



3.11 体育社会心理学研究的实践问题
本节在回顾国际运动心理学研究发展的同时,考量我国相关学科研究的现状,探讨我国体育社会心理学研究发展的国际对接新途径。
实践探索的问题
20世纪80年代,国际运动心理学经历了跨越式的发展。在以后的30多年中,人们逐渐认识到了运动心理学研究的重要性。这不仅是因为竞技体育的制胜取决于心理、技术与体力的综合效应,更是因为体育活动对健康的含义在于提升幸福感状态和生活质量。早在80年代,随着积极心理学的出现,研究人员开始关注运动心理学的应用发展,并提出了“心理训练”的概念。当时的运动心理学研究与实践主要集中在高级竞技运动的个体项目上。到了21世纪,运动心理学研究已普遍被母学科所接受,并在世界范围内达成了运动心理学家包括社会心理学应用的学术资格认证共识。这一时期的国际运动心理学拓展了更加广泛的研究领域,内容涵盖了运动成绩的提高与赛前心理准备、运动中的情绪与情感、过度训练与倦怠、运动创伤的恢复,以及体育锻炼的心理效应与生活质量等问题。
随着竞技体育的竞争性增加,研究不仅涉及个体运动项目的探索,还发展了许多团队体育项目的理论。许多运动心理学实践者意识到,心理援助已不仅仅是帮助运动员准备比赛,而更重要的是增强运动团队有效的交流和培养积极团队发展的动机氛围,以及发展运动员人格。从这个角度上讲,当代国际运动心理学应用研究更加关注系统的纵向效应。由此在教练心理、运动学习与控制、锻炼心理与终身发展等研究领域衍生出了健康发展的相关问题与临床运动心理学的探索。特别是在体育有关的社会心理学领域里,团队动力、凝聚力、交流技术和体育道德等方面的问题也成了研究的热点。
我国运动心理学的学科发展也经历了30多年的努力。1979年和1980年中国心理学会和中国体育科学学会分别成立了运动心理学分会,并开始形成了学科建设的初创阶段。与国外相比,初创时期的研究似乎更强调针对高水平竞技体育的服务,主要关注优秀运动员心理特征评定、心理训练与咨询、教练心理和运动员选材等方面的问题。21世纪以来,学科研究开始转向多元化发展。特别是在研究方法上,从不同角度、不同层面探索体育运动中的心理现象。此时中国的运动心理学研究领域已基本形成了竞技运动心理、锻炼心理和体育教育心理三个方向,主要包含了心理训练、运动认知、心理生理、自我概念、心理疲劳、锻炼与心境、锻炼与自尊、锻炼与认知功能、锻炼与生活满意感、健康运动处方、学习心理动力、体育教师心理特征、教学心理建设与教学模式心理效应等内容。而这时的体育社会心理学还没有形成一门学科。
总体上讲,国际体育社会心理学主要还是包含在运动心理学中。研究关注的问题与我国略有不同,主要为运动心理和锻炼心理两个方向。从相关学术期刊看,相对偏重运动心理问题的探索,而且研究较细较深。我国运动心理学的研究除了运动心理与锻炼心理方向外,还有教学心理,这是我国研究的特色(见表3-5)。
表3-5 运动心理学研究领域的国际比较

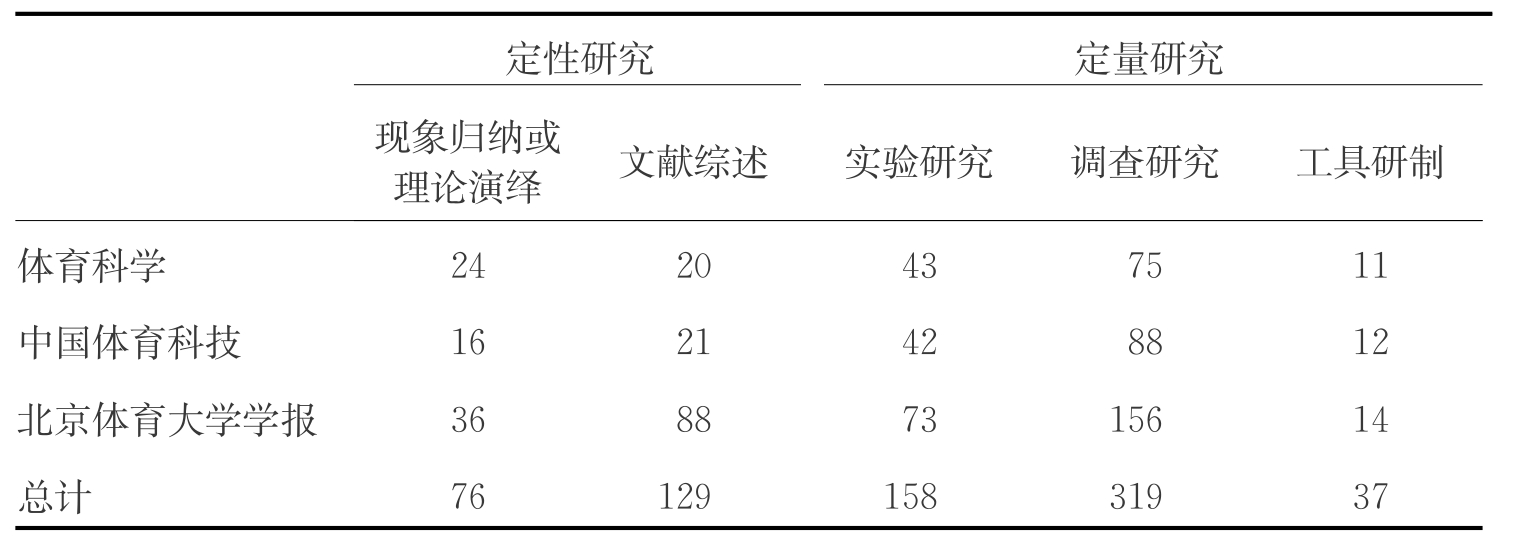
进一步,结合我国运动心理学研究成果的展示窗口,我们选择了国内具有代表性的体育学术期刊,考察研究的质量状况。这样,根据《体育科学》、《中国体育科技》和《北京体育大学学报》1998—2009年发表的与心理有关的研究,共统计到719篇论文。按照国际同类研究领域的划分方法,目前这3种学术期刊涉及的内容主要包括增强运动表现、运动认知、运动情绪、过度训练与倦怠、运动创伤恢复、锻炼心理、社会心理、教练心理、运动学习与控制、健康心理、运动人格和研究方法等方面。从论文主题分布的情况看,与运动成绩有关的探索仍然是主流方向,其次是健康心理、运动学习与控制、运动认知和运动情绪等方面的研究(见表3-6)。另外,从研究采用的设计范式看,定量的调查研究形成了主流,其次是实验研究。除此之外,统计表明文献综述是定性研究的主要内容(见表3-7)。
表3-6 部分学术期刊发表论文的运动心理学研究领域分布(1998-2009)
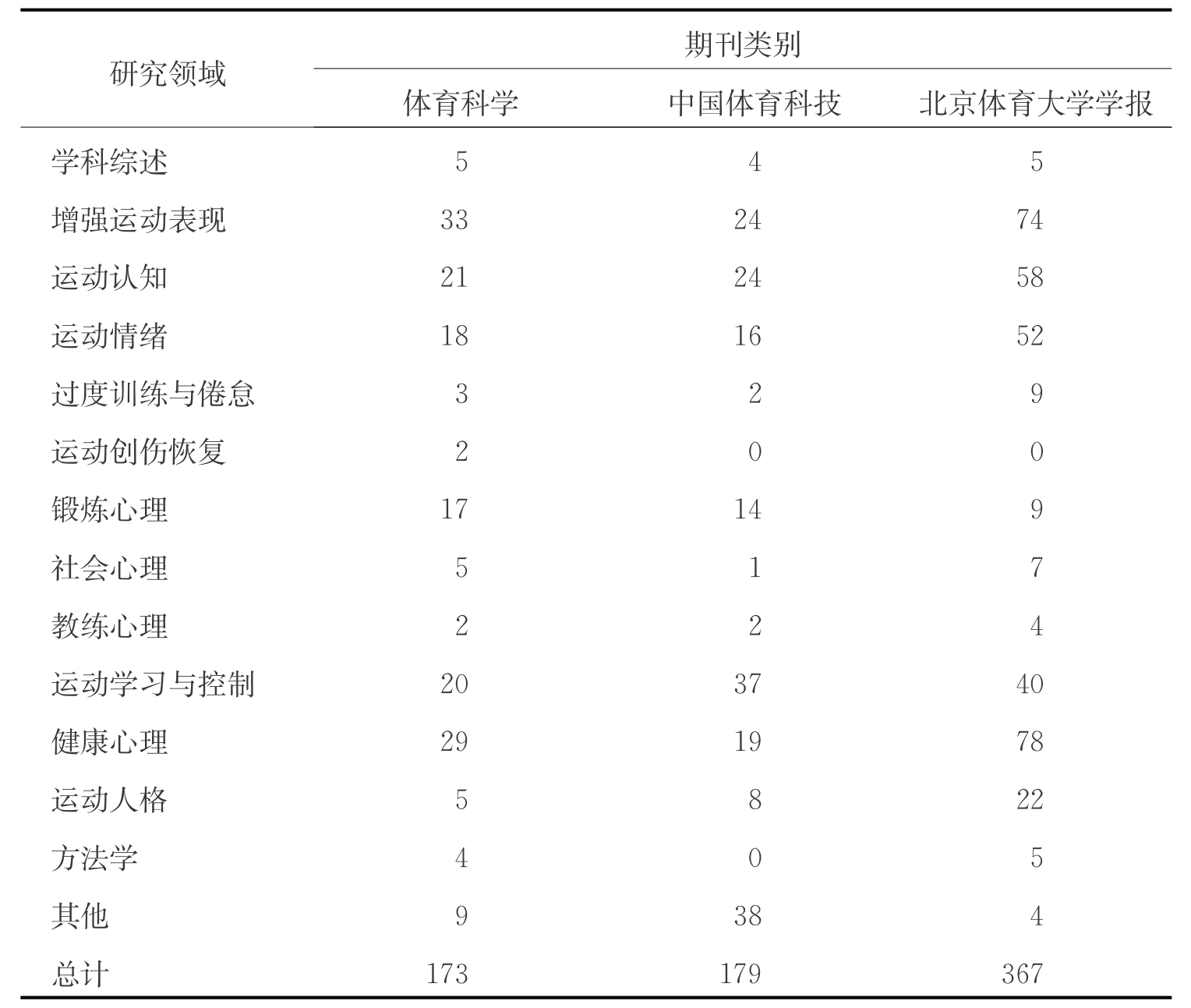
