



近5年来主题检索语言的研究进展
张燕飞 刘元珺 孙珑琦
(武汉大学信息管理学院)
【摘 要】文章调查了近5年(2005—2009)主题检索语言研究的状况。从主题法的应用、网络叙词表、《中国分类主题词表》、自然语言检索、自动标引及本体语言等方面,论述了近5年来主题检索语言的研究进展。
【关键词】主题检索语言 研究进展
The Progress of Research on Subject Retrieval Language in the Past 5 Years
Zhang Yanfei Liu Yuanjun Sun Longqi
(School of Information Management,Wuhan University)
【Abstract】Looking back on the research situation in 2005-2009,the paper reviews the progress of research on subject retrieval language in termsof itsapplication,network thesaurus,ChineseClassified Thesaurus,natural language searching,automatic indexing and Ontology in the past5 years.
【Keywords】subject retrieval language research progress
在网络环境下,以语词作为标引和检索标识的主题检索语言,仍然是信息检索的主流,在信息组织和检索中发挥着重要作用。笔者对2005—2009年主题检索语言的研究状况,利用《中国期刊全文数据库》、《维普中文科技期刊数据库》,以“主题法”、“网络叙词表”、“自然语言检索”、“自动标引”、“中国分类主题词表”以及“本体”和ontology等为关键词,作了一次调查,发现随着计算机技术在信息组织和检索中的广泛应用,特别是网络信息技术和搜索引擎的蓬勃发展,人们对主题检索语言研究的重视程度非常高,研究范围十分广泛。
1 研究成果概述
本文拟通过期刊论文分析近5年来主题检索语言的研究走向。以国内影响较大、用户经常利用的《中国期刊全文数据库》和《维普中文科技期刊数据库》两个期刊数据库为索引依据,结合不同研究者在研究中使用的不同术语来限定检索范围,查得2005—2009年关于主题检索语言方面的研究论文387篇,各年份发表的论文数量如表1:
表1 近5年来主题语言方面的研究论文数量

从调查情况分析,近5年来关于主题检索语言的研究有这样几个特点:①主题语言的检索效率依然是研究的重点,无论是对受控语言的创新研究,还是对自然检索语言的优化研究,业内将提高检索效率视为根本目标;②本体语言的研究成为热点,所发表的研究论文数量多,研究范围也十分广泛;③检索语言之间的互操作性研究,不同类型、不同语言之间的兼容研究,寻找更佳的结合模式研究,是情报检索语言创新研究的主流;④自然语言检索和自动标引是目前研究的焦点,尤其是自动标引的研究,虽然难度较大,但是业内没有停止,一直在进行研究。
应该说,近几年主题检索语言方面研究的热点问题,还是相对集中的,主要涵盖如下几个方面:网络环境下主题法应用的理论与实践研究;网络叙词表的研究;关于《中国分类主题词表》的研究;自然语言检索效率的研究;自动标引研究以及关于本体语言的研究。各主题内容的研究论文数量分布如表2:
表2 近5年来主题语言各主题内容的研究论文数量
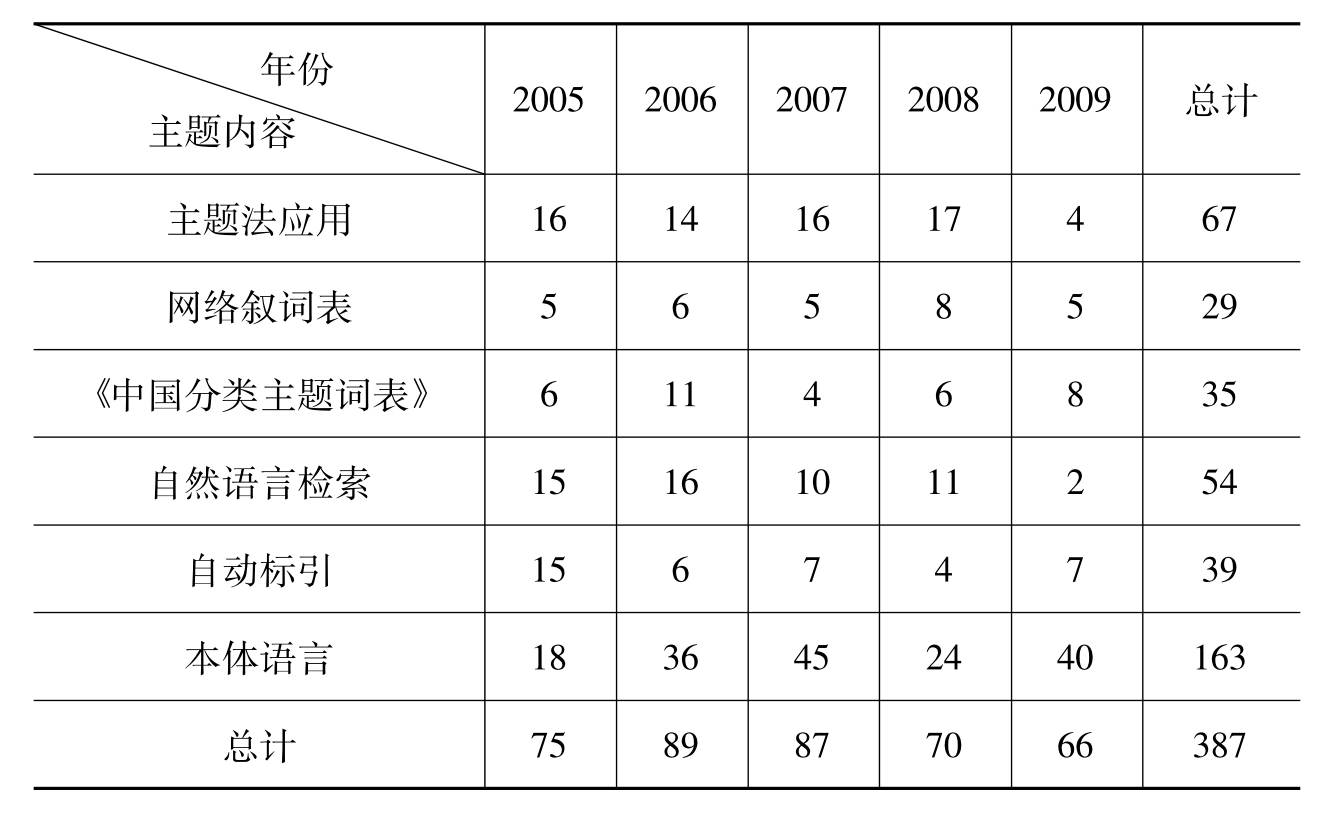
从表2来看,虽然各主题内容的研究论文数量分布不太均匀,像网络叙词表、《中国分类主题词表》分别只占7.49%、9.04%,而本体语言则达到42.12%。但是,总的发展还是基本平衡的,只是不同时间内人们的研究兴趣和重点有所不同而已。总起来看,近几年来,业内对主题检索语言方面的研究仍然呈升温态势,研究的人数众多,一些知名专家、学者领衔,众多专业人员积极投入,尤其是涌现出一支年轻的研究群体;主要研究成果得到认同,在某些研究问题上达成共识。
2 关于主题法应用的研究
自网络产生以来,有关主题法在网络信息组织与检索中的应用研究,一直是人们研究的重点问题。一方面,由于网络技术的迅猛发展,网络信息与知识不断膨胀,信息资源愈来愈丰富,信息量越来越大,并呈爆炸性的增长,因而改进信息组织工具,以应对海量信息的能力,改善信息检索质量,以满足用户的信息检索需求成为急需解决的问题;另一方面,网络技术的发展和搜索引擎兴起,使直观、简便、易用的自然语言重新“回归”,并表现出较强的适应能力。而纯自然语言在网络信息组织与检索中的局限性,使人们对源于自然语言的主题法在网络环境中的应用与发展,以及与新技术融合、创新,十分关注,成为研究的热点。
2.1 主题法应用于网络信息组织的方法
网络的兴起,为主题法的应用提供了崭新的平台。20世纪90年代,国内就对主题法在网络环境下的应用进行过广泛的探讨。在当时,由于网络信息是一种新的事物,网络信息组织是一个新的课题,人们只是从理论层面上分析主题法组织,揭示网络信息资源的优势,阐述网络环境下主题法可以实现的功能,未能深入揭示主题法应用于网络信息资源组织与检索的方式方法(1)。随着网络技术的发展与普及,图书情报界对于主题法应用的研究也逐渐深入,主题法应用于网络信息组织的优势也凸显出来。
