



一、研究方法与数据
1.变量选择
笔者根据股票的定价理论,借鉴会计盈余折现模型,选取净资产收益率(ROE)作为衡量农业上市公司盈利水平(Y)的指标。净资产收益率,是企业一定时期内的净利润同平均净资产的比率,反映投资与报酬的关系,是评价企业资本经营效益的核心指标。对于股票价格变量,本书选取的是样本股票的每年未复权收盘价平均数的自然对数。
宗旨是研究农业上市公司盈利水平受到哪些因素的影响,依据财务理论中经典的杜邦财务分析体系:
![]()
因此,以资产负债率作为企业资本结构的代理变量。资产负债率又称负债比率,指企业负债总额对资产总额的比率,它表明企业资产总额中,债权人提供资金所占的比重,以及企业资产对债权人权益的保障程度。选取流通股比例作为企业股本结构的代理变量,流通股比例指企业流通股在总股本所占的比率。选取每股收益反映公司获利能力的大小,即反映企业普通股股东持有每一股份所能享有企业利润或承担企业亏损,该指标是分析上市公司获利能力的一个综合性较强的财务指标。
分析研究农业行业特征对农业上市公司盈利水平的影响程度也是本节研究的一个目的之一,故笔者选择了农业上市公司主营业务收入增长率来分析农业行业特征对公司盈利的影响。
2.样本选取与数据来源
笔者选取的样本同前文。按照前文样本选取原则,在农业类上市公司中(截至2009年12月31日)选取符合条件的70家上市公司,样本区间为2002年1月4日~2009年12月31日,共有3360个观测样本。所有数据来源于雅虎财经网。
3.研究方法及模型
(1)模型选择。到目前为止,关于上市公司业绩与股票价格相关性的理论与实证研究在国内外已有很多成果。本书从行业板块的角度研究,即以农业上市公司为研究对象,而我国涉农类上市公司整体数量不多,涉及了样本太小的问题,所以要解决样本数量较小的问题采用了综列数据回归模型,在一定程度上很好地弥补了这方面的不足。面板模型(Panel Data)又被称为混合数据、时间序列/横截面数据的联合等,它综合了时间序列和横截面两个维度上的信息,能更好地识别和度量单纯的时间序列和单纯的横截面数据所不能发现的影响因素。同时,从模型的效果方面来说,面板模型扩大了样本容量,能够提供更加有价值的数据,变量之间增加了多变性和减少了共线性,并且提高了自由度和有效性。
本书选用的面板模型为:
![]()
其中,i为农业类上市公司个体,t=1,2,…,T为每个公司的观测期; Yit为农业类上市公司盈利水平变量; Xit和βit分别为对应于i=1,2,…,N的截面公司的解释变量k维向量和k维参数; εit为均值为零的白噪声序列。
(2)模型形式设定。模型(1)描述了时间序列/截面数据模型的三种情形:变系数模型单方差、变截距模型的单方程和无个体影响的不变系数模型的单方程。
其中,最后一种情形假设在个体成员上既无个体影响也没有结构变化,即对于各个体成员方程,α和β均相同。对于该模型,将各个体成员的时间序列数据堆积在一起作为样本数据,利用普通最小二乘法便可求出参数α和β的一致有效估计,也称联合回归模型(高铁梅,2008) 。变系数模型,也称无约束模型,即在允许个体影响由变化的截距项αi来说明的同时还允许βi依个体成员的不同而变化,用以说明个体成员之间的结构变化。变截距模型,也称个体均值修正回归模型,该模型假设在个体成员上存在个体影响而无结构变化,并且个体影响可以用截距项的差别来说明。
