



5.6.1 新词识别[4]
对于自然语言叙词表自动构建来说,新词识别具有很重要的意义,在词表收词和词表更新与维护两个阶段均能涉及。从领域文献直接识别新词的方法能及时发现学科领域内新涌现的自然语言语词,是自然语言叙词表收词的重要来源,也是词表更新阶段发现和增补未登录词的重要途径。
识别词表的未登录词首先需要分词,再从结果中过滤掉词表已有词汇,剩下的即为未登录词。由于中文行文为连续词串形式,词语之间无分隔符,使得中文分词成为自然语言处理首先要解决的问题。目前中文分词主要有三种途径:规则方法、统计方法以及统计与规则相结合的方法。本文所采用N-gram新词识别方法考虑任何成词可能,把语料充分切分成多个N元组,再通过统计方法和规则过滤方法去掉伪词串,最后过滤掉词表已有词汇,剩下的为未登录词。该方法的假设前提是:词汇的重要性与其长度和在文献中出现频率成正比,重要的关键词在文献中至少出现两次。其最大特点是无需考虑汉语语法知识,把语料充分切分成任何成词可能的词串,没有词边界问题。其流程图如图5-3所示。
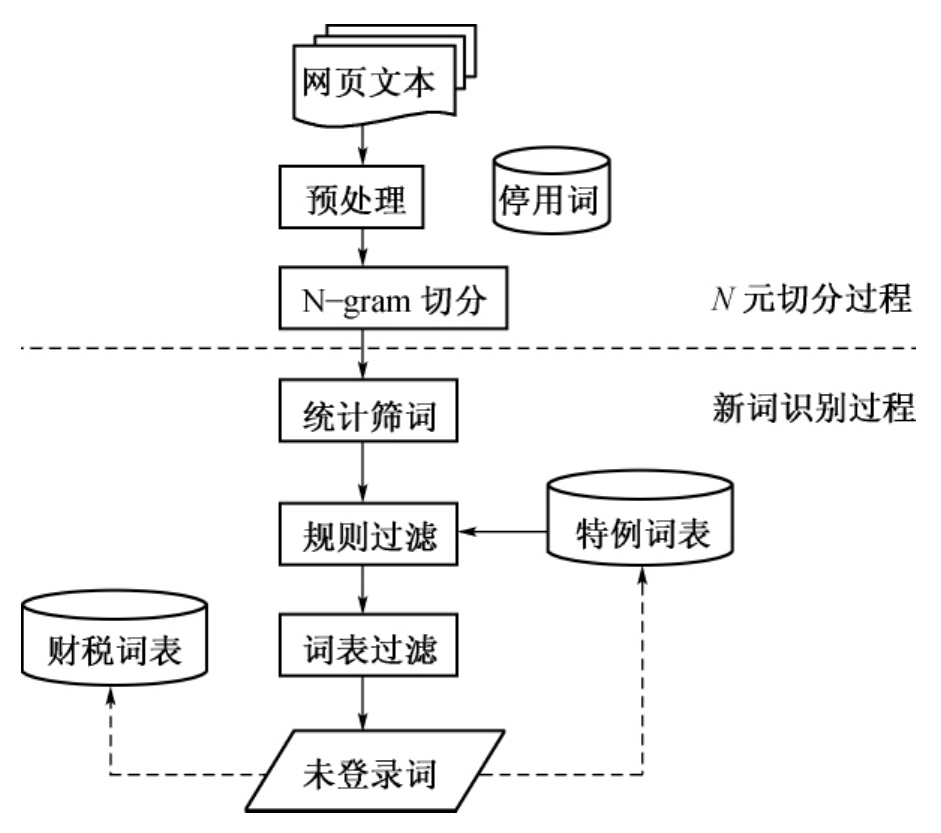
图5-3 新词识别流程
(1)预处理
将采集的财税网页统一转换为TXT文本后,过滤掉文本中的停用词,结果得到多个短句。停用词典主要收录了标点符号、特殊符号和停用词,包括HTML标记符号、“《”、“※”等。停用词过滤的目的是除去无检索意义的词汇,以提高后续操作的效率。如“税务登记是税务机关对纳税人实施税务管理的首要环节”。经过预处理后,过滤掉句中的停用词“是”、“对”、“的”、“首要”和符号“。”,得到短句“税务登记”、“税务机关”、“纳税人实施税务管理”和“环节”。
(2)N-gram切分
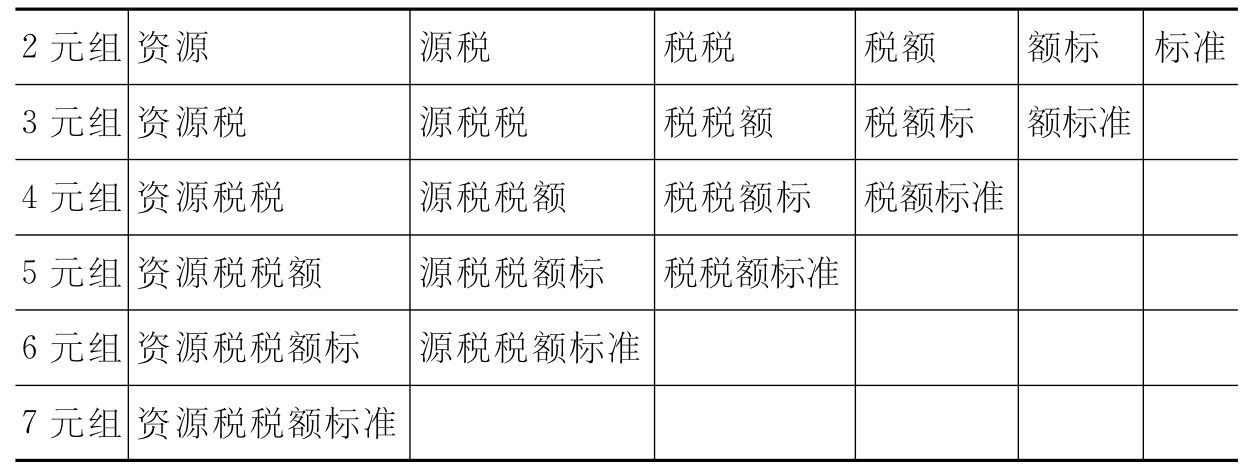