邱桂梅认为(2),主题法是网络信息组织采用的主要方法。其主要表现为:关键词法在网络搜索引擎中的广泛应用;受控词表在网络信息检索系统中的应用;并且认为,主题法适应网络信息不同层次、不同需要的组织,并将网络信息组织归纳为一次信息组织和二次信息组织。由于主题法(主要是关键词法)具有适应网络信息资源的自动标引及快速准确反映信息的特点,所以在自由文本揭示、主页信息组织、超文本链接、主题树、指引库等不同层次的网络信息组织中可以发挥重要作用。
其实,受控的主题词表在网上也被广泛使用。这是因为经过人工规范化处理以后,主题法具有语词与概念一一对应的特点,排除了多义及词义含糊的现象,对同义词进行了有效控制,能显示概念之间的关系,具有较高的检全率。康艳等(3)用网络信息检索的大量实践,证明受控词表能够适应网络信息组织,他们列举了叙词表在元数据、网络数据库、主题网关以及数字图书馆中应用的实例。在国外,很多元数据项目都鼓励使用叙词表,像《国会图书馆标题表》(LCSH)的主题词和《医学标题表》(MeSH)的主题词就用于DC元数据。叙词表用于网络数据库就比较早。自叙词表产生以后,很快就被用于检索刊物和文献数据库索引的编制,像国外一些著名的文摘索引刊物,大多建有书目数据库和全文数据库,而多数书目数据库都采用了自编的叙词表。目前,国外一些著名数据库,如美国教育资源信息数据库、Pubmed数据库、英国国家数字档案库、STI数据库、UM I数据库等,都纷纷进入因特网,而叙词表在这些网络数据库的检索中发挥了重要的作用。
在主题网关中,叙词法能提供特定主题、特定事物的检索需求。刘竟、侯汉清在《情报检索语言与主题网关》一文中(4),以英国社会科学主题网关(SOSIG)为例,分析了主题网关利用叙词法的做法:SOSIG是根据不同的主题领域或学科使用不同的叙词表,而不是使用一种叙词表。例如,英国Essex大学开发的《人文科学与社会科学电子词表》(HASSET)、《政府、政治和人类学叙词表》(IBSS)以及《社会工作与福利叙词表》(CareData)等。认为叙词法应用于主题网关,编目时,为网络资源标引主题词,一方面可以使资源发现和描述更加统一;另一方面可以为用户选择检索词提供入口。检索时,即使用户键入的语词在叙词表中不是规范的叙词,或者叙词表中有多个叙词与之匹配,然而,系统会自动给出提示,并且能为用户提供相关语词的选项,显示出用户所键入语词的上位词、下位词和相关词,以便用户从中选择点击与其检索需求最相关的叙词。这样,叙词表就可以成为帮助用户更准确、更清晰地定义信息需求和实施扩检、缩检或改变检索范围的有效工具。
主题网关,国内也称为“学科信息门户”,是将特定学科领域的信息资源、工具和服务集成为一个整体,为用户提供一个方便的信息检索和服务入口。它是提供经过图书情报机构工作人员对信息选择和筛选后,按学科组织的、可检索和可浏览的因特网资源和资源目录的联机服务系统,其最具特色的部分是详细的元数据(或目录)记录数据库,这些记录对网上资源进行描述并提供指向资源的链接,指引用户获取所需信息。从所具有的功能来看,可以将主题网关视为对网络指南、资源导航、指示数据库的进一步发展。
主题网关的研究与开发始于20世纪90年代中期。近年来,伴随互联网信息技术和标准的发展,发端于图书馆领域的主题网关建设得以不断成熟与完善,已经成为网络信息资源组织的一种重要方式。
同SOSIG一样,由中国科学院承建的中国国家数字图书馆(CSDL)的物理数学、化学、生命科学、资源环境和图书馆学情报学5个主题网关,也依据不同学科应用了不同的分类法和主题法。其标引词都是取自题名、交替题名及资源描述和介绍语句的词或词组,即关键词;生命科学主题网关采用自创的“生命科学主题网关学科体系”、物理数学主题网关采用《国际物理分类法》和《数学主题分类表》、资源环境主题网关采用自创的《资源环境科学分类法》(RESC)、图书馆学情报学按照《中图法》分类。与SOSIG相比,我国的主题网关没有充分利用已有的分类法,尤其是主题法对网络信息资源的揭示与组织。所以,刘竟、侯汉清建议,国内主题网关应当充分利用我国自编的情报检索语言,如《中图法》、《中国分类主题词表》等来组织网络信息资源。当然,各个学科可以依据自身学科的特点自编叙词表,在主题网关中提供叙词表入口,从而提高主题网关的检索效果。
通观国内外主题网关,其信息组织方式有这样几个特点:
(1)学科性。针对特定学科或主题领域,按照一定的资源选择和评价标准,根据用户的信息需求,对具有一定学术价值的网络资源进行搜集、选择、描述和组织。国内外一些著名的主题网关,如美国加州大学的“图书馆员因特网索引”(Librarians'Index to the Internet,LII)、德国哥丁根Lower Saxony State and University Library开发的Geo-Guide、英国诺丁汉大学等开发的BIOME(生命与健康),以及中国科学院国家数字图书馆的环境资源科学信息门户等都具有很强的针对性。
(2)集成性。主题网关将专业领域各种有价值的网络信息资源集中到一个知识体系中,既收录机构网站、数据库等,又收录一些特有的网络信息资源类型,如学术论坛、新闻组、邮件列表等。
(3)规范化。主题网关建设有严格明确的规范,如规定信息资源收录范围、选择标准以及选择步骤;规定信息资源组织体系标准和信息资源描述标准。标准化是实现不同系统间网络信息资源交流的基础,实现数字信息资源整合的关键在于遵循标准化的规范体系。如果没有统一的数字信息资源建设标准和相应的规范,就不可能实现各分布式资源之间的互操作和信息的共享(5)。
在主题网关中,使用主题法等受控的情报检索语言揭示和组织网络信息资源,可以有效地控制信息的质量,为用户提供有价值的、高质量的信息。
