



7.3.3 词汇间的语义相似度计算
上面给出了语义编码间的语义相似度算法的详细过程。词汇间的语义相似度计算、词组(串)间的语义相似度计算都是以此为基础进行的。很显然,词汇间的语义相似度计算、词组(串)间的语义相似度计算的总体思路就是:将词汇映射到《词林》语义空间上去,获得相应的语义编码,从而就可以进行语义编码间的语义相似度计算。这里所说的词汇是泛指各种形式的中文词汇,包括复合词、词组等形式。图7-4为词汇间的语义相似度计算的流程。
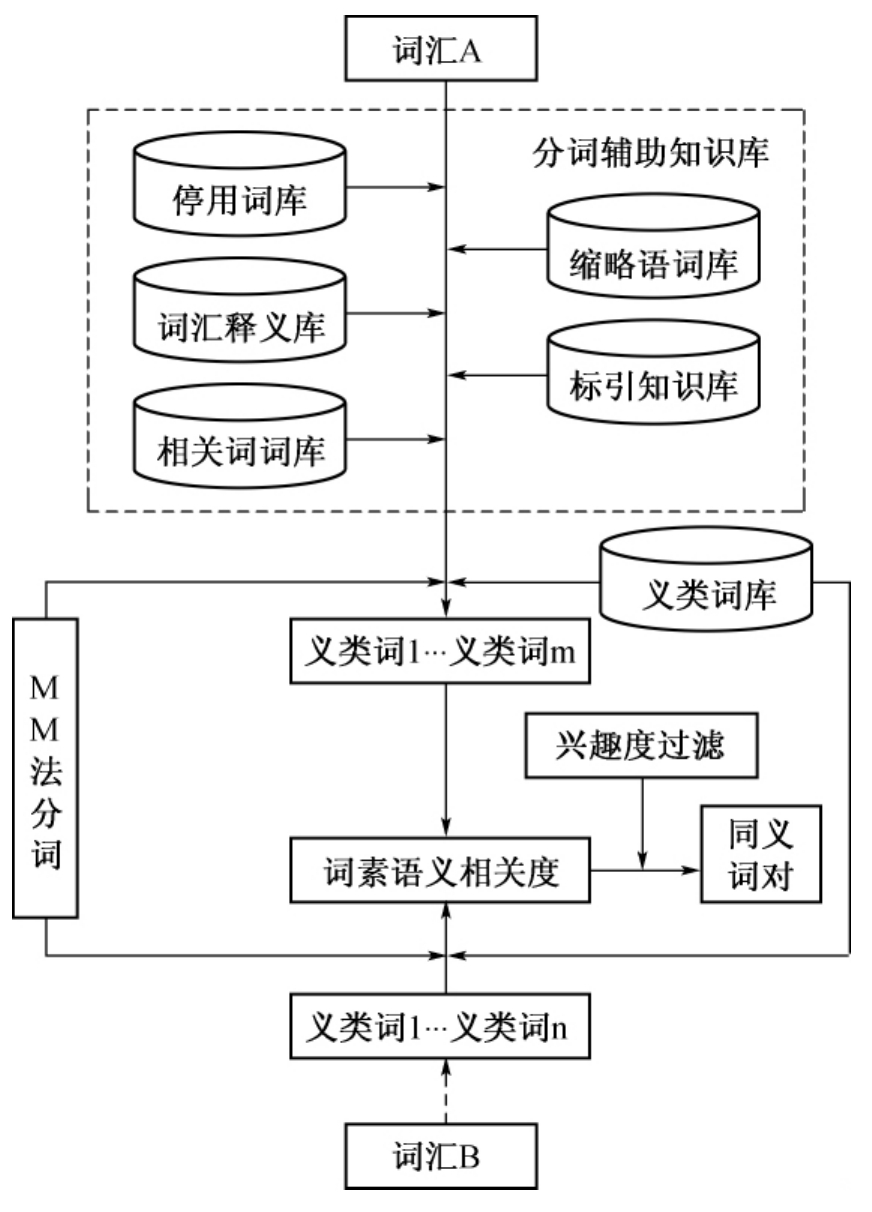
图7-4 词汇间的语义相似度计算流程图
(1)同义词挖掘资源介绍
同义词挖掘涉及的词库有分类知识库、停用词库、缩略语词库、词汇释义库、相关词词库、义类词库(即《词林》)。
●分类知识库。来源于制作的分类数据库,详见本书第6章。
●停用词库。对词汇进行义类词切分时,有些不能成为义类词的字符要予以过滤,主要有对词汇进行修饰的标点符号,如双引号、单引号、书名号等;虚词,如“啊”、“哦”、“吗”等;通用词(称之为半停用词),如“问题”、“论述”、“概述”、“性质”等等。本系统停用词素库中共包含停用词500余条。
●缩略语词库。为了表达的简洁明快,将较长的词语进行简缩,形成一个短小的词语称为缩略语[22]。为了避免缩略语(Abbreviation)的歧义切分,事先收集了大量的缩略语,其中大部分来源于《现代汉语缩略语词典》[22],其中含缩略语款目1 368条,缩略词平均词长为10(即5个汉字字符),而对应的全称词平均词长为22(即11个汉字字符)。缩略语对于计算机来说,如不加以控制(全称化处理),会具有机器理解上的歧义。例如,如“人行”中的“行”可作“银行”解释,也有可能作为“行走”解释;“中行”中的“中”可作“中国”解,也有可能作为“中央”解,如果借助于《现代汉语缩略语词典》,可以得到它们的全称分别为“中国人民银行”(或“人民银行”)、“中国银行”。此外,缩略语还具有较强的能产性,而且有些核心词素可以造成数以百计的缩略语,例如标示单位名称的“联”、“协”、“会”、“办”等的能产性很高。缩略语的能产性,不仅表现在它自身的成族创造,而且还表现为一些双音节缩略语成为构成新词的一部分,有了构造新词的能力。所以建立缩略语词库,不仅对减少词汇歧义有帮助,还对未登录词的识别有很大的启发作用。缩略语词库的记录由缩略语字段和对应的全称字段组成。
●词汇释义库。《词林》中未收录的词称为未登录词,通过大规模语料库统计,可以得到相当数量的未登录词。对于这些未登录词,在《现代汉语词典》(以下简称《现汉》)中登录的,称为一级未登录词,将还未登录的词称为二级未登录词[23]。对于一级未登录词,根据这些词在《现汉》中的释义文本,向《词林》中增补这些词,具体方法见第二小节。对于二级未登录词,可以依据相关词词库和标引知识库,来寻找这些未登录词的相关词,将对应的相关词的义类号作为当前未登录词的义类号。若在相关词词库中还未找到对应的相关词,就利用字面相似度替代词素语义相关度来进行同义词的挖掘。
