



近年来主题检索语言理论及应用研究进展
张燕飞
武汉大学信息管理学院 武汉 430072
【摘要】文章在回顾主题检索语言研究历史的基础上,分别介绍了主题检索语言的理论基础、网络环境下主题检索语言的应用、汉语自动标引,以及主题检索语言与其他检索语言的融合等方面的研究进展。指出在新的信息环境下,主题检索语言的应用有其局限性。因此,重构主题检索语言的理论框架,加强主题检索语言在实践方面的变革与创新研究十分必要。
【关键词】主题检索语言 网络环境 研究进展
The Progress of Research on the Theory and Application of Subject Retrieval Language in Recent Years
Zhang Yanfei
School of Information Management in Wuhan University,Wuhan,P.R.China,430072
【Abstract】Based on the review of the history of research on subject retrieval language,this paper discusses the research progress ofsubject retrieval language's theoretical bases,its application in the network environment,Chinese automatic indexing,and the integrative of subject retrieval language and other retrieval languages.To point out that under the recent information environment,the subject language has its limitation.Therefore,reconstruct the theory frame of the subject language and strengthen the innovation and transformation of the subject search language in practice is extremely essential.
【Key words】subject retrieval language network environment research progress
主题语言是以自然语言的语词作为标识,采用语词揭示和描述信息的主题内容,按主题字顺组织与检索信息的一种情报检索语言。传统意义上的主题语言系指标题语言、元词语言和叙词语言等受控型的人工语言。随着计算机技术的应用,网络技术的普及和发展,用于组织与检索信息用的主题语言已超出了人工语言的范畴,其研究边界在不断扩大,研究内容不断拓新。一方面,传统主题检索语言的改造与创新被提到议事日程;另一方面,自然语言检索的“回归”(1),自然语言在信息检索中的应用,使人们将自然语言的研究纳入主题语言的视野。同时,计算机技术的应用,以及网络技术的普及和发展还对主题语言的研究提出了许多新的课题,并为主题语言的应用提供了新的平台。
1 主题检索语言研究的历史回顾
最早的主题检索语言直接采用自然语言。我国古代类书和国外的《圣经索引》均是以书中出现的语词为标目,利用自然语言的语词提供检索途径。英国人克里斯塔多罗(A.Crestadoro)于1856年写的《图书馆编目技术》和英国索引之父惠特利(H.Wheatly)于1878年所著的《什么是索引》被认为是早期的主题检索语言的论著(2)。然而,对早期主题检索语言创制贡献最大的当推美国图书馆学家克特(C.A.Cutter)。他在总结早期主题检索语言的理论与实践基础上,发表了著名的《字典式目录条例》,提出了标题法的基本原理和方法。在克特思想的影响下,欧、美各国的一些图书馆字典式目录备受欢迎,并在图书馆目录系统中逐渐占据主导地位。1895年美国图书馆协会根据克特思想编制、出版了世界上第一部大型标题表《字典式目录中使用的标题表》,亦称《美国图协标题表》。1904~1914年美国《国会图书馆标题表》(LCSH)问世,这部以《美国图协标题表》和国会图书馆标引实践为基础编制出版的标题表,经过定期全面修订,已经成为世界著名的标题表。在LCSH的影响下,20世纪上半叶,世界上编制出版了几百部标题表,其中比较著名的有:《西尔斯标题表》、《工程标题表》、《医学标题表》、《日本国会图书馆件名标题表》等。在世界众多的标题表中,LCSH以其悠久的历史,浩大的词量和及时的修订而独占鳌头,成为有史以来使用最为广泛的标题表。在主题语言发展史上,LCSH是一部举足轻重的词表,无论是编制技术还是实际应用,LCSH都把标题语言的功能发挥到极致,把标题语言的发展推向了顶峰。
这部著名的标题表的编制与管理有几个明显的特点(3)(4):(1)它是以美国国会图书馆自1897年以来的字典式目录工作实践为基础的。因而有着充足的“文献保证”;(2)能够随着时代的进步、藏书的增长及语义关系的变化而不断地发展和完善;(3)该词表学科面广、收词量大、参照数量多、复分标题用法规范,因而便于用户使用;(4)该词表管理完善,有力量雄厚的管理机构,有多种载体的不同版本(印刷版、缩微版和机读版),有不同周期(月度、季度和年度)的累积本和增补公报。并从1988年第11版起,每年出一新版。目前,这部标题表因其管理机制完善,并与书目数据捆绑发行,使其成为标题语言的标准,具有很大的权威性,继续影响着世界图书情报界。
标题语言的产生和发展,打破了分类法的长期统治,开创了文献组织和检索的新天地,尤其是其专指性、直观性等特点,给人们检索和利用文献带来了方便。但是,标题语言是一种先组式的检索语言,它同体系分类法一样,总不能达到按事物各种特征的任意组合来自由检索文献信息的可能性。因此,人们又探索出了一种新的主题语言,即单元词语言,如同组配分类法的出现是为了克服体系分类法的局限一样,单元词语言是作为对标题语言先组式标识的改革而出现的(5)。早在1939年,英国帝国化学公司的巴顿博士(W.E.Batten)创造了“比孔卡片”的组配检索方法,这是倒排档的开始。1951年,美国学者陶布(M.Taube)建立了单元词卡系统,提出了“单元词组配索引法”概念,其基本思想是用元词(Uniterm,又称单元词)来表达文献的主题事物,这些单元词是从文献正文中直接抽取的,未作任何形式的控制。20世纪50年代,单元词法为美国一些有影响的政府组织和工业组织所采用。由于单元词法以单元词为标引单元,直接性差;实行字面分解和字面组配容易产生歧义等缺点,实行不久就被叙词语言取代而不复存在。但是单元词法对于主题检索语言的发展具有积极的作用(6)(7):(1)开创后组式主题检索语言的先河,具有较高的标引能力;(2)有利于充分发挥机检系统的性能;(3)能实现多途径检索,自由扩大、缩小和改变检索范围;(4)建立了有效的词汇控制方法,创立了句法控制符号。特别是,它为叙词语言的产生和发展奠定了基础。
20世纪60年代,一种新型的情报检索语言——叙词语言横空出世。叙词语言综合了多种情报检索语言的原理和方法,集各法之大成,并以能与不断发展的情报检索技术相适应的特点,很快在世界范围内得到广泛应用,一跃成为情报检索语言的主流。20世纪60年代至80年代是叙词语言发展的黄金时期,据德国情报与文献工作协会(FID)1985年编辑出版的《叙词表指南》一书统计,世界上仍在使用的英、法、德文叙词表有654部(包括部分标题表),麦麟屏等编写的《联机数据库所用叙词表:分析指南》(1988年)中收集了当时联机数据使用的英文叙词表122部。至于世界现有各语种叙词表,则有千余种(8)。这些叙词表覆盖不同学科、专业,大到自然科学与技术各个领域或跨学科、专业的词表。如美国国防部工程师联合会编的《工程与科学叙词表》(TEST)、日本科技情报中心编的《JICST科学技术用语叙词表》等,小到一个专业,甚至一个问题、一种产品的词表。并且被世界上绝大多数采用规范语言的数据库所采用,一般文献型数据库都有相应的检索刊物及叙词表。如联合国系统组织机构、国家统一和地区协作的情报中心、新闻机构以及专业情报中心等,都有本系统固定使用的叙词表。可以这么说,叙词语言的产生对于世界范围内20世纪60年代以计算机为基础的脱机处理系统的大量投入使用和70年代联机检索的发展与普及有着重大的作用。网络环境下,叙词语言仍然发挥着其他检索语言所不可替代的作用。(9)
这一时期主题语言的发展还有三个重要趋势:一是叙词表版本的多样化,叙词表管理计算机化;二是叙词表词汇显示多样化、分类主题一体化(10);三是自然语言在情报检索中的应用。
叙词语言是一种计算机检索的主题语言。早在20世纪60年代在编制印刷版词表的同时,就制作了机读版。由于机读词表独特的优点,以后越来越多的词表用机读形式和缩微形式(包括计算机输出缩微平片)出版。据有关资料统计,机读目录词表的数量呈逐年增加,60年代有6部,70年代有31部,80年代有42部。词表的机读化有力地推动了词表管理的计算机化。一部完善的叙词表的宏观结构应该由字顺显示和分类显示两部分组成,两者融为一个整体,有利于发挥各自的优点,达到最佳的整体效果。20世纪60年代中期以后,随着词表的迅速发展,词汇显示出现了多样化倾向;与此同时,国外还对分类表和叙词表进行了大量的抽样调查和试验,并在此基础上开始了分类法主题法一体化的理论研究。计算机技术在图书馆和情报工作的广泛应用和情报语言学研究的进展,使分类主题一体化词表的产生成为可能。1969年,英国学者艾奇逊(J.Aitchison)等人编制的《分面叙词表》(Thesaurofacet)正式出版,这部新型词表的出版受到了图书馆和情报界的重视和好评,在其影响下,英美等国陆续出版了一批分类主题一体化词表。1982年在德国召开的第4次国际分类法研讨会(ISCCR)对艾奇逊首创的实现了分类主题一体化的新型词表给予了很高评价。会议的结论指出:“更一致和更完善的分类法和叙词表编制方法,促使了1977年《联合国教科文组织叙词表》和1981年《基础叙词表》的问世。”(11)一体化词表的出现,打破了传统叙词表以字顺为主显示词汇的格局,改用一个详细的分类表与一个字顺表进行词汇显示,叙词语言与分类语言的结合已经形成了一种新型的情报检索语言。
