



11.3 双变量子群比较
1.变量的子群比较
在对资料进行单变量描述分析时,研究者经常需要在两种相互冲突的目标上进行选择:一方面要将最完整的资料细节提供给读者,另一方面资料也应该以最方便、最容易处理的方式呈现出来。(5)如何解决资料的详尽性与表达的简洁性问题?一种可行的方式是采用子群比较。这在本质上涉及了两个变量,进入了双变量分析架构。双变量分析的主要目的在于解释某一变量影响了另一个变量,如性别影响收入、教育程度影响收入等。表11-1就是一个双变量子群比较的例子。在这里,国别(联邦德国、英国、法国、日本与美国)构成了子群类别,而它们在“联合国在解决主要国际问题时处理得如何?”的态度构成了子群比较的目标,采用变量的语言来说,态度就是因变量,而国别则是自变量。
表11-1 联合国在解决主要国际问题时处理得如何?(6) (单位:%)
和单变量分析相比,子群比较构成了一种包含两个变量的双变量分析。子群比较的主要目的是分别描述各个子群,这增加了比较性质。在大多数研究中,双变量分析还会增加变量间的关系,双变量分析主要集中于变量上。双变量子群分析不仅具有描述意义,同样还具有解释意义,可以反映变量间的关系,如表11-2所示。
表11-2 男性与女性上教堂的情况 (单位:%)
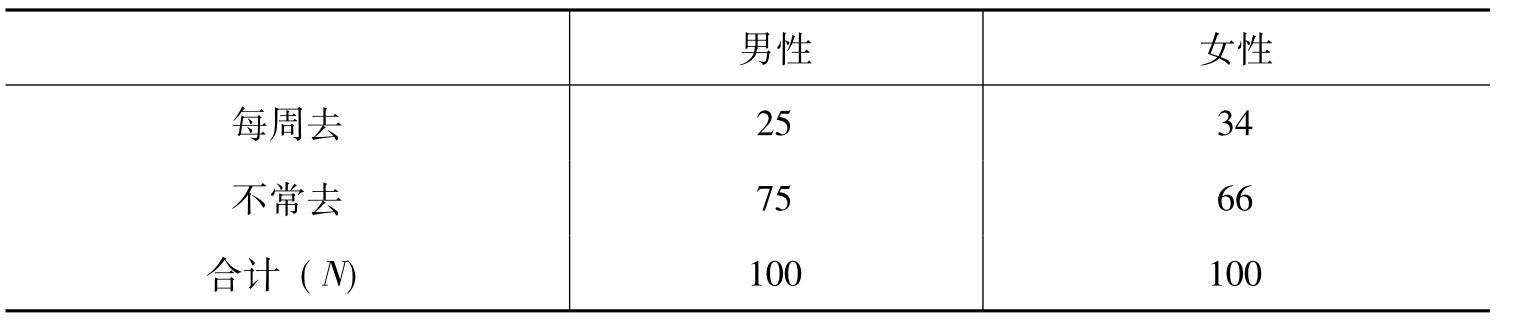
(男性样本为901,女性样本为1134)
在描述意义上,从表11-2可以看出,女性上教堂比男性更为频繁。但是,从解释意义上可以看出,性别自变量对上教堂因变量具有影响,上教堂在某种程度上由性别决定。这种解释与葛洛克的“慰藉假设”一致:在美国社会中,女性仍然被视为二等公民;在世俗社会中无法获得地位满足的人,可能将宗教作为一种地位的替代来源;因此,女性会比男性更倾向于信仰宗教。
一般来说,变量间的因果关系对于理解百分比表格具有重要意义。在这里,女性与上教堂的因果关系较为明确,但在某些社会现象中,很难确定因果关系的顺序。此外,在子群比较中采用何种表达方式也极为重要。在此,我们使用的百分比这样一个相对指标,而非采用样本个案数的绝对数值。
在这里,还有一个阅读表格的正确方式问题,即如何理解表格中的百分比。如果把表11-2这样解读就会出现问题:“在女性当中,有34%的人每周都会去教堂,而有66%的人并不常去教堂;因此,女性并不经常上教堂。”在这里,我们是以性别作为自变量来解读上教堂这一因变量的。因此,对表格的理解必须依据男女性别的比较结果来下结论。特别是,我们应该拿34%和25%进行比较,这样才可以注意到女性比男性更可能每周都上教堂。
一般而言,在表格中,百分比的方向是研究者主观确定的,它们不影响由表格得出的结论。但是,在理解表格时,我们需要找出表格百分比的方向。这个通常可以从表头或者变量分析的逻辑中发现。此外,要注意行与列的加总百分比。如果各列加总百分比为100,那么该表格就是纵向百分比;如果是各行加总百分比为100,那么该表格就是横向百分比。总体来说,存在这样的阅读表格规则:
如果表格是纵向百分比,那么,按行横向来读。
如果表格是横向百分比,那么,按列纵向来读。
2.列联表的格式
通常而言,我们把上面形式的表格称为列联表(Contingency Table):因变量的值必须依靠自变量的值而定。一般来说,制作一个解释性的列联表需要这样的几个步骤:
首先,按照自变量的属性将样本分组。
其次,按照因变量的属性来描述这些分组好的子群体。
最后,按照因变量属性将自变量的子群体相比较,以解读这个表格。