2.2 主题法的互操作技术
伴随计算机技术应用和网络技术的普及,检索语言的互操作技术成为研究的热点,备受关注。这是因为,网络环境下人们获取信息的渠道主要是联机数据库和搜索引擎,特别是联机数据库,由于采用了不同的分类法、主题法揭示和组织信息资源,从而成为人们跨库、跨语种、跨领域检索的障碍。正如情报学家Lancaster所言(6),虽然受控词表有助于促进情报系统内部的一致性,但是却会降低情报系统之间的兼容性。侯汉清等认为(7),实现情报检索语言之间的互操作,就是要找到一种方法,使具有不同标识、不同结构、不同载体的分类表或主题词表的成分互相联系起来,用户只用一种检索语言或不用任何检索语言(直接使用自然语言)就可以实现联网环境下的跨库检索。
互操作,即兼容互换,是伴随情报检索语言的发展而提出来的。国外图书情报界一直比较重视检索语言互操作技术的研究,曾提出并实施过多种兼容互换的模式与方法,如词汇转换、中介词典、宏观词表与微观词表、集成词表、叙词词库、映射和翻译等。有些成果在实践中得以应用,并取得了较好的效果。英、美两国还将互操作技术纳入叙词表编制的国家标准。
国内对于检索语言互操作技术的研究起步虽然较晚,但近年来学者们一直在探讨这方面的问题,完成了一些检索语言互操作项目,为用户的信息检索带来了很大的方便。20世纪80—90年代,图书情报界的学者、专家在研究分类主题一体化理论的基础上,编制出版了多部分类主题一体化词表,其中影响较大的有:《教育分面叙词表》、《农业科学叙词表》、《中国分类主题词表》、《社会科学检索词表》、《航空航天医学主题词表》、《音像资料叙词表》等。20世纪后期,进行了基于计算机的检索语言互操作项目的研究,开始注意对不同分类法、主题法之间的兼容互换,利用计算机技术、自然语言处理技术、数学方法等来解决同义词识别、映射关系发现等问题的研究。1997年,张琪玉先生在《图书馆杂志》发表了《学科—事物概念组配型检索语言——关于情报检索语言的遐想与求索》一文,提出了一种情报检索的新模式,他将这种模式的本质属性归纳为5点(8):①学科聚类系统与事物聚类系统的结合;②先组式检索语言与后组式检索语言的结合、体系分类法与组配分类法的结合;③人工语言与自然语言的结合;④号码标识与语词标识的结合、系统序列与字顺序列的结合;⑤不变概念代码与可变概念体系的结合。其实现方式为“分面分析+概念代码+概念对应转换+数据库技术”。1998年,侯汉清先生提出了建立以《中国分类主题词表》为核心的检索语言兼容体系,实现各种分类语言、主题语言即自然语言之间的兼容的设想(9)。两位学者提出的情报检索语言互操作的思想,为我国图书情报界的集成词库、映射、翻译等互操作技术的研究奠定了重要基础。
进入21世纪,随着知识组织系统(KOS)的应运而生,国内外图书情报界展开了知识组织系统互操作的研究,实施了许多积极而有成效的研究计划,一些成果在实践中得以应用。在这期间,国内学者、专家也研究、编制了一批集成词库,如“中医药一体化语言系统”、“医学分类主题一体化系统建设”、“教育集成词库构建系统”、“汉语科技词汇系统”等。这些集成词库的共同点是将某一特定主题领域的若干词表(叙词表、分类表,有的还包括专业词典)融合在一起,在各源词表的基础上建立一个含全部词条及相关参照的母表。如“教育集成词库”就是一个以《中国分类主题词表》为核心的集成词库,它包括《中图法》与国内外分类法的互操作,《汉语主题词表》与专业叙词表的互操作,以及受控语言与自然语言的互操作。
关于主题法的互操作技术,国外许多机构在这方面做了有益的探索。李育嫦将国外主题法的互操作技术归纳为3种(10):①多语言标题表、多语言叙词表的互操作,与之相关的项目有:MACS、HEREN、AGROVOC、GRMET、Merimee、LMBER等。②叙词表与标题表之间的互操作,像OCLC的ERIC/LCSH项目,其重点是研究词表映射匹配,以及在此基础上实现LCSH与ERIC的互操作。该项目的具体实施是,首先将ERIC叙词表转换成MARC格式,然后与LCSH标题表进行匹配,建立两者之间的链接关系,为用户跨库浏览与检索提供条件。③综合性标题表与专业性标题表之间的互操作,其典型例子是LCSH/MeSH映射项目。该项目是Northwestem大学自1990年至今仍在研究的一个项目。该映射项目以MARC21权威记录格式为中介,采用计算机辅助技术与人工编辑相结合的方法完成两标题的映射。国内学者刘华梅、侯汉清以教育类的数据为例,对叙词表互操作技术进行了较为系统的研究(11),他们选取《中国分类主题词表》、《教育主题词表》、《社会科学检索词表》等叙词表,运用词表结构的自动匹配、同义词表的语词匹配两种技术,实现叙词表之间的互操作。自动匹配一般是借助所选词表本身的兼容性,将叙词表相互的词汇以机读形式存储在计算机内,由计算机自动进行匹配。该项目所选的叙词表均属于汉语分面叙词表,款目格式基本相同,采用自动匹配实现叙词之间的互操作十分方便。对于不能完全对应的语词,则采用基于同义词表的语词匹配技术。其实现的具体步骤:①编制一部语义精良的同义词表;②对匹配的词进行切分,将其切分成多个词或词素的集合;③利用相似度计算公式,计算两个词之间的相似度;④利用程序进行计算;⑤确定阈值,筛选主题词。通过这种方法基本能够实现叙词之间的转换。
