



四、XML检索排序方法
XML检索旨在提供尽可能精确的信息给用户,因此,检索结果可以是任意粒度的元素,只要它在内容上与查询是相关的。所以,XML检索与非结构化文本信息检索的最大不同点是:XML检索不仅仅要对元素根据其与查询的相关度进行打分,而且要决定合适的返回元素大小。因此,XML检索在对结果进行排序时至少要有两步:(1)计算元素得分;(2)选择合适大小元素返回。如果检索是CAS类型,那么在进行得分计算时还需要考虑结构限制,这时就还需要有结果限制处理这一步。下面对这三步主要需要解决的问题及现有的解决方法分别进行介绍。
1.元素得分的计算
在XML检索中,词频等统计数字不再是文档级别的,而是元素级别的,因此在计算元素得分时如何对元素级别的统计信息进行建模是一个主要的问题。很多用于无结构文本的检索模型通过适当的改进都能应用于XML检索之中,例如:向量空间模型,BM25,统计语言模型等。同时也有很多针对XML检索设计的排序方法。迄今为止,还没有公认的XML检索模型。下面介绍一些有代表性的计算元素得分的方法。
(1)向量空间模型
Mass和Mandelbrod[14,23,24]在XML检索中对向量空间模型进行了扩展。文档D和查询Q之间的相关性定义为查询向量和文档向量之间的cos值,如公式(1)所示:
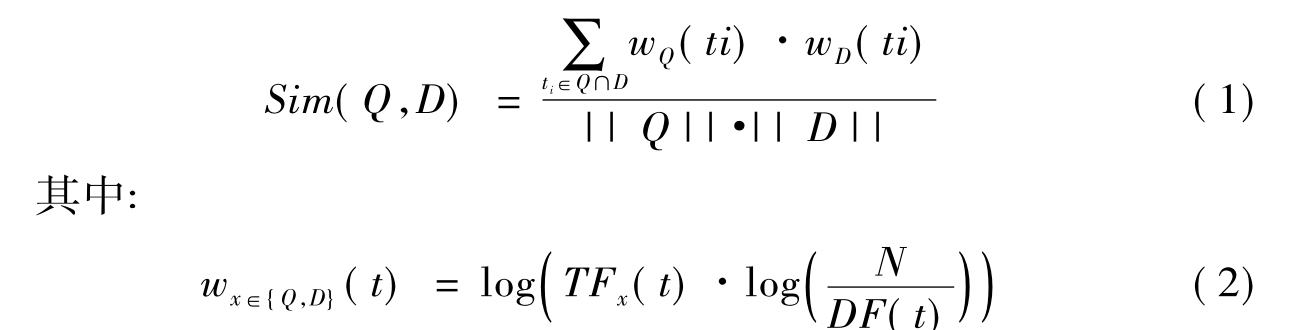
其中N是数据集中文档总数;词频TFD(t)是关键词t在文档D中的出现频率;文档频率DF(t)是包含关键词t的文档总数。
为了检索XML元素而不是整篇文档,需要对N、词频以及文档频率进行重新定义。N定义为数据集中元素总数;词频TFC(t)是关键词t在元素C中的出现频率;元素频率CF(t)是包含关键词t的元素总数。由于XML的元素是嵌套式的,因此在实际计算时,只有词频使用元素词频TFC(t),N和DF(t)依旧使用文档级统计结果。
(2)BM25
Lu等[25,26]在XML检索中对BM25概率模型进行了扩展。针对文档级的检索,定义了BM25F模型,该模型在计算词频时对XML文档中不同的域进行了加权,模型具体计算公式见上文[25,27]。针对元素级的检索,定义了BM25E模型,该模型将元素当做XML文档,同样也对元素进行加权,模型具体计算公式见上文[25,28]。
(3)统计语言模型
Sigurbj9rnsson等[29,30,15]在XML检索中对统计语言模型进行了扩展。他们使用多项语言模型,配以Jelinek-Mercer平滑方法,每一个元素都有一个语言模型。元素的语言模型建模如公式(3)所示:
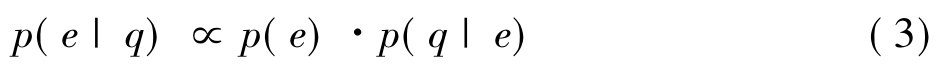
假定查询q中各个关键词(t1,t2…tk)相互独立,公式(3)可以化为:
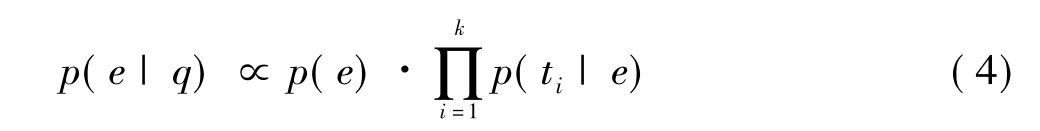
为防止出现数据稀疏问题,对元素的语言模型用另外两个语言模型进行了线性插值,一个是元素所在文档的语言模型,一个是数据集的语言模型。这时,P(ti|e)可以表示为:
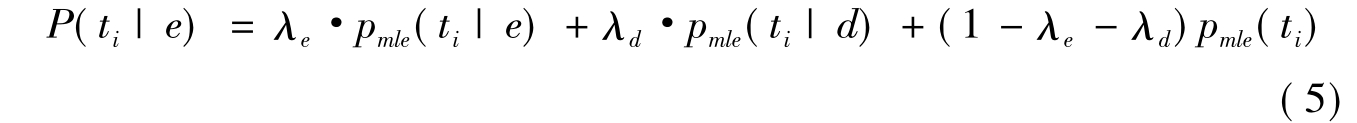