把经过预处理得到的短句充分切分成任何可能成词的N元组词串。由于中文关键词最大长度一般不超过15个字符,同时考虑到词表收录单个字符的词汇量很小,本文采取的方法是,把以上步骤得到的短句,充分切分成最长为15个字符、最短为2个字符的词串,同时统计各词串的频次。切分时把英文单词作为单个汉字处理。如:“资源税税额标准”经N元切分后得到以下结果(见表5-10):
表5-10 N元切分表
对于单篇文献,其论述主题用到的新词一般会多次反复引用。所以在词频统计完成后,把词频为1的词串作删除标记,既减少噪音,又能提高后续筛词的效率。
(3)统计筛词
对于N元切分后得到的各个N元组,首先经过统计方法剔除掉其中包含的部分伪词串。统计筛词分两步:首先进行相邻词比较筛选,然后通过对子串与父串的统计计算进一步剔除伪词串。
①相邻词串筛选方法
对于等长的相邻词串,如AB和BC、ABCD和BCDE等类型,它们含有相同元素并经常同时出现在相同父串内,如果其中一个是具有合理词边界的关键词,则另一个成词的可能性很小,几乎为零。另外,合法词汇易于与其他词组合使用,也就是说合法词汇出现在多个父串中的几率远远大于其相邻伪词串,其结果是合法词串的词频一般高于或等于其相邻词串。这样,把长度相同的相邻词串进行比较,把词频较低的相邻词串作删除标记。如以上N元切分结果中“资源税”在文本集合中出现的几率远大于“源税税”,程序通过词频比较后把“源税税”作为非法词串作删除标记。
②子串与父串筛词方法
对于具有包含关系的父串和子串,如ABCD与AB、BC、BCD类型,根据中文构词特点,多数长词由词义宽泛的短词组配构成,在语料库中,短词的词频往往高于长词,是筛词的一个依据。另外,合法的长词相对短词来说词义往往更专指,是较好的标引用词,同时也是词表优先考虑的收词对象,所以筛词时也要考虑到词长因素。张雪英在其博士论文中提出了一种基于GF/GL权重计算的抽词方法,并经试验证明该方法能够筛选出单篇文献中重要的表达词汇,而且速度快,抽词质量高,具有良好的应用前景,本文直接应用该方法对子串和父串进行筛选。
