



6.4 基于领域本体的语义检索的实现
语义检索的实质是使得计算机能够“理解”用户的检索意图,核心技术是以领域本体的概念关系为基础,通过对本体中的概念关系进行解析和判断,推理出检索词之间的隐含语义关系,将检索从目前的关键词字面检索提高到语义检索的层面。
本文采用Java语言开发了一个基于领域本体的语义检索系统,该系统所采用的开发环境是Windows 2000,JDK 1.5,开发工具为JBuilder 2005以及语义开发包Jena 2.3。该语义检索系统可以初步对用户的检索式进行处理,判断其中具有检索意义的检索词之间的语义关系,使得检索词之间不再是孤立的状态,推理用户的检索意图,最终从语义的层面对用户的检索式进行处理,最终返回检索结果。通过实验发现,这种检索机制相比传统的关键词检索可以发现潜在的、隐含的语义结果,具有较高的精确率和召回率。
6.4.1 总体设计
基于领域本体的语义检索系统主要有以下四个模块组成:
(1)提问词分析模块
提问词分析模块的主要作用是对用户的提问式进行处理,过滤停用词,抽取具有检索意义的实词并且判断用户的提问中心。
(2)语义推理模块
语义推理模块的主要作用是根据用户的提问词进行语义关系判断,判断出各个提问式之间隐含的语义关系,明确用户的真正检索意图。
(3)查询分析模块
查询分析模块是在语义推理的基础上,根据语义关系,自动构建RDQL查询语句,对本体库进行查询,并且把查询结果返回给用户。
(4)本体管理模块
本体管理模块主要是本体的浏览、导航和可视化显示作用,通过本体浏览模块可以清晰地发现概念之间的关系,可视化组件可以对农学本体中的概念关系以动态图的形式直观展现出来。
整个语义检索系统的模块图如图6-9所示。
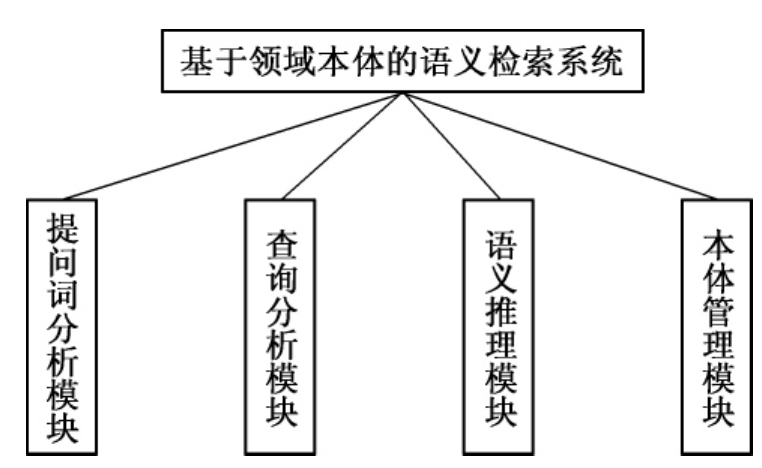
图6-9 基于领域的语义检索系统模块图
6.4.2 技术实现
1 提问词分析模块
提问词分析模块主要是对用户的输入的检索式进行初步处理,抽取其中具有检索意义的实词,同时对检索词进行标注,判断出用户的提问中心,为后续的语义关系推理做好准备工作。
(1)抽词
用户的检索提问通常为自然语言,其中通常含有一些不具有检索意义的虚词。抽词模块首先对用户的检索式进行处理,过滤掉提问式中的停用词,抽取其中有检索意义的实词。例如,用户输入“《齐民要术》的作者是谁?”这样一个提问式,经过处理之后形成“齐民要术作者”关键词序列。
(2)检索词标注
利用本体中的类别信息对检索词进行标注,将具体实例标注为其所属的类,这是对检索词进行的规范化处理,是建立计算机理解检索词的基础。例如,对于含义模糊的检索词“熊猫”则标注为动物或品牌,以便于进一步的语义判断。在本文中,标注的类型是农学本体中的类别(也就是概念分析中的分面)。以下为标注类型和标注符号:
地点PL
农书NS
版本BE
时间TI
人物PE
主题ZT
(3)抽取提问中心
抽取用户的提问中心,是对用户的检索词进行语义判断的基础。在用户的检索式中,提问中心通常是抽象词,而具体的实例则是对提问中心的限制或描述。例如“北京市图书馆”,其中北京市为具体实例,而图书馆则是提问中心;“明代《齐民要术》的版本”,则版本为提问中心。
根据以上分析,不难得出,抽取提问中心的方法是利用农学本体的类(Class)对检索式进行抽取,抽取到的类名词则为提问中心。以“华东地区收藏的齐民要术的版本”为例,经过提问词分析模块处理后的检索结果为:华东地区/PL齐民要术/NS版本/BE,What,其中PL为地点,NS为农业古籍,BE为版本,What为提问中心。
2 语义推理模块