●相关词词库。利用相关词可以识别《词林》中的大部分二级未登录词。相关词的数据方法主要是以分类知识库作为语料库,利用相关度度量和兴趣度过滤得到与一个词最相关的词。由于处理方法与第4章知识库数据处理相似,在此也不再作说明。值得注意的是,为了使相关词词典具有较高的质量保证,必须设定合理的强规则。
相关词词库的数据样例如下:
147团场 生产建设兵团
创业板 股票市场
●义类词库。义类词库中除了包含《词林》中的义类词外,还应事先收集大量义类词。它的制作方法是先以《中国分类主题词表》(以下简称《中分表》)中主题词作为义类词切分对象,进行手工切分,以保证义类词的质量,再利用《题录库》中的关键词进行义类词词库的扩充,如加入“中间业务”等义类词。
在进行同义词挖掘系统的设计时,对义类词库的维护设计是比较重要的。由于《词林》本身也存在一些缺陷,如收词量有限、词分类不合理等,直接采用《词林》作为语义体系会产生同义词挖掘的错误。在进行义类词的维护时,加入“增”、“删”、“改”等模块,以保证义类词库的质量。
(2)词汇间的语义相似度计算方法
下面结合实例来说明具体计算过程。以“商务管理系统”和“商业管理系统”两复合词为例,两者的语义相似度计算步骤如下:
①词组的切分
利用最大匹配法(MM法)将两词切分成义类词:
“商务管理系统”切分为义类词:“商务”、“管理”、“系统”。
“商业管理系统”切分为义类词:“商业”、“管理”、“系统”。
最大匹配法在第3章已经提到过,同义词挖掘系统中是采用正向最大匹配法进行义类词切分的。
②语义编码的提取
根据义类词库提取出存在于义类词库中的义类词所对应的语义编码。
“商务”、“管理”、“系统”对应的语义编码分别为:Da010140、Hc020101、Dd060101。
构成编码集S1={Da010140、Hc020101、Dd060101}。
“商业”、“管理”、“系统”对应的语义编码分别为:Di180203、Hc020101、Dd060101。
构成编码集S2={Di180203、Hc020101、Dd060101}。
③语义编码间的相似度计算
本小节第一部分已详细阐述了语义编码间相似度的计算过程,这对彼此都只有单个语义编码的是适用的,但不能直接计算多个编码集之间的语义相似度。为此,提出了如下的算法计算多个编码集之间的语义相似度,即:


这样,便将编码集S1中的每个编码在编码S2中找到了对应的最相似的编码;例如{Da010140、Hc020101、Dd060101}中的元素在{Di180203、Hc020101、Dd060101}中寻找到的最相似的对应元素,即编码分别为:Di180203、Hc020101、Dd060101。
