



3 结果与分析
3.1 出口对中国茶叶需求规模的影响趋势
图2是通过五年平滑移动后的茶叶出口占茶叶总产量比例的趋势线。从总体上来看,图2的趋势线反映最近20多年出口对中国茶叶需求规模的影响程度有缓慢减弱趋势。另外,该趋势线表现出某种程度的周期性特征。20世纪80年代后5年,出口比例值呈上升趋势,随后约10年时间,比例值逐渐下降,但此后又有约5年的回升,并于2003年左右达到相对高值。如果茶叶出口比例值的确存在周期波动的规律,那么2003年的后十年,茶叶出口占总产量比例值进入下降周期。
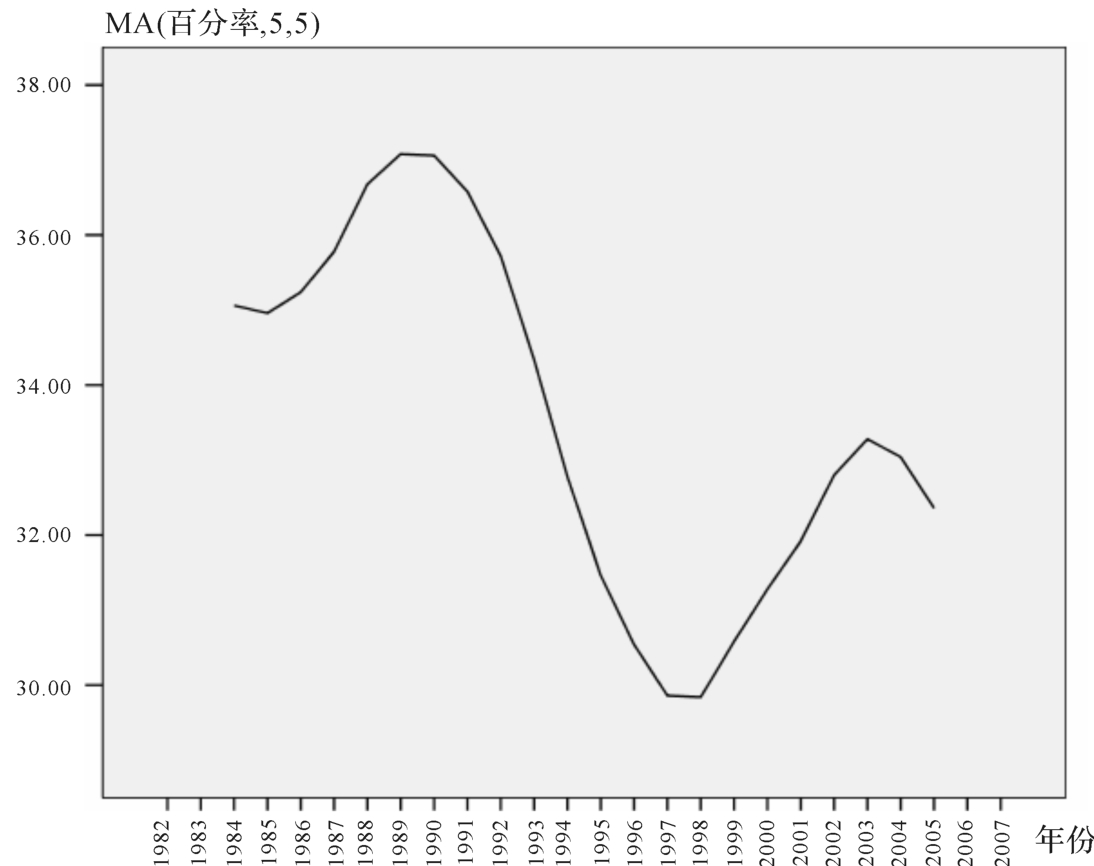
图2 茶叶出口对总产量比例的五年平滑移动均值趋势
3.2 国内市场茶叶需求规模影响因素的计量分析国内市场茶叶消费规模(Y)对人口和可支配收入的回归模型为
Y=-37.564+5.309X1+0.06X2(3-1)(1.183) (0.008)
t=4.487** 7.543** N=30模型R2=0.936,调整R2=0.931,而且系数t统计量均通过显著性检验,因而模型的整体拟合比较理想。