



5.3.4 基于相关反馈学习的检索方法
相关反馈技术是知识检索中提高检索相关度的一项重要技术。要提高相关度,系统就必须正确理解用户的检索要求。但是用户在使用知识检索系统的时候,往往无法输入准确表达自己需求的检索式,尤其是在允许自然语言输入的环境中,用户的初始检索式可能是错误的、模糊的或不充分的,有时随着检索的深入,用户可能会调整初始时的检索要求。传统的信息检索系统默认为用户的检索要求始终不变,不允许用户更改初始检索式,因此很难进一步提高相关度。但如果将人考虑成为系统的一部分,通过用户与系统间的反复交互,不断反馈学习形成新的检索式和检索结果,则可以逐步提高检索的相关度,基于这种思想的检索技术被称为相关反馈技术。它利用用户的反馈信息和反馈过程,逐步了解用户需求,优化用户模型,完善检索结果。
1.相关反馈技术
在许多关于信息检索的文献中,都有对相关反馈技术的介绍,如果将它扩展到知识检索领域,可以得到如下的表述。
对于任何一个检索式Q,知识源K中的知识都可以分为相关的和不相关的两类,假设知识源中所有相关知识的集合为R,所有不相关知识的集合为S,知识检索系统采用的匹配函数为M,则检索所得的结果知识集为{K|M(Q,K)>T},其中,T是一个给定的阈值。
一个理想的检索式Q0应该满足:对于任何的K∈R,有M(Q0,K)>T,而对于任何的K∈S,有M(Q0,K)≤T。相关反馈技术就是要使检索式逐步逼近Q0。首先,由用户输入初始检索式Q1,得到检索结果集K1={K1|M(Q1,K1)>T},用户从K1中选择出相关的知识和不相关的知识反馈给系统,系统根据反馈结果,将相关的标引概念加入检索式,或者去掉不相关的标引概念,形成新的检索式Q2,并再次提交进行新的检索,如此反复。每一次的调整过程都可以用下面的公式表示:
Qi=Qi-1+cK,M(Qi-1,K)-T≤0且K∈R
Qi=Qi-1-cK,M(Qi-1,K)-T>0且K∈S
其中c是矫正增量,它的值是任意的,因此经常被设置为1。
2.知识检索方法
图5-9显示了基于相关反馈学习的知识检索方法的主要原理。
该方法的实现步骤如下:
①用户反馈相关结果集;
②相关反馈学习新的用户知识,并利用新知识修改用户模型知识库中的用户兴趣模型;
③利用新的用户模型扩展检索式;
④检索数据库并返回检索结果,如果用户对结果满意则结束检索,否则转①。
其中检索结果集的反馈、用户知识的相关反馈学习和检索式的扩展是该方法的重点技术,描述如下。
(1)检索结果集的相关反馈
按照用户对相关结果集的反馈方式,相关反馈可分为三种:
一是全文反馈,即在用户反馈某一相关知识文档后,这一文档的全部内容都将被用来产生标引概念。
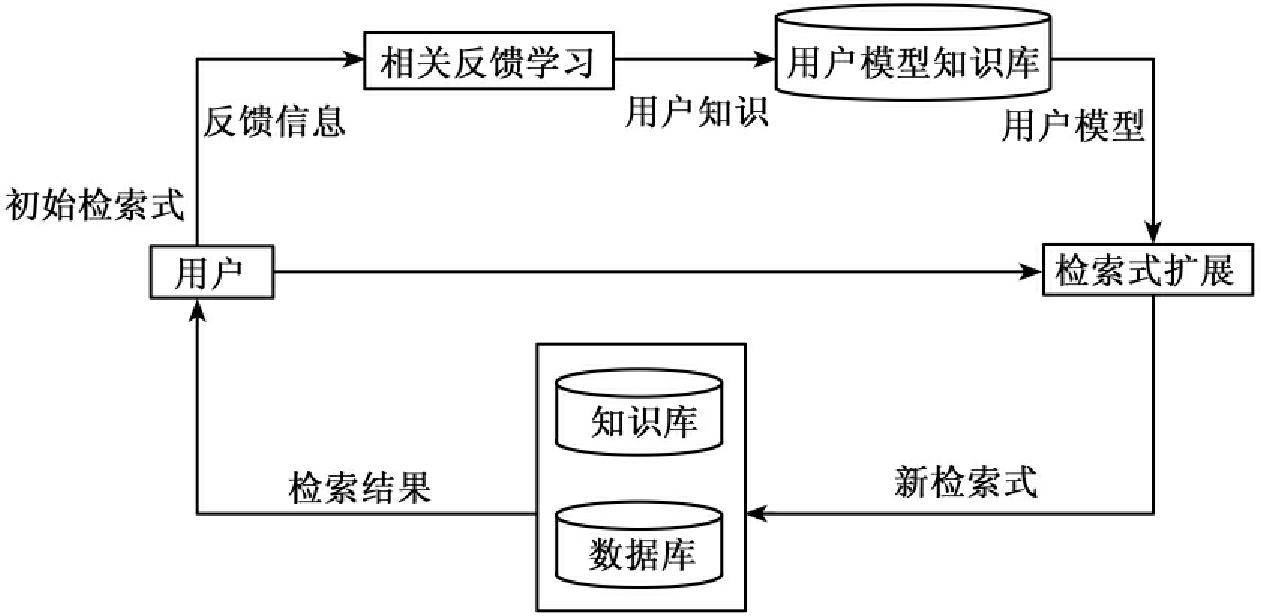
图5-9 基于相关反馈学习的知识检索方法原理图
