



第四节 详析模式与统计控制
一、详析模式
1.详析模式的起源
详析模式(有时也称详析模型)起源于科学研究在实践中的应用。在第二次世界大战期间,塞缪·斯托(Samuel Stouffer)对影响美国军队的士气因素进入了深入的研究,他的这个研究首先检验了一些公认的模式,例如,
(1)由于军阶的升迁会影响士气,所以升迁率高的部门,其士气会相对较高。
(2)由于美国南部存在种族隔离和种族歧视,所以北部的黑人士兵比南部的黑人士兵的士气相对要高。
(3)教育程度越高的人越不愿意当兵。
令人惊奇的事情,经过仔细研究,其结果表明,这些公认的模式都是错误的。首先,军事警察在军队中是升迁率最低的部门,而空军是在军队中升迁率最高的部门,可是前者比后者中抱怨升迁太慢的人要少。其次,黑人士兵的士气并不因在南部或在北部而不同。最后,教育程度越低的人,其当兵的意愿越弱[11]。
社会现象是复杂的,一种现象往往不止是一种原因引起的;或一种社会现象往往同时扮演因和果的角色;或作为因的各种现象之间又存在着某种联系;或在确认现象间的相关或因果联系时,往往还需要通过引入其他变量,才可加以确认。
2.详析模式的分析方法
详析模式是通过引入第三个变量作为控制变量(或检验因素)来考察所研究的两个变量间原有关系的真实含义,即澄清和确定两变量真实关系的类型,说明这一关系的存在、加强或减弱的条件,探讨这一关系的内在原因。同时,它还通过不断引入控制变量来发现各处变量间的具体联系,从而深化对社会现象的认识。
在详析过程中主要运用的方法是“分表法”,但一般只能对于定类或定序变量采用“分表法”。对两变量间关系进行描述的最基本方法是“交互分类”法。采用分表法,即将样本按引入的第三变量分组,形成一个三变量交互分类表,被检验的两变量在这些组中的关系称为部分关系,然后比较两变量的部分关系与整个样本的原关系。
分表法的具体做法是:
(1)以交互分类表的形式考察两个变量之间的原有相关。
(2)引入某个第三变量,根据第三个变量的类别,作交互分类“分表”,如果第三个变量有k个类别,则要作k个分表。
(3)考察原有的相关关系在各个分表中是否发生变化,从而对原有相关关系的真假作出判断。
例如,对原有变量x和y作交叉分类表9-9。
表9-9 对原有变量x和y作交叉分类表

先分析变量x和y的相互关系。再按照控制变量z的不同取值:z=z1,z= z2……最后作分类表9-10和表9-11:
表9-10 z=z1的分类表

表9-11 z=z2的分类表

分别考察分表中变量x和y的部分关系,再与原来的变量x和y的相互关系作比较。这里只涉及控制变量为1个的情况,当存在多个控制变量时,读者可以分层次作分表。
3.详析模式的类型
在详析模式当中,根据所引入的控制变量与所研究的两个变量的位置关系,检验又可分为三种类型:
(1)控制变量位于自变量与因变量之前,即如果控制变量z位于变量x和y之前,
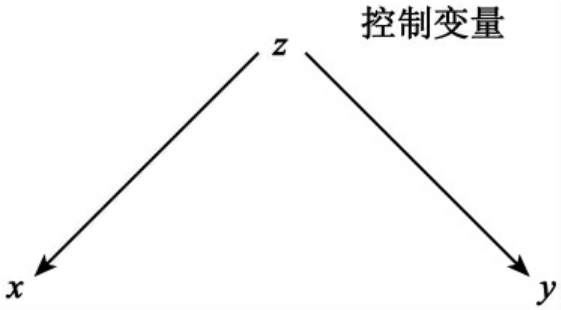
图9-3 控制变量z位于变量x和y之前
则称z为前置变量。
例如,根据统计,婚龄长的人,患病率高些。初看起来,似乎变量婚龄与变量患病率之间存在着正相关关系。但如果引入变量年龄z,则发现这样一个事实:年龄大,同时也是婚龄长和患病率高的原因。实际婚龄和患病率之间并非存在真正的因果关系。可见,为了探讨婚龄和患病率之间是否确有关系,必须引入年龄z才有可能得出正确结论。
(2)控制变量位于自变量与因变量之间,即如果控制变量z位于变量x和y之间,
图9-4 控制变量z位于变量x和y之间
