



2.2.5 关系数据的降维和图示技术
经过上述几个步骤形成的引文关系矩阵,反映了各元素之间的关系的远近,这是一个多维的空间关系,有多少个元素就有多少个维数,对多维数据之间的复杂关系进行可视化生成图表,必须进行降维处理,把高维的数据转换成低维数据,同时还近似地保持原对象间的关系,才能在低维空间上简单地表现高维空间中的复杂对象间的关系。目前在可视化引文分析中应用较多的主要有以下几种技术:
(1)聚类分析
聚类分析是指把分析对象根据彼此之间的相关程度分成类群,使群内尽量相似、群间尽量相异,然后进行分析研究的过程。一般是借助于计算机,把数量庞大、彼此间关系错综复杂的分析对象根据一定的相似性测度方法聚成数目相对较少的一些类群,从而简化数据,揭示对象之间的相互关系,探求其中的规律。聚类分析的一般过程是计算两两分析对象之间的相似系数矩阵,然后把相似系数矩阵作为输入数据,根据一定的聚类算法把分析对象分成类群。聚类方法有多种,但目前使用最多的是非重叠的、内在的,即把分类对象的各属性数据同等对待,每个对象都只能属于最后划分成的类群之一,而不能同时属于两个以上的类群。这类方法根据聚类过程可分为等级聚类法和非等级聚类法两种类型。在对引文数据进行分析特别是进行同被引分析时,运用最多的是等级聚类法。
等级聚类的结果一般用树状图来表示。其形状像一棵倒置的树,顶端是树根,表示整个分析对象集合,底端的每一个树梢(竖线)表示最后分得的分析对象组或单个分析对象;树中每个分支点称为节点,在聚合时代表两个下级分析对象组合并成一个上级组,在分化时表示由一个组分成两个下级组,节点的高度表示此次聚合或分划时的相似系数,代表其等级水平。
用等级聚类进行数据分析,整个分析对象集合与任何最后分组之间有着很简化的联系路线,聚类结果树状图中可以反映这种路线和聚类过程的细节信息。但是,等级聚类树状图无法直观反映对象之间的距离与结构关系。
(2)多维尺度分析
多维尺度分析(Multidimensional Scaling,简称MDS)是指通过某种非线性变换把高维空间的数据转换成低维空间中的数据,变换后的低维数据仍能近似地保持原高维数据间的关系的一种技术。通过MDS可以在较低维空间中直观地看到一些高维样本点相互关系的近似图像。该技术己经成为当今较流行的统计分析软件SPSS中的一个分析模块。如果用n个分析对象的关系矩阵(n ×n)作为原始数据,那么这n个分析对象可以看成是n维空间的n个点,每个对象所对应的那行数据即为该对象的n维数据。