表3-7 部分学术期刊发表论文的研究范式一览(1998-2009)
从国际视野的角度,应该说目前我国运动心理学研究探索的领域基本上还是跟随了国际的主流意识。研究关注的问题也并不落后于国外的同类研究,有的甚至还表现出了中国自己的特色,研究水平也较过去有所提高。而且,越来越多的研究开始运用生理学、神经学、运动学、社会学等交叉学科的指标来探讨运动心理学的问题。从研究的设计上看,定量的实证性调查与实验研究(包括准实验)形成了目前较流行的运用范式。值得一提的是,现在有相当数量的研究在关注心理测量工具的开发。这对我国运动心理学研究的本土化探索有着重要的意义。
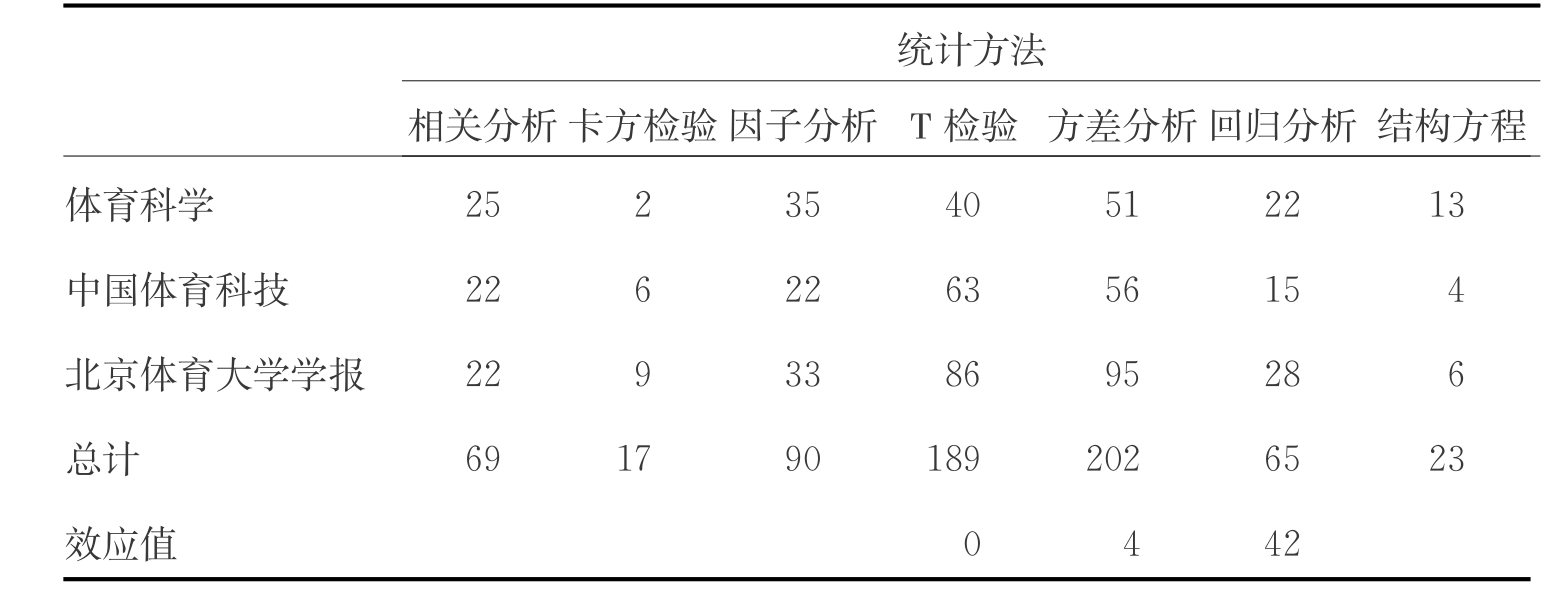
但是,客观地讲,就国内学术期刊发表的论文质量来看,与国外还有一定的差距。笔者以为缺乏科学严谨的研究设计和操作应该是造成差距的“短板”,这可能与我国研究人员的科学专业训练不够有关。例如,在统计的期刊论文中,有相当数量的研究论文缺乏理论,而且方法创新不够;定性研究中采用具有探索特征的“现象归纳”和“理论演绎”设计并不是主流。除了《体育科学》中论文运用“现象归纳”和“理论演绎”相对多于“文献综述”外,《北京体育大学学报》和《中国体育科技》中“文献综述”研究仍是主流的内容。这种现象表明,相关的研究缺乏对新理论的探索,在创新性方面显得不足。同时,在统计的论文中,发现还有使用过于陈旧的,甚至错误的研究设计和统计方法,使得研究的信度、效度过低,基本不能作为研究参考的依据;有的论文存在展示信息不全的问题,特别是许多论文忽略了研究过程和必要数据结果,使文章的可读性较低,对后续研究的参考价值不大。需要指出的是,在数据分析结果的表述中,我们发现在391次差异检验对其效应大小的报告,仅仅出现了4次(见表3-8)。这说明我们的研究人员对这一问题的认识并不十分清楚。其实早在20世纪末,这个问题就引起了国际上许多学者的关注,并撰写了大量的论文来阐述它的重要性。例如,Vacha-Haase等于2000年在《理论与心理学》上发表题名为《研究报告的实际情况与APA统计意义和效应大小的编辑原则》的论文。在文中他再次强调了APA标准对效应大小报告的意义。
表3-8 部分学术期刊发表的运动心理研究论文统计方法一览(1998-2009)
到目前为止,还不能给出中国运动心理学研究问题的前瞻性评价。但从我国学术期刊发表的论文看,研究成果展示出来的质量,应该说还是有一定的问题。目前我国所有学术期刊每年要发表上百篇与运动心理学相关的论文,而真正有价值并可以引用的研究恐怕是屈指可数的。关于这些研究质量的疑问,将逐一进行讨论。
理论的应用问题
研究的最终目的是为了发展理论。所谓发展理论,在研究中不外乎有两种情况:一是研究开始并没有可用的理论来进行指导,理论是通过研究创建起来的。这种情况通常是“发现研究”(exploratory research)。二是在原有理论基础上改进理论,这是真正意义上的“发展理论”,通常是通过“实证研究”(empirical research)来实现的。第一种情况的理论应该在研究的结论中清晰可见。如定性研究中,通过“现象归纳”,提出新的概念和现象关系的解释机制。第二种情况是我们最常见到的,在研究的一开始就有理论的引导,而发展的理论在假设中。在这种情况下,数据的收集与分析固然重要,但仅仅是说明了心理和行为的状态。只有理论才能赋予数据内涵,解释心理与行为变化的原因和回答为什么变量与变量间会存在关系。
Disessa和Cobb曾讨论过理论在研究中的角色,他们认为理论并不需要复杂,关键是要提供对观察对象的解读,回答“为什么”的问题,也就是阐述行为发生的内在含义。例如,研究体育活动参与的问题,研究人员假设自我障碍认知越高的个体,体育活动的行为就越可能会减少。理论提供了这种关系的解释,说明自我障碍会导致体育活动的自我效能感和自信心下降,以致个体认为没有能力和信心去完成体育运动。进一步,自我效能和自信可能会减少行为的意向。这样,研究假设自我障碍的认知可能是影响体育活动的重要因素。这一演绎推理的结论可以通过数据来验证,所以,研究变量关系的构建实际上是一个理论的演绎。然而,许多研究论文却忽略对理论假设的演绎。试想,如果研究没有理论,读者就不能连接问题探索的前后背景,更无法判断为什么要研究这些变量。
