



4.2 分类语言互操作技术
4.2.1 基于同现信息的互操作
分类法的实质就是表达一系列文献情报内容概念及其相关关系的号码标识系统,可以用不同分类法的分类号来标识同一文献或图书,反之,标识同一文献或图书的不同分类号之间必定具有一定的关联,所以本系统采用基于不同分类法的同现信息来确定类目的兼容关系。如果两部分类法的分类号经常一起出现标识同一文献或图书,则认为这两个分类号是可以互相兼容转换的。
目前的图书馆普遍采用MARC机读目录格式存储数据,对同一图书可以采用多种分类法进行分类,用不同的字段来标识,如690字段是《中图法》分类号,692字段是《科图法》分类号,所以可以从图书馆的机读目录中下载一批同现数据。另外,对同一图书,在不同的系统中可能用不同的分类法标识,也可以通过查找不同系统,找到同一图书的不同对应分类号。由于主题内容的交叉性和标引的不一致性,同一图书可能分到不同的类下,即一本书可能给了多个《中图法》分类号或多个《科图法》分类号。这种情况下,采用统一规定,只提取排在前面的一个分类号参与计算。
然而,由于不同的分类法受体系结构不同、类目含义不同等的限制,加上对于不同文献或图书的分类一般都是由文献作者或标引人员自己确定的,具有标引的不一致性,就会造成一部分类法的某一类号下出现另一分类法中多个可兼容类号的现象,这其中势必存在着错误的标引结果,影响互操作的准确性。本系统采用基于统计学习的相关度算法,对同时出现的不同分类号进行约束,在一定阈值范围内再进行不同分类法类号间的互操作。
下面以《科图法》到《中图法》的互操作为例,来详细说明这种方法的可行性。具体思路如下:
(1)收集共现数据。共现数据是从CNMARC记录下载来的,从中提取出同时含有690字段(《中图法》)和692字段(《科图法》)的记录,作为待处理数据库,经过判别后对其中的错误分类号做修改或删除。
(2)词频统计。利用程序及SQL语句分别统计《中图法》和《科图法》各类号出现的频次及两类号同时出现的频次。
(3)计算相关度。采用Dice测度方法计算两类号的相关度,Dice测度公式表达形式如下:
![]()
在实际计算过程中,用ztf_pc表示《中图法》分类号单独出现的次数,用ktf_pc表示《科图法》分类号单独出现的次数,用gxpc表示两类号同时出现的频次,则计算两类号的相关度用如下公式:
![]()
通过程序利用公式4-2计算,得到各个《中图法》分类号及其对应《科图法》分类号的Dice测度值。
(4)以《中图法》为依据,逐类逐号排列记录,因为标引的不一致性,就会造成《中图法》的某一类号下出现《科图法》中多个可兼容类号的现象,将所有与该类号兼容的《科图法》的类号均集中在该类号下,并按其Dice值从大到小排序。例如,《中图法》“G40”下对应的《科图法》类号如下:
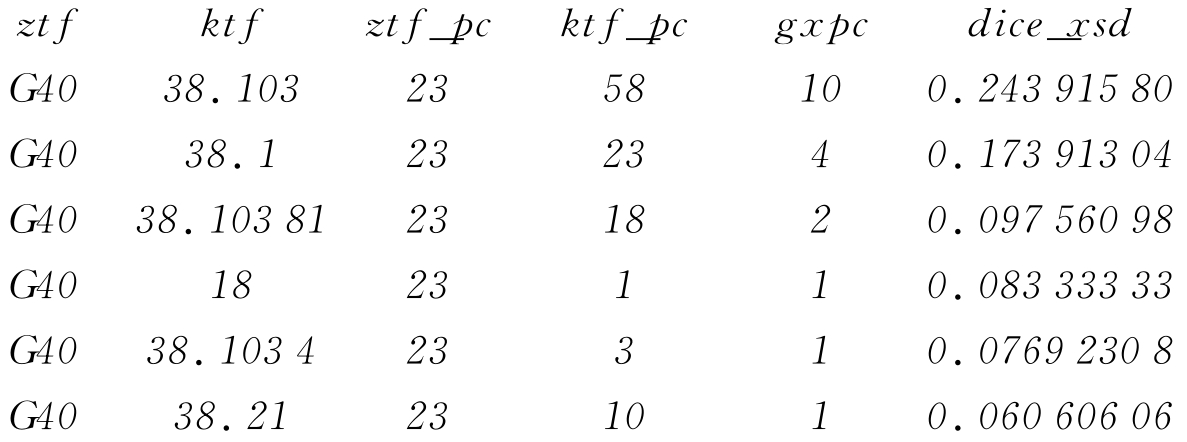
(5)经过上述处理,得到初步的兼容表。在这个表中,对于同一《中图法》分类号,有的兼容类出现多次,则Dice测度值大,说明可转换性好,是转换时应优先考虑的;有的则只出现1次或几次,则Dice测度值小,这就包含偶然性因素,一般是不可靠的兼容类号。
在这种情况下,需要设定一个标准,删除掉一些不合理的兼容类号。结合兼容类号的出现次数和Dice测度值两方面的因素,对兼容表进行处理。对于一个《中图法》分类号对应多个《科图法》分类号的现象,首先将其中《科图法》类号只出现一次的记录删除掉,剩下的按Dice值从大到小排序,经过多次试验结果分析,取Dice值大于等于0.07的记录作为备选兼容类号,另外对于一对一的类号都保留。
(6)利用程序分别将《中图法》类目和《科图法》类目导入到对应类号下,通过判断删除掉其中的错误分类号及一些不合理的兼容类目,并进行适当人工识别,加入一些对应类目,结果允许一个《中图法》分类号对应多个《科图法》分类号现象的存在。至此完成《科图法》到《中图法》的互操作。如《中图法》“G40”类号对应的《科图法》类号记录格式如下:

(7)以《中图法》类号为依据竖向展示,将对应的《科图法》类号及类名(一个或多个)放入一个字段中,横向展示。最终能够通过《中图法》类号,可以方便、快捷的找到其完全对应的或相关的《科图法》类号,以便用户进行进一步的选择。
整个过程可用以下流程图表示:
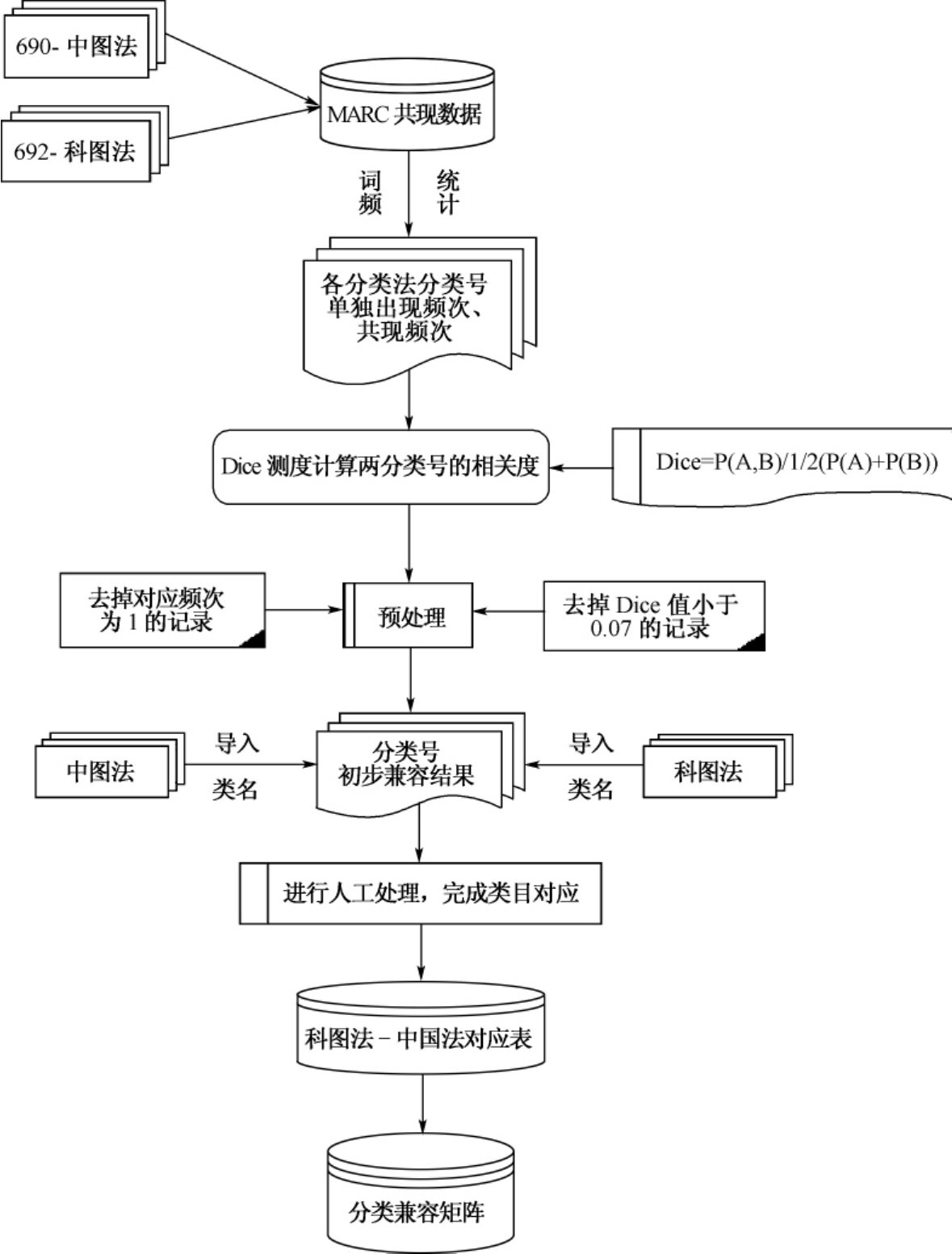
图4-3 《科图法》—《中图法》互操作流程图
