



5.3.5 基于Agent的递归检索方法
利用Agent的移动性来实现分布式信息(尤其是网络信息资源)的搜索是一种高效、可靠的途径。其基本思想是移动一个检索Agent到一个站点上,成为本地Agent,并分析已存储的文档,若存在感兴趣的超链,则复制自身,生成一个具有相同代码的Agent来跟踪感兴趣的超链。其主要运行过程是:在搜索开始时,由用户创建第一个Agent(称为“根Agent”),并将它发送到一个指定站点,分析站点上所收集的HTML页面,并将感兴趣的页面(即与用户指定的关键词的相关度大的页面)地址URL返回。“根Agent”一旦在文档中发现一个链接到另一个站点的感兴趣的超链,在返回用户站点之前,便复制自身生成一个代码相同的Agent来完成跟踪超链的任务。新的被复制的Agent被发送到指定的远程站点,并递归地生成更多的Agent。递归搜索流程如图5-10所示。
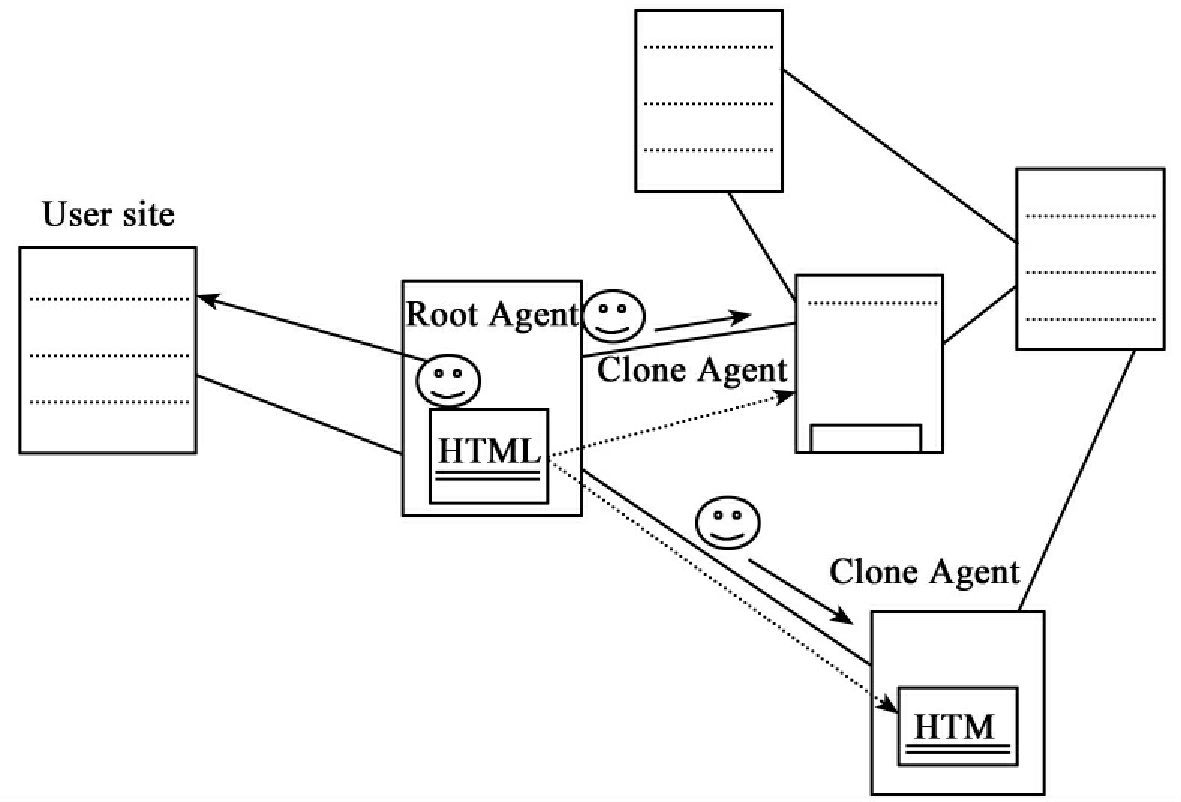
图5-10 Agent的递归搜索流程
为了避免无止境地生成Agent散布到网上,可以依照树的深度给定一个非负整数值来限定Agent的个数,用level表示,它代表离“根Agent”的距离。用户可以根据网络通信状况、能接受的等待时间以及对所需资料的详尽程度来设定一个最大的level值,用Lmax表示,处于Lmax层的Agent不执行复制操作。
具体来说,检索Agent的递归搜索过程分为五个步骤:
第一步,用户创建一个“根Agent”,并给出初始参数:关键词、访问的起始站点、Agent的level值、Lmax值以及用户站点。起始站点可根据类似于Robot的有关方法来确定或根据网上的目录服务(如Yahoo!)来指定。对“根Agent”来说,其level值设为0。Lmax值由用户根据实际情况指定。用户站点是必不可少的,任何Agent在找到所需信息后都会将其返回到用户站点。
第二步,Agent到达起始站点开始访问,它利用本地机制来检索信息,如果没有找到感兴趣的HTML页面,Agent返回用户站点。至于Agent访问本地资源的机制的选择取决于系统中采用的协调策略。
第三步,在感兴趣的HTML页面中,Agent能找出链接到其他站点的且含有相关或相近信息的超链,如果Agent的level值少于Lmax,它将为每个超链复制一个Agent来跟踪访问超链。新复制的Agent具有与“母体”Agent相同的代码、相同的关键词、相同的用户站点、相同的搜索深度,起始访问站点则根据超链设定。
第四步,每一个新创建的Agent到达指定的站点后开始本地搜索(同第二步),并将找到的页面URL返回用户站点。
第五步,将每个Agent所返回到用户站点的信息收集起来,将查询结果进行处理后提供给用户。
与搜索引擎的Robot相比,该搜索方法的优越性表现在以下三个方面:
(1)通过设定搜索深度Lmax,用户可以自行控制搜索过程,根据具体的搜索要求来控制搜索时间;
(2)只需Agent移动到服务器上,并不需要移动所有的数据,节约了网络带宽;
(3)网络连接的不可靠也不会影响Agent的工作,它可以在本地服务器上访问信息资源。