20世纪90年代以来,国内学者、专家一直在进行情报检索语言的互操作技术的研究,取得了一些实用成果,实现了不同类型、不同语言词表之间的兼容。近几年又完成了一些项目,如龚昌明等人的《装备科技信息分类主题一体化词表》、刘华梅研制的《教育集成词库构建系统》、中国医科院医学信息研究所的《医学分类主题一体化系统建设》、中国科学技术信息研究所的《汉语科技词系统》等。但是,与国外相比,实践成果还不是很多,能够推广使用的系统就更少了,特别是对于知识组织系统的互操作研究相对滞后,实现互操作的方法基本限于系统化、翻译、映射等,对于一些较为先进的互操作技术,如词汇的自动转换、集成词表技术等缺乏系统研究。专家认为,无论是对传统文献资源,还是对现代的网络信息资源,情报检索语言仍然是信息组织的主要方式,实现各种知识组织系统之间的互操作,使不同分类法、主题法互相结合,依然是信息检索领域研究的重点。而“如何实现人工语言与自然语言的兼容互换、推出应用型成果,实现人工语言与自然语言的和谐统一,将是我国知识组织及相关领域研究的重要课题”(12)。
3 关于网络叙词表的研究
网络叙词表是一种重要的网络信息组织工具,它伴随信息技术和网络的发展而产生。据陈红艳、司莉2008年所作的调查(13),关于网络叙词表的研究与应用主要集中在国外,而国内尚未见到实际应用的网络叙词表。根据本文对《中国期刊全文数据库》和《维普中文科技期刊数据库》的文献调查,近几年来,国内学者开始注重网络叙词表的研究,虽然目前研究的文献并不多,但是研究的问题比较集中。主要内容涉及:网络叙词表的结构、功能、应用,网络叙词表的设计与编制。
3.1 网络叙词表的结构、功能与应用
主题语言的检索效率高低、检索功能优劣取决于其结构模式。从标题表到单元词表到叙词表,再到分面叙词表的发展,是主题语言结构模式的创新与进步。传统叙词表的结构,最初只有单纯的字顺系统,其功能简单;为了寻求叙词表更佳的功能,一步一步地引进了分类系统。现在,叙词表的宏观结构一般都由两部分组成:字顺显示和系统显示。其中字顺显示部分包括字顺表、专有叙词表、轮排索引、双语种对照索引、入口词表等;系统显示(即分类显示)部分包括范畴索引、词族索引、词族图等。字顺显示与分类显示的有机结合,尤其是分面叙词表的产生,大大提高了叙词表的功能。作为一种优秀的概念语义工具,叙词表综合了多种情报检索语言的原理和方法,在对文献信息的组织和检索中发挥了重要作用,在网络信息资源的组织和检索中也得到广泛的应用。
网络叙词表是传统叙词表在网络环境下的新发展和新应用。同传统印刷型叙词表一样,网络叙词表也有多种类型:有的结构比较简单,主表只含字顺表,《Florida Environments网络叙词表》;有的主表同时拥有字顺表和分类,具有一体化叙词表的特征,如《World Bank网络叙词表》;有的是建立了辅助表的叙词表,像这类网络叙词表一般是同时拥有字顺表和分类表的大型叙词表(14)。按叙词表的编制语种分,有单语种叙词表,如ERIC Thesaurus只采用1种语言;多语种叙词表,如UNESCO Thesaurus采用4种语言。
虽然在组成上网络叙词表与传统印刷型叙词表没有太大的差异,但是,在其生成和实现方式上却有很多不同的地方,尤其是微观结构,凭借超链接方式,其语义结构的显示更加完善、清晰,网络叙词表的功能进一步扩大。曹树金、郭菁于2005年在《图书情报工作》杂志上发表了《网络叙词表的组织结构及优化模式研究》一文,对网络叙词表的宏观结构和微观结构进行了比较系统的研究。作者认为(15),网络叙词表的原理、结构与传统印刷型叙词表类似,只是为了适应网络信息资源的特征,其组织结构做了不同的设置与编排。宏观结构方面,网络叙词表在组成上与传统印刷型叙词表没有什么差异,只是其生成和运作有所不同。由于是由计算机辅助生成的系统,网络叙词表的生成与实现包括机内词表生成子系统、词表排版输出子系统和词表管理子系统组成。机内词表生成子系统要通过建立数据录入模块、数据批处理模块、机内词表建立模块和款目词排序表来生成一个机内词表;词表排版输出子系统用于排版输出字顺表、分类表、轮排表等;词表管理子系统主要用于词表的日常维护工作和查询检索。3个子系统的协调配合支持了网络叙词表的成功运作。
微观结构方面,网络叙词表在入口界面、词汇控制和标识系统3个方面有着显著的特征和优势。
叙词表的微观结构决定着叙词表的功能。网络叙词表依托网络和计算机技术的优势,设置多种入口界面,如提供检索入口、词汇浏览、检索词信息等,为用户选择不同方式进入网络叙词表提供方便。如美国国家医学图书馆的《MESH叙词表》,其界面就提供多种入口设置,用户可按照不同目的和对象进行检索并获得各种叙词信息。利用超链接技术能充分揭示叙词之间的各种关系,使之形成语义网络。这样,用户就能够更加清晰地了解概念间的内涵和外延,根据检索目标来构造检索式,提高检索效率;同时,有了超链接技术,用户可以在不同词汇间跳转,提高词表的使用效率。
网络叙词表是为了适应网络信息资源的组织和检索而产生的。目前,网络叙词表的功能主要体现在两个方面:一是用于网络信息资源的描述;二是应用于信息系统。用于网络信息资源描述的叙词表主要是利用传统叙词表来支持网络资源的发现并提供服务;应用于信息系统的网络叙词表的表现形式有两种:一是独立于检索系统之外,通过浏览词表,选择检索词以后,以所选词汇作为检索入口词来检索信息资源。二是叙词表作为检索系统的一部分,并嵌入在检索系统中,检索与浏览词表后,可直接使用选中的词检索相关的信息资源(16)。不过,目前应用叙词表的网络信息资源检索系统较少,主要涉及技术和成本两个问题。虽然网络叙词表的应用还不是很广泛,但叙词表的网络化是一种必然趋势,也是传统叙词表走向网络化、国际化的必然结果(17)。
3.2 网络叙词表的设计与编制