其中,Pmle(·|e)是对元素e的建模,Pmle(·|d)是对文档d的建模,Pmle(·)是对数据集的建模。λe和λd是插值参数,即平滑参数。三种对象的建模均采用最大似然估计来计算。
此外,P(e)可以表示为:

其中,|e|是指元素e的大小。
另外,Ogilvie和Callan[31,32,33]也在XML检索中对统计语言模型进行了扩展。他们使用一种树结构形式的有生殖能力的语言模型来计算元素得分[31]。树中每一个节点对应了一个语言模型,其中,叶子节点的语言模型是通过该节点的内容来建模的,非叶子节点则通过对其子元素的模型使用线性插值的方法来建模。最后形成的建模树中,每一个节点有一个语言模型,每一条边有一个权值,该权值在线性插值过程中给出。后来,他们将建模过程进一步规则化为层次统计语言模型[33]。
除了从信息检索基本模型进行扩展外,还可以针对XML检索设计其独特的得分计算方法,下面介绍一些典型的方法。
(1)段落检索
Huang等[34]将段落检索(Passage Retrieval)思想应用于XML元素检索中:首先使用固定大小窗格将XML文档分割成一个个有重复的或无重复的片段,一个片段只要含有一个检索词就认为是相关片段。得到这些片段的起始位移和终止位移之后,定义它们的公共祖先(common element ancestor)为含有这些片段的最小元素,然后通过这些片段的得分来计算元素得分。片段得分则采用传统信息检索中的检索模型来计算。
(2)基于阅读收益和阅读努力的方法
Shimizu和Yoshikawa[35]提出了一种基于阅读收益(benefit)和阅读努力(reading effort)的XML检索排序方法。首先假定一个元素的阅读收益大于或者等于它所有子元素的阅读收益之和;一个元素的阅读努力小于或者等于它所有子元素的阅读努力之和。检索结果按照获得收益的效率来排序,即:benefit/reading effort。
元素e的阅读收益定义为:
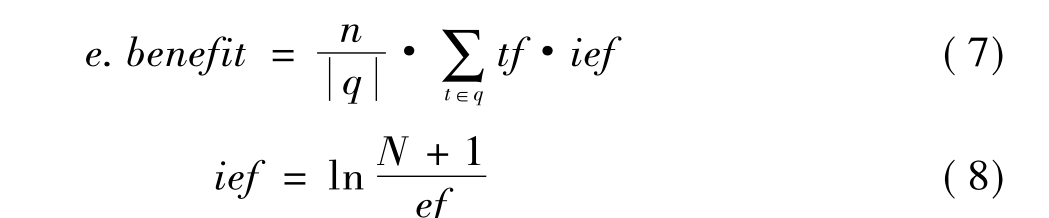
其中,tf是查询q检索词的词频;ief是逆元素频率;n是元素e和查询q共同包含的检索词个数;|q|是查询q包含的检索词个数;N是数据集中元素的个数;ef是数据集中包含检索词t的元素个数。
元素的阅读努力与元素的大小有关,与查询q无关。因此,Shimizu和Yoshikawa将阅读努力定义为元素大小的简单函数。
(3)得分传递方法
Geva[36~39]定义了一种得分传递方法,先对叶子节点计算得分,非叶子节点对其子元素的得分进行叠加而得。
Geva[36]定义的叶子节点的相关度计算公式是:

其中,n是叶子节点中所包含的不同检索关键词个数;K是参数;ti是第i个检索关键词在叶子节点中的频率;fi是第i个检索关键词在数据集中的频率。
非叶子节点的相关度计算公式定义为:

其中,n是该节点的子元素个数;如果n为1,那么D(n)取值为0.49,否则取值0.99;Li就是第i个子元素。
2.选择合适元素返回
