



10.5 因特网购物世界
在本节中我们将对因特网上购物相关的一些知识进行编码。我们将创建一个购物搜索智能体来帮助顾客寻找因特网上提供的产品。顾客提供给购物智能体一个产品描述,它的任务是产生一个提供出售这种产品的网页列表。在某些情况下,顾客的产品描述是精确的,如Cooplix 995数码相机,接下来的任务是查找最佳供应的商店。在其它情况下,描述可能只是部分指定的,如价格低于300美元的数码相机,智能体将不得不比较不同的产品。
购物智能体的环境是整个万维网——不是一个玩具般的模拟环境,而是同样复杂的、经常在发展的每天有上百万人使用的环境。智能体的感知信息是网页,但是尽管人类网站用户看到的是屏幕上作为像素点阵显示的Web页面,购物智能体则将页面感知为一个由普通文字及散布其间的HTML标记语言格式命令而组成的字符串。图10.7显示了一个Web网页和对应的HTML字符串。购物智能体的感知问题包括从这类感知信息中抽取有用信息。

图10.7 上面是人类用户通过浏览器感知到的一般联机商店(Generic Online Store)的一个Web网页形式,下面是浏览器或者购物智能体感知到的对应的HTML字符串。在HTML中,在<与>之间的字符是标记指示,指定页面如何被显示。例如,字符串<i>Select</i>的意思是转换成斜体,显示词Select,然后结束斜体的使用。诸如http://gen-store.com/books这样的网页标识符称为统一资源定位器(缩写为URL)。标记<a herf="url">anchor</a>意味着用链接文本anchor创建一个指向url的超链接
显然,在Web网页上的感知比在开罗驾一辆出租车的感知容易得多。尽管如此,因特网感知任务仍然有复杂性。图10.7的Web网页与实际购物网站相比较是十分简单的,后者包括cookies(一种网页发送给浏览器的特殊信息——译者注)、JAVA、Javascript、Flash、软件机器人排除协议、残缺的HTML、声音文件、电影、只作为 JPEG 图像一部分出现的文本等。一个智能体要能够处理因特网上的所有东西,几乎就像现实世界中能够移动的机器人一样复杂。我们将集中在一个忽略了大部分复杂因素的简单智能体上。
智能体的第一个任务是找到相关产品的供应(后面我们将看到如何选择最好的相关供应)。令query是用户输入的产品描述(例如,“laptop”,便携计算机);如果一个页面是相关的并且的确是一个供应,那么该页面是query的一个相关供应。我们还将会记录与页面相联系的URL:
RelevantOffer(page, url, query) ⇔ Relevant(page, url, query) ∧ Offer(page)
一个含有关于最新的高端便携电脑的回顾的页面是相关的,但是如果它没有提供购买方法,那么它不是一个供应。目前,我们可以说如果一个页面在HTML链接或表格中包含单词“buy(购买)”或“price (价格)”的话,它就是一个供应。换句话说,如果页面包含一个形式是“<a>...buy...</a>”字符串的话,那么它就是一个供应;它也可以用“price”来代替“buy”或用“form”代替“a”。我们可以写下关于这个的公理
Offer(page) ⇔ (In Tag(“a”,str,page)∨In Tag(“form”,str,page))
∧(In(“buy”,str)∨In(“price”,str)).
In Tag(tag,str,page) ⇔ In(“<”+tag+str+“</”+tag,page).
In(sub,str) ⇔ ∃i str[i∶i+Length(sub)]=sub.
现在我们需要寻找相关页面。策略是从一个联机商店的主页出发,考虑所有可以通过伴随的相关链接到达的页面[40]。智能体将具备关于很多商店的知识,例如:
Amazon∈OnlineStores∧Homepage(Amazon,“amazon.com”).
Ebay∈OnlineStores∧Homepage(Ebay,“ebay.com”).
GenStore∈OnlineStores∧Homepage(GenStore,“gen-store.com”).