则称z为中介变量。
例如,我们以年纪相近的妇女为研究对象,发现教育水平越高,子女的数目越少,但这个是为什么呢?我们如果以晚婚来解释这一现象,引入结婚年龄这个变量,并加以控制,则发现在晚婚群体、早婚群体以及总体中,教育水平和子女个数相关性,没有多大差异。所以,晚婚的说法,不能阐明教育水平与子女数目的反比关系。
现在我们用重男轻女的思想来解释这个现象。我们可以利用数据发现,教育水平越低的妇女,越是重男轻女,结果会生较多的孩子。控制重男轻女这一变量以后,发现在各个分表中,教育水平和子女个数相关性都比原表的相关性有大的消减,说明教育水平影响了人的思想,教育水平越高的妇女,重男轻女的思想越不严重,其子女的数目就偏少。
(3)条件分析,这种分析主要讨论在引入第三变量以后,两变量x与y间的原有关系在不同条件下的变化情况,不同条件下,变量之间的关系是有所加强或者有所减弱,或者消失。其主要分析目的是:在控制不同的条件下,两变量x与y的相关性如何。例如,在城市和农村这两个不同条件下,住户拥挤对夫妻冲突的影响?还是不同的民族有所分别呢?条件分析,简单明了,在社会研究中应用十分广泛[12]。
一般地,当我们引入控制变量以后,可能会出现三种结果:
①各分表中的相关关系消失;
②各分表的相关关系与原表相关关系相同;
③各个分表相关关系虽没有消失,但比原表的相关性弱。
当然还会存在一些极端的情况,我们需要进一步分析。
详析模式分析也可以通过在SPSS统计软件操作完成。详析模式其实质是控制了某个变量以后的交互分类表,其操作方法同交互分类表一样,只是增加了控制变量的选项。在打开交叉表(Crosstab…)菜单,将两个交互变量分别送入[Row(s)]和[Column(s)]后,还要将控制变量送入[Layer 1 of]中,然后点击OK按钮即可得出分类表。
二、偏相关分析
相关分析是计算两个变量间的相关关系,通过相关系数大小来衡量两个变量之间相关的强弱程度。但是由于第三个变量的作用,相关系数有时候并不能真正反映出两个变量之间的相关程度。例如,在身高、体重与肺活量三者之间的关系中,假设我们使用Pearson线性相关来计算它们之间的相关程度,可以得出肺活量与身高和体重均存在较强的线性关系。单纯从数据上看的确如此。但实际上,我们控制体重这一变量,即对体重相同的人,分析其身高和肺活量的关系,发现这二者的关系是非常弱的。为什么会出现这一情况呢?其原因在于身高与体重有线性关系,而体重与肺活量也存在线性关系,因此得出身高和肺活量之间存在着较强的线性关系的这一错误结论,所以在分析身高与肺活量之间的相关性,我们需要控制体重这个变量对身高和肺活量相关分析中的影响。在实际社会调查分析过程中,存在着许多这样的现象,在估计工资收入与受教育程度之间的相关关系,需要控制工龄或者工作经验等变量的影响;在研究销售量与广告费用之间的相关关系时,需要控制经济指标等变量的影响。
偏相关分析的任务就是在研究两个变量之间的线性相关关系时控制其他可能对其产生影响的变量。
在偏相关中,根据控制变量数目的多少,可分为零阶偏相关、一阶偏相关……(p-1)阶偏相关。零阶偏相关就是简单相关。比如,变量为y,x,控制变量为t,则变量y与变量x之间的一阶偏相关系数为: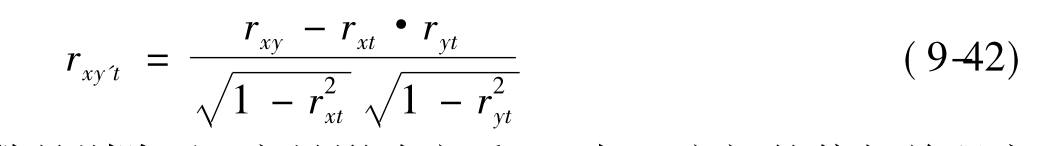
这个一阶偏相关系数是剔除了t变量影响之后,y与x之间的偏相关程度的度量;rxy,rxt,ryt分别是y,x,t两两之间的简单相关系数。