同样采用这种方法,经过词频统计、Dice测度计算、结果筛选等处理后,可以实现部分DDC类目到《中图法》的互操作。
计算完成后,对该方法的性能需要进行一个定量的评价。从同现集合中获取的兼容类目的全面性和准确性两个方面来进行评价,采用两个常用的指标:准确度P和覆盖度R。
·准确度是指利用该方法,从同现集合中提取出的正确
的兼容类目和同现集合中共含有的兼容类目的比值大小。
·覆盖度是指利用该方法提取出的正确的兼容类目,与所有匹配的兼容类目的比值。
准确度越高,表示该方法可以提取准确的兼容类目;覆盖度越大,表示该方法可以提取更多的兼容类目,两者越高越可以证明该方法的可行性。实际应用中,它们各自的定义如下:
准确度:P=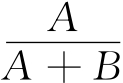 ×100%
×100%
覆盖度:R=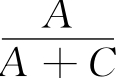 ×100%
×100%
其中,A表示利用同现映射方法匹配的正确的兼容类目;B表示利用同现映射方法匹配的错误的兼容类目;C表示利用同现映射方法未匹配的兼容类目。
对上述完成的《科图法》、DDC到《中图法》的同现映射结果进行测评,见表4-1。
表4-1 同现映射结果
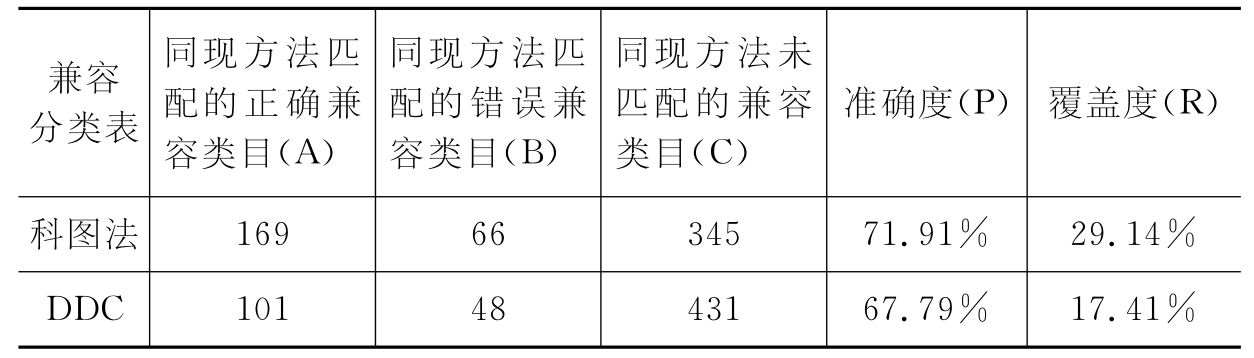
从表4-1可以看出,采用同现映射方法实现不同分类法之间的互操作,其准确度接近70%,说明该方法具有一定的可行性;但其覆盖度偏低,DDC的兼容只达到17.41%,说明这种方法只可以完成其中少部分类目的互操作,有一定的局限性。
出现这种情况的主要原因是语料不够丰富,即下载的MACR同现数据不够全面,有许多《中图法》类号本身就没有包括进来,另外对于中文书籍现在主要采用的都是《中图法》分类号,《科图法》分类号已很少采用;对外文书籍的编目也主要以《中图法》分类号为主,采用DDC分类的很少,所以同现数据比较少,这些都对结果造成直接影响。