在社会科学中,列联表的使用非常普遍,尽管不同的研究者会采取不同的形式,但是有一些基本的原则是大多数表格资料都要遵循的:
第一,表格必须有表头或标题,以简洁地描述表中内容。
第二,变量的内容必须清楚说明。如果可能的话,要呈现在表格中,或者写在正文中,再外加一段附于表中。当变量是取自对态度问题的回答时,这个信息尤其重要,因为答案的意义主要取决于对问题的问法。
第三,必须清楚说明每一个变量的属性。尽管需要简化复杂的类别,但在表格中其意义必须清楚。
第四,当在表格中使用百分比时,需要说明计算的基准。将每一个类别的原始数据都写出来是多余的,因为这些数值可以根据百分比和基准计算出来。此外,将数值和百分比同时列出会造成混淆,容易导致理解上的困难。
第五,如果因缺失资料如无答案而将某些样本删除,其数量必须在表格中标示出来。
3.列联表χ2检验
从上述内容中,我们可以知道,列联表主要适用于变量为定类—定类类型的数据,它是将研究所得的一组数据按照两个不同的变量进行综合的分类。通过列联表,我们可以较为深入地理解样本资料的分布状况与内在结构,并在此基础上对变量间的关系进行分析和解释。但是,这种分析和解释主要在样本范围内成立。而我们研究的目的则不仅仅是描述或说明样本,我们更为关注的是通过样本的情况来反映和表现总体情况。为了保证我们从样本中获得的结果具有统计意义,保证样本中呈现的变量关系同样存在于总体之中,我们必须对列联表进行χ2检验。在这里,我们主要介绍χ2检验的基本步骤。χ2检验的计算公式为:
![]()
在该公式中,fo表示列联表中每一格的观察频数;fe表示列联表中fo对应的期望频数。
fo可以由表格直接提供,而fe的计算方法为:用每一个fo所在行的汇总数乘以其所在列的汇总数,再除以汇总的个案数。
χ2检验的具体步骤为:首先,建立两个变量间无关系的假设;其次,计算出χ2值;再次,根据自由度df=(r-1)(c-1)和给出的显著性水平,即P值,查χ2分布表获得相应的临界值;最后,将χ2值和查表所得的临界值比较。如果χ2值大于或等于临界值,则列联表中自变量对应的子群体在因变量值上差异显著;如果χ2值小于临界值,那么,列联表中自变量对应的子群体在因变量值上无差异显著。下面,以具体案例说明。表11-3是一个关于城乡中学生升学意愿的列联表。
表11-3 城乡学生升学意愿分布表(7) (单位:%)

如果仅从列联表的百分比来看,可能会得出这样的结论,即两类学生在是否考大学上差异显著,城市中学生想考大学的比例明显高于农村中学生。但是,这仅仅是样本情况,我们能否用之推论总体还需要进一步检验。下面,我们对上述结果进行χ2检验。
由上面的公式,可以得到χ2值为3.692;然后,我们设定P值为0.05,在此显著性水平下查χ2分布表可得临界值为3.841。两者比较,可以看出,χ2值小于临界值。至此,可以发现,列联表中自变量(学生类型)中两个子群体(城市中学生与农村中学生)在因变量(上大学意愿)上没有显著差异。由此可知,从列联表中的百分比数据并不能得出城乡中学生在考大学意愿上存在显著差异的结论。
需要说明的是,由χ2检验公式可知,χ2值的大小不仅与数据的分布有关,而且还受到样本规模的影响。当样本规模足够大时,一些很小的分布差异也可以通过χ2的显著性水平检验。也就是说,对大样本来说,以χ2检验来确定变量间是否存在显著性关系并无太大意义。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