设增加控制变量w,则变量y与x的二阶偏相关系数为: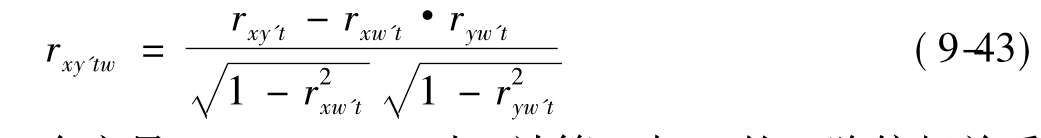
一般地,考察控制p个变量t,w,…,s时,计算Y与X的p阶偏相关系数: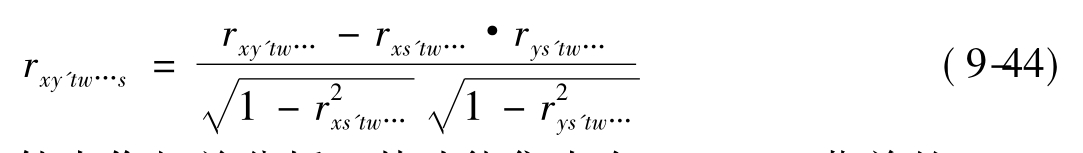
通过SPSS统计软件来作相关分析,其功能集中在Statistics菜单的Correlate子菜单中,其中Partial过程主要用来作偏相关分析,如果需要进行相关分析的两个变量的取值均受到其他变量的影响,则可以利用偏相关分析对其他变量进行控制,输出控制其他变量影响后的相关系数,这种分析方法和下面的协方差分析非常类似。【Variables框】用于选入需要进行偏相关分析的变量,至少需要选入两个变量。【Controlling for框】用于选择需要在偏相关分析时进行控制的变量,如果不选入,则进行的就是普通的相关分析。
三、协方差分析
协方差分析是把方差分析与回归分析结合起来的一种统计分析方法。方差分析用于比较因变量Y在因素X的不同水平上的差异,但Y在受这个因素影响的同时,还受到另一个变量Z的影响,而且Z变量难以人为控制,不能作为方差分析中的一个因素处理。我们称这个Z变量为协变量。
例如,我们要分析表9-7中男女的工资水平是否存在着显著性的差异,但工资水平与他们工龄有紧密关系,所以我们有必要控制工龄这一协变量Z,才能正确分析出男女工资水平是否存在显著性差异。关于协方差分析,其数学原理比较复杂,有兴趣的读者可以查阅统计学的有关书籍[13]。
关于协方差分析,我们可以通过SPSS统计软件中的分析(Analyze)菜单下的一般线性模型(General Linear Model)中的子菜单(Univariate)完成。选中此菜单后,在Dependent Variable中选择因变量,一般在Fixed Factor(s)中选择自变量,即分组变量,在Covariate(s)中选择协变量,即可完成协方差分析的SPSS操作过程。
本章小结
统计学是收集、处理、分析、解释数据并从数据中得出结论的科学。统计分析数据的方法包括描述统计和推断统计。描述性统计是研究利用取得的数据,用图表的形式对数据进行处理和总结,进而通过综合、概括和分析,得出反映研究现象的一般特征。推断统计是研究如何利用样本数据来推断总体特征的一个统计分支。
在本章的前两节着重点在于介绍单变量和多变量的描述统计分析,单变量描述分析又分为:集中趋势分析,离中趋势分析,形状分析;在集中趋势分析中,介绍了均值,众数和中位数。均值是集中趋势的最常用指标,缺点是易受极端值影响。在离中趋势分析中,介绍了方差或标准差、离散系数、异众比率、四分位差、全距等。其中方差是衡量一组数据的离散程度的最常用的值,与均值一样,适用于数值型的数据,不能用于分类数据和顺序数据。众数和异众比率则适合分类数据,对于顺序数据一般采用中位数和四分位差。多变量分析包括:列联表、相关系数。都是描述和测量变量间关系强度的统计方法,可以借助散点图观察和判断变量间的关系形态,而利用列联系数或者相关系数测量变量间的关系强度。同时补充了两个重要的内容:方差分析和回归分析。有兴趣的读者可以查找更多的资料。这里涉及的公式较多,不要求读者背下来,能大致理解公式含义,并上机操作得到结果即可。
本章的第三节主要是讲解推断统计中的参数估计。参数估计方法包括点估计和区间估计,涉及的有均值、比例、相关系数这三个统计量。点估计很简单,用样本估计量直接作为总体参数的估计值,区间估计则是在点估计基础上,在一定的置信水平下给出总体参数的一个置信区间。在实际运用中,我们主要是作区间估计。