从这个角度讲,要提升运动心理研究的质量,我们不能仅仅简单地对过去的文献进行综述,或表述变量出现在过去的研究中,而应该意识到变量的关系组合是需要理论来组织的。Richard L.Daft是《管理科学季刊》和《管理学杂志》的审稿专家,他曾在1995年写过一篇题为《为什么我要建议拒绝你的投稿与你能做什么》的文章。在文中他清楚地阐述了理论在研究中所处的地位,并指出:“变量的测量、数据的收集,以及数据的分析技术都是研究的重要部分,但它们并不足以使一篇论文发表。”
另外,特别值得一提的是,在一些定性研究中也存在着缺乏理论的问题。一般情况下,定性研究的基本目的是构建理论。论文要基于研究者观察或访谈的数据提出理论框架,最后结论是明确提出新的概念和模型。与定量研究一样,定性研究同样要遵循理论比数据更重要的原则。研究人员应通过论文来提炼实践中的观察,完成理论对知识的贡献。然而,有的研究人员,特别是年轻的研究人员可能是过于“胆怯”而不敢去深挖数据的内涵,更不敢尝试从自己观察到的现象中提出一个新理论。我们应该明白一点,有时候并不是因为编辑不喜欢定性研究,而是这些研究没有模式,没有观点,也没有结论,更没有把构建理论放在论文首要位置而不得不拒绝发表。
假设的验证问题
在进行数据分析时,研究人员总是希望追求有意义的结果(即p<0.05)。然而,我们的问题是:当你提供一个研究结论时,你对自己有多大的把握保证你所提供的发现是真实的?就目前我们能够分析到的38个研究结果,发现90%的结论值得商榷。也就是说,当实际的差异并不存在时,作者却报告一个“有意义”的结果。统计学上把这种结论的错误称之为“Ⅰ型错误”(TypeⅠerror)。相反,当实际的差异确实存在时,作者却报告了一个“没有意义”的结果。这种错误通常被称为“Ⅱ型错误”(TypeⅡerror)。
怎样理解这个结果呢?我们还需要提到“零假设意义验证”(null hypothesis significance testing,NHST)理论。在统计学里,所谓NHST理论是指研究中我们通常会寻求拒绝没有关系或没有差异的假设(即“零假设”),并以此为证据,说明研究假设存在的可能性。但是,由于事件的偶然性,或是研究样本的问题,导致这些证据并非完全真实。这样,我们在提供证据时,必须要把这些因素考虑进去。因此,在NHST中,p值与α水平被用来判断证据错误的依据。同时,在这个过程中,我们接受至少两种判断上的错误:一是如果我们拒绝了零假设,非差异的结果可能的确存在,即“Ⅰ型错误”;二是如果我们接受了零假设,非差异的结果可能的确不存在,即“Ⅱ型错误”。
NHST理论在我们当今的科学研究中非常有用,它是说服读者相信研究结果的有力工具。NHST最早是由Rounald Fisher提出来的。但它不是唯一的验证理论。当时Fisher创建了“单一的二元零假设验证”(the testing of a single binary null hypothesis)理论,并建议采用p值作为统计的强度。然而,在他的理论中,并没有提到“两者选一的假设”(alternative hypothesis)、“Ⅰ型错误”和“Ⅱ型错误”、“统计检力”(Statistical Power)等概念。这些重要概念是由与Fisher同时期的波兰人Jerzy Neyman和Egon Pearson发展的,并且他们认为意义验证并不是单一的假设验证,而应该是两者选一的假设验证。一直以来,这些观点仅在各自的研究领域里被承认,直到20世纪50年代,统计学教科书才把他们的观点整合到意义验证理论中,并成为今天我们看到的NHST理论。后来许多学科,如心理学、社会学、教育学、医学、经济学等都把这个理论作为研究假设的验证工具。