经过此步的计算可以得到每个最佳匹配中的相似度数值,作为进一步计算的依据。例如:{Da010140、Hc020101、Dd060101}中的元素与{Di180203、Hc020101、Dd060101}中元素计算的最大相似度分别为:1/8、1、1。
接着,根据词汇“重心后移”思想,对于每个编码按照1,2,3,…,N(N为编码集的元素个数)的权重方案,计算平均相似度,作为两词汇的语义相似度计算结果。
续上例,计算“商务管理系统”与“商业管理系统”的语义相似度为:
Simi(“商务管理系统”,“商业管理系统”)
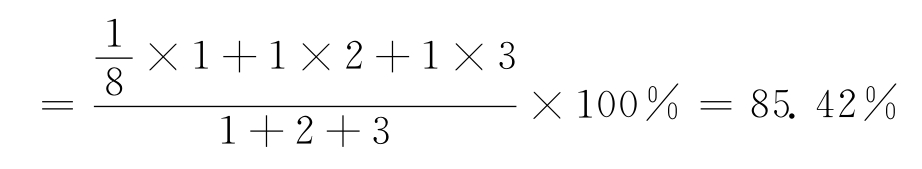
结果为85.42%,两词的相似度较高。
另一种计算方法是依据以下公式进行的,即:
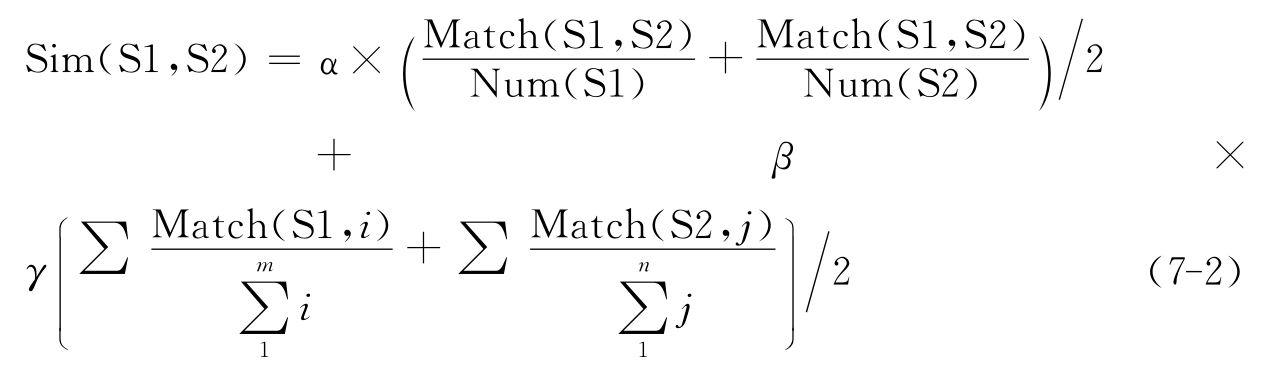
其中:
α:两编码集含有相同元素的个数对语义相似度的影响权重,在此系统中设为0.6;
β:相同元素在各编码集中的位置关系影响权重,在此系统中设为0.4;
γ:位置系数,γ=Min(Num(S1)/Num(S2),Num(S2)/Num (S1));
Match(S1,S2):表示两编码集中含有相同元素的个数;
Num(S1)、Num(S2):分别表示编码集S1与S2所含元素总数;

所处位置的权重之和。
需要指出的是,这里所说的“相同”,不像字面相似度那样直接找到两词汇中的相同部分,由于本算法研究的是编码,而非简单的字、词,所以在进行语义相似度计算时,可取一编码集中每个元素在另一编码集中的最相似的元素的相似度作为相同的元素单位,即一编码集的元素在另一个编码集中找到的最相似的元素,且它们之间的语义相似度为0.125,则认为两个元素中0.125个相同的元素。之所以能进行这样的计算,是因为基于《词林》的语义体系是一个树型结构,易于进行一些基于语义距离的计算,这是字面相似度算法所无法比拟的。
根据公式(7-2),计算“商务管理系统”与“商业管理系统”的语义相似度为:
Simi(“商务管理系统”,“商业管理系统”)
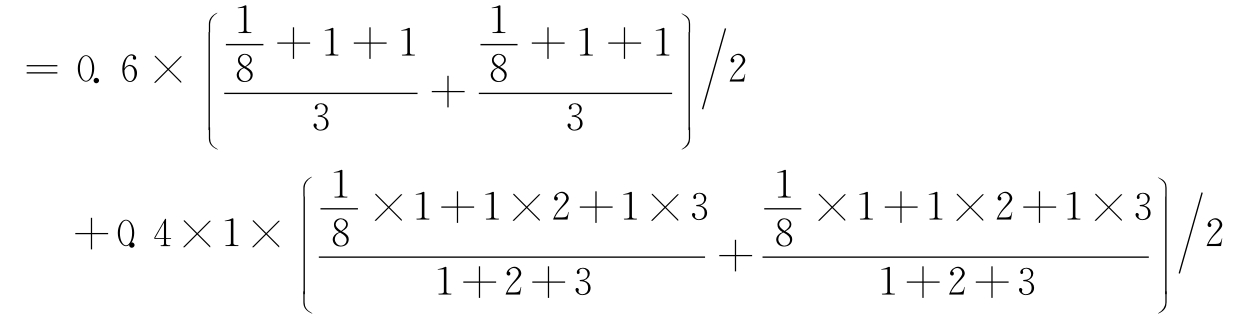
![]()
在同义词挖掘系统中是采用公式(7-2)进行词汇的语义相似度计算的。表7-1给出了其他例子的计算结果。
表7-1 词汇语义相似度计算结果样例

在词组的切分过程中,对存在的切分碎片,如“MP3”、“A股”等,要加入人工审定词表,以供以后进行人工语义编码。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