针对上述情况,我们可以考虑加大语料库,从多种途径收集更多的同现数据,从而提高该算法的性能。如对于DDC分类法,可以从以下几个途径获得同现数据:主要是国内图书馆中现有的外文图书MARC记录,从中抽取出同时含有《中图法》和DDC分类号的记录,条件允许的话可以下载大批量数据,有助于提高计算的准确度;其次,现在的出版物,无论中文还是外文,都带有CIP数据,CIP数据中又都分别带有《中图法》和DDC的分类号。对于中文书籍,可以在国外的编目记录中查找到该书的对应DDC分类号;而对于外文书籍,则可以从国内的编目记录中查找该书对应的《中图法》分类号,从而可以搜集到一批比较精确的对应类目;另外,目前世界上许多图书馆纷纷将本馆的OPACS(图书馆公共查询目录)送入Internet,形成了世界范围内的书目信息资源共享,为该方法的实施提供了有利的条件。总之,如果可以获得大量的共现数据,加大语料库,这种同现映射的算法将是一种值得提倡的好方法。
4.2.2 基于类目的直接映射
基于同现信息的映射方法只可以实现部分分类法之间的互操作。对于那些用此方法不能实现兼容的类目,我们还需要结合其他的方法来完成。本系统采用了基于类目的直接映射方法(即计算类目的相似度)来实现。
类目映射时,不仅要考虑到类目的表达形式,如类号、类名等,还要考虑类目所表达的概念在外延和内涵上的相符程度。相同的概念在不同分类法中可能采用不同的类名,所以类目所表达的概念一般要由类名、注释、上下位类等概念来界定。第3章中的《中图法》和《杜威法》映射系统,就是通过计算类名词、注释词、上位类类名词、下位类类名词以及类目对应的主题词等词汇的语义相似度,得到类目的相似度,进而确定类目之间的映射关系,将映射结果分为相等、包含、包含于、大部分重叠、小部分重叠五种情况,通过实验证明了这种方法的可行性。
本系统也利用这种方法,通过计算类目的相似度进行映射。一般体系分类法对类目名称进行了一定的规范化,要求类目名称用词确切,能反映类目的实际内容范围,并且采用比较通行的科学名词;当类目名称不能确切表达类目的实际内容时,使用注释加以补充、说明,所以等级体系分类法一般是通过类目和注释来表达各种复杂概念的。本系统选择类目对应的类名词及其注释词进行映射计算,将类名词及注释词统称为类目对应词。下面以DDC到《中图法》(简称CLC)的互操作为例,来详细说明这种方法的可行性。具体思路如下:
(1)类目对应词的抽取:在抽取类名词及注释词之前,首先必须对类目概念和注释进行规范化处理。CLC类目词基本上采用的都是比较规范的语词,主要是去掉其中的停用词及特殊符号,将多主题概念进行分解,从注释中提取出能表达主题概念的语词。而DDC是外文分类法,在概念表达上和中国的语言习惯有很大差别,翻译的DDC类目有些生硬、简化,需要对它进行严格处理,使其能表达完整的概念,并且尽量和CLC类目表达相一致。具体抽取规则可参见第3章中的详细论述。
(2)经过规范化处理后,将每一条类目表示为能表达完整概念的语词,即将每个类号用多个对应的类名词来表示。然后将其格式进行转换,利用程序将每个词抽取出来,并赋予其对应的分类号,形成词—分类号的对应形式。
(3)建立词素词典,对所有类名词进行切分。要实现词与词素之间的对应转换,需要建立词素词典。本系统的词素词典的构建方法是:将本系统已收集的所有主题词表和分类表,包括《中分表》、《教词表》、《社科表》等的全部主题词及其所有参照款目,以及DDC类目都作为词素来源;利用现有的分词程序将其进行切分,形成若干词素,并进行合并去重处理;最后由人工进行判断,对其中切分错误的词素进行纠正,最终形成词素词典。在此词素词典的基础上,采用最大正向匹配算法(MM法)分别对DDC类名词和CLC类名词进行切分。
(4)利用词素相似度计算公式,计算DDC类名词和CLC类名词的相似度,如计算A、B两词的相似度,则计算公式如下:
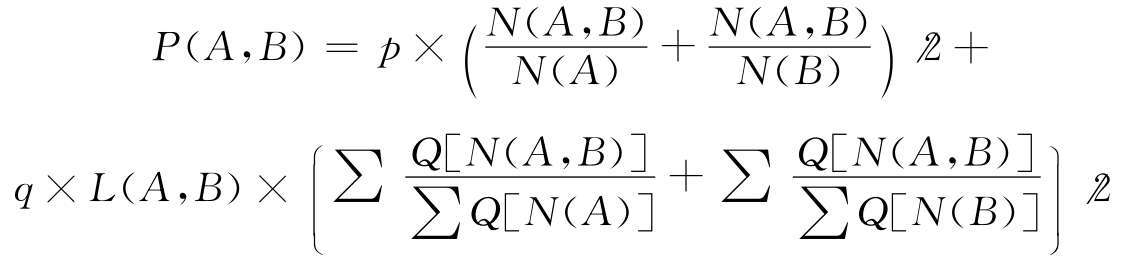
其中,p,q分别表示匹配词素和词汇结构对相似度的影响系数,p,q<=(0,1)且p+q=1。这里分别取p=0.6,q=0.4;
L(A,B)是参与匹配的两个词所含词素个数的比值,其取值作如下约定:
当N(A)<N(B)时,L(A,B)=N(A)/N(B);当N(A)≥N(B)时,L(A,B)=N(B)/N(A);
例如计算“全面发展教育”和“和谐发展教育”的相似度:
①词素切分:分别将两词切分成词素,“全面发展教育”切分成“全面/发展/教育”三个词素,即N(A)=3,“和谐发展教育”切分成“和谐/发展/教育”三个词素,即N(B)=3;
②找到两词的相同词素:两词含有“发展”与“教育”两个相同词素,即N(A,B)=2;
③权重计算:采用传统算法中的“重心后移”原理计算分配权重,则“发展”在“全面发展教育”中的权重为2,“教育”为3;“发展”在“和谐发展教育”中的权重也为2,“教育”为3,则:
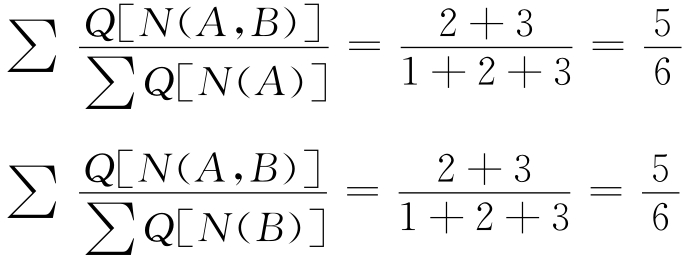
④相似度计算:将上述数据代入公式,则相似度结果为:
xsd=0.6*(2/3+2/3)/2+0.4*1*(5/6+5/6)/2=0.73333333
(5)确定阈值,筛选对应词。经过上述公式计算后,得到两两词之间的相似度,经过多次实验结果分析,结合以往的经验,确定阈值为0.6,即提取相似度大于等于0.6的词作为对应词。对于存在大量对应词的情况,按其相似度大小进行排序,取排在前十位的词添加到对应词下。然后进行适当的人工识别,删除掉其中明显错误的及不合理的兼容内容,结果允许一个CLC类名词对应多个DDC类名词现象的存在。
(6)通过CLC类名词对应其分类号,将DDC类号及类名对应到相应CLC类号下。
(7)上述两种映射结果合并、去重,完成DDC到CLC的兼容。
举例来说,如DDC类目“378.02/财政管理”,注释为“包括费用和学费”,经过规范化处理将该类目表示为“378.02/财政管理;费用;学费”,即“财政管理;费用;学费”这三个词对应的分类号都为“378.02”;《中图法》类目“G467.27/学杂费”,表示为“G467.27/学杂费;学费”,即“学杂费;学费”对应的分类号都为“G467.27”。然后利用词素词典对各个词进行切分,再基于词素相似度两两交叉计算每两个词之间的相似度,可以得到DDC注释词“学费”与《中图法》“学费”之间可以建立对应关系,进而导出其对应的两个分类号“378.02”和“G467.27”之间可以建立映射关系。
整个过程可用流程图4-4表示如下:
通过上述类目映射方法,可以实现《科图法》、DDC等分类法到《中图法》的互操作,同样采用准确度P和覆盖度R两个指标对该算法进行评价,见表4-2。
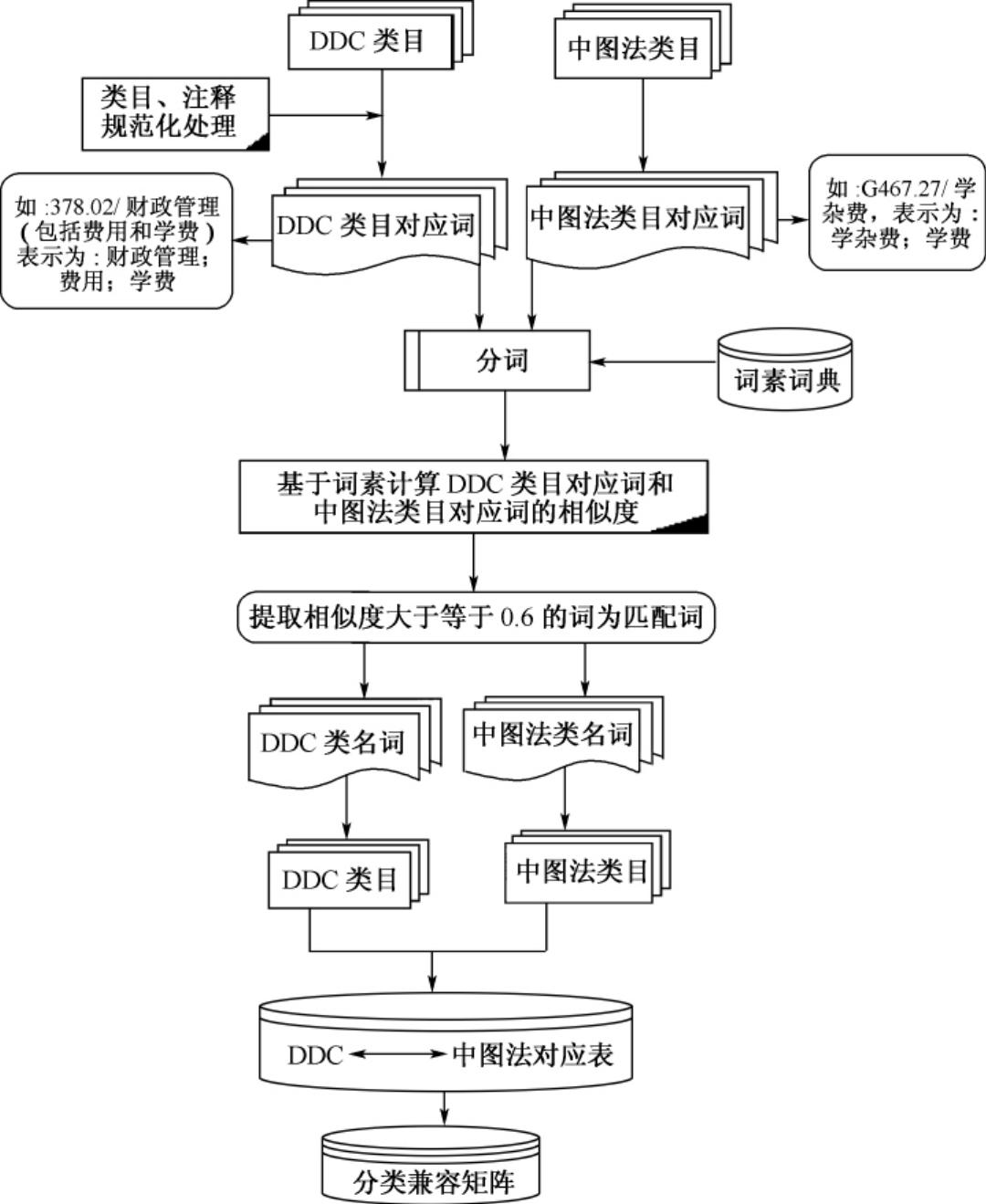
图4-4 DDC-《中图法》互操作流程图
表4-2 类目映射结果
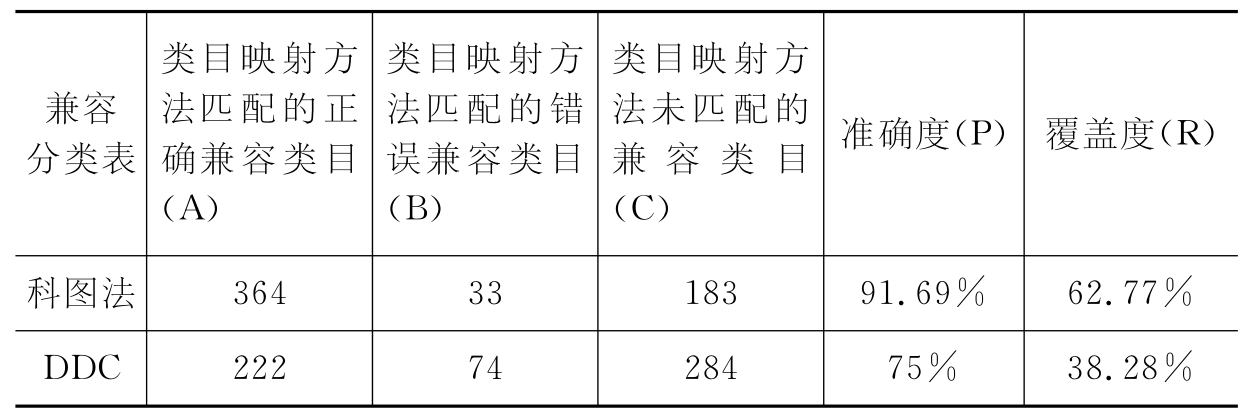
