



6.5.2 基于文本分类的方法
相似度系数是一种比较简单有效的评估方法,但是需要首先保证人工标引的质量,很难客观真实地反映关键词自动抽取方法的性能。文本信息自动处理的根本目标不是关键词本身,而是它们在实际应用系统获得的检索性能。自动分类是最常用的文本信息自动处理技术之一。运用关键词进行自动分类的能力被认为是评估关键词自动抽取方法性能的最佳手段。
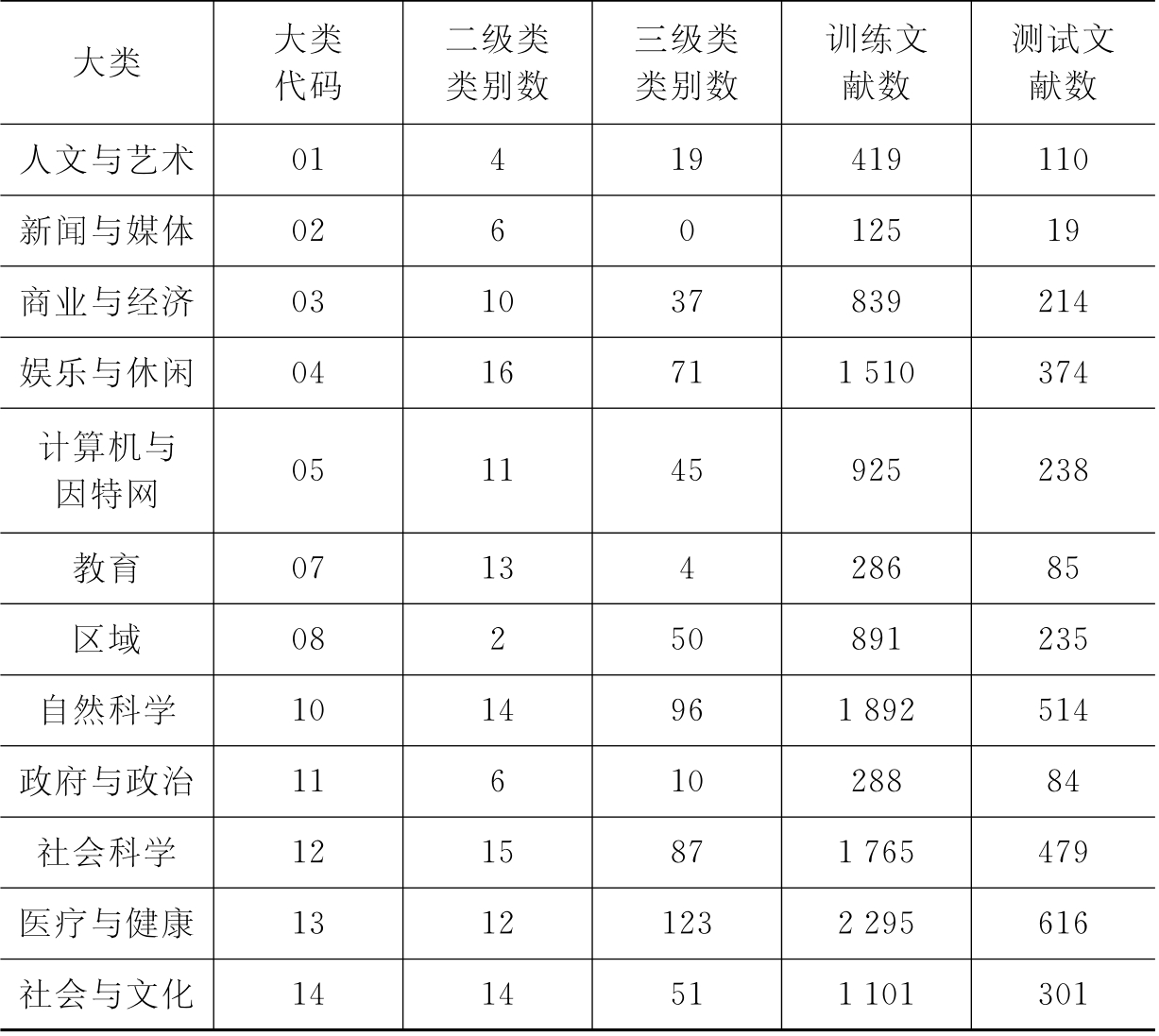
基于中文分词和TF/IDF的关键词抽取方法(简称TKEY方法)长期以来一直占主导地位。本文主要对GKEY方法和TKEY方法的性能进行对比分析。实验数据集(CWT)由北京大学网络实验室提供,包括15 605个网页文本。训练集和测试集划分与原数据集一致。数据集的分类表结构以及训练集和测试集见表6-3。