商店将它们的货物分成产品类别,并从它们的主页给主要类别提供链接。次要类别可以通过跟踪相关链接的一个链表来达到,最后我们就能到达供应。换句话说,如果页面能够通过商店主页的相关类别链接的一个链表到达,那么它与查询是相关的,接着再跟随一个链接就可以达到产品供应:
Relevant(page,url,query) ⇔
∃store,home store∈OnlineStores∧Homepage(store,home)
∧∃url2RelevantChain(home,url2,query)∧Link(url2,url)
∧page=Getpage(url)
这里谓词Link(from,to)表示有一个从URL“from”到URL“to”的超链接(参见习题10.13)。为了定义什么可以当作RelevantChain,我们需要跟踪的不是任何旧的超链接,而只是那些与指向产品查询相关链接的链接文本相关联的链接。为此,我们用LinkText(from, to, text)来表示有一个在from和to之间的链接,它用text作为链接文本。如果每个链接的链接文本是一个描述d的某相关类名,那么两个URL, start和end之间的链接链表与该描述d是相关的。链表自身的存在是通过递归定义来确定的,用空链表(start = end)作为基础情况:
RelevantChain(start,end,query)⇔(start = end)
∨(∃u,text LinkText(start,u,text)∧RelevantCategoryName(query,text)
∧RelevantChain(u,end,query)).
现在我们必须对text成为query的一个RelevantCategoryName的含义是什么加以定义。首先,我们需要将字符串和以它命名的类别联系起来。这通过使用一个谓词 Name(s, c)来完成,说明字符串 s是类别 c 的一个名称——例如,我们可能声称 Name(“laptops”, LaptopComputers)。更多的关于谓词Name的例子如图10.8(b)中所示。接下来,我们定义相关性。假设query是“laptops”。那么当下面的陈述中有一个成立时,RelevantCategoryName(query, text)为真:
• text和query命名同一个类别——例如,“laptop computers”和“laptops”(都是便携计算机的意思——译者注)。
• text命名一个像“computers(计算机)”这样的超类。
• text命名一个像“ultralight notebooks(超轻型笔记本电脑)”这样的子类。

图10.8 (a)产品类别分类法。(b)类别的指代文字
RelevantCategoryName的逻辑定义如下:
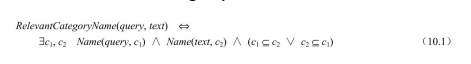
否则,链接文本是不相关的,因为它在此界线以外命名了一个类,诸如“mainframe computers(大型计算机)”或“lawn & garden(草坪和花园)”。
那么跟随相关链接,它本质上就有了产品类别的丰富层次。这个层次的顶层部分可能看起来像图10.8(a)。要罗列出所有可能的购物类别是不可行的,因为一个顾客总可能提出一些新的需要,且制造商总是会提供新的商品来满足他们(比如,电动护膝取暖器?)。尽管如此,包含大约1000个类别的本体论对大部分顾客将是一个十分有用的工具。
除了产品层次自身之外,我们还需要有一个丰富的类别名称词汇。如果类别和命名它们的字符串之间一一对应,那么生活将会更容易。我们已经看到了同义词问题——同一个类别的两个名称,比如“laptop computers”和“laptops”。还有多义性问题——两个或更多类别用同一个名称。例如,如果我们添加语句
Name(“CDs”, CertificatesOfDeposit)
到图10.8(b)所示的知识库中,那么“CDs”将命名两个不同的类别。
同义词和多义性将导致智能体必须跟踪的路径条数的显著增长,并且有时会使判断一个给定页面是否真正相关变得困难。更严重的问题是用户可以输入的描述或商店可以使用的类别名是一个十分广阔的范围。例如,当知识库只有“laptops”时,链接可能是“laptop”;或用户可能寻找“能够放在波音737经济舱位置的折叠小桌子上的计算机”。预先枚举一个类别能被命名的所有方法是不可能的,所以在某些情况下为了判断Name关系是否成立,智能体将必须能够进行附加推理。在最坏情况下,这需要完全的自然语言理解,一个我们推迟到第二十二章讨论的话题。实际上,少数几条简单的规则——比如允许“laptop”匹配一个名为“laptops”的类别——非常有效。习题10.15要求你在对联机商店进行一些研究之后,发展一套这样的规则。