1958年,IBM公司的卢恩(H.P.Luhn)创制了“题内关键词索引”(KWIC),此后关键词索引经过不断改进,出现了多种类型,如“题外关键词索引”(KWOC)“双重关键词索引”(DKWIC)等。关键词索引的创建,为自然语言在情报检索的应用开辟了新的领域,至20世纪80~90年代,自然语言已有了较广泛的应用,在一些系统中,自然语言与规范语言并用,称为“混合系统”(12)。
我国是一个主要使用分类语言的国家,主题语言的研究在我国起步较晚,尤其是叙词语言。1971年出版的《航空科技资料主题表》是我国第一部叙词表。此后,叙词表的研制才有了发展。《汉语主题词表》的编制出版可视为我国叙词语言发展的重要里程碑。参加该表编制的单位之广、人数之多,是在全国范围内的一次大规模的编表实践,并确立了国内自编传统的书本式叙词表的重要编制原则和方式,为我国主题语言的发展创造了条件。进入80年代,我国叙词表的编制工作有了进一步发展,先后编制出版了70余部叙词表,这种势头至90年代仍未削减,目前,我国已编制的叙词表在百部以上,几乎覆盖了各专业和各种文献类型,构成了我国叙词语言体系。其中最具代表性的词表有:《汉语主题词表》、《国防科学技术叙词表》、《军用主题词表》、《中国档案主题词表》等。在这期间,就叙词语言的发展方向,召开过两次全国性会议,研讨了叙词语言的编制理论和技术问题。戴维民认为,20世纪我国主题语言理论与技术研究取得了重要的成就:(1)确立了概念组配是叙词语言的基本原理,叙词法是体系分类法、组配分类法、标题法、单元词法以及关键词法等多种检索语言的原理和方法的综合。(2)叙词表的宏观结构和微观结构的优化,在宏观结构上打破了《汉语主题词表》所确立的“五表齐全”式的宏观结构,特别是分类主题一体化词表的编制,使汉语叙词表的结构有了新的突破,而《国防科学技术叙词表》和《军用主题词表》的等级关系全显示的应用,则极大地优化了词表的微观结构。(3)计算机辅助技术的应用既提高了编表效率,又保证了编表质量,而且使词表的编、管、用一体化。90年代编制的词表都运用了计算机编制技术。(4)制定了一系列标准,使词表的编制和使用纳入了规范化的范畴,同时,词表的标准化也促进了词表兼容化的进展。(5)叙词语言与自然语言的接口及结合使用,以及运用叙词表控制手段编制自然语言检索的后控制词表。(13)
2 主题检索语言的基础理论研究
主题检索语言的理论是指导主题语言实践的基础。1972年,美国情报学家兰开斯特(F.W.Lancaster)出版了《情报检索词汇控制》一书,全面论述了情报检索词汇控制的基本理论与方法,在图书馆及情报界产生了重大影响,被认为是情报检索领域的重要论著。20世纪80年代初,我国著名图书馆学家张琪玉先生从提高情报检索语言的检索效率出发,提出了应从更高层次对分类法、主题法等各种检索方法进行统一研究;于1983年出版了《情报检索语言》一书,这一开拓性研究,对我国情报检索语言领域的理论与实践起到了积极的导向和推动作用。情报检索语言“是表达一系列概括文献情报内容的概念及其相互关系的概念标识系统”(14),无论是分类法,还是主题法都是建立在概念逻辑和知识分类的基础上的。兰开斯特创立情报检索词汇控制理论和张琪玉开创的情报语言学理论,都为情报检索语言的发展作出过重大贡献,现在仍然影响着情报检索语言的改造与创新。
然而,计算机技术的应用和互联网的发展,使信息环境发生了很大变化,一方面,过去庞大有力的联机数据库在欣欣向荣的网络资源面前逐渐黯然失色,以前用于文献前处理的方法和程序在处理庞杂的无结构的网络资源中显得力不从心,无论在速度上、质量上、效率上都无以拿出与文献资源增长水平相应的手段(15)。另一方面,面对互联网上海量的、无序的、良莠不分的信息资源,人们越来越感觉到难以驾驭。为了避免在信息海洋里迷失方向,人们在不断地探索、寻求新的理念、新的方法。最近几年业内掀起的对知识组织和语义网理念的研究热潮,为主题语言的创新和发展提供了强有力的理论基础。
2.1 知识组织理论对主题语言的影响
知识组织(Knowledge Organization)这一概念,由英国分类学家布利斯(H.E.Bliss)于1929年提出,起初是指图书馆学、情报学的分类系统和叙词表,后泛指文献工作。在人工智能领域,知识组织则是指专家系统和问题求解系统中的重要术语,其涵义是指在这类系统中对已经“过程化”的知识加以组织(即加入某些控制信息来控制知识的使用)以满足子目标之间的协调关系的过程。作为一个研究领域,知识组织主要研究信息的表示、编码和组织方法,词汇控制问题,知识组织系统的形成机理、结构、功能、性能评价,以及它的语义、句法和语用学方面,它与其他语言符号系统的关系和连接问题(16)。国际知识学会(ISKO,法兰克福)会刊《知识组织》,把这个领域的研究范围归纳为9个方面,主要包括知识组织理论、分类表、叙词表以及知识组织环境等。
知识组织系统(Knowledge Organization Systems,KOS)是对各种对人类知识结构进行表达和有组织的阐述的语义根据的统称,包括分类法、叙词表、语义网络,以及更为泛指的情报检索语言。Lindo Hill博士等将知识系统归纳为如下一些主要类型(17):
(1)分类和归类系统模式:
①归类的类表(categorization schemes):十分松散的结构,可以是任何分组归类用的大纲。
②系统的分类表(classification schemes):类表中将用于表达泛指主题的类号(数字或字母型)按照等级或分面形式排列。
③标题表(subject headings):提供一系列用以表达一个馆藏中各文献主题的受控词,以及一套将标题组配呈复合标题的规则。
④知识分类表(taxonomies):根据事物的某种特征将事物分成有序类组,例如生物分类学的严格分类体系。
(2)元数据式的系统模式:
①指南(directories):名称及相关信息列表。
②地名辞典(gazetteers)
(3)关系模式:
①实用分类系统(ontology)(又可理解为概念空间concept spaces):用以表述十分复杂的事物间的相互关系的特定概念模式,其中包括语义网络模式中所缺乏的规则和公理。
②语义网络(semantic networks):表达概念的词汇集,按照复杂多变的关系网络中的节点的模式建造。
③叙词表(thesauri):表达概念及其等同、等级、相关关系词汇。另一种类型的词表(如Roget's Thesaurus)则只表现词间的等同关系(同义词),以及词汇的归类。
(4)词汇单:
①规范文档(authority files):用于控制用于同一人或事物的不同名称,或者为某个特别领域中专用名词的词汇单。
②字典(dictionaries):按字母顺序排列的词单,提供词的定义,其中包括对每个词的各种词性的解释。
③术语表(glossaries):按顺序排列的词汇,通常带有定义。
网络环境下,重新研究知识组织和知识组织系统,不是简单的重复,而是螺旋式的上升。在手工检索时代,用于知识组织的工具(分类法、标题表),由于其复杂性极大限制了它们在传统编目环境之外的应用。如DC、LCSH都是为卡片目录设计的,是那个环境下的杰作,然而,由于卡片上的空间有限,而每个类号,每条主题词都要印一张新卡片,所以对每份资料所标引的类号和主题词数量要严格控制,它们是为文献组织实践留下的重要遗产。到联机时代,随着对知识组织系统类型和功能的进一步探索,用于标引和检索的知识组织系统的发展达到高峰,产生出现今仍然在大型数据库中使用的众多叙词表。然而叙词表语言严格的词汇控制规则和句法又限制了它在网络环境下的应用,因为使用者必须受过专门训练。过去的十几年中,那些服务于图书情报信息科学之外的人们已经尝试了无数的工具和方法,直到走过360度后,网络的主要领导力量和大众才又发现知识组织系统的魅力,进而在最近几年内掀起对知识组织系统的研究、开发、应用的新一轮高潮(18)。
目前,在数字图书馆建设中知识组织系统被有机地纳入其中,将数字图书馆的结构和功能扩大,并使之达到更高的水平。这对作为知识组织工具主题语言来讲,提出了更高的要求。一个典型的例子是美国加州大学圣巴巴拉分校的亚历山大数字图书馆(Alexandria Digital Library,ADL)项目(19),该项目的重点在于设计并运行其颇有特色的地理参考数字图书馆。在ADL中,叙词表被应用于宏观结构中,亚历山大数字图书馆(ADL)的重要组成部分——地名辞典的条目就是根据《ADC地貌特征叙词表》来组织的。为了支持知识组织系统的结构既能帮助用户查找所需信息,又在数字图书馆馆藏中做导航的功能,该项目又制定了ADL叙词表服务协议(ADL Thesaurus Service Protocol),作为自动联网查询各种不同词表的通用协议。在一项亚历山大数字地球模型系统(ADEPT)项目中的一个研究,是建立一个概念空间模型,以展示学科领域中的概念及关系,并以此作为本科生教学中的一个最基本的方式。概念空间模型实际上扩展了叙词表模式,对知识领域中概念集的表达更加全面和完善,这种模式的意义在于将概念相互关系本身作为一组组织成分——其本身就是一个知识组织系统。
1998年,OCLC在寻找为从主题角度最佳使用都柏林核心元数据(DC)记录的方针时,开始对主题词汇的新的路径的开发。认为用于网络环境下的主题词汇应满足以下要求(20):
结构上简单明了(即易用于标引和使用),容易维护;
应该能提供最佳的查询点或查询途径;
应该做到在不同的知识发掘和查找环境中(包括联机公众图书馆目录)能灵活地跨学科地操作。