从表4-2可以看出,采用类目映射方法实现不同分类法之间的互操作,其准确度和覆盖度都有了提高,尤其是《科图法》到《中图法》的转换,准确度达到了91.69%,说明了该方法具有一定的可行性。但对于DDC转换,覆盖度仍然偏低,说明该方法也有一些不足之处,需要人工对类目概念进行规范化处理,耗费一定的时间和精力;同时由于个人理解不同,类目规范化时必然加入个人主观因素,可能会造成概念损耗或增义,尤其是对于由外文翻译而来的中文DDC类目,有些本身就存在概念失真现象;另外基于词素计算语词相似度的方法本身也有缺陷,对一些异形同义词不能识别出来,以上这些因素都会直接影响映射结果。
针对以上情况,提出以下一些改进意见,希望可以提高该方法的性能。首先要考虑减少人工干预,直接选择经过规范化的类目数据,建议采用索引数据来进行映射。一般的分类法都编有索引,分类法索引又称为分类法类目索引,其原理就是将分类表中有检索意义的全部类目名称、类名的同义词、注释中出现的概念名称、甚至一些分类表中未列出的概念名称,按其字顺排列,并在每一名称(标目)后注明相应的分类号。所以分类法的索引词都是经过规范化的概念名称,可以拿来直接使用。《中图法》、DDC都编有各自的索引,为该方法的实施提供了有利的条件。其次,对于基于词素的相似度计算方法,也有待于改进,本系统考虑加入同义词表来提高计算的准确度,该方法将在后面详细介绍。
利用分类表索引进行互操作,可分为以下几种情况:首先,可以将不同词表的索引数据合并,利用计算机编制轮排索引,将含有相同词素的类目集中显示;其次还可以添加索引词的同义词或对应主题词,从而提高转换的准确度;最后,可利用索引词进行上述相似度计算,提取阈值在一定范围的词为同义词。另外,对于外文分类法的转换,可以尝试结合英文及中文来进行匹配。
由于分类法索引是对整部分类法的类目名称、概念名称等按字顺进行排列的,致使同一类的数据分散,所以数据搜集需要很大的工作量,鉴于本系统只是以教育为例的实验系统,缺少人力、物力,此处没有使用索引数据。但如果有电子版本的索引,可以利用计算机编程直接抽取出某一类数据,则直接用索引词来进行匹配、转换,不失为一种很好的转换方法。在以后的项目研究或实验中希望该方法能得到推广应用。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。