20世纪70年代末以来,我国编制的叙词表共198部(18),基本覆盖各个学科领域。早期的叙词表,基本上是由图书情报人员或学科领域专家人工编制的,随着计算机技术的应用,叙词表的编排、生成均由计算机辅助完成。现在,叙词表的管理、维护以及词库的建设基本由计算机完成。传统印刷型叙词表在对文献信息的组织与检索中发挥了重要的作用,特别是与计算机技术结合完美地实现了对文献信息的准确检索,提高了检全率和检准率,一举成为情报检索的主流。
随着因特网的迅速发展,网络信息以指数形式增加,人们对于信息组织和检索的质量提出了越来越高的要求。经过规范化处理的叙词表的局限性凸显出来了,主要表现在:①难以适应科学技术“微分化”和“积分化”趋势;②难以适应对信息内涵的全面揭示;③难以适应以知识单元为基础的计算机智能组织系统的信息控制;④难以适应知识形成和演化过程的控制(19)。基于自然语言检索的搜索引擎适应了网络信息增长态势,出现了以Yahoo为代表的主题分类信息检索方法,以谷歌、百度为代表的以关键词索引为主的全文检索方式,一度成为组织和检索网络信息的主要工具。然而,传统的搜索引擎由于搜索的内容比较复杂,导致用户查询的结果存在大量的无关信息,降低了查询的精确度,影响了检索效率。正如专家所言,不作词汇规范和词间关系显示,是自然语言检索系统最大的优点:降低了信息处理成本,减轻乃至消除信息处理难度,增加了检索系统的易用性;也是它的最大缺点:降低了检索效率,增加了获得较高检索效果的难度(20)。这是因为,类似于搜索引擎的网络信息检索工具大多采用基于关键词的全文检索方式,这种检索方式虽建库简单,查找方便,但返回的信息过多,有时检索效率会低到令人无法容忍的地步,其主要原因是概念不匹配。要提高纯自然语言检索系统的性能,需要把叙词表的控制机制引入到检索系统中,实现概念检索与导航(21)。
据有关专家调查(22),从1991年到2002年,国内有关叙词表的研究文献基本没有增长,可以说,这段时间由于自然语言的“回归”,有关叙词表的研究趋于低谷。从2002年起,有关叙词表的研究文献呈上升趋势,叙词表的研究和应用逐步升温,掀起了新一轮研究热潮,从而引发了图书情报工作者的重新思考,过去用于文献信息检索非常成功的叙词表,能否在网络环境下同样发挥重要的作用?然而,一个不容争论的事实是,传统印刷型叙词表产生于纸质文献时代,应用到数字化、网络化环境存在一定局限性,已经不能满足网络信息检索的需要。鉴于国外应用网络叙词表的成功经验,设计与编制汉语网络叙词表被提到议事日程。
迅速发展的计算机技术和网络技术为叙词表的应用提供了良好的平台,也为叙词表的改造与创新提供了技术支持。曾建勋、常春认为(23),汉语网络叙词表的编制已具备一定条件:①在概念术语选用方面具备了科学依据和数据支持,如CNKI、重庆维普、万方数据等大型语料库,百度、谷歌等搜索引擎,此外,还可通过日志获取用户使用检索词汇的种类和频次,所有这些语料库,为网络叙词表的编制中基于概念覆盖、词频统计、用户使用的关键词来选取规范的概念术语提供了可能;②在网络叙词表词间关系建立方面,海量的语料,计算机的计算速度和智能程度,提供了获取概念术语间词间关系的可能;③网络叙词表在计算机应用概念术语数量控制方面不是主要问题,而主要考虑如何找全所有的专业术语,并且给出这些术语之间尽量多的词间关系;④标准的数据格式(如SKOS的数据格式、OWL的数据格式等)及可视化的编制和应用界面,网络叙词表编制可视化系统,能清晰地表达各类知识结构层次关系,可视化系统表现在编制、维护、应用等多个方面。
杜慧、侯汉清提出了一种汉语叙词表自动构建思路和方法(24)。在某一确定领域内,采用模式识别、同现分析、词聚类等自然语言处理技术,实现自动识别词间等同关系、等级关系和相关关系,来构建一部领域叙词表。相比传统的编表方法,自动构建汉语叙词表有自身的优点:①充分利用计算机技术的优势,实现自动识别词间关系,从而既可降低词表编制专家的智力负担,又可缩短编表时间,还有利于叙词表的推广使用;②由于词汇直接来源于本领域文本语料库,能够客观真实地反映该领域的知识框架,提高信息检索效率;③自动构建的叙词表,能够尽量完备收录同一概念的不同表达形式,对于用户在检索中输入的自然语言词汇,系统能够提示与之对应的叙词,根据不同用户的检索行为和检索方式,构造不同的检索策略,或提供导航,或直接实施检索扩展,符合网络环境中普通大众对叙词表的要求。这种自动构建的叙词表虽与印刷型叙词表在组成部分上没有多大差别,但它与网络叙词表极其相似,是由计算机辅助生成的系统,因此在词表的生成和运作方面就大不一样了。
网络叙词表的一个重要特征是可视化,其用户界面既是词表结构与内容的直接体现,也是用户与词表系统之间进行交流的窗口。因而,界面的友好性、易用性和内容的可获取性是衡量其质量的标准。司莉、陈红艳选取了40个英文网络叙词表,对个词表的用户界面内容进行了全面调查与分析。作者认为(25),词表用户界面设计策略,主要包括创建丰富全面的首页界面、建立完备易用的检索功能、实现多途径浏览辅助检索、完善网络服务项目以及合理布局界面结构等内容。
4 关于《中国分类主题词表》的研究