MDS就是要将这n维数据所表示的对象散列到低维空间(一般是二维),并且在低维空间中的散列点表现出原n维数据之间的位置关系和亲疏程度。最后形成的低维图形可以用来分析对象之间的关系。虽然多维尺度分析中点的疏密远近可以反映一定的类群关系,但不够明确,同时由于是用散点方式代表分析对象节点,不能表示出对象节点之间的连接,因此,同被引分析中常把多维尺度分析与聚类分析结合起来使用。做法是:首先用多维尺度分析把对象表示成平面上的散列的点,然后根据聚类分析的结果把这些点用线圈成点群,最后根据点与点之间、点与点群之间、点群与点群之间的位置关系进行分析研究。国外在20世纪90年代中期以前采用这种方式进行同被引分析的研究较多,例如MacCain和Small都曾多次应用这种方式进行著者或文献同被引的研究[20]。近几年国内学者在同被引分析研究中采用的也是这种多维尺度分析与聚类分析相结合的方法[21,22]。但多维尺度分析的一个局限性是由于一般借助于通用统计软件SPSS来进行,而SPSS能处理的数据对数量有限,特别是如果先要进行相似系数转换时,数据对数不能超过100对。例如Howard D.White和MacCain在1998年对情报科学进行著者同被引分析可视化采用多维尺度分析时,就不得不把著者数量限制在前100名著者[23]。
(3)因子分析
因子分析是最早被应用于学科结构分析和图示的降维技术之一。因子分析是从多个对象指标中选择少数几个综合对象的一种降维多元统计分析方法,以达到数据简化的目的。在分析处理多元素间的关系时,元素间的关系往往极为密切,使观测数据反映的信息有重叠,因此,人们希望找出较少的彼此间互不关联的综合元素,尽可能近似地反映原来元素之间的信息。这些不可观测的少数的几个综合性的元素被称为公共因子或潜在因子。表现在学科知识结构分析上,因子分析能够把大量的数据归结为少数几类,从而把某一学科划分成多个学科分支。但因子分析一般通过表格的形式反映分析结果,其图示功能很差,现在一般仅作为辅助分析的工具,和其他降维图示技术如多维尺度分析等配合使用。Chen Chaomei在进行著者同被引分析时曾把因子分析和后文将要介绍到的寻径网络技术配合在一起使用。
(4)自组织映射神经技术