二是语义段反馈,即用户选择某一知识文档的部分内容进行反馈,标引概念也只从被选择的语义段里产生。这种反馈方式相比起全文反馈,其优势在于对复杂的大型文档的检索。这种文档往往含有较多的知识点,跨越多个学科,而用户常常只需要其中的某一个或几个知识点。如果采用全文反馈,用户只能以整个文档为单位进行选择,不相关的内容也会被系统认为是相关的,从而干扰了标引概念的生成。文档越复杂,这种干扰性也就越强。但是如果采用语义段反馈,用户只选择涵盖相关知识点的段落反馈回来,就可以避免或减少以偏概全。大量试验证明,对复杂文档进行语义段反馈是行之有效的。在语义段反馈中,语义段的长度如何确定是一个关键性问题。一般来说,语义段的长度是固定的,一些试验证明,语义段长度在200~300词时效果最好。在有的试验系统中,也有过完全由用户自己决定语义段的长短的尝试,这样做可以更好地反映用户的需求,但是增加了系统的运行负担。
三是概念反馈,在这种反馈方式中,系统并不是将检索到的知识直接提供给用户进行选择,而是对其进行进一步分类聚化,按类或族提炼出主题概念,用户从这些主题概念中选择相关者,用于修改检索式。这种方式节省了用户进行文档浏览时所用的时间,但需要高效的算法来分析和组织检索结果。
(2)相关反馈学习算法
相关反馈学习是相关反馈技术应用时的核心部分,在知识检索中,相关反馈学习的效果直接关系到用户兴趣模型的构建。相关反馈学习算法如下:
●提取反馈文档中的标引概念或概念特征集合;
●构建概念加权矢量;
●获取用户知识;
●修改用户兴趣模型。
在传统的相关反馈学习中,一般注重的是反馈结果,即什么是相关的和什么是不相关的知识。但如果要达到学习用户知识的目的,还应该考虑到用户的反馈行为,即为什么用户认为某一类知识是相关的,而另一类则是不相关的。围绕这个问题,出现了很多解释用户行为的方法,笔者认为采用概念特征集合是一个简单有效的方法。
所谓概念特征集合是指一套对某个标引概念在文档中重要程度进行衡量的标准。它可以包括:标引概念在文档中出现的频度、标引概念在文档中的分布状况和标引概念与检索式间的相互密切程度等。以标引概念c为例,我们可以用I(c)表示c的频度,T(c)表示c的分布,R(c,q)表示c同检索式q间的关系。
频度I(c)是相关反馈系统中表示标引概念权值的最常用的方法。I(c)的值越大,表明概念c在文档中出现的次数越多,重要性也越大。计算I(c)的权值可以采用基于概率统计的公式:
![]()
其中wi是I(c)的权值;N是数据库中文档的总数;n是至少包含了一次标引概念c的文档的总数;R是用户返回的相关文档的总数;r是至少包含了一次标引概念c的相关文档的数目。
对于一个标引概念c来说,如果它在文档中分布得越均匀,它就越有可能反映出该文档的主题内容。分布值T(c)正是基于这样一种思想来考察标引概念的重要性的。概念c在某一文档d中的分布权值wt可以用下面的公式进行计算:
wt=length(d)-(first(c)+last(c)+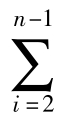 |eposi(c)-posi(c)|)
|eposi(c)-posi(c)|)
当pos1(c)≤distr(c)时,first(c)=0;
否则,first(c)=pos1(c)-distr(c)
当length(d)-posn(c)≤distr(c)时,last(c)=0;
否则,last(c)=length(c)-(posn+distr(c)),
