



6.2.4 等级识别
基于相似度矩阵的等级聚类算法把同一主题相关的词汇聚集在一起,实现对不同主题相关词汇的划分,但各簇内词汇之间的等级关系尚不确定。等级识别算法采用统计方法,旨在把每个簇中的词汇组织成等级结构,实现叙词表等级关系的识别。分析现有汉语叙词表的词族索引中词汇等级的分布特点,与词汇在等级结构中所在级别相关的因素主要有:①词频。通常认为词频越高的词汇语义越宽泛,成为上位词的可能性越大;②词长。词长越长,词汇所揭示的概念越具体专指,成为下位词的几率越高。这样,根据这些因素对词汇所处等级位置进行量化表示,用H代表等级系数,某词汇Ti的等级系数可以定义为:
![]()
其中,Freq(Ti)为词汇Ti的总词频;N表示词汇Ti所含有的词素个数,用正向最大匹配算法对词汇Ti进行词素切分所得。这样,我们可以根据需要建立等级的数目和等级系数确定词汇在等级结构中所处的等级层次,词汇的等级系数越大,它在等级结构中的位置越高。
Forsyth和Rada曾经设计一种完全基于词频的等级识别方法[12]。其算法前提是:①高频词具有较为宽泛的含义,而低频词含义较为狭窄;②如果具有不同词频的两个词汇p和q,其密度函数形状相同,则判断它们词义相似。由此推导出高频词p是低频词q的上位词。本文借鉴了他们的方法,首先选择需要生成的K个等级层次,按等级系数把各个簇中的词汇分成K个等级层次,对于每个等级层次中的词汇,如果位于等级层次低的词汇与其上一等级层次中的某个词汇语义相似度最高,则认为是该词汇的一个下位词。具体实施算法如下:
步骤1:输入需要建立的等级数量K。
步骤2:根据等级系数,把簇中的词汇归入到K个不同的词级中,每个等级系数段对应一个词级。
步骤3:最高词级定义为level0,低词级依次定义为level1,level2...
步骤4:在相邻层次产生父—子连接。对leveli中的每个词t,计算t与leveli-1层中每个词之间的相似度,t成为与之最相似的那个leveli-1层词的子节点。如果leveli-1层中有多个词符合该条件,那么认为它们都是t的父节点,也就是说,一个词允许有多个父节点。
步骤5:在leveli中的每个词都与leveli-1中的词连接后,检查leveli-1中的词汇,识别出那些没有子节点的词,并把这些词传送到leveli层。
步骤6:判断是否到达底层,是则结束,否则执行步骤4。
经过该算法后,以上聚类结果中的各个簇中的词汇基本归入到不同等级中,如图6-8所示,再经过人工判定和调整后即可确定等级关系。
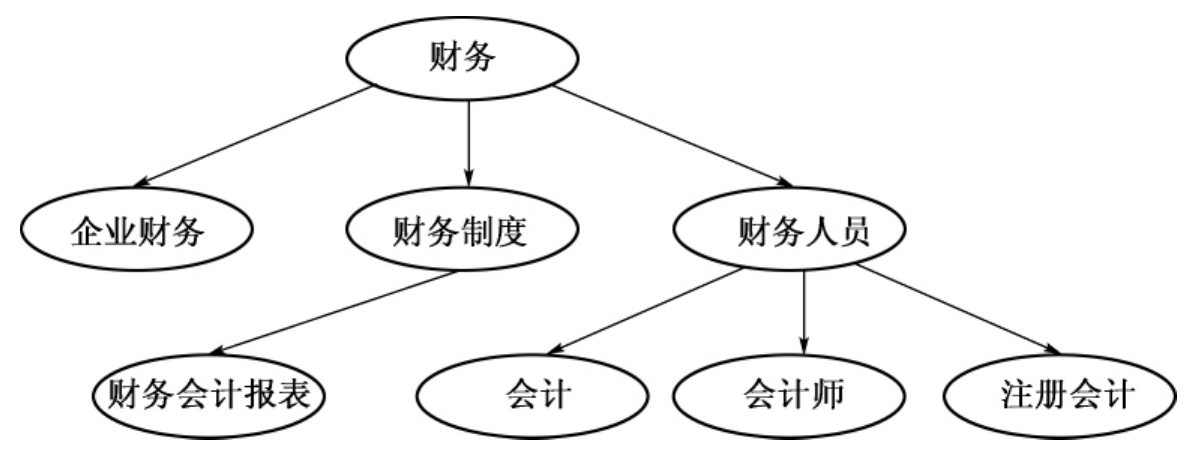
图6-8 等级识别结果示例
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