Neyman和Pearson认为,当研究人员在对假设进行选择时,可能会作出错误的决定,并用概率来反映错误存在的可能性。这样,在他们的验证理论中,“Ⅰ型错误”发生的概率被表示为意义的水平(即α值)。也就是说,如果选择0.05的水平为有意义的验证,“Ⅰ型错误”发生的概率就是5%。当α值取值越低时(如0. 01),“零假设”接受的标准就越高,同时“Ⅰ型错误”发生的概率就越低。但是,所有事件都是可逆的。当“Ⅰ型错误”发生的概率越低,这个验证的检力就变得越低了。
所谓“检力”是指验证检出统计意义的概率。例如,如果选择0. 5为中度“检力”,获得有意义的检出率就是50%。根据NHST理论的界定,“检力”的完整余值(即1-power,β)表示为NHST中“Ⅱ型错误”的比值。Cohen建议,在假设验证前,研究人员应考虑它们的比重。例如,如果把α水平设置在0. 01,研究的“Ⅰ型错误”风险可以降低到很小。但是,验证的“检力”同时也被减小到0. 1。这样,“Ⅱ型错误”的风险就增加到90%(1-0. 1)。一个0. 1水平的验证“检力”意味着研究人员只有10%的机会获得一个有意义的结果。
“检力”的指标对于我们的研究结论具有重要的解释意义。也就是说,如果我们在研究中发现一个具有统计意义的结果,“检力”的大小将决定它的实际价值。例如,当研究的“检力”为0.1时,意味着统计发现的结果只有10%的机会可以得到验证。而当研究的“检力”为0.9时,则意味着我们的发现有90%的机会可以得验证。显然,对于一个90%的事件发生率来说,更具有实践的指导意义。所以,在实际的研究中,一个结果的真实性与实际获得的结果有关。
其实,除“检力”控制外,国外学者还用其他一些方法来减少判断错误的发生。例如,在方差分析的后测验证中,采用Tukey测试、Newman-Keuls测试等可以很好地控制“Ⅰ型错误”。但是,当控制了“Ⅰ型错误”后,“Ⅱ型错误”的风险却又会增加。那么,怎样来平衡这个风险点呢?学者建议通过计划控制研究的“效应大小”(effect size)来达到平衡的目的。关于这一点,Cohen首次提出了基于“效应大小”来确定“检力”的方法,以此判断研究结论的真实性。当时他通过对《变态与社会心理杂志》发表的78篇论文进行了“检力”分析。结果发现,在中等效应水平上的研究,“检力”均值为0. 48,接近50%的意义检出率。而大效应水平上的意义检出率为70%。Cohen认为,如果考虑这些研究结论的真实性,这样的“检力”均值普遍偏低。所以,他在1988年建议研究的“检力”应该在0.80以上为可接受的水平。但是,Sedlmeier和Gigerenzer在1989年重复了Cohen的工作,结果发现中等效应研究的“检力”均值仅为0. 37,比Cohen的0.48减少了0. 11。Sedlmeier和Gigerenzer强调这种问题距离10年前Cohen提出之后不但没有改善,反而变得更糟了。因此,他们呼吁学术界应该关注研究“检力”过低的问题。
在体育科学研究中(包括运动心理的研究),Jones和Brewer曾对《研究季刊》(Research Quarterly)发表的研究论文进行过“检力”分析,结果发现小、中、大效应研究结果的平均“检力”值为0. 13、0. 50和0. 78。Christensen和Christensen(1977)对《健康、体育与娱乐研究》(Health,Physical Education,and Recreation Research)发表的论文分析也发现,研究“检力”的平均值更低,分别为0. 08、0. 32和0.69。这些分析结果表明,两个研究统计的体育研究论文结果均未达到Cohen建议的“检力”接受标准。这意味着这些研究发表的结果可能都包含了“Ⅱ型错误”。2000年,Speed和Andersen对《体育科学与医学杂志》(Journal of Science and Medicine in Sport)发表的29篇论文进行了“检力”分析,结果发现小、中、大效应研究结果的“检力”均值分别为0.14、0. 63和0.97。Speed和Andersen指出,统计论文中,小效应研究的“检力”均值仍然没有达到Cohen建议的标准。但是,中等和大效应的研究中,已分别有38%和75%的“检力”值到标准。总体上超过半数的研究“检力”达到接受标准(56. 5%)。由此可见,从1972年到2000年,经过了近30年的努力,国际体育科学研究的质量在不断地提高。