先组式主题用于难以满足这些要求,必须进行现代化改造,如美国《国会图书馆标题表》(LCSH),因为其丰富的词汇和语义关系而被各种元数据标准推荐为主题词来源,被广泛应用于各种数字化资源的主题标引,然而其复杂的句法又常常令人望而生畏,而且现在的LCSH远远达不到以上所举的若干要求,这一点也与都柏林核心元数据集的简单性和语义上的可互操作性相违背。因为使用者必须受过专门训练,其对规范文档的自动化管理效率也因此受到限制。网上信息的迅猛增加迫使书目控制系统向易懂、易用方向转变,主题标目也不例外。美国图书馆学会(ALA)的ALCTS/SAC委员会、美国国会图书馆(LC)最近共同进行了一项编制《FAST(主题术语的分面式应用)》词汇的工作(21)。具体做法是在一个句法简单的分面式的词表中采用LCSH,其目的在于保留LCSH丰富的词汇,同时使之易懂、易控制、易应用、易使用。Edward T. O'Neill和麦麟屏认为,在分面化的LC主题词的基础上,FAST充分显示了它的优越性。
另一个有意义的研究是从知识组织概念出发,构建一个知识组织模型(见图)(22)。
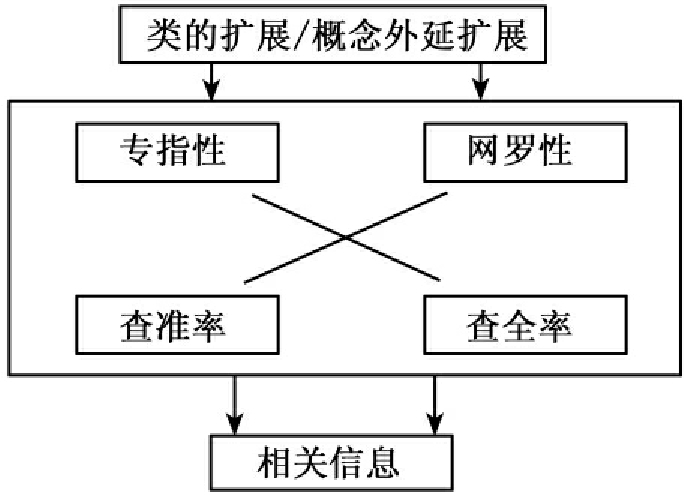
在图书馆学、情报学领域,有效组织和检索信息的策略往往可以通过考察其专指性、网罗性、相关性和其他以主题分析为中心的因素来测试。知识组织模型中的概念与用于信息组织和检索的概念是相同的。
知识组织模型的核心是从混乱的信息中检索出相关信息,相关性也可以理解为近似性(aboutness),即文献(数据)是关于什么的看法可以直接反映在标引(或编码)中。然而,对近似性的更广泛的看法可能包括预测用户的需求,而一个对相关性的面向用户的看法,除了要考察主题的简单意义外,还要考虑效用和环境因素。
文献(23)的作者提出的知识组织模型主要用于组织研究数据,挑选出变量或主题作为指标,对数据进行组织,为进行最终分析创建一个数据的组织体。作者认为,当把知识组织模型用于信息组织时,该模型通过标引从受控词汇的选择流经它的应用,以便为检索创建一个逻辑上组织完备的数据库。王知津等认为,知识组织模型的开发与探讨提供了“一个方法论的概念方法”,(24)尽管它不是万能的,但有助于提高研究的整体质量。对于受控词表的研究亦不例外。
2.2 语义网对主题检索语言的影响
语义网(Semantic Web)是当前因特网的延伸。十几年前(1990年),现为麻省理工学院万维网协会主席的Tim Berners.Lee发明了万维网(Web),人们通过因特网(Internet)可以获得各种信息,但是,Web仅仅是一个单调的内容显示,计算机只负责将一个网页链接到另一个网页,网络不能按照用户的要求自动搜索和检索网页,直至找到所需要的内容。针对目前因特网在信息表达、检索等方面存在的缺陷,万维网的缔造者Tim Berners.Lee于2000年12月在XML2000会议上,提出了下一代因特网的概念——语义网,并于2001年5月在《科学美国人》杂志上发表了同名论文“The Semantic Web”,为人们勾勒出一幅未来语义网的美好前景。
因特网在信息表达和信息检索方面存在的缺陷,主要在于其设计目的是面向用户直接阅读和处理,因没有提供计算机可读的语义信息,因此限制了计算机在信息检索中的自动分析处理以及进一步智能化的信息处理能力(25)。而语义网是一种能理解人类语义的智能网络,可以使人与计算机之间的交流变得像人与人之间交流一样轻松(26),能够满足智能主体(Agent)对WWW上异构、分布信息的有效检索和访问。实现网上信息资源在语义层上的全方位互联,并在此基础上,实现更高层的、基于知识的智能应用。正因为如此,Tim Berners.Lee认为:“语义网使现行网络得以拓展,其信息的涵义得到准确的定义,并能较好地促使人机合作”(27)。
2.2.1 实用分类系统与语义网
语义网的目标是要充分发挥因特网的潜力,最终使技术能够让机器支持全球化的知识交流,实现语义网的核心是对实用分类系统(Ontologies)的开发和利用。美国纽约州雪城大学信息研究学院的秦健博士对此作过详细研究(28)。文献(29)的作者自制了一个《数字化教育资源》的实用分类系统,还将实用分类系统与传统图书馆分类法和可扩展置标语言文献类型定义进行了比较研究。其研究成果认为,三者的主要区别在于概念之间关系的表达,实用分类系统中概念之间关系的表达比其他两者要广而且深。这是由于实用分类系统主要是为机器增加“智能”进而实现自动处理信息,知识分享和再利用而建立的,所以在数据模型和表达语言方面,它的结构与数据库很接近,通过简单处理即可将整个分类系统转成数据库而直接实施到信息系统的开发和建设当中,并且可以为知识采集,知识库的建立提供框架平台。
在实用分类系统的构造方法上,目前主要有两种方法:
一是利用现有的叙词表,如Wielinga等(2001)将美国的Art and Architecture Thesaurus(艺术和建筑叙词表)中的西方家具部分进行改造,建立一个西方古董家具知识管理所用的实用分类系统。在一些专门的领域,往往有编好的叙词表,以这些叙词表为基础,扩充概念特性、关系等成分,建立实用分类系统可以达到事半功倍的效果。
二是利用现有的分类法,如英国曼彻斯特大学的OpenGalen项目。
实用分类系统应用非常广泛,在图书馆学和信息科学领域主要体现在数字化文献处理和检索两个方面。
2.2.2 叙词表与本体(Ontology)
叙词表和Ontology是两种知识组织系统(30)。叙词表是一种语义词典,由术语及术语之间的各种关系组成,能反映某学科领域的语义相关概念。它主要用于对信息进行标引时自动或辅助选择索引词以及进行检索时的后控制,是提高查全率和查准率,实现多语种检索和智能化概念检索的重要途径。
Ontology原本是一个哲学的概念,谓之“本体论”,被哲学家用来描述事物的本质。后来知识工程学者借用了这个概念,一般译为“本体”,在信息科学领域,也有人译为“实用分类系统”。格鲁伯(T.R.Gruber)将其定义为:“Ontology是一个概念模型的明晰的规范说明。”(31)在此基础上,加上一些限定词作进一步展开则为,Ontology是共享概念模型的、形式化的、明晰的规范说明。根据此定义分析,Ontology有如下特征(32):
(1)Ontology是一种概念模型,它是通过抽象出客观世界中的一些现象的相关概念而得到的模型,是进行信息资源管理的基础。
(2)它所使用的概念及使用这些概念的约束条件都有明确的定义。
(3)它所体现的知识是共同认可的知识,反映的是相关领域公认的概念集,它所针对的是团体,而不是个体。
(4)它是一种能在语义和知识层次上描述信息系统的概念模型建模工具,具有良好的概念层次结构和对逻辑推理的支持能力。
本体作为一种能在语义和知识层次上描述信息系统的概念模型建模工具,自提出以来就引起了信息科学、图书馆情报学领域的国内外专家的关注。
近几年来,本体的开发得到很大发展,如联合国开发计划署和Dun&Bradstreet共同联合开发的UNSPSC本体,此本体作为产品和服务提供术语库。美国新泽西理工学院的面向对象保健词汇知识库项目(OOHVR),在语义网中大约有5 000个有组织的概念。最大和最全面的是在美国德州奥斯汀的MCC和Cycorp开发的CYC,大约有50 000个概念,概念之间的约束和关系多于4 000 000个,为常识知识的多个方面提供形式的公理理论。威林加(B.S.Wielinga)等人利用已有的叙词表或分类表来改造本体语言等。
国内图书情报界有人将本体研究与叙词表研究结合起来(33)(34)(35),试图通过对两种知识组织系统的比较研究,找出其共同点和差异性,寻求网络环境下主题语言的优化。
赵焕洲等认为,叙词表和本体都是用来描述特定学科知识,组织特定学科知识的工具;两者都包含词(概念、类)及词(概念、类)间关系,且都具有等级结构,并通过等级关系及词(概念、类)间关系将词(概念、类)组织起来;无论是叙词表还是本体都需要维护以及不断地修订。
李景、钱平则从以下几个方面阐述了叙词表与本体的区别:
(1)从逻辑表达形式上,叙词表中术语是规范的科学语言,使每一个叙词在词语形式和语义上只能有一个概念,而本体中术语,可以是自然语言和半自然语言,不一定是受控的科学语言。
(2)在组织结构上,叙词表中知识点的分布是线性的,一维的,本体中作为概念模型也具有概念层次结构,但由于概念间的关系复杂、交错,其知识点、概念分布是网状的。
(3)本体是一个开放集成的体系,它的底层知识库与概念集可以随科学领域的更新和发展随时进行修正和更新,利用本体动态更新的特点,可以找出学科发展的规律。叙词表虽说也是一个开放系统,可以随科学发展而进行修订、更新,但由于词表结构相对稳定,不能与科学发展保持同步。
(4)在词间关系方面,叙词表在表达语义方面受到明显的限制,只能显示“用、代、属、分、参、族”这样简单的语义关系,而本体中的概念间的关系非常广泛、深入、细致和全面,它可以体现许多在叙词表中无法描述的关系,这是两者最主要的区别,也是为什么基于Ontology的系统可以实现语义检索和半自然语言,乃至自然语言检索功能的奥妙所在。
(5)叙词表是一个词汇库(语料库),但不是知识库,而本体不仅是概念集、语料库,还可以是知识库。
现阶段,叙词表对网络信息组织以及知识表示及组织有一定的局限性,从理论上讲,本体作为一种能在语义和知识层次上描述知识系统的概念模型的建模工具,在知识组织方面相对于叙词表来说具有广阔的发展前景,但本体的构建是一项非常费时费力的工作,这大大制约了本体的发展和应用。目前,国内外一些学者、专家正在积极研究如何基于叙词表来构建本体的问题(36)。
3 网络环境下主题语言应用研究
近年来,因特网的广泛应用和发展,构成了人类信息环境变化的重要层面。网络跨越时空障碍,使世界范围内的信息交流、资源共享成为可能,同时它也对传统的信息组织和检索方法构成了很大冲击。网络信息的无序、无限、优劣混杂,人们纷纷在网上发出“从混沌到有序”,“使我们编制的缠绕的网不再缠绕”的呼吁(37)。在网络信息世界这个浩瀚、动荡的信息海洋中,准确、及时、有效地获取与自身需求相关、切题和适用的信息,对所有网络用户来说是十分重要的,同时也非常具有挑战意味。因而,出现了对网络信息组织研究的热潮。