表6-3 CWT数据集的类别分布及划分
TKEY方法中的中文分词采用ICTCLAS。TF/IDF定义为:
![]()
其中,n表示数据集中的文献总数,dk表示数据集中包括词k的文献总数,fk表示词k在文献i中出现的频率[8]。在实际操作中,aki阈值的确定比较困难,为了便于比较两种关键词自动抽取方法的性能,规定每篇文献两种方法抽取的关键词数量尽量相同。具体做法:首先用GKEY方法抽取出数据集中每篇文献的关键词(其中k=1),然后根据每篇文献的关键词数量,决定TKEY方法对每篇文献抽取出的关键词数量。
TKEY方法操作步骤:
(1)用ICTCLAS分词系统进行分词。
(2)清除文本中的停用词和特殊符号。
(3)计算每个词的aki值,并将aki值由大到小排序。
(4)参照GKEY方法抽取出的关键词数量,再按aki值大小抽取出相应数量的关键词。
采用GKEY方法从训练集中抽取出139 658个关键词,其中56个关键词分词错误;从测试集中抽取出37 251关键词,其中25个关键词分词错误。用TKEY方法从训练集中抽取出137 574个关键词,从测试集中抽取出36 819个关键词。分类性能评价采用信息检索领域最经典的两个指标:
查全率:
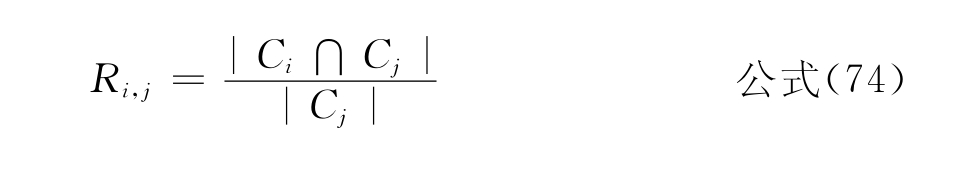
查准率:
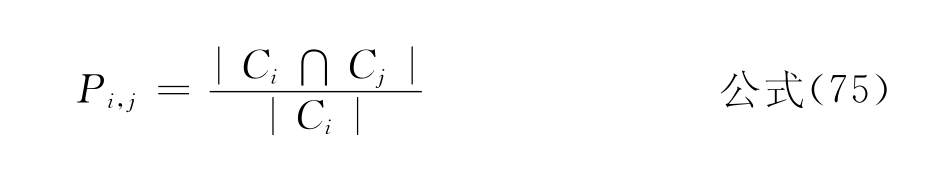