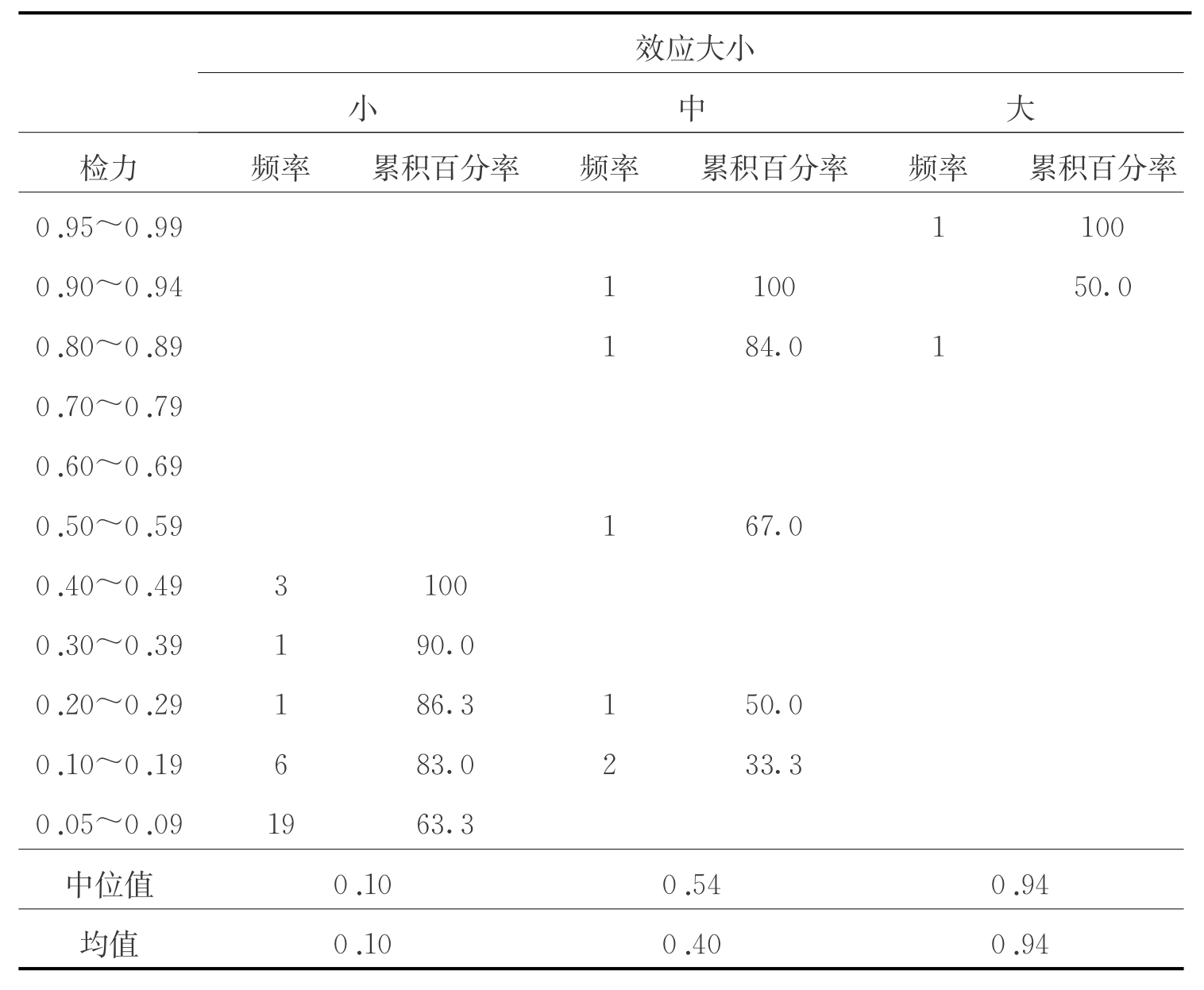
由于我国体育学术期刊对发表论文的要求没有与国际对接,我们无法获取相关的完整数据用于研究质量的分析。但在《体育科学》、《中国体育科技》和《北京体育大学学报》中我们仍然获得了38个有意义验证的数据,经“检力”分析统计法发现,小、中、大效应研究结果的“检力”均值分别为0.10、0.40和0. 94(见表3-9)。参照Cohen对研究“检力”的接受标准(80%),在我们的分析数据中,只有10%的意义验证达到可接受的标准。也就是说,90%的统计意义选择都可能存在“Ⅱ型错误”。这个百分比远远低于国外的同类研究。进一步分析发现,在这些随机抽取的38个样本中,约80%的结果是小的效应值,而且“检力”值都在49%以下。由此可见,应该说我国运动心理学研究的质量与国际水平存在着一定的差距。
表3-9 《体育科学》、《中国体育科技》、《北京体育大学学报》发表的部分研究的“检力”分析一览(n=38)
关于p值的理解
在体育的实证研究中,运用p值来帮助研究人员作出结论的选择几乎成了唯一的手段。但是,在笔者审稿的过程中发现,有相当一部分作者似乎并不了解p值的真正含义。总结起来至少可以列出三个方面的误区;一是低于α值的p值与研究结果的重要性无关。然而,有的作者在讨论结果时强调自己发现的重要性仅仅是因为获得了一个较小的p值。二是一个有意义的统计结果不可能告诉研究结果的可重复性。然而,有的作者却认为p值计算是评估研究结果可重复的概率。三是p值并不能单独评估研究效应的大小。然而,有的作者却把p值的大小作为研究的效应来解释。
为什么会产生这些错误的认识呢?问题可能出在对NHST的理解上。一般来说,统计意义上的p值具有两个含义:一是低于α值的p值可以视为拒绝“零假设”的证据;而等于或大于α值的p值则被视为接受“零假设”的证据。从这个意义上讲,p值是作为对“零假设”拒绝与否的凭据。二是p值反映效应大小与样本误差的功能。也就是说,在一个给定的样本中验证意义与效应大小直接相关。表现为:
验证意义(p)=效应大小×研究样本的大小
在NHST的使用中,由于p值比较敏感,无论是当样本误差很小时(可能是因为大样本量或大效应所致),还是当样本误差很大时(可能是因为小样本量或小效应所致),只要有很小的差异都可以被判为有意义的统计。但需要指出的是,此时的p值并不能区分哪些差异是由于效应大小,而哪些差异是由于样本误差的作用。所以,p值没有提供任何关于研究意义大小的信息,更谈不上复制研究的概率。
Thompson曾建议了一个正确运用p值的步骤:首先,当获得一个有意义的结果后,应根据p值的情况决定下一步的分析(即是否继续分析)。然后,分别考虑该样本误差和效应大小。这样,研究人员可通过计算效应大小来区分识别样本量的效应与误差。最后,研究人员可采用其他方法来复制这个分析结果。这一步骤的运用不仅可以验证所获得的分析结果,还可以为他人提供一个分析指南。
然而,统计意义的验证并不是完美的。许多学者(如Cohen,1990,1994;Schmidt,1996;Hunter,1997;Levin,1998;Thompson,1998等)对此提出过质疑。例如,Cohen曾在1994年指出,意义验证存在“非必然的推理错觉”(illusion of attaining improbability)。具体地讲,验证是基于拒绝“零假设”的意义水平设定在至少0. 05,并表现为拒绝是否正确的概率。这样,假设验证的推理为:
如果“零假设”是正确的,则数据发生的可能性不大。但是,数据发生了。所以,“零假设”的可能性不大。