Kohonen T.依据大脑对信号处理的特点,提出了一种神经网络模型———自组织映射神经模型[24](Self-Organizing Feature Map,简称SOM),这是一种无监督的自组织和自学习网络。主要功能是将输入的n维空间数据映射到一个较低的维度(通常是一维或者二维)输出,同时保持数据原有的拓扑逻辑关系。它与其他类型神经网络的区别在于:它不是以一个神经元或网络的状态矢量反映分类结果,而是以若干神经元同时(并行)反映分类结果。这种特征映射神经网络通过对输入模式的反复学习,使连接权矢量的空间分布能反映输入模式的统计特性。
SOM网络由输入层和竞争层组成,输入层由n个输入神经元组成,竞争层由m个输出神经元组成,输入层各神经元与竞争层各神经元之间实现全互连接(如图2-1所示)。为清楚起见仅画出各输入神经元与竞争层神经元j的连接情况,网络的连接权值为(i=1,2,…,n;j=1,2,…,m)。
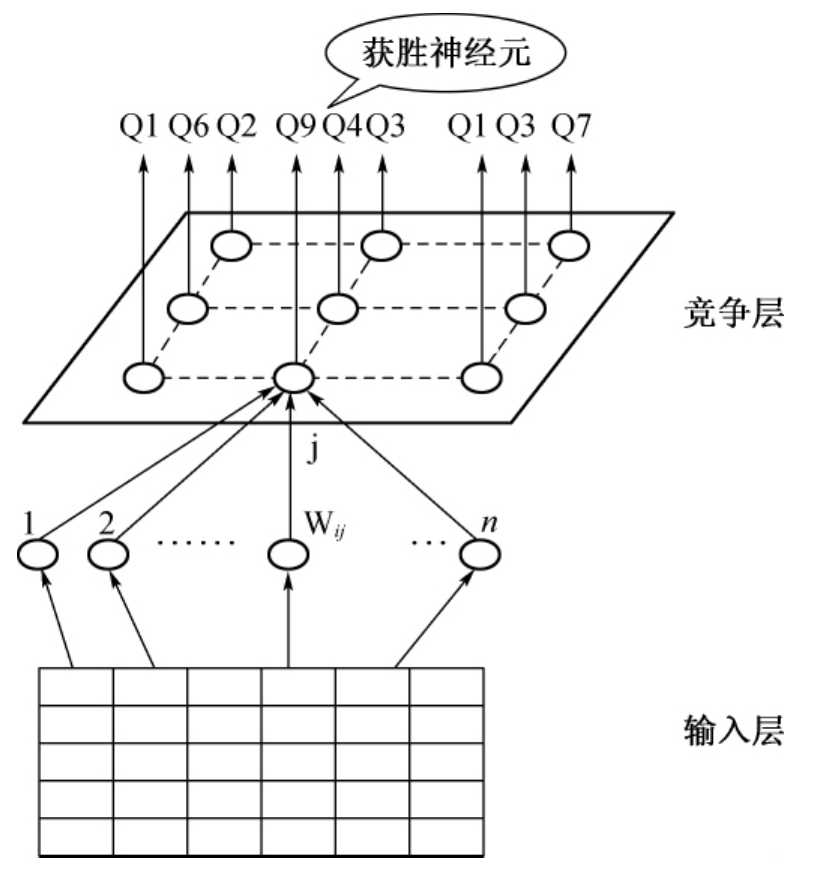
图2-1 SOM网络结构图
SOM的一般算法可归纳如下:
①初始化网络连接权值(可取一个较小的随机值);设置一个较大的初始邻域;
②将一个给定的输入向量加载到网络上;
③计算输入向量与权值向量的点积,并选择其中的最大者;
④更新所选结点及其邻域结点的连接权值;
⑤重复步骤②,直到满足终止准则。
SOM应用于同被引分析时,以一维空间和著者同被引为例,其过程如图2-2所示。在一维空间中,是一个8×8的网格,输入25位著者(高维),每个输出节点代表了一个矢量(权重),最初输出节点的矢量是随机分配的。给定一个著者以及与之具有高同被引度的24个著者,这25著者之间的同被引关系生成一个稀疏的同被引矩阵。这25维的同被引矩阵就是SOM的高维输入数据。随机从同被引矩阵中挑选一行,然后与所有的输出节点进行比较(8×8),找出相关度最大的输出节点,并且修改它的权重(以及邻域内的神经元),以便下一次进行比较的时候再次选中它。上面的学习过程需要重复很多次才能够到达某种稳定状态。最后的学习结果是相似度大的著者在2维空间的距离就越小。
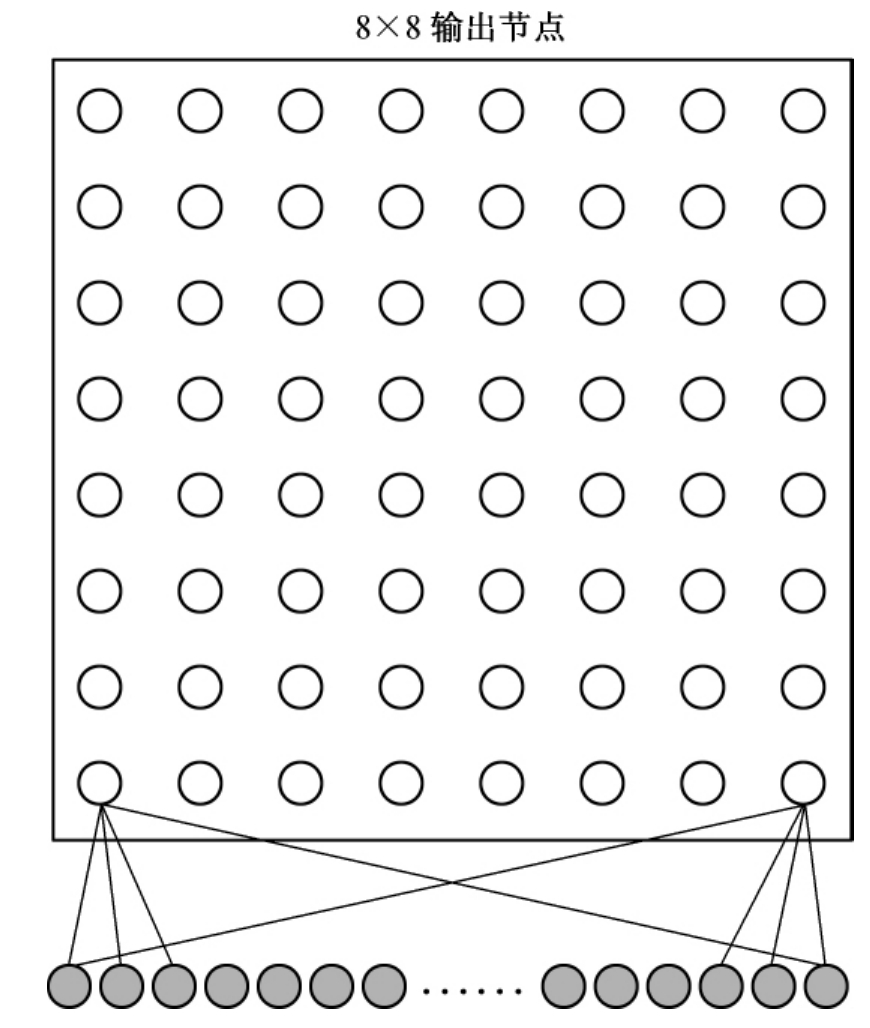
图2-2 同被引分析的SOM算法结构图
SOM已经被应用于文献的聚合分类图示中,特别是网络文献。Xia Lin是第一个把SOM应用于信息可视化的人[25][26],他的可视化系统Visual SiteMap[27]就是利用SOM,对从数据库中挖掘出的概念进行分类集簇和可视化显示。
ET-Maps是Chen Hsinchun和他的同事们利用SOM对文献进行分类集簇可视化显示的又一个例子。该系统根据Yahoo对娱乐信息的分类类目,采用SOM的算法对各类文献进行相似性分析,对网上娱乐信息进行分类可视化显示[28]。