其中Ci表示i类测试文献的所有关键词,Cj表示j类训练文献的所有关键词,Ri,j表示测试集中j类文献预测到训练集中i类的查全率,Pi,j表示测试集中j类文献预测到训练集中i类的查全率。实验结果如表6-4、表6-5、表6-6和表6-7所示。
表6-4 GKEY方法在CWT数据集上的查全率
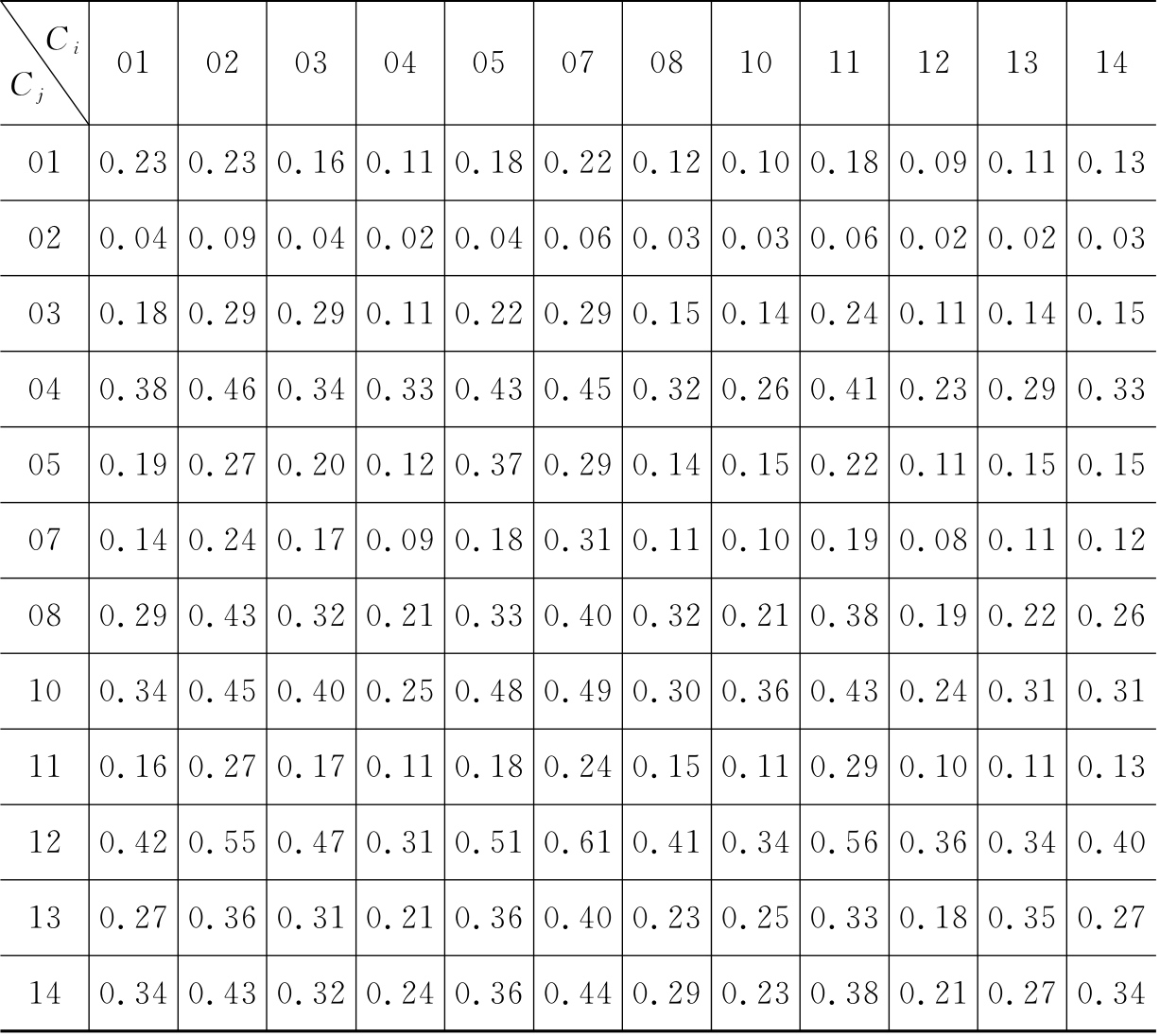
表6-5 GKEY方法在CWT数据集上的查准率
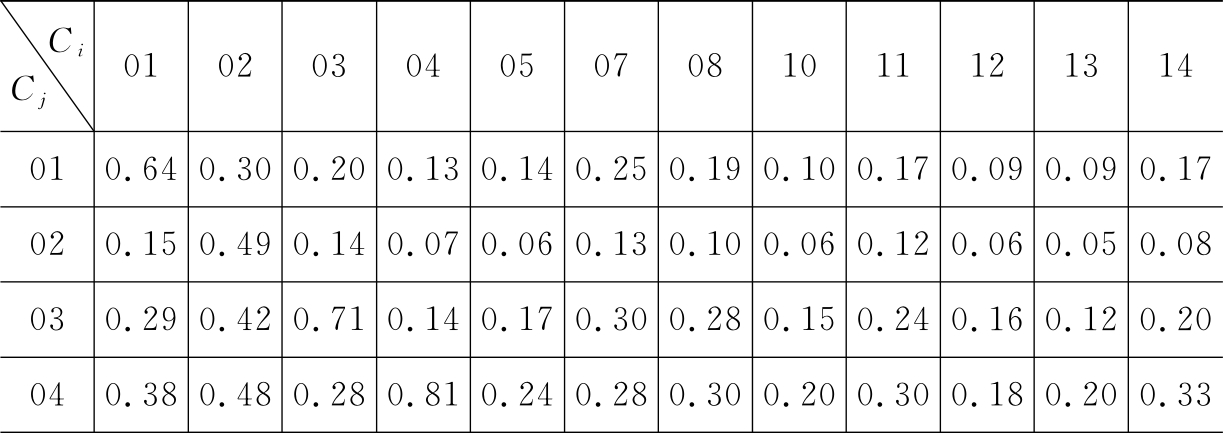
续表 6-5
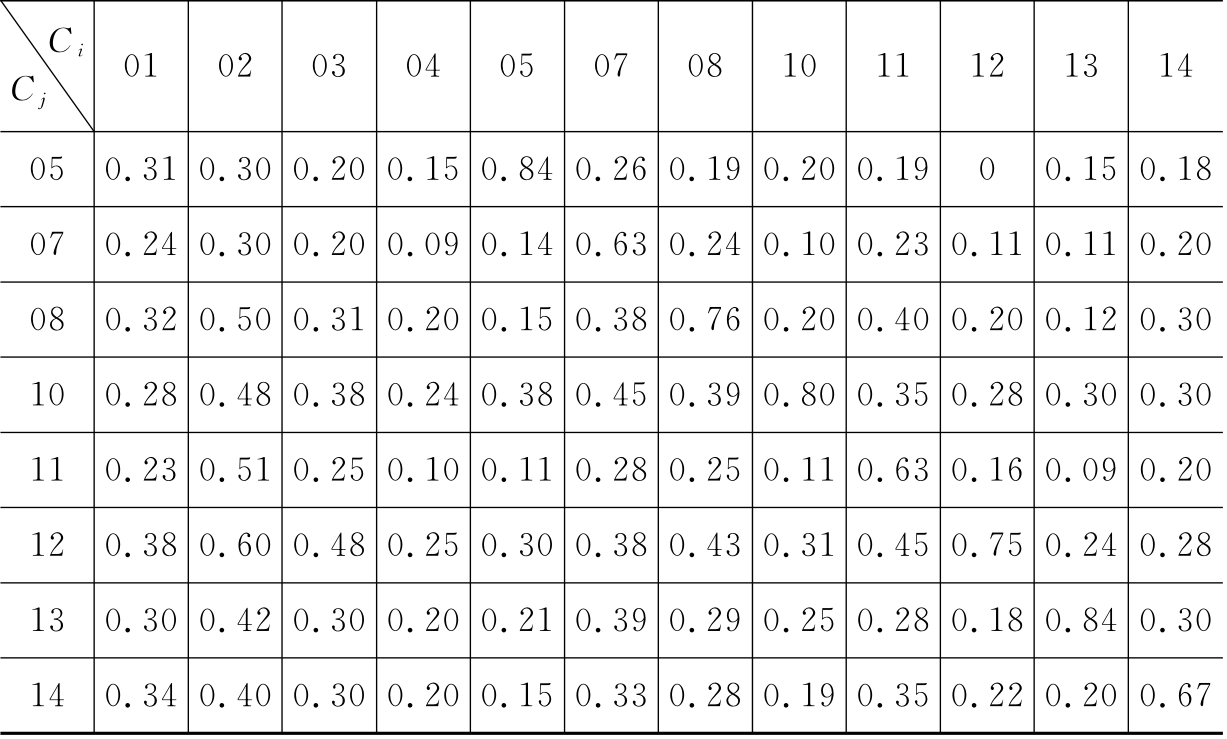
表6-6 TKey方法在CWT数据集上的查全率
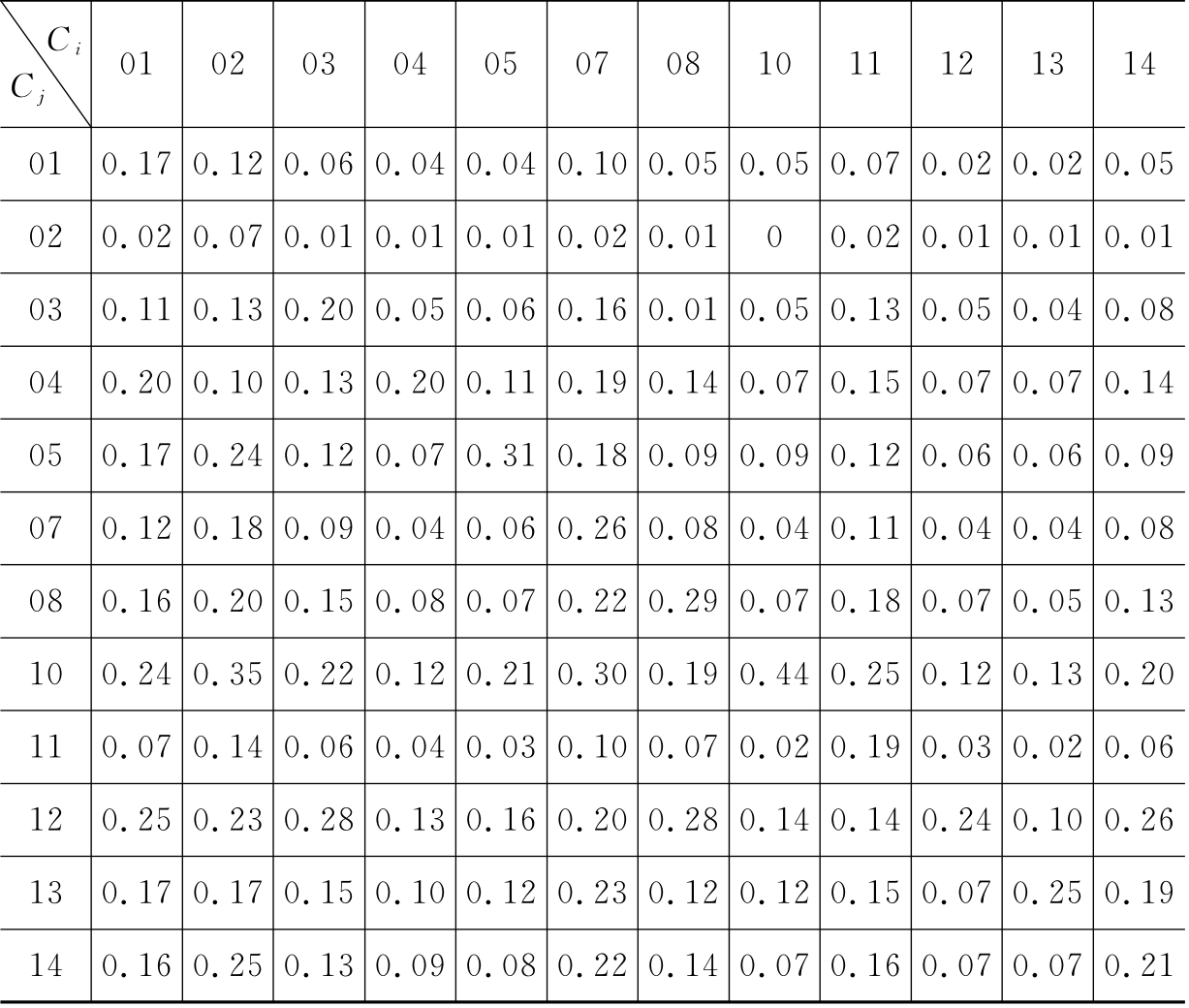