已知来自前面段落的逻辑定义和产品类别及命名惯例的适当的知识库,我们是否准备好运用推理算法来得到与我们的查询相关的供应集合了?还没有!遗漏的要素是 GetPage(url)函数,它指代给定URL的HTML页面。智能体的知识库里面并没有每个URL的页面内容;也没有推断这些内容可能是什么的明确规则。作为替代,只要子目标包含GetPage函数,我们就可以安排执行正确的HTTP过程。这样,它看来是一个仿佛整个网页都在知识库内的推理引擎。这是称为过程性附件的通用技术的一个例子,由此特定的谓词和函数可以用专用方法来处理。
对供应进行比较
让我们假定上一节的推理已经为我们的查询“laptops”产生了一个供应页面集合。为了比较那些供应,智能体必须从供应页面抽取相关信息——价格、速度、磁盘容量、重量等等。这对实际网页是一个很难的任务,因为之前提到的所有原因。一个处理这个问题的通常办法是用称为封装器(wrapper)的程序来从一个页面抽取信息。信息抽取的技术在第23.3节中讨论。眼下,我们假定封装器存在,且当给定一个页面和一个知识库时,它们给知识库添加断言。典型地,封装器层次将被应用到一个页面:一个很普通的封装器来抽取日期和价格,一个特定一些的封装器来抽取计算机相关产品的属性,如果需要的话,还可以有一个知道特殊商店格式的站点特定的封装器。已知一个gen-store.com的页面上具有文本
YVM ThinkBook 970. Our Price: $1449.00
伴随着各种技术规格说明书,我们希望一个封装器抽取类似下列信息:
∃lc,offer lc∈LaptopComputers∧offer∈ProductOffers∧
ScreenSize(lc,Inches(14))∧ScreenType(lc,ColorLCD)∧
MemorySize(lc,Megabytes(512))∧CPUSpeed(lc,GHz(2.4))∧
OfferedProduct(offer,lc)∧Store(offer,GenStore)∧
URL(offer,“genstore.com/comps/34356.html”)∧
Price(offer,$(449))∧Date(offer,Today).
这个例子显示出当我们认真地接受商业交易的知识工程任务时出现的几个问题。例如,注意价格是offer的一个属性,并不是产品自身的。这是重要的,因为一个给定商店的供应可能会天天改变,甚至对于同一台便携式电脑也如此;对某些类别——如房子和油画——同一个物体同时被不同中间商以不同的价格提供。还有更复杂的情况我们没有处理,诸如价格依赖于付款方式以及根据顾客资格确定的某种程度折扣的可能性。总而言之,还有很多有趣的工作要做。
最后的任务是比较我们已经抽取的供应。例如,考虑这3个供应:
A:2.4GHz CPU,512MB RAM,80GB disk,DVD,CDRW,$1695。
B:2.0GHz CPU,1G RAM,120GB disk,DVD,CDRW,$1800。
C:2.2GHz CPU,512MB RAM,80GB disk,DVD,CDRW,$1800。
A 比 C 有优势;也就是,A 更便宜更快,而其它方面都一样。通常,如果 X 至少一个属性有更好的值而且任何属性都不差,那么X比Y有优势。但是A或B都不比另一个有优势。为了判定哪一个更好,我们需要知道顾客在CPU速度和价格与内存和磁盘空间之间如何权衡。关于多属性间的偏好的一般课题将在第 16.4 节中考虑;到现在为止,我们的购物智能体只是简单地返回满足顾客描述的所有无优势供应的清单。在这个例子中,A 和 B 都是无优势的。注意这个结果依赖于每个人都倾向于更便宜的价格、更快速的处理器和更大容量存储的假设。一些属性(诸如笔记本的屏幕大小)依赖于用户的特殊偏好(便携性对比可视性),对于这些,购物智能体将不得不询问用户。
我们这里已经描述的购物智能体是一个简单的例子;许多改进是可能的。尽管如此,它具有足够的能力,结合恰当的领域特定知识,它能够被购物者实际使用。由于它的陈述性结构,它能够很容易地扩展到更复杂的应用。本节的要点是说明某些知识表示——特别是产品层次——对于这样的智能体是必要的,而且一旦我们有了这种形式的某些知识,作为基于知识的智能体处理其余部分就不是很困难了。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