不同模型形式其估计结果有很大差异,如果模型形式设定不正确,估计结果将与所要模拟的经济现实偏离甚远,因此在建立面板模型前需对模型形式的设定进行检验,即检验样本数据符合哪种时间序列/截面数据模型形式,进而避免模型设定的偏差,改进参数估计的有效性。常用的检验是协方差分析检验,即以下两个假设:
H0: β1= β2= β3= …= βN即假设在横截面上个体影响不同,但不存在变化的经济结构。
H1: α1= α2= α3= …= αN
β1= β2= β3= …= βN即假设在横截面上无个体影响、无结构变化,则普通最小二乘法估计给出了α和β的一致有效估计。相当于将多个时期的截面数据放在一起作为样本数据。
构造两个F统计量来完成的,在假设H0和H1下的F统计量分别为:
![]()
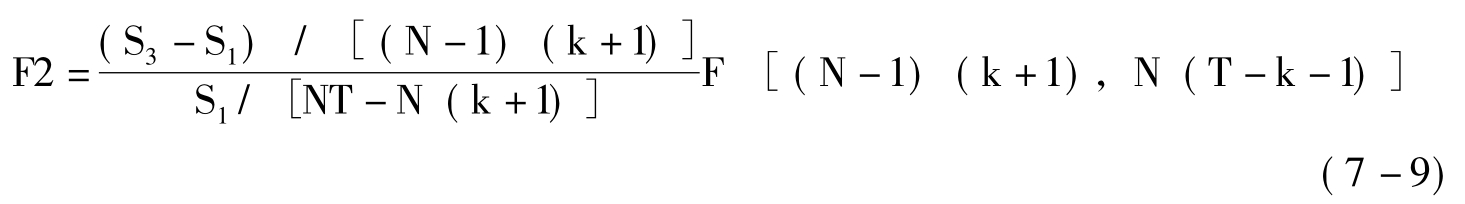
如果接受假设H1,即可以认为样本数据符合不变系数模型,就不必要进行进一步检验;如果拒绝H1,则需进一步检验假设H0,如接受假设H0,则可以认为样本数据符合模型变截距模型,如果拒绝H0则可以认为样本数据符合变系数模型。
其中,S1、S2、S3分别表示变系数模型、变截距模型和不变系数模型进行估计时的残差平方和,N表示农业上市公司样本公司的个数,T表示样本数据的时期数,k表示所选作为解释变量的指标个数。
将所取样本数据分别代入变系数模型、变截距模型和不变系数模型三个模型,得出相应的残差平方和为: S1= 16.6326,S2= 89.4436,S3= 147.8859,检验结果如表7-19所示。
表7-19 面板模型设定形式的检验

由表7-19可以看出,在1%和5%的显著性水平上,F1统计量的值和F2统计量的值都大于检验的临界值,所以可以认为样本数据符合变系数模型。
在变系数模型中,个体影响表现为模型中被忽略的反映个体差异的变量影响,又分为固定影响和随即影响两种情况。对于固定效应模型(Fixed Effects Model)还是随机效应模型(Random Effects Model)的选择,经验表明,当N较大而T较小时,两种方法的估计值会有显著的差异(高铁梅,2008) 。如果能确定样本中个体或截面单元不是从一个较大的样本中随机取出的选择固定效应模型;如果样本中的横截面单元被看作随机抽取,选择随即效应模型。鉴于本书研究的70家样本公司是按一定的标准选取的公司,而不是从总体随机抽取的样本,个体成员之间的差异,可以被看作回归系数的参数变动。因此按照经验方法可以直接选取固定效应模型进行分析。通过豪斯曼(Hausman,1978)检验来判断模型类型的方法,其结果也支持固定效益模型,本书在这里就不再列示检验的结果。
该模型的特点在于,同时考虑了横截面数据和时间序列,消除了横截面的偏差,着重于以固定截距代表每个横截面单元的不同特征。
为了反映个体之间的差异性,更为深入地研究70家农业上市公司和所属子行业的股票价格对企业盈利水平的敏感度差异,建立了以股票价格LN (P)为截面特定系数变量的固定效应变系数模型:
![]()
其中,c为各截面成员的公共截距项; αi为各截面成员特有的截距项; βi为农业上市公司的股票价格对企业盈利水平的敏感系数; γi为农业上市公司资本结构对企业盈利水平的敏感系数; δi为农业上市公司的股权结构对企业盈利水平的敏感系数; λi为农业上市公司的公司获利能力对企业盈利水平的敏感系数; υi为各农业上市公司的农业行业特征对企业盈利水平的敏感系数; εit为随机误差项。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










