重测信度”。内部信度指的是调查表中一组问题是否测量的是同一个概念,一般用Cronbach's α系数及“折半信度”。在单一维度内考察测量题项之间内在一致性最常用的指标是Cronbach's α系数。其公式为
本调查问卷信度的检测采用内部一致性方法,以Cronbach's α系数来检测问卷题目,得到的α系数值越高,则代表其检测的因子内部一致性越大,信度越高。Nunnally(1975)认为,Cronbach's α系数若大于0.7则表示信度很高,若小于0.35则属于低信度,0.5为最低可接受的信度水平。
SPSS统计软件分析后的结果如表2-17所示。
表2-17 SPSS分析结果
α=0.902,说明该问卷有很好的信度。
3)因子分析
因子分析是研究如何以最小的信息丢失,将众多原始变量浓缩成少数几个因子变量,以及如何使因子变量具有较强的可解释性的一种多元统计分析方法。按照因子分析的出发点,可用一个数学模型来表示这一思想。假设原有变量有p个,分别用x1,x2,x3,…,xp表示,其中xi(i=1,2,…,p)是均值为零、标准差为1的标准化变量,F1,F2,F3,…,Fm分别表示m维因子变量,m应小于p。于是有
x1=a11 F1+a12 F2+…+a1mFm+a1ε1
x2=a21 F1+a22 F2+…+a2mFm+a2 ε2
…
xp=ap1 F1+ap2 F2+…+apmFm+ap εp
也可以矩阵的形式表示为
其中,F为因子变量或公共因子,可以把它们理解为在高维空间中的互相垂直的m个坐标轴;A为因子载荷矩阵,aij称为因子载荷,是第i个原有变量在第j个因子变量上的负荷。如果把变量xi看作m维因子空间中的一个向量,则aij表示xi在坐标轴Fj上的投影,相当于多元回归分析模型中的标准回归系数;ε为特殊因子,表示了原有变量不能被公共因子所解释的部分,相当于多元线性回归模型中的残值项。
因子分析常常有以下四个基本步骤:
(1)确认待分析的原有若干变量是否适合作因子分析。
(2)构造因子变量。
(3)利用旋转方法使因子变量更具有可解释性。
(4)分别计算因子变量得分。
表2-18是居住满意度调查问卷有关KMO测度和巴特利特球体检验结果。KMO是Kaiser-Meyer-Olkin的抽样适度测定值,当KMO值越大时,表示变量间的共同因素越多,越适合进行因子分析。一般认为KMO如小于0.5,则不适合进行因子分析。该表结果显示,KMO值为0.812,适合作因子分析。表中的巴特利特球体检验的χ2统计值的显著性概率是0,小于0.01,同样说明数据具有相关性,是适宜作因子分析的。
表2-18 KMO测度和巴特利特球体检验结果
表2-19所示为总方差分解表。从表中可以看出,大于1的特征根共有8个,因此取8个共同因子。这8个共同因子解释了总体方差的70.912%,即累计贡献率达到70.912%。
表2-19 总方差分解表
表2-20为因子负荷表。将表中同一列的因子负荷较大的评价指标归为一类,据此可以解释共同因子的含义。
表2-20 因子负荷表
注:问卷中第n个指标表示为Qn。
共同度是每个测评指标因子负荷的平方和,共同度越大,表明该测评指标对共同因子的依赖程度越大,也就是说用这些共同因子来解释该测评指标就越有效。一般来说,当共同度大于0.4时,共同因子就能很好地解释该测评指标了,共同度相对较小的根据经验可以剔除。分析结果显示,各测评指标因子的共同度都大于0.4(最小0.570),说明问卷中设置的测评指标对居住满意度的影响是显著的,每一指标的设置是有必要的。
4)线性回归分析
线性回归分析是侧重考察变量之间的数量变化规律,并通过一定的数学表达式,即回归方程来描述这种关系,进而确定一个或几个变量的变化对另一个变量的影响程度,为预测提供科学的数学依据。
(1)因子变量线性回归分析
下面将运用SPSS软件,围绕居住满意度和上述因子分析结果的各项因子的线性关系进行统计分析。
在多元线性回归分析中,引入自变量的多少是很重要的。由于本次问卷调查的因子分析结果有8项因子之多,为能在选择变量的每一阶段都可剔除不显著的自变量,所以选择线性回归分析中的逐步筛选法(Stepwise)筛选自变量。
通过运行SPSS软件,建立了以居住满意度(S)为因变量,以F1、F2、F4、F5、F7为自变量的线性回归模型。回归系数与显著性检验表如表2-21所示。
表2-21 回归系数与显著性检验表
从所有模型的所有解释变量的t检验情况来看,几乎所有的变量的系数都在0.02的水平上,显著异于0。说明这些变量都可以作为解释变量存在于模型中,解释居住满意度(S)的等级。因此,可建立回归方程:
上表中的标准化回归系数可以衡量自变量对因变量的贡献程度。依据标准化回归系数建立标准化回归方程:
(2)因子变量的各项指标线性回归分析
由于指标较多,在进行此项线性回归分析时同样采用逐步筛选法(Stepwise)进行线性回归分析。
运行SPSS软件后,5个因子的分析结果如表2-22所示。
表2-22 因子F4的回归系数及显著性检验表
因子F4的标准化回归方程为:
表2-23 因子F1的回归系数及显著性检验表
因子F1的标准化回归方程为:
表2-24 因子F2的回归系数及显著性检验表
因子F2的标准化回归方程为:
表2-25 因子F7的回归系数及显著性检验表
因子F7的标准化回归方程为:
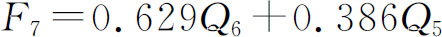
表2-26 因子F5的回归系数及显著性检验表
因子F5的标准化回归方程为:
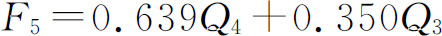
各项指标对总体居住满意度的影响系数等于其在因子变量线性回归分析中的标准系数乘上在对应因子变量中的标准线性回归系数。结果如表2-27所示。
表2-27 各项指标对总体居住满意度的影响系数
注:影响系数保留三位小数,小于0.1的指标没有罗列。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