另外,共线性诊断结果显示,特征根Eigenvalue≠0,条件指数Condition Index<30,V IF<10,说明自变量并不存在显著共线性。模型中人口变量(X1)的系数为正值,说明随着人口的增长,茶叶消费量会随之增加。另外,可支配收入(X2)的系数亦为正值,说明茶叶消费品具有收入弹性的特征,这符合茶叶不是劣质品或必需品的假设。根据上述统计检验结果,可以初步判断模型(3-1)是可行的。依据该估计模型,假如可支配收入不变,当人口增加1亿人时,需求量将增加5.3万吨;同样,假如人口不变,当可支配收入增加10%,则需求量较原收入水平的消费量约增加0.6%。
当模型(3-1)中增加液态茶饮料变量(X3)(用中国饮料工业协会统计中的其他饮料数据值表示)后,模型转变为Y=617.319-48.842X1+0.130X2+0.015X3(3-2)模型中调整R2=0.947,诊断结果显示模型亦不存在共线性问题,但X3系数的t统计量没有通过显著性检验。另外,X1的系数为负值,这不符合随着人口增多茶叶消费量增加的实际情形。综合分析认为,液态茶饮料变量在模型中没有增加的必要。当然,该结果不能说明茶饮料的消耗对国内茶叶需求没有显著性影响。由于国家相关部门只是在近几年对软饮料进行分类统计,所以模型分析的样本很小(N=11),依据小样本来估计模型可能会出现很大的偏差。