2005年,《中国分类主题词表》第2版完成修订并出版,该表的电子版也同时出版。这是图书情报领域的一件盛事,立即引起业内人员的高度重视。一时间,介绍、评论、应用的文章骤多。人们关心《中国分类主题词表》,是因为这是一部在我国图书情报界有着极其重要影响的分类主题一体化词表,尽管在结构上、在分类号-主题词的对应上没有分面叙词表那样完美,分面叙词表的分类号与主题词之间是等值兼容关系,而《中国分类主题词表》的分类号与主题词之间只有一部分是等值兼容,但是,在实际应用中却显示了巨大的生命力,除了它是基于《中图法》和《汉语主题词表》在我国广为应用的检索语言外,还由于这种分类号-主题词对应的形式更加适用于文献信息的标引和检索(26)。《中国分类主题词表》的问世,极大地推动了我国图书馆、情报机构主题目录的建立和主题检索的应用。
4.1 《中国分类主题词表》(第2版)的性能研究
虽然《中国分类主题词表》的初版是基于《中图法》第3版(含《资料法》第3版)与《汉语主题词表》双向对照索引,但是它的功能在当时就已经超过了国外类似的词表。它不仅可以用于选类和选词,而且可以同时用于分类标引与检索、主题标引与检索,实际上《中国分类主题词表》已经成为分类检索语言(《中图法》)和主题检索语言(《汉语主题词表》)兼容、互换的工具。经过10多年的应用,修订后的《中国分类主题词表》在性能上有哪些改进呢?在网络环境下,《中国分类主题词表》(第2版)可用做什么?业内专家对此进行了深入研究。
侯汉清、李华从规模和性能上对《中国分类主题词表》的新旧两个版本进行了测评和比较研究(27),认为在规模上(主要是从收词的数量考查)《中国分类主题词表》是一部综合性的大型一体化词表,其收词应尽量完备,各学科收词量应适中。修订后的第2版实际新增叙词21 607条,新增入口词21 000条,新增族首词917条,大幅减少了叙词词串的数量。目前,《中国分类主题词表》第2版共收录分类法类目52 992个、主题词110 837条、主题词串59 738条、入口词35 690条,囊括了哲学、社会科学和自然科学所有领域的学科和主题概念,是我国目前最大的分类—主题一体化标引和检索工具(28)。在性能上,主要对类目对应标引深度、词汇的先组度、等同率、关联比和参照度等几个方面进行了测评。其中词汇的先组度、等同率、关联比和参照度对词表性能有着重要影响,如提高等同率可以增加检索入口,方便用户检索。
根据研究显示,《中国分类主题词表》新旧两个版本,除词汇的先组度指标基本保持平衡外,类目对应标引深度、等同率、关联比和参照度等的指标,第2版较之第1版都有不同程度的增加。在修订之前,词表编委会就提出了提高《中国分类主题词表》与自然语言兼容能力的构想,增补入口词,使之趋于自然语言化。为此,第2版增加了大量的同义词、准同义词和主题概念的不同表达方式;将一批被删除的正式叙词改为入口词。经过一增一改,使第2版等同率比第1版提高了一倍多,第1版的等同率为14%,第2版提高到32%。等同率的大幅提高,既提高了词表的易用性,便于标引,又提高了检索系统的易用性,用户使用的大量自然语言可以通过词表的语义控制转换成规范的主题词(29)。参照度和关联比这次修订增幅不大,这可能是因为第2版大幅增加叙词,还未来得及建构新增概念的词间关系。尽管如此,等同率、参照度和关联比提升,大大改善了词表的性能。
侯汉清、李华在对《中国分类主题词表》新旧两个版本进行测评和比较研究后,就完善《中国分类主题词表》的性能提出了建设性的意见(30):今后对《中国分类主题词表》的修订应当继续把增加入口词,提高等同率作为修订重点;鉴于第2版的关联比和参照度仍然偏低,今后的修订应当尽量减少无关联词的数量,加强对叙词概念之间语义关系的分析,逐步完善词表的语义网络,使其成为网络实现信息资源的概念检索和智能检索的重要语义工具。
网络环境下,《中国分类主题词表》(第2版)可用做什么?陈树年、刘惠敏分析,《中国分类主题词表》第2版的新功能有3点(31):第一,它是一种分类法和主题法对应的一体化检索语言,可同时进行分类标引和主题标引;第二,它是一种检索工具,利用电子词表,通过浏览分类等级树可以检索到特定数据库的信息,通过输入主题词就可以检索到与该主题词匹配的信息;第三,它是一种语义网络,其重要价值在于构建了一个完整的知识地图,既能描述知识的等级体系,又能描述主题概念的语义关系。正是由于它具备这些功能,网络环境下,它既可以用于传统的文献信息组织,又可以用于数字图书馆的信息组织,还可以用来组织网络信息。适用于图书馆、档案馆、情报所、书店、电子网站等进行各种类型、各种载体文献信息的分类主题一体化标引和检索。其电子版为实现机助标引和自动标引提供了知识库和应用接口。
当然,为了适应更大范围信息组织的需要,在完善其标引功能和检索功能的基础上,应注意开发新的功能,诸如检索语言互操作、元数据自动生成、网络检索的自动查询扩展、计算机辅助标引、自动标引、自动分类等,并为本体、主题图、语义网络等新型知识组织系统的研制,提供词汇和语义资源(32)。
4.2 《中国分类主题词表》(第2版)电子版
20世纪90年代以来,计算机技术和网络技术在图书馆得以广泛应用,联机编目和远程网络编目进一步发展,传统印刷型的《中国分类主题词表》已不能满足机读数据库的需求,编制一部具有机助标引和检索功能,甚至自动标引功能的机读型的《中国分类主题词表》,是广大用户的呼声。2000年4月,《中图法》编委会所确立的《中国分类主题词表》修订原则中提出,要求该表在满足分类主题一体化标引和检索功能的前提下,提高对计算机编目、计算机网络检索环境的适应能力,在满足中间用户——标引人员标引需求的前提下,还要满足最终用户——一般读者的查找要求,提高其与自然语言的兼容能力。要充分利用计算机技术,发挥已有机读数据库的作用,重视和完善已有的词表编辑管理系统,开发研制《中国分类主题词表》的编辑管理系统(33)。2005年,《中国分类主题词表》电子版随同印刷版问世,其研制工作既具有理论上的探索性,又具有实践上的创造性。电子版的研制成功,在许多方面弥补了印刷版的不足,它是为兼顾印刷版的需求而开发的电子化的信息资源组织工具。有了电子版,用户可以免去在印刷版中来回翻检的烦恼,增强词表的易用性,提高标引和检索效率;为实现我国信息组织和检索工具系统的数字化、网络化打下了坚实的基础;为我国公共文献信息资源检索系统提供了受控标识的语义检索平台,成为我国唯一一部可用来组织综合性数字信息资源的检索工具。