Campanario则利用SOM对期刊间的引用关系进行了可视化分析,生成了相关图[29]。
(5)寻径网络技术
寻径网络(PathFinder Network,简称PFNET)是美国心理学家Schvaneveldt等人在1989年提出的用来分析数据相似性的一个模型[30]。它根据经验性的数据,对不同概念或实体间联系的相似或差异程度作出评估,然后应用图论中的一些基木概念和原理生成一类特殊的网状模型。该算法对一个复杂网络中衡量数据相似性的关系进行了简化,检查所有数据之间的关系,在所有可能的两点路径中只保留最强的连接,从而建立数据间最有效连接的路径。最终结果是将数据以及数据之间的关系表达成一个图,图中节点表示数据,边表示数据之间的关系。PFNFT有两个重要参数:r和q。q是指路径的最大长度,r参数是闵可夫斯基度量规则(Minkawski Metric),是计算路径长度的一个参数。对PFNET的一些基本定义,这里不再详细叙述,但根据其定义,有以下几条规则:
①任意点到其自身的距离为0;
②对于边不具有方向性的网络的距离矩阵,该矩阵是对称的;对于边具有方向性的网络,距离矩阵是非对称的;
③如果将网络中的节点作为一个个独立的概念或实体对象,将节点间的边看作是概念间的联系,边的权值表示联系的差异程度,则根据该网络生成的PFNET剔除掉了不必要的节点联系,保证了把节点间最为密切的联系保留在PFNET中。
近几年,以Chaomei Chen等为代表的一些学者把PFNET应用于著者同被引分析的可视化中,并取得了良好的效果。
目前已经有商业化的软件把PFNET算法和图示功能融合在一起,最著名的就是PFNET算法的创始人Schvaneveldt和他的同事们开发的KNOT软件,最初是被运行在DOS操作系统上,现在已经有了基于Windows的版本。Howard D.White在2003年采用1998年的有关情报学研究的作者同被引数据,对情报学结构进行可视化显示就是采用了KNOT软件[18]。
(6)最小生成树算法
最小生成树算法(Minimum Spanning Tree,简称MST)与PFNET比较相似,其基本思想是:把所有的数据元素看成分布在一个平面上的距离不等的点,如果有n个点,那么连接各点的可能线路就应该有n(n-1)/2条,但是本着节约成本的原则,根据各点之间的距离建立不同的连通网络,最后选择总的线路距离最短的那个连通网络。