对单篇文献切分出的任意词串W的GF/GL权重计算方法为:
![]()
其中,FRE Q为词串W的词频,LEN为词串W的词长。
然后对词长相差小于等于k个字符的子串和父串进行比较,把权重较低的子串或父串作删除标记。如对于子串“税额标”和父串“税额标准”,当“税额标准”的GF/GL值大于“税额标”时,把“税额标”作删除标记,如果“税额标准”的GF/GL值均大于其他词长差异符合k值范围的父串和子串时,那么认为它是具有合法词边界的词汇,予以保留。其中k值的设置直接影响筛词的结果,k值越大,筛选出的合法词汇越少。经过反复试验发现,k值设置为1时,即对于任意词串W,只与词长大于W一个字符的父串和词长小于W一个字符的子串进行权值比较,筛词效果最佳。
(4)规则过滤
经过以上处理,能够剔除大部分伪词串,其结果经过词表收词过滤后,即为未登录词。但经试验发现,在筛词结果中仍然存在少量伪词串。经研究发现,大部分遗留伪词串存在一些规律,如首字和尾字是介词的话,该词串必定为伪词串。所以本文构建了一个“前停字表”和一个“后停字表”,把伪词串中常见的前字和后字集中起来,过滤掉符合条件的伪词串,提高筛词质量。前停字表和后停字表总结伪词串规律,在试验中不断扩充,是动态增长的特例词典。
这样,经过以上各处理步骤后,除去带删除标记的伪串,剩下的为成词的合法关键词。过滤掉财税表中已有的词汇并经过人工判断后,保存未登录词到底层词库中,同时累加词频。
(5)新词识别模块的使用
新词识别模块界面如图5-4:
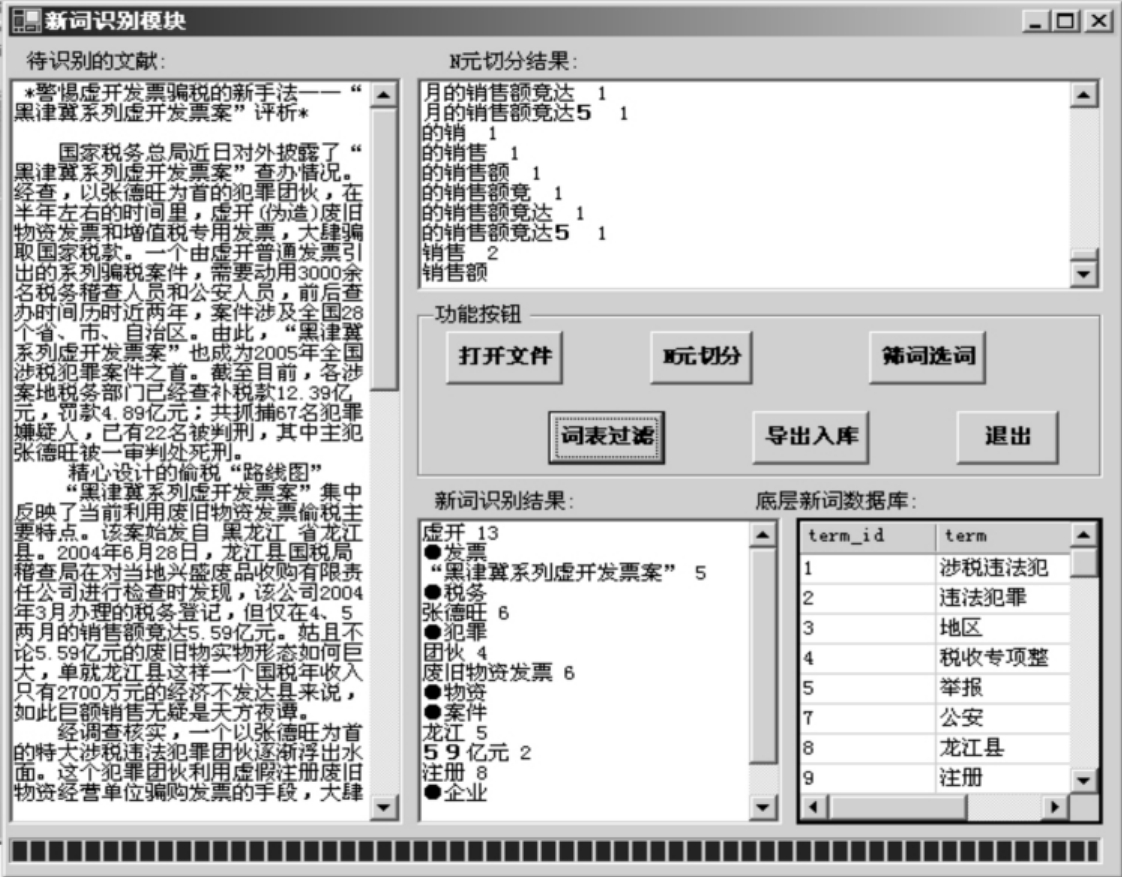
图5-4 新词识别模块