3.3 中国茶叶需求规模的预测模型
1.简单的时间趋势模型
出口量(M odelⅠ)以及国内市场茶叶消费(模型Ⅱ)的时间(t)趋势预测模型统计量见表1。尽管模型Ⅰ和模型Ⅱ整体的R平方均大于8,时间变量的系数均通过显著性检验,但模型中的Durbin-W atson统计量仅分别为0.580和0.380,远离2的水平,反映模型中的残差存在明显相关性,即存在序列相关问题。因此,使用简单的时间趋势模型来进行预测时,必须非常谨慎。
表1 中国茶叶出口和国内消费的时间趋势预测模型统计量
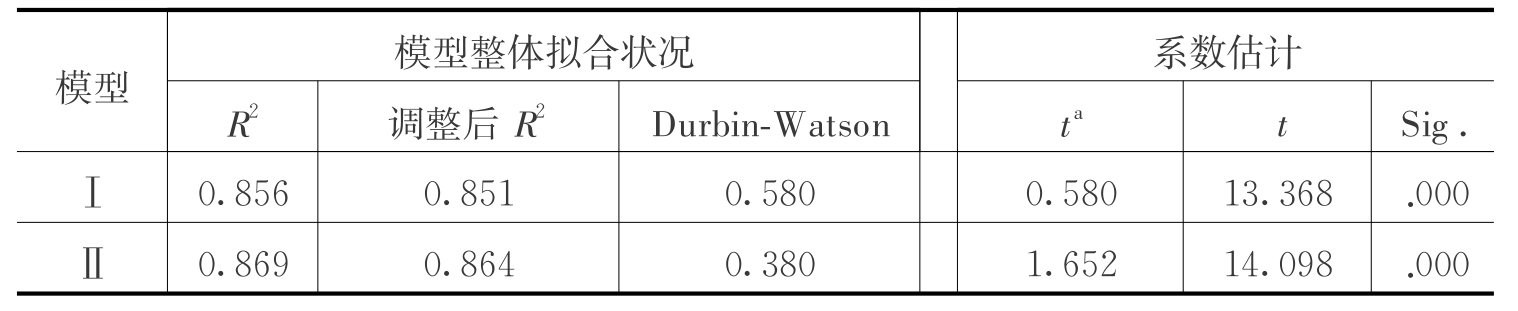
注:“a”为时间变量的系数。
2.自回归模型
时间趋势模型中增加一阶自回归变量后,模型的统计量见表2。出口量自回归模型中的Durbin-W atson>1.65,可以推断残差为白噪声序列,即不存在序列相关或不明显。从残差的非相关角度来看,模型(3-3)较简单的时间趋势模型已有明显改善,出口量的一阶自回归模型在统计上是可行的,其数学表达式为~Y=8.619+0.610Tt+0.710Yt-1(3-3)