参考文献
[1]陆汝钤.世纪之交的知识工程与知识科学[M].北京:清华大学出版社,2001.
[2]Ingwersen P,J-rvelin K.The Turn:Integration of Information Seeking and Retrieval in Context[M].Springer,2005.
[3]VICODI architecture.Schema http:∥www.vicodi.org/2005-12-11
[4]徐国虎,董慧.基于语义的数字图书馆推理检索研究[J].中国图书馆学报,2006(3).
[5]董慧,余传明,徐虎,等.基于本体的数字图书馆检索模型(Ⅳ)研究[J]——历史领域知识推理机制.情报学报,2006(6):666-678.
[6]周宁,张玉峰,张李义.信息可视化与知识检索[M].北京:科学出版社,2005.
[7]张玉峰.智能情报系统[M].武汉:武汉大学出版社,1991.
[8]金燕,张玉峰.基于本体论的知识检索研究[J].图书情报工作,2004(7):41-43.
[9]金燕,张玉峰.基于中文自然语言处理的知识检索模型[J].中国图书馆学报,2004(2):60-62,63.
[10]张玉峰,王翠波.概念知识库的设计与学习方法[J].中国图书馆学报,2004(1):63-65.
[11]张玉峰,李敏,晏创业.论知识检索与信息检索[J].中国图书馆学报,2003(5):23-26.
[12]张玉峰,李敏.动态约束性概念网络与知识检索研究[J].情报学报,2003(3):278-281.
[13]艾丹祥,张玉峰.相关反馈技术在知识检索中的应用[J].情报科学,2003(10):1100-1103.
[14]张玉峰,文燕平.智能检索Agent系统研究[J].中国图书馆学报,2002(5):54-56.
[15]张玉峰,晏创业.基于机器学习的知识检索模型研究[J].图书情报知识,2002(4):6-9.
[16]李敏.基于认知理论的语义检索研究[D].武汉:武汉大学信息管理学院,2006.
[17]艾丹祥.基于本体论的知识检索研究[D].武汉:武汉大学信息管理学院,2004.
[18]李敏.网络医学信息资源的知识检索研究[D].武汉:武汉大学信息管理学院,2003.
[19]晏创业.基于机器学习的智能检索研究[D].武汉:武汉大学信息管理学院,2002.
[20]文燕平.智能检索Agent系统研究[D].武汉:武汉大学信息管理学院,2001.
[21]Sowa J F.Categorization in Cognitive Computer Science.∥Cohen H,Lefebvre C.Handbook of Categorization in Cognitive Science,Elsevier,2006,141-163.
[22]http:∥ciir.cs.umass.edu/
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。