由于这个因果关系推理的后置并非前提的必然结果,所以犯了前置逻辑错误。Cohen把它称为“前提错觉”(the permanent illusion)。基于此,Cohen等一些学者建议研究人员不能依赖这一方法作为唯一手段,并推荐使用“效应大小”(effect size)的指标来弥补这一缺陷。所谓“效应大小”指一个标准差异的度量,即两组平均值差与标准差的比率:
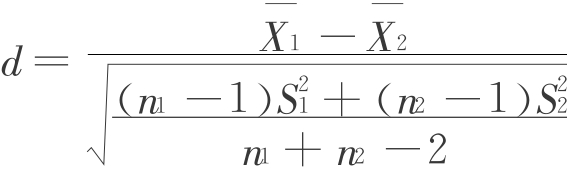
根据Cohen的定义,其中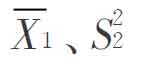 和n1分别是平均值、标准差和i的样本量。当然,效应大小有许多种算法,主要根据统计采用的方法来决定。现在一般表示的效应大小有:d(针对T检验)、ES(针对方差分析)、R2(针对回归分析)等。它们的大、中、小设定值各不相同,如d的设定为:大=0. 80、中=0.50、小=0. 20;而对于ES的设定是:大=0. 14、中=0. 06、小=0. 01。
和n1分别是平均值、标准差和i的样本量。当然,效应大小有许多种算法,主要根据统计采用的方法来决定。现在一般表示的效应大小有:d(针对T检验)、ES(针对方差分析)、R2(针对回归分析)等。它们的大、中、小设定值各不相同,如d的设定为:大=0. 80、中=0.50、小=0. 20;而对于ES的设定是:大=0. 14、中=0. 06、小=0. 01。
Thompson给出了两个理由阐述为什么有采用研究效应的大小值:一是研究的效应大小可以反映统计结果的实际意义;二是报告研究效应的大小有利于在将来的文献综述中进行元分析综合。目前国际学术界已基本达成共识,要求作者在报告p值的同时必须附带研究效应大小的值。有的学术期刊在投稿指南中就明确注明需要报告研究效应大小的值。Murphy是《应用心理学杂志》的一名编辑。他曾在1997年的期刊编辑附言中建议:
如果一个作者在报告意义验证结果的同时决定不附带效应大小的值,我会要求他(她)提供特别的解释为什么不报告研究效应大小。到目前为止,我还没有得到一个充足的理由拒绝报告效应值。所以,除非是真的有困难,通常情况下都应该在论文中报告研究效应的大小。
从这个角度讲,不能不说我国运动心理研究对这个问题忽略得太久了。正如我们前面提到的,在统计的391次p值报告仅仅附带4次研究效应大小。应该是改变这种状况的时候了。
实验设计的问题
在我们统计的158个实验研究设计中,有73个采用了“前后测试控制组设计”(pretest-posttest control group design),约占实验设计的50%,说明该设计已成为研究人员常用的方法。其主要原因有两个:首先,它属于“真实验设计”(true experimental design),能科学地控制对内部效度的威胁。其次,它是一个多层设计。通常情况下,它被用于两组比较(实验组与控制组,或两组给予不同的干预),但很容易延伸进行另外的多组比较,所以使用方便。
但是,使用这种设计时应小心选择数据分析方法。如果数据处理方法运用不当,就可能产生结论错误。例如,Speed和Andersen(2000)曾指出,T检验分析与这种设计有关的“Ⅱ型错误”。具体地讲,“前后测试控制组设计”中的T检验分析主要由前测的组间同质检验和组内差异的分析组成。但是,这种“同质”可能会因为一个小效应的“无意义差异”结论而引起质疑。如前讨论,在效应值较小的情况下接受“零假设”,无疑会增加判断上的“Ⅱ型错误”。这样,由于同质验证并不能保证组间“相等”结论的真实性,前置的逻辑错误必然会导致组内差异错误判断的结论。
关于“前后测试控制组设计”中使用ANOVA的数据处理方法,Huck和M cLean早在1975年就指出了其潜在的危机。他们分析了此种情况下可能存在的三个问题:一是ANOVA结果的组间主效应可能过小,引起表述上的错误;二是交互效应和干预效应的重复计算;三是多层分析结果前后矛盾。具体地讲,根据“前后测试控制组设计”模式的原理,由于因变量的前测得分是在实验干预施加前获得的,故交互效应和干预效应不对其产生作用。然而,对于后测得分来说,则会受到交互效应的影响,但交互效应的结构又不成立。另一方面,基于实验施加的干预仅仅作用于因变量后测得分的事实,这样,当重复测试的ANOVA被运用于前后设计时,线性数据模型中主效应F值将会被分散,从而使其计算的效应比实际的效应小,造成对分析结果的错误描述。
