



第一节 判断模型拟合优度的统计指标
要检验模型与数据是否拟合,需要评价模型的拟合优度,我们一般用一个综合数字即拟合指数来表示。大多数拟合指数都是基于拟合函数计算出来的,而评价结构方程模型的拟合函数极其繁多,文献上先后出现了七十余种,由此计算出的被人们所接受的拟合指数也高达四十余种,但到目前为止,习惯于用来评价结构方程模型检验结果的拟合指数只限于发展得较早较成熟的几种,根据侯杰泰(2002)、王晓玉(2004)等人的归纳,主要有以下七种。
一、χ2指数
由于大部分拟合指数都以χ2指数(卡方指数)为基础(即χ2的函数),只是加上各式各样的修正,因此,χ2指数是用来反映模型整体拟合优度的一个重要的指数,也是一个传统上用来衡量实际的协方差矩阵与预测的协方差矩阵之间拟合的紧密度的一个指标。较小的值,一般高于0.05的显著水平,可以表示实际的协方差矩阵和预测的协方差矩阵之间没有显著差异,因此,在假设的模型和实际用来验证模型的数据之间有较好的拟合优度。然而,根据Hair等(1992)的观点,χ2指数经常会对样本量过于敏感,并且随着样本规模的增加,χ2指数有更大趋势解释等价模型的显著性差异;因此,为了避免χ2值受到样本量大小的影响,在对模型的拟合优度进行评价时,一般用χ2/df即卡方指数除以自由度df来评价模型的拟合程度,根据Carmines和Micver(1981)的观点,卡方值和自由度之比应小于或等于3,而Wheaton等(1997)认为这一指标可以在小于5的范围内被接受。
二、渐进误差均方根
渐进误差均方根(RMSEA),这个指标早在1980年就由Steiger和Lind提出,但直到最近,学者们才认识到这个指标是用来反映协方差结构模型信息的最重要的指标之一,RMSEA值越小,表示模型的拟合优度越高。一般认为,RMSEA值小于0.05表示模型具有很好的拟合度,而在0.05~0.08之间表示模型有合理的拟合度,在0.08~0.10之间,表示模型只有普通的拟合度,当RMSEA值大于0.10时,表示模型拟合度很差。
三、优良拟合指数和调整的优良拟合指数
优良拟合指数(GFI)也是反映结构模型检验效果的整体拟合指数,它是对假设的模型能够解释的方差和协方差的比例的一个测度,如果参考参数的数量对这个指数进行计算,就会产生调整的优良拟合指数。调整的优良拟合指数(AGFI)的基本用途是用来诊断模型拟合是否通过过多的协调关系数的过度拟合数据导致的。通过下面的计算公式可以反映出优良拟合指数和调整的拟合指数之间的关系:

式中:(p+q)——观测变量(指标)的数目;
 ——观测变量的方差和协方差的全部数目(称为数据点);
——观测变量的方差和协方差的全部数目(称为数据点);
df——自由度。
参数相对于数据点越少和自由度越大,调整的拟合指数就越接近于优良拟合指数。
优良拟合指数和调整的拟合指数的值域都在0~1之间,从0~1表示拟合度越来越好,研究者们习惯上认为,优良拟合指数大于0.9,就可以表示假设的模型可以接受,而对于调整的优良拟合指数,一般也可以认为应该超过0.9,但Sefars和Crover(1993)提出,优良拟合指数和调整的拟合指数的容忍范围可以降低到0.8以上的范围。
四、均值平方残差的平方根
均值平方残差的平方根(RMR)也是用来反映模型检验结果的整体拟合指标,均值平方残差的平方根的含义是观察的输入矩阵和估计矩阵之间残差的平均数的平方根,其计算公式为:
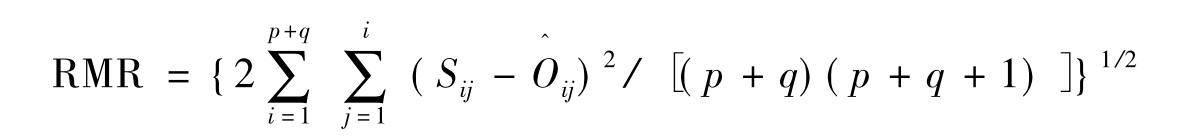
均值平方残差的平方根的值域在0~1之间,其值越小,表示模型的拟合度越好。一般认为,这一数值小于0.05,表示模型具有比较好的拟合度,Chau(1997)建议这一指标的接受值不应该超过0.10。
五、规范拟合指数
规范拟合指数(NFI)是Bentler和Bonett(1980)提出的,也是一个被经常采用的拟合指标,其计算公式为:

式中: ——建立模型的卡方值估计;
——建立模型的卡方值估计;
 ——假设模型的卡方值估计。
——假设模型的卡方值估计。
因此,规范拟合指数是用来测定独立模型和假设模型之间卡方值的缩小比例,但规范拟合指数这一指标有其局限性,一方面,在于它不能控制自由度,因此,可以通过增加参数来减少卡方值;另一方面在于规范拟合指数的抽样分布平均值与样本规模正相关,因此,在小样本时,这一指数可能会低估模型的拟合度。规范拟合指数的分布范围应该在0~1之间,从0~1表示拟合度越来越好(1表示完美拟合),一般认为这一指标应该大于或等于0.9。
六、增量的拟合指数
增量的拟合指数(IFI)是Bollen(1989)用来克服规范拟合指数的局限性的一个指标,这一指标能够减少NFI指标的平均值对样本规模的依赖,并考虑了设定模型的自由度的影响,其计算公式为:

式中: ——独立模型的卡方值估计;
——独立模型的卡方值估计;
 ——假设模型的卡方值估计;
——假设模型的卡方值估计;
dfmodel——设立模型的自由度。
IFI的值域是0~1,值越大,表示模型的拟合度越好,一般接受的标准是大于等于0.9。
七、比较拟合指数
比较拟合指数(CFI)是Bentler于1990年提出的,是通过与独立模型相比较来评价拟合程度的统计指标,其计算公式如下:

其中,τindep=χ2indep-dfindep,而τmodel=χ2mod el-dfmodel。比较拟合指数的值域也是0~1之间,一般认为0.9及其以上的值域表示模型的拟合度较好。
上面介绍的各项指数都是衡量结构方程模型拟合优度的重要标准。由于没有哪一项指标能够全面地反映出模型的拟合优度,因此,国际上比较常用的方法就是用拟合指数“大拇指法则”来对模型的拟合优度进行判断。构成大拇指法则的指标即上面所介绍的这几种常用指标: 、RMSEA、GFI、AGFI、RMR、NFI、IFI、CFI。本书研究也将根据国际惯例,采用这些指标来对模型的拟合优度进行判断。
、RMSEA、GFI、AGFI、RMR、NFI、IFI、CFI。本书研究也将根据国际惯例,采用这些指标来对模型的拟合优度进行判断。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。