3.1 网络信息资源的组织方法
随着网络信息组织与检索实践的不断丰富和发展,各种类型、各种品牌的网络信息检索工具如雨后春笋般不断涌现,其各自的检索功能与服务在不断完善;结合网络信息资源检索特点的各种行之有效的检索策略、方法与技巧等也在逐步的探究和形成中。其中,将传统情报检索语言的思想和原理应用于网络信息组织和检索是非常重要的一部分,图书情报界十分重视研究传统情报检索语言在网络信息组织中的应用。
3.1.1 网络信息组织的分类法
目前,在网络信息组织与检索中分类组织方法的运用主要有如下两种情况:
一是采用一些著名的文献分类法(有的经过一定的改造)作为组织网络信息的方法。如OCLC的Net First系统、加拿大图书馆的加拿大主题信息系统(Canadian Information by Subject)、英国联合信息系统的BUBLLINK、荷兰国家图书馆的荷兰电子主题服务系统等采用DDC作为网上信息组织的检索系统,而美国依阿华州立大学的网络数据库(Cyberstacks)以及中国教育系统的中国教育科研网则采用的是LCC和《中图法》。
二是参考文献分类法的形式或类目体系,设计分类导航体系,建立分类目录,这是大多数网站、搜索引擎采用的主要形式,如著名的搜索引擎Yahoo就设立了功能强大的分类目录。
3.1.2 网络信息组织的主题法
网络信息组织和检索中的主题法是不同于网络信息分类目录的另一种方法。主题法是利用语词对信息进行揭示与组织,具有“直呼其名、依名查检”的直接性;描述信息主题用标识和检索用标识都采用自然语言语词,便于用户掌握;使用组配形式,概念表达灵活,在计算机网络化技术中易于实现;通过确定语词间的关系,可以揭示概念之间的复杂关系。在网络环境下,利用主题语言进行信息和检索,就是通过一定的计算机程序,实现从网络信息单元主题的语词出发,直接捕获信息。康桂英等在分析了主题的优势后认为(38)(39),网络环境下主题法可以实现如下功能:
(1)用于主页信息的字顺主题组织。目前各类网络中关于机构、事物名称或个人的信息几乎毫无例外地采用主题字顺组织方式建立查询系统。这种系统能够按所提供事物的主题名称将有关机构或个人的信息集中在一起,以使用户对机构或个人信息进行全面查询。
(2)创建主题树指引库技术组织与揭示网络信息资源。创建主题树指引库不仅便于浏览器把某一或某些相关主题的节点进行集中,按主题标识集中起来,而且便于指引用户查询所需信息资源。
(3)用关键词法与叙词法相互结合的形式组织与揭示网络信息资源,既有利于用户利用自然语言组织文献,也有利于网络信息资源的准确描述和科学组织。
3.2 关键词法在网络信息组织中的应用
3.2.1 关键词法概述
关键词法是适应目录索引编制过程自动化的需要而产生的。关键词是直接从文献题名、文摘或正文中抽取的具有检索意义的自然语词。由于关键词一般不加规范或只作极少的规范化处理,故网络环境下的数字化信息检索大量采用了关键词法作为检索途径,其运用之广泛使其成为了广受欢迎的“大众化”检索语言。
目前在网络信息组织和检索中,关键词法应用十分广泛,几乎所有的网络信息检索系统都提供关键词检索功能,其中最突出的就是搜索引擎。此外,随着全文检索技术的发展,许多以往控制相对严格的联机数据库及OPAC等也都逐渐增加了关键词检索的功能。李玉安曾就关键词的重要性展开调查(40),他认为,用户乐于利用关键词检索,关键词法具有良好的发展前景。其原因在于(41)(42):
(1)计算机数据管理系统的应用,为关键词语言的自动标引和抽词标引提供了强有力的技术支持和保障。
(2)随着人们标引和检索实践的观念改变,关键词语言有了广泛的用户基础,它的检索习惯和技巧容易被读者所接受。
(3)关键词语言是人工语言标引向自动标引过渡的桥梁。
(4)关键词语言标引+后控词表的方法,是关键词语言自动化建库与检索的转折点。
3.2.2 搜索引擎的关键词检索功能
虽然,搜索引擎采用的都是关键词检索,但不同的搜索引擎提供的检索功能和效果也有不同。一般而言,简单关键词检索的质量比较差,面对浩如烟海的信息资源,单用简单关键词检索很难达到用户满意的效果。因而,为了增强关键词检索的功能,搜索引擎无一例外地都或多或少采用了一些高级关键词检索功能。包括:布尔检索、加权检索、限定检索(网页深度、专家选择、优秀网站、资源类型、数据类型、日期、地区和域名)、截词检索、词组和短语检索、概念检索、容错检索、相似检索、在结果内再次检索、多语种检索和检索结果翻译、自动链接分类类目、过滤检索、按相关度排列检索,以统计链接数判断网页重要性等。这些措施是国外有关关键词检索的研究成果(43),是对关键词检索某个方面的改进,都有助于增强关键词检索的功能。
我国情报语言学家张琪玉先生在《网络信息检索工具增强关键词检索功能的措施》一文中,共列举各种增强关键词检索功能的措施达22种之多,并从中文关键词检索的角度提出带有总结性的看法:
(1)关键词检索基本原理十分简单,原始模式的关键词检索方法容易操作,但检索效果往往不理想,使用户无法容忍。为了提高检索效率,所有的网络信息检索工具都或多或少地采用了增强其检索功能的措施。越是检索效率要求高的检索工具,采用的措施越多,关键词检索易用性的优点丧失也越多。目前网络信息检索工具(如搜索引擎)中的所谓“高级检索方法(即采用增强措施的关键词检索方法)甚至比分类浏览检索方法更为复杂。关键词检索方法之所以在网络信息检索工具中被广泛应用,一方面是主题检索途径不可缺少,而更主要的原因是利用它能使建立索引数据库的过程完全自动化。
(2)在增强关键词检索功能的各种措施中,起主导作用的是布尔检索、加权检索、限制检索和按相关度排列检索结果四种。
(3)网络资源的建库筛选,对关键词检准率的保障有重大意义。但网络资源建库前筛选的覆盖面有限,且实效性也较差,尤其是不可能实现完全自动化的。
(4)对中文网络信息检索工具而言,主题检索途径不可缺少,面对浩如烟海的网络信息资源,不可能完全采用人工主题标引,关键词检索方法是必然选择。采用各种增强关键词检索功能的措施,也成为必由之路。
3.2.3 联机数据库中的关键词检索
联机数据库是网上重要的学术信息资源,其信息组织不同于一般大众性的网络信息组织,其特点如下(44):
(1)有专门机构或开发商组织开发,配备有专业信息加工、组织人员,信息组织更规范,描述更准确,如CNKI。
(2)信息资源大多数是数字化了的文献信息,其组织和检索有较强的理论和实践基础。如美国ProQuest Information and Learning公司出版的《商业信息全文数据库》(ABI),其中收录有2 590多种商业方面的期刊,该系统信息的组织和检索与传统理论、方法的联系较为紧密,受控程度高。
(3)信息内容科学性强,组织和检索的系统性和体系化较容易实现。
(4)用户的知识结构和信息需求比较单一,检索目的性强,检索提问更专业。
(5)一般提供有多种检索途径供选择,检索效率也较高。像美国ProQuest Information and Learning公司的学术期刊图书馆(ProQuest Research Library)数据库,除基本检索和高级检索外,还提供主题指南和出版物检索等功能。此外,还有检索技巧和主题浏览等工具。
联机数据库所提供的关键词检索,可从广义和狭义两个方面理解。广义上说联机数据库的一切检索途径都可视为全文关键词检索。这种检索方式与搜索引擎的关键词检索类似,是建立在文本检索技术上的。狭义的关键词检索则专指对关键词或主题词字段进行检索,这种检索是建立在人工关键词或主题词标引基础上的。目前,大部分数据库都使用的是全文关键词检索技术,为了提高检索效率采用一些增强关键词检索功能的措施非常必要。但张琪玉先生认为(45),采用各种增强关键词检索功能的措施还不可能彻底消除关键词检索的缺陷,甚至不可能基本消除关键词检索的缺陷。网络信息的全自动标引虽很理想,也很有必要采用,但要达到完善程度还有很大距离,这一距离估计不可能在较近的时期内克服。因此,在现阶段,网络信息的人工标引也是必要的、合理的。
3.3 网络信息组织中主题词表的应用
在网络信息资源的组织和检索中,主题词表这一传统信息检索机制被引入其中,并受到专家们的重视,具体表现为联机显示的叙词表得到大力开发,众多的叙词表生产者也纷纷推出传统叙词表管理应用软件。
根据Traugott Koch汇编的一份统计资料(Controlled vocabularies,thesauri and classification systems available in the WWW)显示,目前在因特网上有众多的联机叙词表提供在线服务,如(46):
The Astronomy Thesaurus
(http://msowww.anu.edu.au/Library/thesaurus/);
UNESCO Thesaurus
(http://www.ulcc.ac.uk/unesco/);
AGROVOC Thesaurus(FAO)
(http://www.fao.org/agrovoc/);
The art&Architecture Thesaurus(AAT)
(http://shiva.pub.getty.edu/aatbrowser/);
Thesaurus of Parasitology
(http://www.personal.kent.edu/-slis/zeng/template/thesauri/miller/tp.htm);
ASIS Thesaurus of Information Science
(http://www.asis.ort/publications/Thesaurus/isframe.htm)
联机显示的叙词表涉及学科面很广,其检索途径有浏览检索和提问检索两种,但大多数还是采用的浏览检索。叙词表的浏览方式一般包括字顺浏览和等级分层式浏览。目前单语种词表占多数,也有少量的多语种词表。