传统的信息检索模型是将各个检索词看做是孤立的,忽略检索词之间的语义关系,这也是造成基于关键词检索的检索模型在一定程度上返回大量无关检索结果的原因之一。语义推理模块正是通过建立语义推理引擎,来判断用户检索词之间的语义关系,对用户的检索提问进行计算机理解。
(1)建立推理引擎的目的
本体的查询需要借助RDQL语言,但该语言本身不具备推理功能,只能查询模型中有直接关系的数据,例如在农学本体库中,有“湖湘本be_CollectedBy中国农业遗产研究室”、“中国农业遗产研究室located_in江苏”这样两条实例,它的意思是“中国农业遗产研究室收藏了湖湘本,同时中国农业遗产研究室位于江苏省”,由此,我们可以推断出“湖湘本藏于江苏省”这样一条结论。但是RDQL语言不具备这样的传递推理机制,不可能得出上述推论,因此必须引入推理机制,RDQL语言才能对所有的语义数据作全面的查询,从而获取用户满意的查询结果。
建立推理引擎的目的正是将本体中具有隐含语义关联的数据推理出来,获取所有相关联的数据作为RDQL查询的数据库。推理引擎借助于本体信息及相关的公理描述可以从基本的RDF描述中获取额外的断言(Assertion),经过推理处理可以获得RDF有向图中的所有语义闭包。当用户提交查询从RDF数据模型获取数据时,不仅能得到数据模型本身所含有的数据,而且可以得到由推理机制所产生的蕴含知识数据。
(2)建立推理引擎的方法
本文中采用的推理方法是利用Jena包中通用规则推理机制,采取工厂化方法GenericRuleReasonerFactory获得通用规则推理机,从而引入事先写好的形式化的规则库文件对农学本体库进行推理。之所以选择通用规则推理机是因为考虑到推理处的蕴涵知识的意义和推理效果,RDFS规则推理机(RDFS Rule Reasoner)、OWL-Lite推理机(OWL FB Reasoner)等内置推理机对农学本体库进行推理,得出的是基于描述逻辑的推理结果。
例如,这样一个推理规则:
(?a rdf:type rdfs:Class) (?a rdfs:subClassOf ?a)
该条推理规则的意思是:如果?a的类型是rdfs:Class,那么推理出?a是它自己的子类,也就是说如果有“禾谷类作物”这样一个类,那么“禾谷类作物”可以作为该类的一个子类存在。其实这种推理对于用户来说并没有任何意义。用户并不关心这样的知识,最后的结果是推理结果之后会产生大量的、无关的垃圾信息,影响系统处理的效率和效果。因此选择了通用规则推理的机制。
例如在本体库中存在“收藏机构locate_in地区”,“收藏机构collected农业古籍”,经过传递性推理就可以得出“地区collected农业古籍”。经过推理引擎处理,可以得出本体库中所有具有隐含语义关联的类以及实例间的语义关系。
(3)建立语义模式库
抽取本体库中所有的语义属性(主要针对ObjectType属性),按照(Domain,属性名,Range)的形式建立语义模式三元组构成语义模式库。根据语义模式库,经过相关计算就可以确立标注后的检索词之间的语义关系。
(4)确立检索词的语义关系
本体中的三元组都是“主语,谓语,宾语”的形式,用户的检索提问通常都是对主语或者宾语提问。通过步骤(1)的语义推理已经得到RDF有向图的所有语义闭包,因此若本体库中存在用户提问的检索结果,至多通过两个三元组组合便可以得到检索结果。
本文利用传统的向量空间模型构筑检索词的语义关系,将标注后的检索词以及语义模式库中的语义模式视为向量,通过余弦函数进行匹配判断。
For每一个语义模式向量
If Sim(检索向量,语义模式向量)>0.7 存入提问候选集