与出口量自回归模型不同的是,国内市场茶叶需求模型的Durbin-W atson值=0.680,明显地小于2,这说明该模型的残差有显著性相关。因此,自回归模型在预测国内市场茶叶需求规模时,是不可靠的,这需要其他建模方法。
表2 中国茶叶出口和国内消费的自回归预测模型统计量
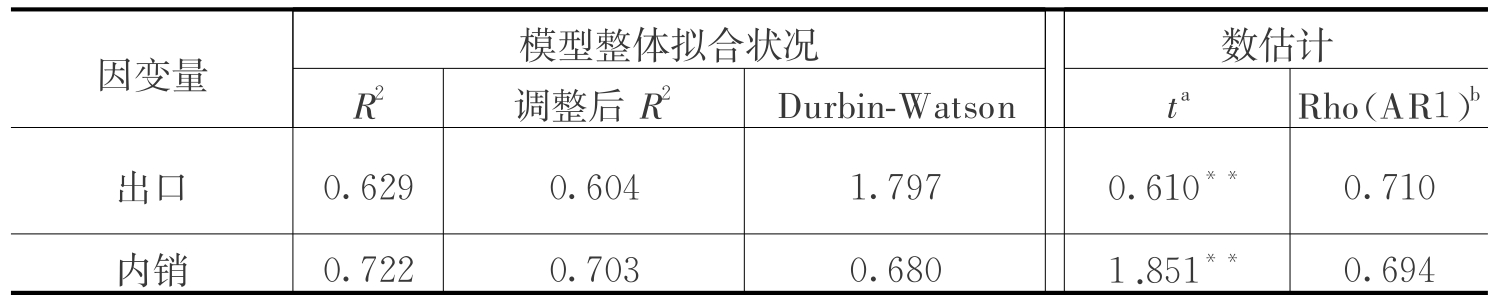
注:“a”为时间变量的系数;“b”为自回归系数
3.国内市场需求预测的ARIM A模型
(1)模型识别。
一阶差分后,国内茶叶需求量(1976—2007年)的自相关函数(ACF)和偏自相关函数(PACF)见图3和图4,其ACF呈拖尾衰减,PACF一步截尾,可判断为平稳序列,因而可初步将模型识别为ARIM A(1,1,0),进而对参数进行估计。
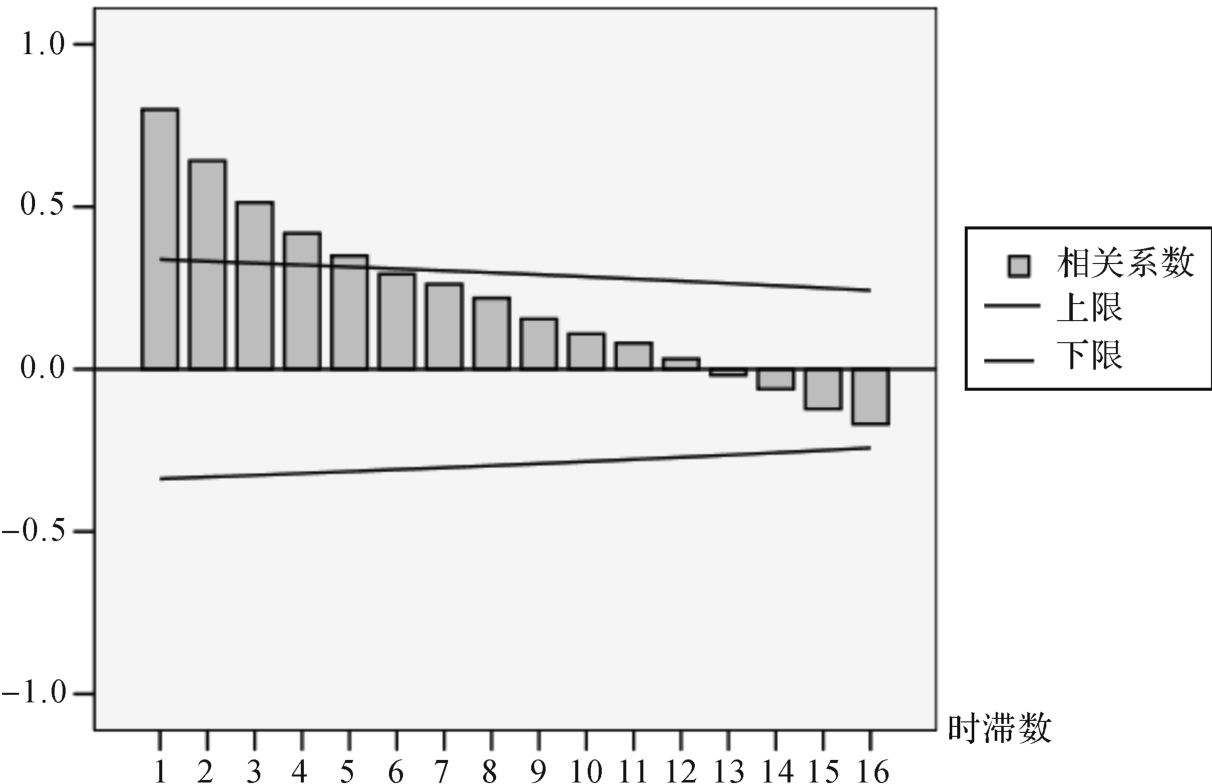
图3 国内茶叶消费量一阶差分序列数据平稳性检验的自相关函数图
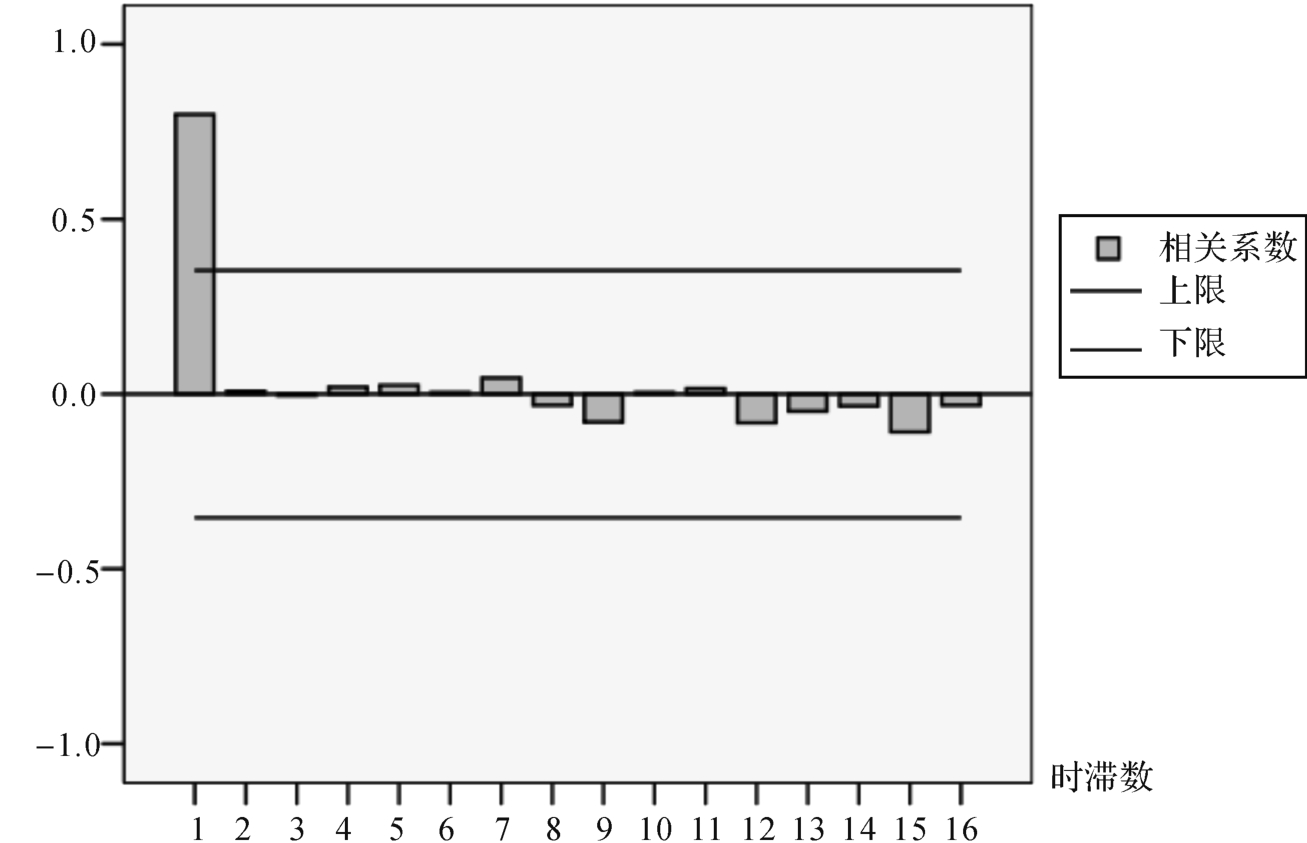
图4 国内茶叶需求量一阶差分序列数据平稳性检验的偏自相关函数图