除因特网上联机显示的叙词表外,众多全文检索数据库中也使用受控词表(47)。如美国教育资源数据库中使用的《ERIC叙词表》、(http://searcheric.org/)、英国国家数字档案馆使用的《UNESCO叙词表》(http://hdad.ulcc.ac.uk/search/thesaurus.htm)、Pubmed数据库使用的《医学主题词表》(http://www.ncbi.nlm.nih.gov/entrez/ meshbrowser.cgi)、STI数据库使用的《NASA叙词表》(http://www.sti.nasa.gov/thesfrml.htm),以及UMI数据库使用的《ProQuest受控叙词表》(http://www.umi.com/hp/support/vocab/)等。联机数据库检索系统中的词表系统的作用主要就是提供在线的实时帮助,是检索的辅助系统,并不是用来进行信息标引的。在用户对数据库进行检索时,词表系统可以帮助用户选取更准确、更合适的叙词以及叙词之间的逻辑关系,从而构造出较为准确、科学的检索式,提高检索效率,减轻用户在检索时的盲目性,并得到满意的输出结果。邱君瑞认为,要想满足检索和标引的需求,需要编制两种不同的受控词表,一种是用做知识组织的工具,另一种用做自然语言检索的辅助工具。
为了克服网络环境下传统主题词表和关键词表在文献信息处理中的不足,张俊提出一种将主题词表和关键词表结合词表(48),这种词表系统包括主题词表、关键词表、自然语言检索时用的停用词表和存放标引结果并进行检索匹配的文献——关键词表。其中主题词表又由主题词表、词间关系表和范畴分类表组成。
张俊认为,经过改进后的词表具有这样一些特点:
(1)主要通过关键词进行标引,通过文献—关键词表进行检索匹配,通过主题词表的参照系统、范畴等级分类体系及主题词与关键词的对应关系进行扩检、缩检和检索策略的优化。
(2)以关键词表为核心进行标引和检索,充分利用关键词表标引难度小、效率高、检准率高、用自然语言词语构造检索表达式、检索用户智力负担小的优点。
(3)通过建立关键词与主题词的对应关系,在发挥关键词表优势的同时,也没有丧失主题词表组织严谨、标引准确、参照系统完备、方便进行检索策略调整和检索过程优化的特点。
(4)通过对标引关键词的相关排序,可以按照相关性权重进行检索命中文献的输出。
(5)通过停用词表对自然语言的过滤,实现自然语言表达的检索需求的解析,进一步简化信息检索过程。
(6)为了减少词表控制的复杂性,将关键词与主题词的对应关系进行简化,将需要组配对应的词全部转为直接对应,并将组配后产生的新概念也加入主题词表。
4 汉语自动标引研究
自动标引是根据拟存储、检索的文献(题名、文摘、正文)用计算机自动选定标引词的标引技术。自动标引主要有两种类型:自动抽词标引和自动赋词标引。自1958年美国IBM公司卢恩首先提出自动标引以来,已经发展了40多年,在这期间人们研究了多种自动标引方法,如国外报道的自动标引方法有:统计法、语言法、概率法、书目引文法、人工智能法等。国内也研究出了词表切分标记法、统计标引法和神经网络汉语分词法等。目前,人们仍在继续寻求最佳的自动标引方法。
4.1 汉语自动分词技术研究
汉语和西方语言不同,语词之间既无空格也无特殊的标志,所以研究汉语自动标引,首先要考虑书面文献的自动分词。20世纪80年代以来,国内科技人员根据我国技术条件,结合汉语词汇特点,提出了多种分词方法(49)(50)(51)。
(1)基于词典的分词方法。
由王永成、陈培九等提出。该方法的主要思想是:先构建词典,词典中要尽可能包含可能出现的所有词。然后对待分文本按照一定的算法进行匹配,从而实现分词。此种方法可分为正向最大匹配法、逆向最大匹配法、双向匹配法、逐词匹配法、最小匹配法、全切分匹配法等。这种分词方法比较成熟,目前自动分词中多数采用词典分词法。
(2)基于统计的分词法。
由邓钦和、龙泽云等提出。该方法分词的依据和主要思想是:词是稳定的字的组合,因此在上下文中,相邻的字同时出现的次数越多,就越有可能构成一个词,即根据词出现的概率来选择标引词的方法。此种方法能有效自动排除歧义,能识别新词、怪词。
(3)基于语义的分词方法。
由黄祥喜等提出。该方法的基本思想是:在分词的同时进行语法语义分析,利用句法和语义信息来处理歧义现象,一般包括三个部分:分词子系统、句法语义子系统、总控制部分。在总控制部分的指示下,分词子系统进行分词、句法子系统对分词歧义性进行判断,若分析结果准确,则为选用的标引词(52)。该方法的典型代表有:知识分词语义分析法、语法分析法、扩充转移法、邻接约束法、综合匹配法、后缀分词法、特征词库法等。
(4)基于人工智能的分词方法。
人工智能的分词方法主要包括神经网络分词法(贺萌华、李栗等)和专家系统分词法(53)。
神经网络分词法旨在模拟人脑神经系统机构的运作机制来实现分词功能。专家系统是从模拟人脑的功能出发,构造推理网络,将分词过程看做是知识推理过程。
应该说,在我国,汉语分词技术的研究取得了很大进展,上述提出的一些分词法在软件方面已达到或接近实用水平,为汉语自动标引研究和应用奠定了一定的理论和实践基础。
4.2 汉语自动标引方法
苏武华将到目前为止国内所研究的汉语自动标引方法归纳为七种:词典标引法、切分标记标引法、单汉字标引法、统计标引法、句法分析标引法、语义分析标引法和人工智能标引法。他认为(54),(1)词典切分标引法和切分标记法都是先组式标引法,检索速度快,但构建分词词典较困难,词典维护量大;(2)切分标记标引法对切分后的词组或短语需要再分解,但分解模式和分词知识库很难适应汉语灵活的构词变化,较易产生标引错误;(3)统计法是建立在词典切分法和切分标记法两者的基础上,既有两者的优点,也有两者的缺点,相比较其他自动标引方法,统计标引法较为简单实用,且有一定的实际标引效果,但是语言是有意义的符号序列,这类方法要克服单纯统计的形式化缺陷,取得更高的标引质量,就必须结合语义分析法;(4)单汉字标引法避开了分词障碍,易于实现,也不存在词典构造问题,但很难用它来处理文本中隐含的主题概念,而且会产生虚假组配现象;(5)句法语义分析标引法和人工智能标引法是汉语自动标引技术发展的必然趋势,标引质量高,但现在在这方面的技术还不很成熟,都还处于试验阶段。目前,全文数据库常用的标引技术有词典切分标引法,单汉字标引法和一些特殊方法(55)。王兰成等研究的基于中国档案主题词表的自动标引方法,将切分关键词和标引主题词融为一体,合理地构造了词典。他们认为,词典切分标引法比较容易实现对同义词、近义词等的控制,查全率与查准率相对较高。这种标引方法先要建立切分词典,然后以该词典为依据将文本字串与词典条目逐一比较,匹配成功则将该字串作为索引项,其实现过程是:
(1)利用非用词表排除输入的文献题目中的非用词,并将剩下的短语记录在短语文件中。
(2)利用机读主题词表对剩下的短语逐一比较,抽出主题词并将其所出位置、范畴号和词族信息记录在抽词文件中。
(3)利用汉语的局部语法特征和一些主题判断规则对上述的信息进行加工。这些规则是由程序实现的,主要有低权值主题词排除规则、单字主题词选择规则和通用主题词选择规则等。他们研究了基于中国档案主题词表的自动标引控制问题,取得了初步成效,在系统的研究过程中解决了一些关键技术和结构问题,为我国研究基于汉语主题词表的自动标引提供了理论和技术借鉴。
汉语自动标引一般都要利用分词技术,目前,由于在分词规范、分词算法、歧义控制等方面还存在一些难以解决的问题,所以汉语分词技术还没有实用化。避免汉语分词中的技术特点,转向基于多词表自动标引抽词研究是当前中文信息自动主题与分类标引可以采用的又一种策略,查贵庭、侯汉清以新华社新闻稿自动标引的实验也证明这是最为可行的方法(56)。他们通过对现有的汉语分词和自动标引研究情况调查后,发现自动标引系统中所涉及的“分词”实际上是抽取代表主题概念的关键词,将分词技术的研究转向抽词技术研究,可利用各种词表来解决自动标引系统中的技术难点。
抽词词表不仅是自动标引系统中不可缺少的基础条件,而且还对抽词质量有很大影响。在新华社新闻稿自动标引实验系统中,查贵庭、侯汉清所构建的词表有:停用词表、特例词表、同义词表、关键词表、人名、机构名和地名词表、主题词表、自由词表和分类主题词表。确定的抽词顺序依次为:特例词表处理、停用词表切分、地名抽词、关键词抽词(包括人名、机构名抽词)以及关键词筛选和关键词增补。该系统具有数据导入、抽词处理、主题标引和自由标引、分类标引、增补关键词和各类词表的维护功能。其中抽词处理还包括,特例词表标记处理、停用词过滤、关键词抽取、地名抽取以及关键词和自由词增补等。
通过自动标引实验表明,该系统运行效率、抽词标引准确性和人机标引相符性等都取得了令人鼓舞的效果。
4.3 网络信息资源的自动标引
网络信息资源的自动标引是信息自动处理的热门课题。网络信息浩如烟海,涵盖各学科领域,且种类繁多,但由于信息来源分散、无序、无统一管理机构,变化、更迭、新生、消亡等都时有发生,难以控制,再加上组织管理手段不够科学、规范,故网络信息并非人们想象的那样唾手可得。因此,如何将网络信息进行有效组织和管理,为普通用户提供简洁方便的检索方法是目前研究开发的重点,而标引则是重中之重。
周晓红根据网络信息的特点,提出了关键词标引和全文标引相结合的混合标引方法。她认为,全文标引的特点是查全率高而查准率较低,而关键词标引查准率高查全率往往比较低,因而简单采用全文标引或关键词标引方式,都不能很好地满足要求,必须采用全文标引和关键词标引相结合的方式才能较好地实现网络信息检索系统的功能。(57)为此,她提出了网络信息检索系统中信息自动标引算法的选择和实现方法,并认为这是最基础也是最关键部分。
长期以来关于自动标引的研究和应用基本上停留再基于关键词的标引。一般说来,关键词标引的检索效果总难令人满意,除了“返回信息太多”这个给人直观感觉到的问题外,还有两个不很直观的深层次问题(58):一是“忠实表达”问题。很多情况下,用户很难简单地用关键词或关键词串来忠实表达他所真正需要的内容,表达困难导致检索困难。另一个是“表达差异”问题,人类的自然语言中,随着时间、地域或领域的改变,同一概念可以用不同的语言形式来表达。因此,对同一概念的检索,不同的用户可能使用不同的关键词来查询,如“电子计算机”和“电脑”。