EndFor
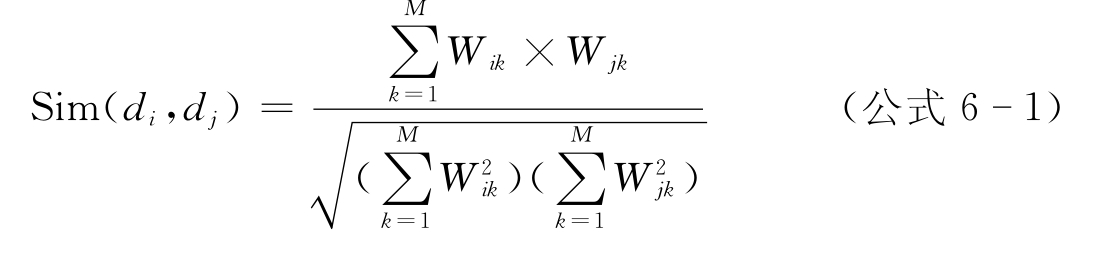
其中,di,dj分别为检索向量和语义模式向量的距离,W为分别对应向量。
仍以“华东地区收藏的齐民要术的版本”为例,经过语义匹配得到的提问候选集为“华东地区,collected,版本”,“齐民要术,has_edtition,版本”。
3 查询分析模块
(1)RDQL查询语句简介
RDQL[17]是Jena中针对RDF的查询语言,这种查询语言将RDF视为三元组,也就是带有向边的图,图的节点是资源(Resource)或者文字(Literal)。RDQL提供了一种图匹配策略,查询RDF中满足一定节点的图,查询结果返回匹配到的属性值。
RDQL满足一定的范式,基本由SELECT、FROM、WHERE 和USING字句组成。其中SELECT字句衔接的是提问中心,WHERE字句衔接的是查询条件,而FROM和USING字句分别衔接的RDF模型和本体的URI地址,由检索时设定。例如,在http://example.org/peopleInfo#查询年龄在24岁以上的人,具体的查询语句如下:

(2)构建RDQL查询语句
RDQL满足一定的范式,类似数据库查询中的SQL语句,因此构建RDQL查询语句的时候,只需要按照语法规则将查询内容和条件填充到指定的位置即可。其中SELECT字句衔接的是从检索词中抽取出来的提问中心,也就是标注为“WHAT”的查询词;WHERE字句衔接的是查询条件,也就是生成的语义关系组合,即满足一定语义关系的用户查询组合。因此把2(4)中形成的语义关系组合添加到WHERE字句之后,而FROM和USING字句分别衔接的RDF模型和本体的URI地址,在本文中即为农学本体。以“清代描述大麻栽培的农书有哪些”为例,生成的查询语句如下:
SELECT?x WHERE(c:齐民要术,c:has_edtion,?x),(c:华东地区,c:collected,?x)
USING c for http://www.owl-ontologies.com/unnamed.owl#
(3)查询结果处理
将(1)中形成的查询语句交给本体模型,如果本体中存在符合语义关系组合的三元组则返回属性值;如果不存在,则返回NULL。
4 本体管理模块
以树形结构表示本体的等级体系,将本体中的类表示为根节点,将实例表示为叶子节点,点击树的节点,可以显示该节点相关的各种属性。通过对树的浏览实现对本体的内容浏览,通过关键词查询可以检索到该关键词在本体中的等级关系以及所有的属性。
解析方法:

图6-10 领域本体导航图
(1)类的解析
利用listHierarchyRootClasses( )方法得到本体的根节点,然后利用listSubClasses( )方法对根结点判断是否有子类,通过递归的方法得到所有的子类。
(2)实例的解析
根据(1)得到的类,对每个类通过listSubClasses( )方法判断并获取类的实例,利用getLocalName( )方法得到实例的名称。
(3)属性的解析
首先利用is Datatype Property( )和isObject Type Property( )方法判断是数据属性还是对象属性,然后利用各自不同的特征对属性进行进一步解析。如果是Datatype属性,则属性值为Literal类型,如果是Object Type属性,则属性值为Resource类型。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











