



一、信度和效度
评估研究(evaluation research)有时称为项目评估(program evaluation),目的在于评估论证工作,并非是一种论证方法。项目评估的概念应用领域很广泛,从研究方法论角度来看,评估者考察某项研究的科学性及其价值,主要关心两项指标:效度和信度(reliability)。当然,评估者也应包括研究者本人。研究者在完成一项研究或取得阶段结果后,最好能超脱研究者的立场,按局外人的思维方式来评估这些结果,这样做很有必要,可帮助发现研究工作中的问题,尽管要做到“超越”很困难。
管理研究除了纯粹描述性的研究,都是为了发现某种变量与变量、现象与现象之间的联系,如前面列举的一些例子,无形资产导致东道国和跨国企业双方得益,自杀率的决定因素是社会的和谐程度等。每项研究或每篇研究论文对于两变量间关联的论证力度不会相同,最好的情况是读者信服研究者提供的论据和推理过程,同意研究者对两变量关联的解释并排斥其他的解释。方法论常采用内部效度(internal validity)的术语来描述这种论证力度。
内部效度概念首先由坎布尔和斯坦利(Julian Stanley)于1963年提出,用来考察经验证过的研究假设,判断其表述的变量间关系的可信程度。前面提到“求知”(knowing)是个人对于变量或现象之间存在关联的主观判断,而“知识”(knowledge)则是个人判断已取得社会共识的结果,从这个角度说,内部效度可理解为:研究者的判断可以取得共识并成为知识的程度。
一项研究的内部效度高,说明研究者对变量间关联的命题在研究设定的情境下是成立的。然而,在其他的时空条件或其他的分析单位情况下,该项命题是否适用,新的有关这些变量间关联的研究是否会得出同样的结果,内部效度并不能回答这个问题。研究者关于变量间关联的判断是否具有普遍性(generalization),能否在超越研究情境下同样成立,这就要引入另一个概念,即外部效度(external validity)。外部效度描述研究者已证实的假设可供推广的程度,辨明此项假设所断定的变量间关联的适用范围和环境。
评估研究中,内部和外部效度都须考察。内部效度表明所论证的变量间关系的科学性和可信程度,其值越高,说明该项研究内部的论证和推理逻辑越严密。外部效度表明所论证的变量间关系在其他情境下的适用程度,其值越高,说明此研究结果应用价值越大。
信度或精确度(reliability)是和效度并列的、评判研究工作的另一项重要指标。信度表示对于同样的对象,运用同样的观测方法得出同样观测数据(结果)的可能性。例如测试职工对于领导层的满意度,第一次测试结果是40%职工很满意,20%职工很不满意,第二次用同样的问卷和数据处理方法得出测试结果是10%很满意,30%很不满意,这种观测结果的信度不高。
信度和效度的关系如图5-13所示。(a)图的信度高、效度低,(b)图表示无信度、低效度,(c)图的效度、信度均高。可见,信度表示度量结果的重复性,数据与平均值的差异程度,第一章已提到,重复性是科学研究的一项必备属性。效度则判断度量结果是否真正是研究者所预期的结果,指数据与理想值的差异程度。
图5-13 效度和信度关系
信度是效度的必要条件,但非充分条件,若在不同时间进行测量,两次测量的结果变异很大,不仅没有信度,也必然没有效度。但在实用上,效度检验最为有效,如测量工具(问卷、实验设计等)效度合格,往往无须去关心它的信度,只是效度不够才进而评价信度。
信度较之效度可以更直观地加以测量,常用的信度指标有三类:稳定性(stability),等值性(equivalance)和内部一致性(internal consistency)。
1.稳定性