那么能否在关键词标引的基础上扬长避短实现主题标引呢?吴春玉认为,现代信息技术的发展和汉语词典切分方法的成功应用,完全可以在中文全文检索系统中实现主题标引。(59)她提出的具体思路是:利用汉语自动分词的研究成果,采用词典分词法将文献进行切分,通过词加权或词频统计法对切分后的词进行排序确定关键词,利用主题词表将关键词转化、合并、去重、重新排序后确定系统正式使用的主题词,并追加文献代号送入系统主题词字段中。在实现过程中,为了继续发扬关键词标引能及时反映新出现的专业术语,及时更新词表的优势,把原文献给出的关键词一并加入到切分后的词汇集中,进行合并、去重、加权、排序后确定为关键词,同时采用主题词表中的用代关系,将同义词合并,转化为规范词后排序的方法,这样就可以避免关键词标引过程中出现的一词多义、多义一词,实现真正意义上的自动主题标引。
看来,仅仅采用机械的关键词匹配来进行信息检索很难提高检索效率,把信息检索从目前基于关键词层面提高到基于知识(或概念)层面,是解决问题的根本和关键。因此,“今后自动标引的研究应从关键词标引全面转向主题词标引的研究和实践中”(60)。从目前国内研究的现状来看,阻碍全文自动标引接近使用的最大障碍是主题词典的建设,为此,韩客松、王永成介绍了一种用层次概念词典改进主题标引质量的新方法,提出了用三种方法产生主题概念进行全文标引的概念标引(61)。主题概念标引的好处是对文章主题的包容能力较强,能克服主题词的不连贯性,而导致检索者很难从主题词中较准确地揣摩出文章主题的缺陷。
很显然,为了正确进行主题概念标引,把信息检索从目前基于关键词层面提高到基于知识(概念)层面,一个最重要的也是最困难的问题是建设一部好的层次概念词典,韩客松、王永成提出的方法有一定的理论和实用价值。
5 主题检索语言与其他检索语言的融合研究
在信息检索系统中,单独采用主题语言组织信息很难满足不同用户的检索需求。主题语言所遵循的严格的词汇控制方法和复杂的句法控制规则限制了它的应用,因为使用者必须受过专门的训练。随着网络信息资源的迅猛增长,各种书目控制系统都向着易懂易用的方向转变,这就要求主题语言必须适应网络环境的要求:结构上应简单明了,容易维护;能提供最佳的查询点或查询途径;同时应该做到在不同的知识发掘和查找环境中能灵活的跨学科的互操作(62)。而实现主题语言与其他检索语言的融合,进行优势互补,既可满足不同用户的检索需求,又可提高检索效率。
一般认为,信息组织方法融合的形式有三种:检索语言的兼容、分类语言和主题语言一体化和受控语言与自然语言的结合。目前,讨论较多的是检索语言的兼容和受控语言与自然语言的结合。
5.1 检索语言的兼容研究
早在20世纪60年代就有关于检索语言兼容问题的研究文献出现。1964年,检索语言兼容性问题被提议为第二届分类研究国际研讨会的讨论主题,40多年来,人们探讨了检索语言兼容的多种方法,如宏观叙词表、微观叙词表、分面叙词表、参照语言和元叙词表等(63)。随着网络的迅速发展,以及大量电子文献数据库和搜索引擎的出现,检索语言的兼容研究有了新的进展:如国外的Multilingual Access to Subjects(MACS)(64)和CARMEN(65)以及国内山西省图书馆的“计算机文献标引对照系统”等项目,开始研究检索语言之间的人工或自动语义匹配问题(66)。近年来,国外投入大量的人力物力研究检索语言概念兼容的方法,提出了“交叉转换”方法,基于统计的相似度度量方法和人工智能算法等。其中,一些基于统计的相似度度量方法和人工智能算法,已经用于部分项目创建不同索引语言概念之间的兼容转换关系。例如,CARMEN和ViBsoz应用条件概率建立了两种叙词表的概念双向转换关系,Vizine-Goetz用对数相似度系数建立了LCSH标题和DDC分类号之间的匹配关系。国内张雪英、侯汉清等人提出了实现检索语言兼容的方法和设想。
张雪英提出了RST模型(Rough set based transfer model)(67)。该模型是一种基于统计的相似度度量方法,它基本克服了传统方法的主要弊端,能够实现索引语言之间的自动概念兼容转换。RST模型根据粗糙集和索引语言的一些基本理论,能够明确定义概念之间的语义关系和相似程度。她还提出了一系列概念转换筛选规则(一对一转换、一对多转换、多对多转换),从而大大缩减了该模型在实际应用中的计算复杂度和计算量,指导人们筛选出最正确的概念转换关系。
为提高中文文献信息检索便捷性,实现信息资源共享,侯汉清提出了以《中国分类主题词表》为核心建立检索语言兼容体系的设想。侯汉清认为(68),这个兼容体系不是新编一部大型的宏词表,也不是新编一部以词汇协调代码为基础的中介词典,而是建立一部可以不断扩充的集成词表。其特点可概括为:①以《中国分类主题词表》为核心,实现与各种分类语言、主题语言及自然语言三者之间的兼容;②覆盖各个学科、覆盖国内各种分类法、叙词表;③基本不对原词表进行加工,主要通过发挥计算机联机显示、统计及转换功能,实现兼容互换。借助《中国分类主题词表》的特殊地位和巨大影响,可以为联网环境中检索语言实现兼容互换创造最有利的条件和环境。
该兼容体系由以下几个部分组成:
(1)《中图法》与其系列版本之间的兼容;
(2)《汉表》与专业叙词表之间的兼容;
(3)《中图法》与国内分类法之间的兼容;
(4)国外著名分类法(DDC、LCC、UDC等)及叙词表、标题表与《中图法》或《汉表》之间的兼容;
(5)《汉表》与自然语言的兼容。
实现这个兼容系统,用户可以摆脱检索语言的障碍,轻松实现跨数据库的有效检索。
5.2 受控语言与自然语言结合研究
在计算机检索技术出现之前,信息检索以受控语言为主,分类语言和主题语言是最常用的语言。进入网络时代自然语言在信息检索中占着主要地位,各种搜索引擎、数据库索引几乎都提供自然语言检索,并形成了研究的热潮,甚至有人认为自然语言将取代受控语言在信息检索中的地位和作用,人工语言将走向消亡(69),信息检索将是“自然语言时代”(70)。
自然语言用于信息检索固然有很多优点,从某些性能上看,它比传统的受控语言更能适应网络环境的需要,在网络环境下能发挥出良好的性能(71):①自然语言符合客观需要,可以不受限制地随时输入新词,因而能跟上学科发展,加速机检数据库的建设;②易用性好,检索方便,不需要培训,用户掌握快;③标引简便快捷,易于实现自动化;④标引一致性好,一般在较小范围内采用“现成词”;⑤专指度高,可具体到文摘、索引或文献正文中出现的任何一个有实际意义的语词。所以,网络信息检索工具采用自然语言检索的必要性是不容置疑的(72)。
在信息检索的实践中,自然语言的检索效率和易用性也受到质疑:由于表达概念过分自由、语义无关联;为了得到较高的结果返回率,用户在检索过程中需要放弃某些质量要求,由此造成的检索结果信息冗余达到不可容忍的程度。实践证明,网络信息检索不能惟一地只用自然语言(73),人工控制手段决不能被彻底抛弃。
张琪玉先生认为,信息检索发展的大趋势,是情报检索语言的自然语言化和自然语言的情报检索语言化,是两者的初级结合到完全融合的过程。M.R.米达马尔做过一项研究发现,自然语言与受控语言结合使用可提高检索效率5%(74)。
蔡庆芳在分别分析了受控语言和自然语言的各自性能后认为,自然语言与受控语言具有天然的优势互补性,两种方式的结合可达到更好的检索效果(75)。她认为,编制后控词表、入口词表、混合词表、构筑概念空间模型,运用数码链接关键词技术和词表相似度识别转换技术等,是实现受控语言与自然语言结合的行之有效方法,并分别阐述了各种方法的特点。
事实上,有关受控语言与自然语言结合的研究,图书情报界的学者们历来十分重视,除蔡庆芳归纳的上述几种方法外,最近,张俊提出了一种主题词与关键词结合的词表编制方法(76),旨在将主题词表和关键词表两种最常用的检索语言结合起来,嫁接优化而产生一种更适合网络信息处理的工具。林青提出了建立“关键词—叙词法链接模型”(77),其链接模型结构并不复杂,主要在两者之间建立一个转换链接系统。利用这个系统,用户查检信息资源时,输入相应的关键词,该关键词通过链接的非控词系统转换成规范叙词,而后检索得出所需信息资源。在这个过程中,关键词与检索结果是用户界面,非控词系统与词表则是隐形系统。当然,用户也可直接输入规范叙词检索得出所需信息资源。建立“关键词—叙词法链接模型”旨在增大检索入口,精确检索结果,既可弥补关键词法的不足,又能切实发挥叙词法的效用。林青认为,它不但可以在各种数据库中应用,也可在各种网络搜索引擎中应用,其应用前景十分广泛。
5.3 两种有代表性的一体化语言
UMLS和张琪玉先生提出的分类语言、主题语言和自然语言一体化检索系统,是当前受控语言与自然语言结合的典型代表,也是情报检索语言未来发展的必然趋势。
5.3.1 美国一体化医学语言系统(UMLS)
UMLS是由美国国家医学图书馆自1986年开始研制的一项长期计划,其目的在于建立一个计算机化的可持续发展的生物医学检索语言集成系统和机读情报资源指南系统(78)。这个系统将不同类型的情报语言汇集成一个统一体,它与一般一体化语言的最大区别,也是它最突出的特点在于:高度专业化、全方位一体化和情报检索语言系统化(79)。
UMLS是一个动态系统,它的知识源起初由3个部分(超级叙词表、语义网和情报源图谱)组成,后新开发了一个“专家词典”其知识源由4个部分组成:超级叙词表(Metathesaurus)、语义网络(Semantic Network)、专家词典(SPECIALIST Lexicon)和情报源图谱(Information Sources Map,ISM)(80)。而2005年版的UMLS的基本构造进行了比较大的调整,即由原来的4个知识源改为3个知识源:超级叙词表、语义网络和专家词典。另外还包含两个工具:即知识来源服务器(Knowledge Sources Server)和MetamorphoSys.