本章的最后一节主要讲解关于统计控制的一些方法,包括详析模式、偏相关系数、协方差分析。现实生活中的现象是比较复杂的,数据往往表现的并不是真正的事实。这就需要一定的控制手段,甄别出我们需要的,上面三个方法都是利用控制某一变量,得到其余两个变量的关系,但这三个方法考察的对象是不同的。详析模式是控制第三变量,考察另外两个定类变量或者定序变量的列联表,并分析列联表的关系强弱问题。偏相关系数是剔除控制变量的影响,衡量其余两个变量关系强度。协方差分析是控制协变量的影响,考虑一个分类变量和一个定距变量的方差分析(实质是均值比较)。
关键术语
描述统计 相关分析 参数估计 详析模式 统计控制
思考题
1.调查某高校某班学生,学习社会统计学的40位学生成绩如下:
93 84 92 89 79 82 75 87 67 76
91 80 78 88 82 81 74 96 92 76
74 83 76 74 78 79 81 82 87 79
77 80 82 81 89 94 68 86 90 87
请用相关的统计软件,计算该班学生成绩的平均值,中位数,众数,上四分位数,下四分位数,方差,标准差,四分位差,偏度,峰度。
2.调查少年犯的性别和社区背景之间的关系,经过统计汇总,得到如下交互分类表:
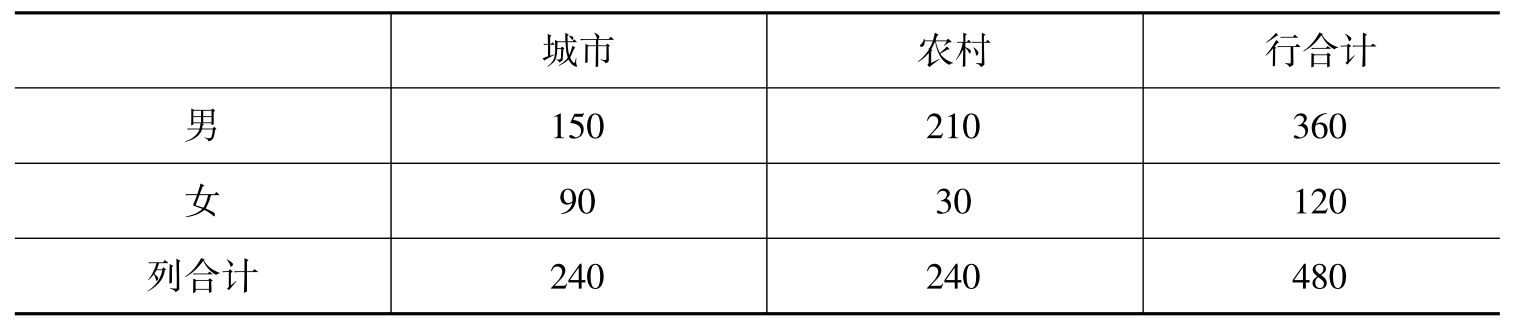
请计算关于此表的φ系数和Q系数,及其χ2值,同时基于χ2值的列联强度φ系数和C系数。
3.调查某市职工的工资情况,随机抽取600名职工作为样本,得到他们的平均工资为810元,标准差为187元。求置信度为95%的情况下,该市职工月平均工资的置信区间是多少?
4.某地区调查下岗工人中女性的比例,随机抽取了36个下岗工人,其中20人为女性。要求估计:
(1)下岗工人中女性比例的点估计。
(2)以95%的置信系数估计该地区下岗工人中女性比例的置信区间。
(3)能否得出下岗工人中女性超过男性的结论。
【注释】
[1]达莱尔·哈夫.统计陷阱.廖颖林,译.上海:上海财经大学出版社,2002.
[2]周德民,廖益光,曾岗.社会调查原理与方法.长沙:中南大学出版社,2006: 293-394.
[3]周德民,廖益光,曾岗.社会调查原理与方法.长沙:中南大学出版社,2006: 304-305.
[4]水廷凯,等.社会调查教程.北京:中国人民大学出版社,2007:315.
[5]高惠璇.SAS系统BASE使用手册(第1版).北京:中国统计出版社,1997,4: 342.
[6]翁定军.社会统计.上海:上海大学出版社,2006:43.
[7]其中y表示因变量,i表示自变量的水平个数,j表示在某个水平下的观测数,有TSS=RSS+BSS。
[8]张文彤.SPSS11.0统计分析教程(高级篇).北京:希望电子出版社,2002.
[9]高惠璇.SAS系统STAT使用手册(第1版).北京:中国统计出版社,1997,4.
[10]由于总体标准差未知,用样本标准差代替,所以这里采用T检验,与前面的公式稍有不同。
[11]巴比.社会研究方法.邱泽奇,译.北京:华夏出版社,2002:317.
[12]李沛良.社会研究的统计应用.北京:社会科学文化出版社,2002.
[13]张文彤.SPSS11.0统计分析教程(高级篇).北京:希望电子出版社,2002:27.
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。