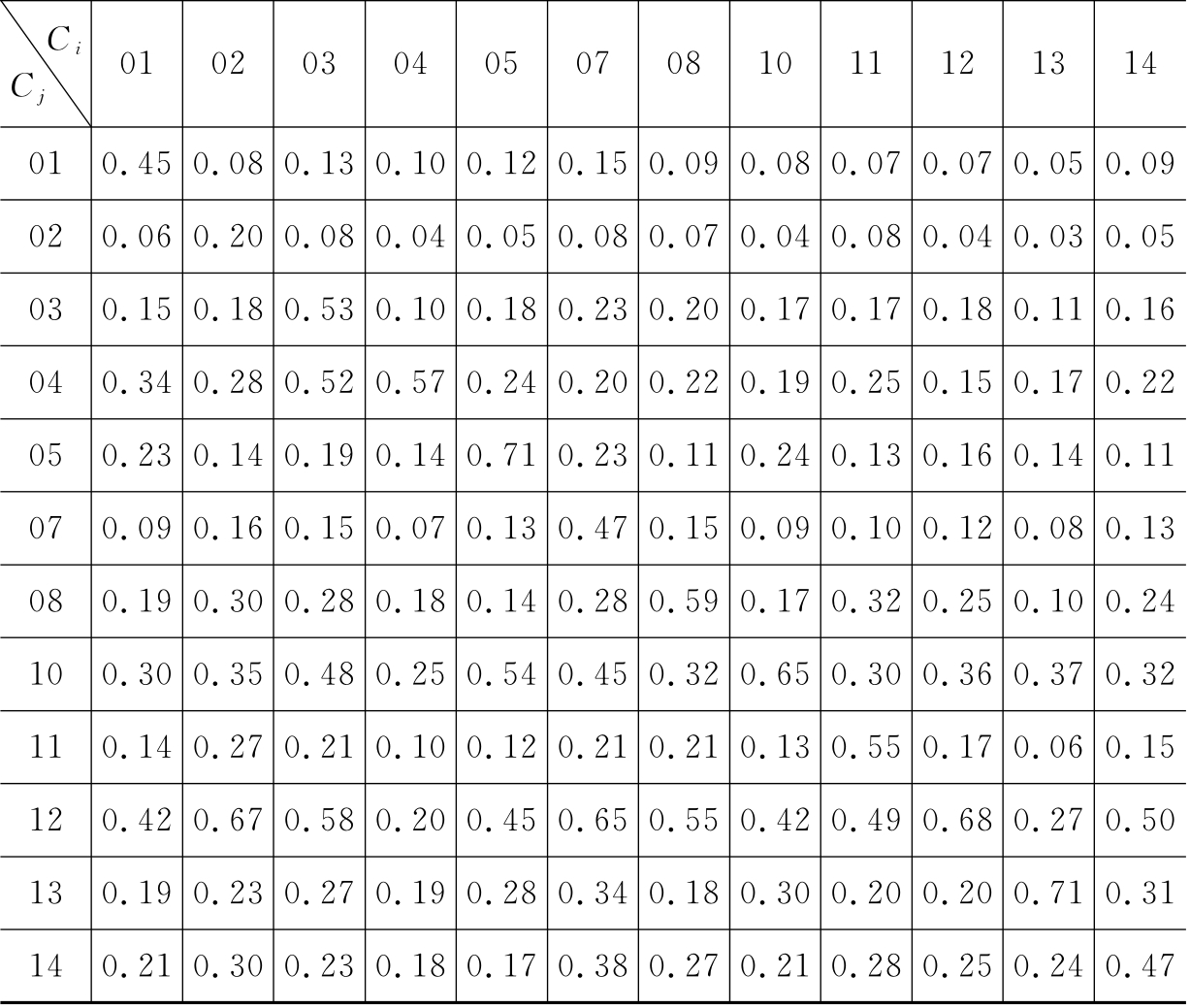
表6-7 TKey方法在CWT数据集上的查准率
一个分类系统总是期望,当i=j时,查全率和查准率越高越好;而当i≠j时,查全率和查准率越低越好。即尽可能少地避免交叉分类的情况。为了更全面地反映分类系统的分类性能,定义了平均查全率和平均查准率指标,其中m是整个分类系统中类别的数量。
平均查全率:
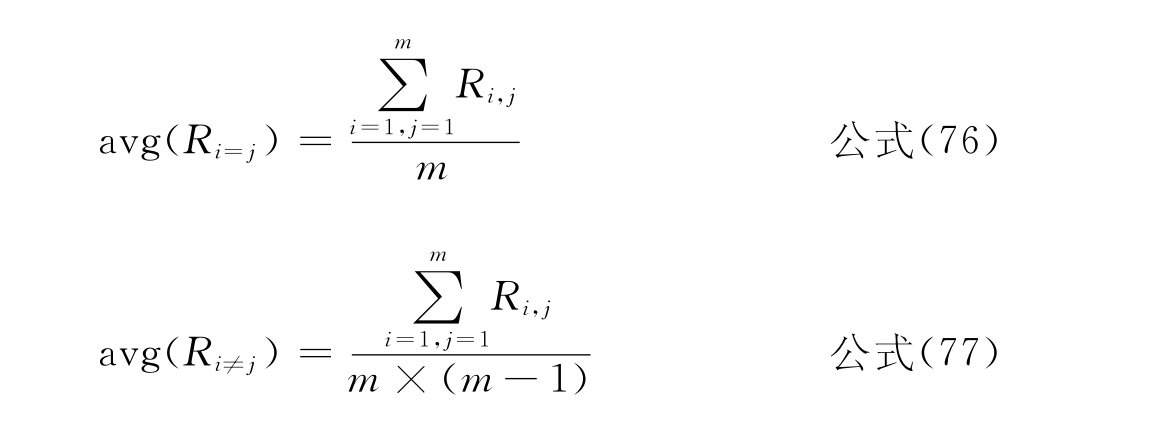
平均查准率:
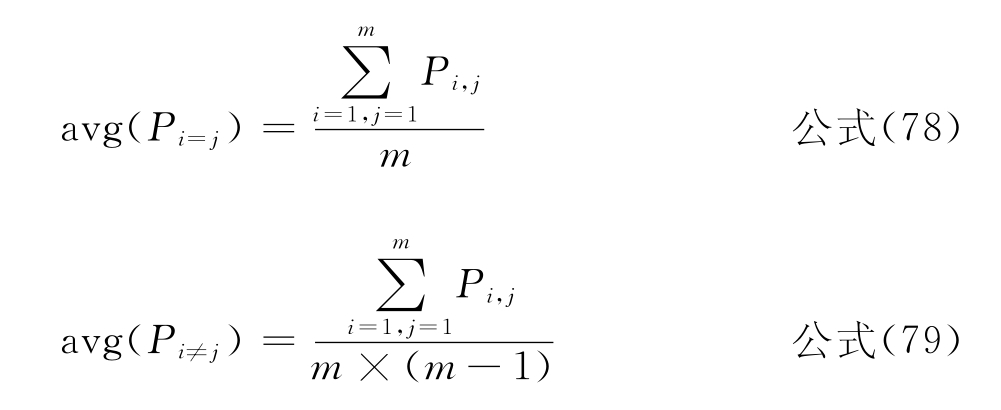