Huck和M cLean进一步指出,理论上讲,由于实验干预只能作用因变量的后测得分,采用One-way ANOVA分析主效应也是一个思路。但是,如果缺乏因变量的前测得分,对于分析模型来说会影响两个效应:一是解释组间差异有关的实验干预主效应变化;二是减少组间差异引起的分析“检力”下降。然而,如果采用因变量的前测得分,ANOVA就会计算交互效应的F值和干预主效应的F值。在这种情况下,实际上是重复计算了干预的效应,两个F值具有同样的含义。在运用重复测试的ANOVA分析数据时,Huck和M cLean发现,许多研究存在交互效应的F值与实验干预主效应的F值不同。这也反映了该分析方法与理论之间产生了不符的问题。
另外,有学者建议把干预前后得分的差值作为因变量,进行One-way ANOVA分析。但Sheeber等指出,这种方法仍然无法控制前测组间的差异问题。也就是说,如果前测组间存在差异,统计得出的意义结果仍然无法确定是否实验干预的效应,与前面分析的One-way ANOVA情况基本相似。所以,在运用“前后测试控制组设计”时,它同样存在One-way ANOVA方法的问题。
为了克服ANOVA在“前后测试控制组设计”中产生的问题,许多学者建议用协方差分析(ANCOVA)来处理前后测试的设计实验问题。ANCOVA是用于随机分组的前后测试组间差异的分析方法。一般地讲,后测得分作为因变量,前测作为协变量。在心理学实验设计中,ANCOVA是分析组间变化比较好的一种方法。但是,Jamieson(2004)指出,当被试组的构成不是随机分组,而是自然分组时,分析的基线变化就不是由于机会产生的了。这时的ANCOVA结果表述就会产生偏差。所以,在进行实验设计时,需要注意这一点。
未来的发展
差距的对比并非在于打击自信,问题的分析旨在激励寻求发展的出路。一方面,笔者希望本文的讨论能启迪我们对科学研究的再思考。另一方面,也渴望从以下两个方面去进行再探索。
学术论文可读性的提升
众所周知,写论文不是写给自己看的,而是要面对你的读者。因此,读者是否能读懂你的文章就显得尤为重要。例如,有的研究缺乏理论支持,或是操作不能反映理论的模式和概念;有时,作者寻求一个间接变量,却不能给读者一个直接的理由;在一些操作变量的关系上,有的逻辑分析思路混乱,有的甚至缺乏必要的研究过程表述,内容显得杂乱无章,而且偏离主题,大量篇幅讨论与主题无关的信息,让读者很难读懂论文的真实意图,等等。
其实,高水平的论文最能显示作者良好的科学训练。也就是说,作为研究人员,要努力学会让别人理解你的思路,了解研究问题的来龙去脉。理论总是与研究相关,不管是创新一个理论,还是验证一个理论,都要给出具有说服力的证据。让读者了解到什么是研究的新发现,并给出足够信息,让研究结果变得可再现。同时,作为研究论文的作者,要努力做到文章前后一致,逻辑有序,避免在结论中突然提出新观点。
实际上,由于在研究过程中,收集到的信息是零乱的,所以我们需要自我训练,学会去除无序的信息,让读者知道研究中究竟发生了什么。学会展示必要的研究信息,努力提高论文的可读性。最后,关于论文的可读性问题,一个好的学术论文作者应该追求把复杂的科学问题变得让百姓读懂,而不是把简单事情搞得复杂化。
学术研究质量的提升
高质量的研究不仅经得起考验,更能为后续研究提供具有说服力的证据,并成为有价值的参考来源。一般来讲,学术研究质量的控制可以通过对研究的“信度”和“效度”评估来实现。这里所指的信度是研究结论的误差度,而效度则是一个“宏”概念,反映了理论推理与研究证据的一致性。心理学中已经建立了一些有效的评判方法。例如,早在2001年,国外的《应用心理学杂志》、《咨询与临床心理学杂志》、《实验教育学杂志》、《当代教育心理学》等17种学术期刊编辑指南中就明确要求作者在报告p值的同时“必须”附带效应大小的值。另外,为了提高研究的质量,有学者还建议在因素分析中要报告构想系数,并要求把信度和效度数据设置在0.75以上作为可接受的底线,以及建议避免运用进级分析等。