(1)超级叙词表(Metathesaurus)。
第14版的超级叙词表集成了十多个语种的100多种来自病历、管理、卫生数据库,书目和全文数据库和专家系统中的生物医学受控词表和分类表,共收录了100多万个概念和500多万个概念名称(81)。
超级叙词表保留了来源词表中的所有概念名称、含义、等级关系、属性和词间关系,不仅为每个概念添加了相应的基本信息,而且还为来自不同来源词表的术语创建了新的关系链接,将来自不同来源词表的表达同一概念的多个概念名称联系起来。除了保留有来源词表中的标识符外,超级叙词表还为每个概念名称及其所表达的概念分配了惟一的并且是永久的标识符。超级叙词表采用四级结构模式(概念、术语、词串和原子)、四种标识符(CUI概念标识符、LUI术语标识符、SUI词串标识符和AUI原子标识符)来显示词汇结构,将一个概念的多种不同术语连同多个变异词串有序地组织在一起。
(2)语义网络(Semantic Network)。
语义网为超级叙词表中的所有概念提供了语义类型、语义关系和语义结构信息。超级叙词表中每个概念被至少制定了一种语义类型,并且是最专指的语义类型,语义网络的间隔水平(granularity)是变化的,它是解释概念含义的重要线索。第14版包括135种语义类型和语义关系。UMLS语义网络的范围非常广泛,可以实现对多领域的大量术语进行类分。
(3)专家词典(SPECIALIST Lexicon)。
专家词典可以为美国国立医学图书馆自然语言处理专家系统(SPECIALIST Natural Language Processing System)提供必要的词典信息,是一个包含众多生物医学词汇的英语词典,覆盖所有的常见英语词汇和生物学词汇。第14版的专家词典约有183 000条词汇记录,292 000多个词。词典条目既可以是单个词形式,也可以是复合词形式。专家词典包括一组词典程序,它们可以确定英语词汇的范围以及识别生物医学术语和文本词的词形变异,还包括三个索引,超级叙词表中所有的词串的单个词索引、标准词索引、标准词串索引。
(4)其他工具。
①知识来源服务器(Knowledge Sources Server)。UMLS知识来源服务器(UMLSKS)是一个计算机应用程序,它可以为UMLS的知识来源和其他利用UMLS开发的知识来源提供因特网访问。其目的是提高用户尤其是系统开发人员对UMLS数据的可获得性。该系统的系统结构可以使远程用户(个人或计算机)向美国国立医学图书馆(NLM)的服务器发出提问。
②MetamorphoSys。MetamorphoSys是一个安装和定制程序,它包含在UMLS的每个版本中。它可以安装UMLS的一个或多个知识来源。一旦选定了UMLS的超级叙词表,MetamorphoSys就可以帮助用户实现超级叙词表的子集。
目前,国外已将UMLS应用于创建病案系统、课程分析、Web搜索技术、自然语言处理和智能化情报检索等(82)。
5.3.2 分类语言、主题语言与自然语言一体化检索系统
实质上,张琪玉先生提出的分类语言、主题语言与自然语言一体化系统是在类名(或分类号)、主题词、关键词之间建立对应关系,以便互相转换、互相控制(83)。
他将这种检索系统的作用归纳为以下几点:
(1)通过关键词→主题词的对应,将检索提问所使用的关键词转换成主题词,再转换成多个同义关键词扩展检索式进行检索,可在不影响检准率的情况下提高检全率。
(2)通过关键词→(主题词)→类名的对应转换。①作为分类体系的自然语言接口,通过关键词进入分类系统,可使分类检索系统变得容易;②在网络信息检索工具中的关键词检索中,可转向分类目录,把检索限定在类目范围内进行,以排除无用信息;③作为分类体系的自然语言接口,也可供分类标引人员使用,提高标引质量;④反映关键词→(主题词)→分类类目对应关系的对应表,可为在自动抽词基础上的半自动分类标引工作。
(3)通过分类目录→主题词对应,可选择合适的主题词进行检索。实现三大检索功能一体化,用户不论从哪个角度都能比较容易检索到所需信息。张琪玉先生还设计了三种语言一体化的几种模式:以体系分类法作为标引用语言的一体化模式;以叙词法作为标引用语言的一体化模式;以关键词(自然语言)作为标引用语言的一体化模式和以使用关键词抽词词典自动抽取关键词作为标引语言的一体化模式。他认为,三种语言一体化系统以自然语言自由标引模式较佳。
在目前的信息检索系统中,大多数检索系统都具有三种检索功能,但它们没有融为一体,而是相互并立的。实现三者的有机结合,是网络环境下信息用户的迫切需求,也是信息检索用语言发展的必然趋势。
6 结 语
计算机技术的应用,尤其是网络的普及和发展,改变了主题语言的生存和发展环境,作为知识组织的一种工具,主题语言的组织对象、组织方式、技术手段和服务用户等也发生了根本性变化,从传统的对文献特征的描述,深入到信息单元、知识单元,由传统手工操作到自动化、智能化技术的处理,由服务于专门用户到普通大众用户等。虽然,作为检索语言,它在网络环境下所要实现的基本目的和功能在本质上是和非网络环境一致的(84),但是,面对新的信息技术和新的信息环境,主题语言的局限性是显而易见的。因此,重构主题检索语言的理论框架,加强主题检索语言在实践方面的变革与创新,以及网络环境下主题语言的应用,汉语自动标引和主题语言与其他检索语言的融合,尤其是与自然语言的接口的研究等,仍然是当前研究的重要课题。
【参考文献】
1.侯汉清主编.索引技术和索引标准.北京:北京图书馆出版社,1997:7
2.侯汉清,马张华.主题法导论.北京:北京大学出版社,1991:5,95
3.侯汉清.中国美国英国主题标引方式比较.北京图书馆通讯,1985(4)
4.曹树金,罗春荣.信息组织的分类法与主题法.北京:北京图书馆出版社,2000:254
5.张琪玉.情报语言学基础.武汉:武汉大学出版社,1997:138,147
6.戴维民.20世纪图书馆学情报学.北京:北京图书馆出版社,2002:117
7.曾蕾.叙词语言是当代情报检索语言的主流.情报科学,1986(4)
8.侯汉清.国外叙词表的概况及发展趋向.情报学报,1989(5): 378~386
9.侯汉清.分类主题一体化词表的进展.北京图书馆通讯,1988(1):39~43
10.戴维民.中国情报检索语言50年研究论纲.中国图书馆学报,2000(3):62~69
11.曾蕾.网络环境下的知识组织系统——编者的话.现代图书情报技术,2004(1):2~3
12.赖茂生.知识组织理论与技术.北京:北京大学信息管理学系,1994:3
13.Linda Hill,在数字图书馆结构中融入知识组织系统.现代图书情报技术,2004(1):4~8
14.Eduward T.O'Neill,麦麟屏.FAST:主题术语的分面式应用——以《国会图书馆主题词表(LCSH)》为基础的简单化词汇.现代图书情报技术,2004(1):9~15
15.Given,L.M.&Olson,H.A.Knowledge organization in research: a conceptual model for organizing data.Library&Information Science Research,2003(25):156-176
16.王知津,张国华.知识组织概念模型的运用——以组织研究数据为例.图书情报工作,2004(11):34~38,45
17.宋炜,张铭.语义网简明教程.北京:高等教育出版社,2004:2
18.戴维民主编.信息组织.北京:高等教育出版社,2004:294
19.Tim Berners.Lee,Hendler James,Lasila Ora.The Semantic Web. Scientific American,May 2001
20.秦健.实用分类系统与语义网:发展现状和研究课题.现代图书情报技术,2004(1):16~23
21.赵焕洲,唐爱民.对两种知识组织系统——叙词表与Ontology的比较研究.情报理论与实践,2005(5):469~471
22.Gillber,T.R.A.Translation Approach to Porlable Ontology Specitications.Knowledge Acquisition,1993(5)
23.牟冬梅,崔艳玲.MeSH.本体论在医学知识组织中的作用.情报杂志,2005(7):120~122
24.李景,钱平.叙词表与本体的区别与联系.中国图书馆学报,2004(1):36~38
25.胡冰.网络信息资源组织方法综述.情报科学,2003(4):434~437
26.康桂英.分类法与主题法在网络信息资源组织与揭示中的应用.情报科学,1999(3):248~287,291
27.刘晓敏.论网络信息的有效组织.情报科学,2000(2):102~104
28.李玉安.试论关键词语言在文献检索语言中的地位和发展趋势.情报杂志,1999(6):66~67
29.焦玉英主编.信息检索进展.北京:科学出版社,2003:96
30.张琪玉.网络信息检索工具增强关键词检索功能的措施.图书馆杂志,2001(1):7~10
31.张燕飞.网络信息组织的主题语言.武汉:武汉大学出版社,2005:260
32.Controlled vocabulavies,thesauri and classification systems ovaiilable in the www.DC subject.http://www.lub.la.se/metadata/subject. help.html.