可以说,《中国分类主题词表》电子版是情报检索语言在网络时代发展与应用的产物,是从内容上组织整序和检索的主要电子工具。
为了宣传、推广电子版,作为《中国分类主题词表》编委的卜书庆等专门撰写了《〈中国分类主题词表〉电子版研制概述》的研究论文,介绍了电子版的研制经过,详细分析了电子版的研制原理、功能设计特点。作者归纳了电子版功能设计的10大特点(34):
(1)个性化用表环境的设计。在预设常用的启动环境的基础上,不同类型的用户可根据个性化需求自行定制启动环境。
(2)多表、多文档互动结构的设计。这里的“互动”是指电子版在预设状态下点击主题词或分类号,系统会自动按照第一个对应的词或类号,在对应表多文档结构定位显示,如果有分属关系的主题词包括族首词,则动态生成词族和自动定位在词族表的语义关系中,为用户提供了一个查找概念和显示语义关系的理想平台。
(3)参照项的超文本链接功能的设计。有了这种超文本链接功能,人们可对分类表中的直接上、下位类或主题词表中的参照项,依多窗口方式链接重定位。这种保留原窗口的超链接设计提供了一表多文档的结构环境,有利于对类目或主题词比较分析。
(4)多途径、多方式的检索窗体的设计。词表的多途径、多方式的检索窗体,是从标识匹配检索和语义检索角度出发,设计出单项检索和组合检索两种窗体,包括15种检索途径、5种检索方式和3种逻辑组合检索方式。通过它们,既可以满足一般检索系统的匹配检索,也可以满足基于结构化数据的智能检索,还可以满足复杂类目、类组的检索和多属性的主题检索。
(5)结构化全文检索功能的设计。据介绍,电子版的全文检索功能较之一般的全文检索,在查全的基础上提高了查准率,因而被称之为智能化的全文检索。
(6)分类主题一体化扩检检索功能的设计。一体化扩检是电子版从语义检索角度开发的一种独特思维检索方式,这种设计可方便用户通过模糊检索,判断选择最专指的类目和主题词;同时,对于新的用户来说,即使不熟悉类表和词表,也能提高文献标引效率和质量。
(7)分类树视图存储功能的设计。有了这种机制,用户可以将针对不同需要调整好的分类树视图保存起来,随时调用。
(8)词族动态重组功能的设计。
(9)与计算机检索和标引的引用系统挂接功能的设计。有了这种挂接功能,用户可从词表系统中将确定要使用的类号或主题词发送回宿主程序,作为检索或标引用词。
(10)添加评注、批注等公务目录作用的功能。
总之,电子版可通过多种浏览方式和检索方法来实现各种条件下的分类主题一体化检索及各种需求的一体化显示功能,并通过超文本技术实现了类目间、叙词间、类目与叙词间的自动链接,大大降低了印刷版查找的复杂程度和实施扩检、缩检的难度,实现了真正意义上的分类主题一体化标引和检索,提高了信息资源的加工效率,同时提供了一个知识和文献信息检索服务的平台(35)。
《中国分类主题词表》电子版出版以后,受到图书情报界标引人员的高度重视,他们在文献标引实践的基础对其进行研究,用事实说话,既肯定电子版在实际标引工作中的优异功能,也为其进一步修订和完善提出建议。朱芊撰文(36),从推广使用的角度,在分析电子版分类主题一体化检索功能的基础上,介绍了查类、选词的一般方法与步骤,指出了使用过程中应注意的问题。黄星亮则介绍了利用《中国分类主题词表》电子版标引文献的技巧,认为该表电子版所具有的先进性及其在文献标引工作中的重要价值不言而喻,但也存在不足,如软件设计尚待改进,录入数据不够规范等。并建议充分利用电子版的优势,及时进行版本升级,提高其适应性,使之在文献标引和检索中发挥更大的作用(37)。刘英杰认为(38),电子版为标引人员提供了极其便利的检索方法,使标引工作效率和质量大大提高。李楠在肯定其电子版功能的同时,也明确指出电子版的问题,如标识控制不够严谨、选词不够规范等。尽管如此,瑕不掩瑜,相信随着不断的修订和完善,电子版必定会显示强大的生命力(39)。
4.3 《中国分类主题词表》的应用
《中国分类主题词表》是一部分类主题一体化词表,毫无疑问,可以用于文献分类标引和主题标引。它还是我国使用最为广泛的分类语言和主题语言兼容转换的工具,尤其是电子版的出台,达到了浏览和互动检索的目的,能够达到同一概念的分类标识和主题标识互换检索,同一种语义关系标识的检索;修订后的电子版还提高了自然语言的检索能力,起到了入口词检索的作用;其中,一体化互动显示还能起到自然语言多入口词检索的作用,克服了同一主题概念单一的检索形式(40)。
鉴于《中国分类主题词表》真正实现了分类主题一体化,在国内影响大,通用性强,用户比较熟悉,侯汉清先生早在2000年就提出一种基于《中国分类主题词表》的后控词表的设计方案,并以其作为基本框架,编制新闻信息数据库后控词表(41)。这种将自然语言检索标识与《中国分类主题词表》对应的后控词表编制模式,扩大了该词表的应用范围,研制者无须另起炉灶为后控词表建立新的分类体系。这样在它的基础上建立后控词表不仅可以利用其分类体系,而且还可以将对应列出的主题词作为控制词,在控制词下建立一个自由词词群,直接利用《中国分类主题词表》的分类体系和词汇,使其后控词表具有分类主题一体化词表的性质和功能,其使用面宽,易于推广。