由于XML文档是嵌套式的结构,检索出的元素可以是任意层次结构的,因此如果子元素符合检索要求则父元素也符合检索要求,有时父元素信息全面,子元素只是片面地含有部分信息;有时子元素中的冗余信息较少,父元素反倒含有更多的不相关信息。所以,在计算了元素得分并按照得分高低进行排列之后,需要对元素进行去重处理,对相互嵌套的检索结果选择合适的元素大小返回。目前主要有以下几种方法:
(1)选择得分最高的元素
最简单的方法就是直接选择得分最高的元素返回[17,37]。这种方法把元素之间看成是相互独立的,没有考虑不同元素之间的关系。
(2)考虑元素间关系进行选择
根据元素间关系来进行重复元素去除的方法主要有以下几种:①Shimizu和Yoshikawa[35]将重复元素定义为两种:包含(contain,包含一个得分更高的子元素)和被包含(contained,被包含于一个得分更高的父元素)。如果是包含的,那么去掉已经检索出来的被包含的子元素;如果是被包含的,那么直接忽略该条结果。②Clarke[40]则对包含了或者包含于得分更高元素中的元素进行了得分调整。③Mass等[24]和Lu等[28]考虑了同一篇文章中所选出元素的分布情况以及元素得分情况。④综合多种因素,不仅仅是得分大小。Mihajlovic等[41]定义了一种效用函数,根据元素中相关内容的比例、元素得分及其长度来度量元素的有用性大小。对元素E,其效用函数定义为:
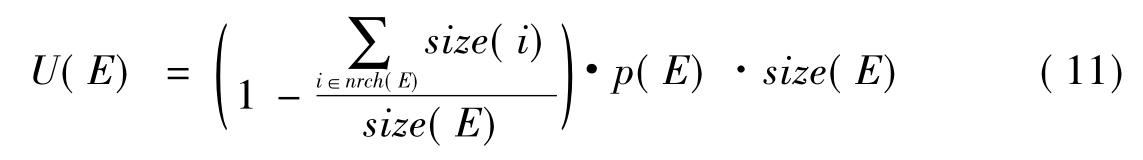
其中,p(E)是由检索模型计算得到的元素相关性得分;nrch(E)是元素E中不相关子元素集合。
3.结构限制的处理
用户对结构限制的指定分为两种:一是为限制检索,即对目标元素结构进行限制;二是为减少查询的元素范围,对待检元素结构进行限制。这两种限制都存在模糊解释和严格解释两种。因此,对结构限制的解释按照对待检索元素的模糊/严格解释和目标元素的模糊/严格解释两部分共存在四种不同的解释方式[42],后来Trotman和Lalmas[43]通过对INEX2005的各种不同解释方式进行相关度分析得出了对待检元素的结构限制与检索效果好坏没有关系的结论,因此后续几年仅对于目标元素进行不同方式的解释。以下介绍对目标元素进行模糊解释的几种方法。
(1)全部忽略
最简单的方法就是直接忽略掉结构限制。
(2)构建等价标签集
为了对结构限制进行模糊的处理,最直接的方法就是构建等价标签集。如Mass和Mandelbrod[24]事先挑选出大小合适的元素并对每种元素进行单独的索引。检索时,并行在所有索引上进行。通过与等价标签列表进行比较实现了结构限制的模糊解释。Mihajlovic等[41]则使用INEX往届的人工相关性评测结果来自动构建等价标签集。
(3)利用结构限制
Theobald等[44]和Geva[37]利用结构限制来进行得分计算。他们先计算元素的内容相关性得分,然后根据元素与结构限制的匹配程度来增加得分。这种方法可以看做是间接的模糊处理。
(4)放松路径限制
当使用数据库实现XML检索时[41,44],可以通过放松查询路径限制来达到模糊处理结构限制的目的。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。