由同一个受测者应用同一种测试工具(如问卷)作出反应(如回答),若能出现前后一致的结果,则称这种测试方式具有稳定性。例如,工作地写实,观测一位车工加工某零件的工时。如多次观测得到的工时记录都一样,这便是稳定的观测过程。稳定性的判断主要受到时间因素的干扰,因为两次观测的时间间隔中可能出现其他因素影响观测结果,如工时观测中,另一批零件的材料性能差异等,但并不说明这种观测方式不具备稳定性。
实地研究的直接观测法常应用此稳定性指标,因为它易于反复观测同样的行动,比较前后两次的观测结果,并判断此观测方式的信度,指导后续观测。问卷法就不同,通常被调查者能按问卷回复一次就不错了,难以重复测试,稳定性判断也变得困难。
2.等值性
信度的第二个方面是考虑不同观测者(实地研究)对同一测试项目(问卷法中的问题和量表)带来的测试差异。从时间角度来说,稳定性关注不同时刻点的人员和情境变异,等值性则关注同一时刻点、不同人员对某测试项目带来的测试误差。差异越小,等值性越高。如问卷法,比较各个被调查者对同一测试问题的打分,便可判断此测试方式的等值性。等值性指标值并非总是越高越好。利用同一测试项目有不同测试结果的现象,可以将被调查人员分类,同类人员的测试等值性高,不同类人员等值性有显著差异,这往往是研究者为了发现和分析问题而期望得到的结果。
3.内部一致性
信度的第三项内容是观测项目(指标,问卷的问题等)之间的内部一致性(internal consistency)或同质性(homogeneity)。
内部一致性关注不同测试项目所带来测试结果的差异。任何观测工具的测试项目(如问卷中的问题,考卷中的试题)总是有限的,亦即具有选择性。不同测试项目得出同样的测试结果,便符合内部一致性。如设计业务水平考核的试题库,由该题库中随机抽取若干组题目,若同一水平的受试者按各组试题都能考出同一档次的成绩,则此题库具有良好的内部一致性。企业客户管理中,采用不同的问卷而客户分类结果却是相同的,说明这些问卷符合内部一致性要求。
内部一致性指标在问卷法观测数据中经常用到。本章“结构方程建模”一节中,内部一致性就是相关软件AMOS等的一项重要计算指标。因为“结构方程”所包含的测量模型部分,主要是运用确定型因子分析技术。这就要求研究者为一般属于潜变量的因子设计若干个可测试的显变量,亦即本节所说的“测试项目”,这些测试项目之间的内部一致性便是有待检验的指标。
当测量工具含有多个同类测试项目时,可使用折半法(split-half techniques)将测试项目按单双数或其他随机方式分成两半计分,如果两者相关程度很高,则代表测试项目的内部一致性高。
折半法的主要问题是折半的分类方式,可能会影响内部一致性系数。为此常使用KR20法(Kuderd Richardson)与Cronbach′sα系数法。KR20法适用于测量答案只能二选一的测量工具,而Cronbachα系数则常用于定距尺度的测试量表,它的应用最为普遍,“结构方程建模”一节中即用该指标,其表达式为:
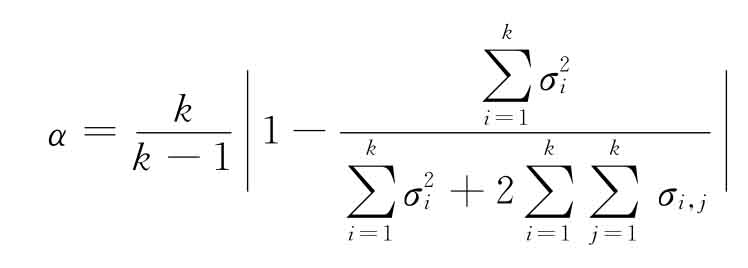
k为所探讨的问卷项目之个数。
例5.5 设对三个指标(V1~V3)作内部一致性信度计算,此三个指标之方差各为0.71,0.58,1.28,而协方差为:Cov(V1,V2)=0.23,Cov(V1,V3)=0.34,Cov(V2,V3)=0.15,则
若为探索研究,此α系数一般应大于70%,应用研究则大于90%为宜。
无论是评价内、外部效度或信度,都有一个前提条件,它就是研究结果的可测性。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