采用GKEY方法在CWT数据集上获得的实验效果:avg(Ri=j)和avg(Ri≠j)分别为0.30和0.24,avg(Pi=j)和avg(Pi≠j)分别为0.71和0.24。
采用TKey方法在CWT数据集上获得的实验效果:avg(Ri=j)和avg(Ri≠j)分别为0.22和0.11,avg(Pi=j)和avg(Pi≠j)avg(Ri=j)分别为0.54和0.21。
GKEY方法在分类系统中获得的检索性能明显优于TKey方法,关键原因在于:一是中文分词主要从语言学的角度,而不是概念的角度考虑如何断词,大量专指概念被切分为比较泛指的词。例如:“操作系统”被切分为“操作”和“系统”,“语音编码”被切分为“语音”和“编码”;二是TF/IDF权重法假设一个特定数据集的文献应该是相关的,而CWT数据集中的文献涉及多个学科。
在关键词筛选算法中,k是一个可以控制标引深度和标引专指度的参数。最佳k值的选择应该根据具体的应用系统来确定。原则上,选择可以获得最佳检索性能的k值。下面,我们采用CWT数据集进行分类实验,以具体说明k值对关键词抽取性能的影响(见图6-2、图6-3)。

图6-2 不同k值在CWT上获得的查全率

图6-3 不同k值在CWT上获得的查准率
参数k对关键词的抽取性能具有较大的影响。在CWT数据集上的实验,当k定义为2时,分类系统可以获得最优的检索性能。当k=4时,系统查全率和查准率最低。这说明当关键词过于专指或者泛指时,系统都不能获得最优的检索性能。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。