33.邱君瑞.受控词表网络应用现状分析.情报科学,2001(11): 1230~1232
34.张俊.主题词与关键词相结合的词表在网络信息处理中的应用.图书情报工作,2004(5):32~37
35.熊回香.全文检索系统中的汉语自动分词及其歧义处理.中国图书馆学报,2005(5):54~57
36.张琪玉主编.情报检索语言实用教程.武汉:武汉大学出版社,2004:236
37.苏武华.汉语自助分词和自动标引方法研究.农业图书情报学刊,2004(7):103~105
38.王兰成等.基于中国档案主题词表的自动标引控制研究.情报学报,2002(2):177~180
39.查贵庭,侯汉清.基于多词表的自动标引技术研究——新华社新闻稿自动标引的实验.情报学报,2002(3):273~277
40.周晓红.网络信息检索系统中信息自动标引方法的设计与实现.情报杂志,2005(12):41~43
41.首都信息发展有限公司北京网络多媒体实验室.智能搜索引擎为电子商务导航.互联网世界,2000(10):58~60
42.吴春玉.中文全文检索系统中实现主题词标引思路.情报杂志,2005(1):115~116,119
43.韩客松,王永成.中文全文标引的主题标引和主题概念标引方法.情报学报,2001(2):212~216
44.张雪英.基于并行文献数据库的索引语言概念兼容转换.情报学报,2005(2):161~167
45.Doerr,M.Sematic problems of thesaurus mapping.Journal of Digital Information,2001,1(8)
46.Krause,J.&Marx,J.Vocabulary switching and automatic metadata extraction or how to get useful information from a digital library.In: proceedings of the First DELOS Network of Excellence Workshop,2000,133-134
47.侯汉清.建立以《中国分类主题词表》为核心的检索语言兼容体系.http://www.Lib.pku.edu.cn/98conf/paper/(访问日期: 2006/03/27)
48.王群,敬卿.论自然语言的优势与人工语言的消亡.大学图书馆学报,2004(2):62~65,52
49.何灵巧,陆宗诚.情报检索语言的发展方向问题.图书情报知识,2005(1):68~72
50.寇均锋.论情报检索语言的自然语言化发展趋势.中国图书馆学报,1999(3):28~31
51.张琪玉.网络信息检索用语言的发展趋势.图书馆杂志,2001(3):5~7,22
52.Mudda mail M.R.Natural Language Versus Controlled Vocabulary in Information Retrieval:A Case Study in Soil Mechanics.Journal of the American Society for Information Science,1998:49(10)
53.蔡庆芳.论受控语言与自然语言的优化控制.情报杂志,2004(12):104~105
54.蔡庆芳.受控语言上自然语言一体化研究[同等学历人员申请硕士学位论文].武汉:武汉大学信息管理学院,2003
55.林青.关键词法—叙词法链接模型——自然语言与人工情报检索语言的结合.情报探索,2003(2):1~3
56.胡德华,方平.一体化医学语言系统(UMLS)及其对我国情报检索语言的启示.情报学报,2000(2):158~163
57.http://www.nlm.nih.gov/pubs/factsheets/umlsmeta.hrml.(访问日期:2005/05/18)
58.方平.Web网上IGM的工作程式与智能检索.高校图书馆工作,1997(2):27~31
59.张琪玉.分类语言、主题语言与自然语言一体化检索系统与《中国财经报刊数据库》的实践.现代图书情报技术,2002(1):66~68
60.戴粟芳.从Ei叙词表的变化看情报检索语言的发展趋势.情报杂志,2002(12):62~63

【作者简介】张燕飞,副教授,有著作出版,发表多篇论文。
【注释】
(1)侯汉清主编.索引技术和索引标准.北京:北京图书馆出版社,1997:7
(2)侯汉清,马张华.主题法导论.北京:北京大学出版社,1991:5,95
(3)侯汉清.中国美国英国主题标引方式比较.北京图书馆通讯,1985(4)
(4)曹树金,罗春荣.信息组织的分类法与主题法.北京:北京图书馆出版社,2000:254
(5)张琪玉.情报语言学基础.武汉:武汉大学出版社,1997:138,147
(6)侯汉清,马张华.主题法导论.北京:北京大学出版社,1991:5,95
(7)张琪玉.情报语言学基础.武汉:武汉大学出版社,1997:138,147
(8)戴维民.20世纪图书馆学情报学.北京:北京图书馆出版社,2002: 117
(9)曾蕾.叙词语言是当代情报检索语言的主流.情报科学,1986(4)
(10)侯汉清.国外叙词表的概况及发展趋向.情报学报,1989(5):378~386
(11)侯汉清.分类主题一体化词表的进展.北京图书馆通讯,1988(1): 39~43
(12)戴维民.20世纪图书馆学情报学.北京:北京图书馆出版社,2002: 117
(13)戴维民.中国情报检索语言50年研究论纲.中国图书馆学报,2000(3):62~69
(14)张琪玉.情报语言学基础.武汉:武汉大学出版社,1997:138,147
(15)曾蕾.网络环境下的知识组织系统——编者的话.现代图书情报技术,2004(1):2~3
(16)赖茂生.知识组织理论与技术.北京:北京大学信息管理学系,1994:3
(17)Linda Hill,在数字图书馆结构中融入知识组织系统.现代图书情报技术,2004(1):4~8
(18)曾蕾.网络环境下的知识组织系统——编者的话.现代图书情报技术,2004(1):2~3
(19)Linda Hill.在数字图书馆结构中融入知识组织系统.现代图书情报技术,2004(1):4~8
(20)Edward T.O'Neill,麦麟屏.FAST:主题术语的分面式应用——以《国会图书馆主题词表(LCSH)》为基础的简单化词汇.现代图书情报技术,2004(1):9~15
(21)Edward T.O'Neill,麦麟屏.FAST:主题术语的分面式应用——以《国会图书馆主题词表(LCSH)》为基础的简单化词汇.现代图书情报技术,2004(1):9~15
(22)Given,L.M.&Olson,H.A.Knowledge organization in research:a conceptual model for organizing data.Library&Information Science Research,2003(25):156-176
(23)Given,L.M.&Olson,H.A.Knowledge organization in research:a conceptual model for organizing data.Library&Information Science Research,2003(25):156-176
(24)王知津,张国华.知识组织概念模型的运用——以组织研究数据为例.图书情报工作,2004(11):34~38,45
(25)宋炜,张铭.语义网简明教程.北京:高等教育出版社,2004:2
(26)戴维民主编.信息组织.北京:高等教育出版社,2004:294
(27)Tim Berners.Lee,Hendler James,Lasila Ora.The semantic web. Scientific American,May 2001
(28)秦健.实用分类系统与语义网:发展现状和研究课题.现代图书情报技术,2004(1):16~23
(29)秦健.实用分类系统与语义网:发展现状和研究课题.现代图书情报技术,2004(1):16~23
(30)赵焕洲,唐爱民.对两种知识组织系统——叙词表与Ontology的比较研究.情报理论与实践,2005(5):469~471
(31)Gillber,T.R.A.Translation Approach to Porlable Ontology Specitications.Knowledge Acquisition,1993(5)
(32)赵焕洲,唐爱民.对两种知识组织系统——叙词表与Ontology的比较研究.情报理论与实践,2005(5):469~471
(33)赵焕洲,唐爱民.对两种知识组织系统——叙词表与Ontology的比较研究.情报理论与实践,2005(5):469~471
(34)牟冬梅,崔艳玲.MeSH.本体论在医学知识组织中的作用.情报杂志,2005(7):120~122
(35)李景,钱平.叙词表与本体的区别与联系.中国图书馆学报,2004(1):36~38
(36)赵焕洲,唐爱民.对两种知识组织系统——叙词表与Ontology的比较研究.情报理论与实践,2005(5):469~471
(37)胡冰.网络信息资源组织方法综述.情报科学,2003(4):434~437
(38)康桂英.分类法与主题法在网络信息资源组织与揭示中的应用.情报科学,1999(3):248~287,291
(39)刘晓敏.论网络信息的有效组织.情报科学,2000(2):102~104
(40)李玉安.试论关键词语言在文献检索语言中的地位和发展趋势.情报杂志,1999(6):66~67
(41)李玉安.试论关键词语言在文献检索语言中的地位和发展趋势.情报杂志,1999(6):66~67
(42)焦玉英主编.信息检索进展.北京:科学出版社,2003:96
(43)张琪玉.网络信息检索工具增强关键词检索功能的措施.图书馆杂志,2001(1):7~10
(44)张燕飞.网络信息组织的主题语言.武汉:武汉大学出版社,2005: 260
(45)张琪玉.网络信息检索工具增强关键词检索功能的措施.图书馆杂志,2001(1):7~10
(46)Controlled vocabulavies,thesauri and classification systems ovaiilable in the www.DCsubject.http://www.lub.la.se/metadata/subject.help.html
(47)邱君瑞.受控词表网络应用现状分析.情报科学,2001(11):1230~1232
(48)张俊.主题词与关键词相结合的词表在网络信息处理中的应用.图书情报工作,2004(5):32~37
(49)熊回香.全文检索系统中的汉语自动分词及其歧义处理.中国图书馆学报,2005(5):54~57
(50)张琪玉主编.情报检索语言实用教程.武汉:武汉大学出版社,2004:236
(51)苏武华.汉语自助分词和自动标引方法研究.农业图书情报学刊,2004(7):103~105
(52)苏武华.汉语自助分词和自动标引方法研究.农业图书情报学刊,2004(7):103~105
(53)熊回香.全文检索系统中的汉语自动分词及其歧义处理.中国图书馆学报,2005(5):54~57
(54)苏武华.汉语自助分词和自动标引方法研究.农业图书情报学刊,2004(7):103~105
(55)王兰成等.基于中国档案主题词表的自动标引控制研究.情报学报,2002(2):177~180
(56)查贵庭,侯汉清.基于多词表的自动标引技术研究——新华社新闻稿自动标引的实验.情报学报,2002(3):273~277
(57)周晓红.网络信息检索系统中信息自动标引方法的设计与实现.情报杂志,2005(12):41~43
(58)首都信息发展有限公司北京网络多媒体实验室.智能搜索引擎为电子商务导航.互联网世界,2000(10):58~60
(59)吴春玉.中文全文检索系统中实现主题词标引思路.情报杂志,2005(1):115~116,119
(60)吴春玉.中文全文检索系统中实现主题词标引思路.情报杂志,2005(1):115~116,119
(61)韩客松,王永成.中文全文标引的主题标引和主题概念标引方法.情报学报,2001(2):212~216
(62)Linda Hill.在数字图书馆结构中融入知识组织系统.现代图书情报技术,2004(1):4~8
(63)张雪英.基于并行文献数据库的索引语言概念兼容转换.情报学报,2005(2):161~167
(64)Doerr,M..Sematic problems of thesaurus mapping.Journal of Digital Information,2001,1(8)
(65)Krause,J.&Marx,J..Vocabulary switching and automatic metadata extraction or how to get useful information from a digital library.In:proceedings of the First DELOS Network of Excellence Workshop.2000.133-134
(66)张雪英.基于并行文献数据库的索引语言概念兼容转换.情报学报,2005(2):161~167
(67)张雪英.基于并行文献数据库的索引语言概念兼容转换.情报学报,2005(2):161~167
(68)侯汉清.建立以《中国分类主题词表》为核心的检索语言兼容体系. http://www.Lib.pku.edu.cn/98conf/paper/(访问日期:2006/03/27)
(69)王群,敬卿.论自然语言的优势与人工语言的消亡.大学图书馆学报,2004(2):62~65,52
(70)何灵巧,陆宗诚.情报检索语言的发展方向问题.图书情报知识,2005(1):68~72
(71)寇均锋.论情报检索语言的自然语言化发展趋势.中国图书馆学报,1999(3):28~31
(72)张琪玉.网络信息检索用语言的发展趋势.图书馆杂志,2001(3): 5~7,22
(73)张琪玉.网络信息检索用语言的发展趋势.图书馆杂志,2001(3): 5~7,22
(74)Mudda mail M.R.Natural Language Versus Controlled Vocabulary in Information Retrieval:A Case Study in Soil Mechanics.Journal of the American Society for Information Science,1998:49(10)
(75)蔡庆芳.论受控语言与自然语言的优化控制.情报杂志,2004(12):104~105
(76)张俊.主题词与关键词相结合的词表在网络信息处理中的应用.图书情报工作,2004(5):32~37
(77)林青.关键词法—叙词法链接模型——自然语言与人工情报检索语言的结合.情报探索,2003(2):1~3
(78)胡德华,方平.一体化医学语言系统(UMLS)及其对我国情报检索语言的启示.情报学报,2000(2):158~163
(79)张燕飞.网络信息组织的主题语言.武汉:武汉大学出版社,2005: 260
(80)胡德华,方平.一体化医学语言系统(UMLS)及其对我国情报检索语言的启示.情报学报,2000(2):158~163
(81)http://www.nlm.nih.gov/pubs/factsheets/umlsmeta.hrml.(访问日期: 2005/05/18)
(82)方平.Web网上IGM的工作程式与智能检索.高校图书馆工作,1997(2):27~31
(83)张琪玉.分类语言、主题语言与自然语言一体化检索系统与《中国财经报刊数据库》的实践.现代图书情报技术,2002(1):66~68
(84)戴粟芳.从Ei叙词表的变化看情报检索语言的发展趋势.情报杂志,2002(12):62~63
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