(2)AR IM A(1,1,0)模型参数估计。ARIM A(1,1,0)模型的数学表达式为(1-Ф1B)(1-B)Yt=μ+at(3-4)其中Yt为国内茶叶需求量,Ф1为自回归系数,μ为常数,at为白噪声。将表3中的系数值代入模型(3-4),得(1-0.561B)(1-B)Yt=2.609+at进一步化简,得Yt-1.561B Y t+0.561B2Yt=2.609+at即 Yt=2.609+1.561 Yt-1-0.561Yt-2+at(3-5)
表3 国内茶叶需求ARIMA(1,1,0)预测模型的系数估计

(3)模型的诊断。
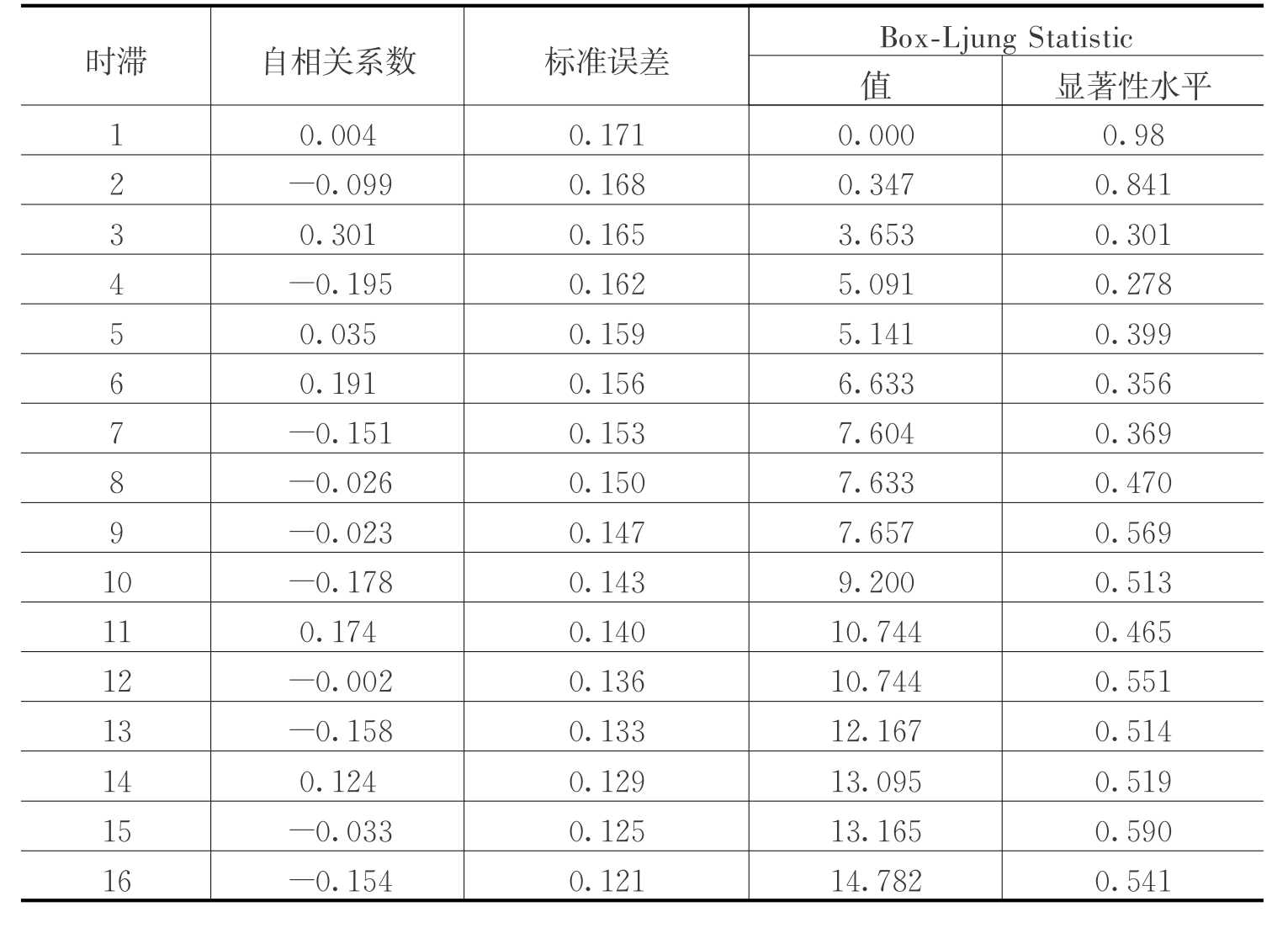
模型(3-5)是否很好拟合还需要对残差序列进行自相关检验,亦称残差的白噪声检验。如果自相关系数统计量的P值出现小于0.05,则认为残差存在自相关性,模型拟合不足,需要改进。模型(3-5)残差自相关检验的结果见表4。表4中的P值都远大于0.05,据此,可以判断残差为白噪声序列,模型诊断可以通过。
表4 模型(3-5)残差的自相关检验结果
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