点击“打开文件”按钮,在出现的对话框中选择待识别财税文本对象,该文本全文即显示在左侧文本框中。点击“N元切分”按钮后,系统执行预处理和N元切分过程,同时记录各N元词串在整篇文本中出现的频次,并把结果显示在右上侧的文本框中。点击“筛词选词”按钮后,系统对切分出的N元词串进行统计筛词和规则过滤,把识别出的具有合法词边界的词汇显示在“新词识别结果”文本框中,点击“词表过滤”按钮后,系统把词表中已有词汇作“●”标记,剩余未作标记并带有词频的词汇即为未登录词,点击“导出入库”按钮后,可以把这些未登录词存储到底“层新词数据库”中同时进行词频累加。
例如:对单篇财税文本“警惕虚开发票骗税的新手法——‘黑津冀系列虚开发票案’评析”一文,识别出未登录词有:“虚开”、“发票”、“黑津冀系列虚开发票案”、“税务”、“张德旺”、“犯罪”、“团伙”、“废旧物资发票”、“物资”、“案件”、“龙江”、“59亿元”、“注册”、“企业”。经过词表过滤后,对“发票”、“税务”、“犯罪”、“物资”、“案件”、“企业”作已有标记,其余词汇为未登录词,可以收入到“底层数据库”中。
在实际应用中,新词识别结果较为理想,易于得到词长较长的专指词汇,基本符合自然语言词表自动构建的要求。但结果中仍存在部分通用词如“虚开”、“利用”等,还有极少数不合法词串(不成词的词串)。一般情况下,含义宽泛的通用词汇在文献库中往往具有较高词频,根据这个规律,批量文献经过新词识别后,未登录词按词频自大到小排列,把经过人工判断确认的高频通用词充盈到停用词典中,随着停用词典的丰富与完善,新词识别的性能会更佳。另外,可以考虑加入词性标注来增强规则过滤的有效性,进一步提高新词识别的性能。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。