eposi=posi-1+distr(c),
distr(c)=length(d)/n
其中length(d)表示文档d的长度;first(c)表示c在d中首次出现的位置;last(c)表示c在d中最后出现的位置;eposi(c)表示c第i次出现时的期望位置;posi(c)表示c第i次出现时的实际位置。distr(c)表示c在d中的期望分布值,n表示c在文档d中出现的总次数。由上式可以看出,T(c)的值是通过标引概念c在文档d中每次出现时的实际位置和期望位置的差值来量度的。差值越小,T(c)的权值就越大,表示c在文档中分布得越均匀。
概念特征R(c,q)主要通过标引概念c与最靠近它的某检索项之间的距离来量度,距离越大,表明c与检索式q的密切程度越小,反之亦然。R(c,q)的权值可用以下公式计算:
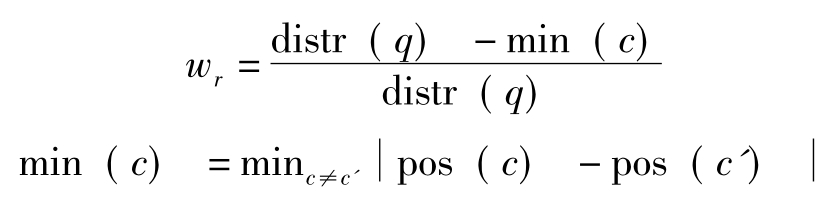
distr(q)=length(d)/occs(q)
其中distr(q)是文档中所有检索项的期望分布值,pos(c)是c出现的位置,min(c)是c与某个检索项间c'的最小距离,occs(q)是检索项在文档中出现的总次数。
将概念特征集合的权值组合起来可以形成概念加权矢量,例如,对于某个标引概念c,它的加权矢量是{wi,wt,wr}。知识检索系统可根据给定的阈值,选取权值最大的若干概念加权矢量,作为新的用户知识对用户模型进行修改。
假设在旧的用户兴趣模型中有若干个关于某概念c的权重信息,当加入新的用户知识时,可以通过如下公式对原有的权重进行修正:
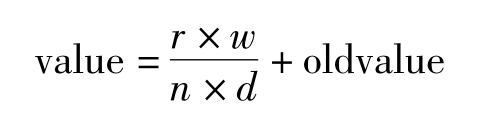
其中oldvalue是概念c在用户兴趣模型中的旧权重;r代表概念c所在文档的相关度,例如:当c代表相关文档时,r的值为1,而当c代表不相关文档时,r的值为-1;w是概念c的加权矢量的权值;n是返回的文档总数;d是一个调节常量。
修改后的用户兴趣模型被存放在用户模型知识库中,供扩展检索式或进行其他检索操作时使用。
(3)检索式的扩展方法
检索式的扩展是指对原有的检索式增加或删除检索项的操作,这里的检索项可以从知识库中的用户兴趣模型中获得。从用户模型中选取与本次检索相对应的概念,依其权重进行比较排序,形成新的检索矢量。在以向量空间为基础的检索系统中,可以采用著名的Rocchio算法修改检索式,设Qi为新的检索向量,Qi-1为原有的检索向量,R为相关文档向量,S为不相关文档向量,则Rocchio算法可用如下公式表述:
Qi=αQi-1+β∑R-γ∑S
这里的α,β,γ都是常量,被称为Rocchio权值,它们的值分别为1,1/|R|和1/|S|,也有些系统为了计算方便,将α,β,γ的值都设为1。另外,如果没有反馈不相关文档,可以省去算法中的S项。
在相关反馈的实际应用中,可以根据实际情况对多个系统变量进行修改,以获得最佳的效能,例如,可以改变反馈的相关知识的数目n和用于修改检索式的标引概念的数目m,还可以改变反馈的重复次数和相关度的阈值等。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