当然,相关的研究人员还在不断地探索更有效的方法,以保证学术成果质量的提高。例如,“置信区间”(confidence intervals)就是一个最近流行的假设验证方法,并正在开始取代p值的地位。所谓“置信区间”,主要反映干预效应的测量值,表示干预效应大小的范围。置信设立为一个上限和下限,以使包含在一个随机区间内的拟合参数等于1-α。用公式表示为:
p[θL(X)≤θ≤θU(X)]=1-α
其中,θ为关注的参数;θL(X)和θU(X)为随机置信的上限和下限,主要基于观察数据X和p值概率。由于θL(X)和θU(X)直接表述为θL和θU,而且取决于随机数据,所以我们可以理解为置信的上、下限是随机的。在实际应用中,由于置信区间告诉我们可能的效应大小范围,所以,作为结果的判断,它更优于p值。从实践的意义上讲,由于置信区间直接反映效应大小,对研究的结果解释更直观。理论上讲,统计学上的意义并不表示干预效应。所以,在很多情况下,统计没有意义,并不意味着实际没有效应。同样,统计出现了意义,也并不一定表示对实际具有重要性。
置信区间的优势在于验证研究假设的方法简单易行,其原理为:首先,假设置信水平为95%。这意味着构建的置信区间有95%的机会包含了真实的干预效应值(换算成p值则表示为出错率小于0.05)。这样,判断过程表示为:如果置信值落在“无效应”值区,差异则表示无统计意义(对于一个95%的置信区间,无意义在5%的水平上);如果置信值落在“无效应”值区外,差异则视为具有统计意义(对于一个95%的置信区间,有意义在5%的水平上)。所以,“统计意义”(相当于p<0.05)被认为是“置信区间”,但对于一个具体的观察数据来说,这些区间反映了可能的最大和最小效应值。
置信区间之所以优于传统的假设验证,是因为它能够告诉我们更多的信息。例如,区间的上、下值反映了真实效应可能存在的大小。从区间宽度看,窄的区间说明效应大小存在一个小的范围。这样,任何远离这个区间的效应都可以很肯定地被研究排除在外。这种情况通常会出现在大效应的研究中。这样,对真实效应的估计通常会很准确。也就是说,研究有足够的“检力”来选择效应。但是,对于一个宽区间来说,意味着可获取多个效应范围,则认为研究效应可能很小。因此,任何效应大小的评估都可能是不准确的。这样的研究通常被视为较低“检力”的研究,而且可提供的信息也是很有限的。
如同p值一样,置信区间提供了判断研究效应的描述。然而,需要指出的是:从理论上讲,组间的差异是通过计算获得的,这样,置信区间提供了可观察的“统计意义”差异。但是,正是因为简单地凭借机会很难观察到这个差异,导致我们判断结论不是真实的。根据定义,20次有意义的发现中出现1次假的,则可能被误认为非真实的事件。这通常被称为“Ⅰ型错误”。虽然这很不幸,但在统计意义中这又是不可避免的。而且,统计比较的计算次数越多,这种错误的发生率就越高。另一方面,有时“统计意义”可能错误地被描述为一个重要的结果。其实,“统计意义”仅仅是关注干预之间的数据是否产生了差异。对于一个大样本的研究来说,发现了“统计意义”的差异,可能对实际的指导意义也不大。关于这一点的统计描述,可基于研究样本量来考虑结果的重要性(具体参见表3-10)。
表3-10 研究结果表述中统计意义与样本量的角色

总之,从研究的质量上看,主要反映的问题是研究人员普遍对理论的作用认识不足,研究设计缺乏科学的计划。数据分析手段落后,甚至有错误运用,而且也不严谨,导致研究普遍存在“检力”较低的现象。在研究成果的展示方面,一些关键的环节和数据被忽略。经过初步的“检力”分析,结果发现,约有90%的研究可能存在“检力”不达标的问题。所以,强调研究“效应大小”的重要性应该得到重视。未来我国体育社会心理学研究发展,改进方法学应该是一个较好途径。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