Samoylenko[13]等对期刊之间的引用数据进行分析,就是运用了MST算法来确定各期刊之间的距离。西班牙的Felix Moya Anegon[31]根据类目对大科学进行领域可视化时也是采用MST来计算各科学大类之间的距离。
最小生成树(MST)和寻经网络(PFNET)优于多维尺度分析(MDS)的优点之一,就是生成的可视化图中可以表示出对象节点之间的连接关系。
(7)三角测量
三角测量(Triangulation)是一个把n维空间中的点排列到二维图形的技术,其思想是随机选择其中的一个点,把其安排到一个位置,然后选择在原来空间中与该点距离最短的第二个点放于另一位置,第三个点的位置则要根据它与前两个点的相对位置构成一个三角形,依次把各点根据相似度计算所得的距离进行安排,最后使所形成的图中的任意三个点都能构成三角形,并且各三角形的最小角最大[2]。同其他的排列技术相比,三角测量的计算量较小,且所形成的图形较准确地反映了单个数据点之间的距离。
Henry Small在其1999年发表的文献同被引可视化分析中就采用了三角测量技术,他所做出的“科学图”是一系列的鸟巢状的圆形互相嵌套,并以等级形式反映各学科之间的关系[32]。
(8)力矢量布局算法
力矢量布局算法(Force Directed Placement,简称FDP)是用来把本来属于多维空间的节点按照它们之间的相似关系在平面图上进行映射的一种技术[33,34]。其基本思想是:把节点看作物理实体,把表示它们之间距离的边看成提供连接两点的力矢量。节点的移动和布局遵从局部能量最小的原则。
传统的力矢量布局算法比较容易理解和操作,但是由于在对节点进行布局时每增加一个新的节点都要对每个节点间的力矢量进行重新计算,因此在处理大量数据时速度很慢。最近出现了一些力矢量布局算法的改进模型,可视化软件系统VxInsight就是采用了改进的力矢量布局算法[35]。Kevin W.Boyack等利用期刊引用数据对科学领域进行可视化分析,就是采用了VxInsight[10,14]。
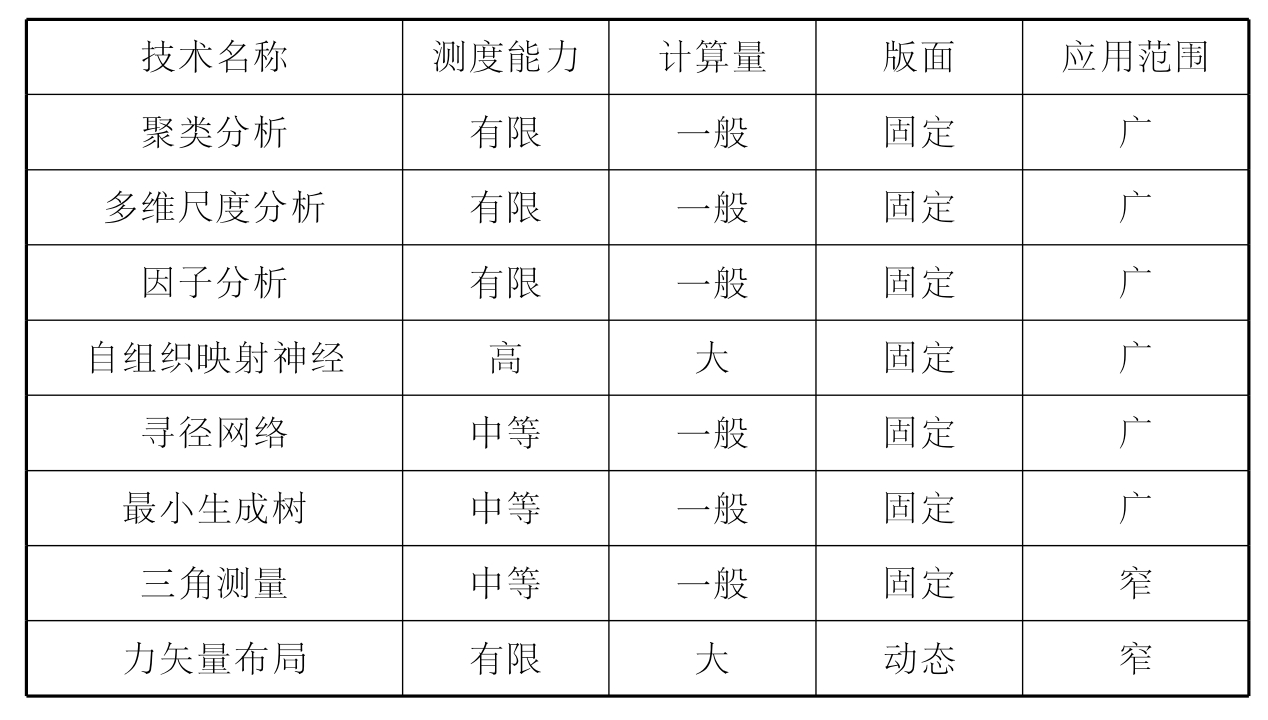
以上算法和技术可谓各有优缺点,如果从测度能力、计算量、版面的动态和静态以及应用范围来进行评价和考察的话,可以用表2-1进行总结。
表2-1 同被引分析降维技术比较
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