《中国分类主题词表》第2版及电子版问世以后,有些专家提出新的设想,将其应用于领域本体的构建。其实,领域本体就是一个个专门领域的知识分类或主题图,分类法、主题法都可以看成是本体方法。薛云等在分析、对比本体与分类法、主题法各自的特点及相互关系后,提出基于《中国分类主题词表》的中国民族音乐领域本体的构建,并赋予实践(42)。
实际上,利用《中国分类主题词表》构建领域本体,有非常好的可扩展性和权威性,也可以很方便地对其进行扩展。任瑞娟具体分析了《中国分类主题词表》与Otology之间的关系,认为两者在概念、概念等级分类、概念之间的关系以及分类等方面确有很多相似之处,提出了基于《中国分类主题词表》构建分布式Otology的设想。作者认为,《中国分类主题词表》的权威性、科学性、知识性是使其成为中文叙词表Otology标识的首选实例(43)。
当然,分类法、主题法包括分类主题词表,在其编制时还没有考虑到网络信息计算机语义识别的问题,但是,它们都是图书情报界长期积累、积淀的关于知识体系、语义关系的结晶,包含着非常丰富的知识和语义的关系。尽管分类法、主题法还有很多关系不那么严密,显示的语义关系比较简单,但《中国分类主题词表》的一体化结构却提供了较丰富的知识、概念的体系与关系,以此为基础构建领域本体是可行的。
专家们认为,《中国分类主题词表》在数据挖掘和知识发现、同义词识别、自动标引、电子政务和电子商务等信息组织中,也都有重要作用,关键是人们如何发掘和利用(44)。
5 关于自然语言检索研究
随着计算机技术和网络技术在图书情报工作中的应用,主题检索语言的发展出现了由受控语言向自然语言的“回归”(45),自然语言检索也就成为研究的热点。业内人士纷纷撰文,或赞扬自然语言在网络信息检索中的优良性能,或比较受控语言和自然语言在信息检索方面的差异,有人甚至质疑情报检索语言在网络环境下存在的必要,等等,可以说是百家争鸣,各抒己见。
自然语言的确有很多优点:易用性好,检索方便;标引简单快捷,易于实现自动化;标引具有较好的一致性;专指度高,可以具体到文摘、文献正文中出现的任何一个有实际检索意义的语词;还可指定检索用词的出现位置等。自然语言的这一系列优点显示出了它更适应网络信息资源数量庞大且增长迅速的状况,“网络信息检索工具采用自然语言的必要性是不容置疑的”(46)。但是,在自然语言“回归”之初,人们的认识有些偏颇,“许多论述对自然语言的评价过于夸大”(47)。其实,自然语言在信息检索中也存在严重不足:表达概念过分自由,语义无关联。正如张琪玉先生所指出的,“缺乏控制的单纯自然语言检索,是决不可能成为情报检索语言的发展方向并取代人工语言的”(48)。
近几年来,人们对自然语言检索的研究比较理性,基本集中在自然语言检索和情报检索语言的结合与融合,利用受控语言的原理和方法提高自然语言检索的效率,自然语言处理技术等方面。
5.1 自然语言检索效率
从检索语言的角度来说,自然语言检索就是指在为文本信息提供检索标识时,使用文献作者、文摘编写者原来所用的语词或标引人员自拟的语词,而不是取自受控词表中的语词。目前,自然语言检索主要还处在关键词检索这一层次上,即关键词索引及数据库、全文检索和搜索引擎。无论是关键词索引及数据库、全文数据库,还是搜索引擎及由搜索引擎自动建立的网络资源数据库,实际上都是利用关键词检索技术来实现信息检索,关键词检索几乎成了自然语言检索的代名词。
20世纪50年代,关键词检索方法就开始运用于文献检索,起初用作检索刊物的临时索引,后来数据库的关键词检索得以重视; 80年代,基于计算机、电子出版、光电扫描等技术支撑的全文检索技术崛起,而全文检索总是以关键词的形式与索引数据库进行匹配检索,是发展得相当成熟的一门检索技术;进入网络时代,搜索引擎成为信息检索的重要工具,就其本质而言,搜索引擎也是一个大型的全文检索系统,一般检索系统所提供的检索功能,搜索引擎同样也能支持。所以,搜索引擎的检索实际上就是全文关键词匹配检索。半个多世纪以来,关键词检索技术在发展中不断变化,尤其是在网络检索系统中,采用自然语言检索信息成了信息检索的主流,关键词检索法已经成为用户广为使用的方法,被视为“大众检索语言”。
与传统的情报检索语言相比,关键词检索法在适应当今信息检索技术发展和用户需求中具有很多优异性能(49):计算机关键词索引的建立相对来说容易实现,在标引阶段不控制或只进行少量控制;抽词时使用禁用词表排除非关键词,处理相当方便;便于用户采用自然语言表达检索课题,容易被用户接受。但是,在具体使用过程中仍存在严重不足,除返回的信息太多这一表层现象之外,还有两个深层的原因,即语词概念的“忠实表达”和“表达差异”的问题。正是由于这个原因,容易造成与主题相关的信息分散;没有清楚显示概念之间的关系,容易造成检索系统的失误;用户难以确定全部的检索用词,加重了用户的负担。因此,要保证较高的检索效率,必须适当地介入受控语言的控制机制(50)。
研究表明,提高自然语言的检索效率必须引进受控语言的词汇控制原理和方法,对信息检索中的各种不利因素进行控制,使两者互相结合或融合。在研究中,人们提出了多种模式,如受控语言与自然语言结合使用、受控语言与自然语言并行使用、编制入口词表、建立后控词表(51),以及利用混合检索技术对自然语言进行适当控制等。上述各种模式都是在自然语言检索和传统受控语言检索之间寻找一条中间道路,而且大多是从理论上对提高自然语言检索效率的探索,尚缺乏对自然语言检索及相关问题的系统、深入研究。可以说,目前国内对自然语言检索的研究仍处于探索阶段,一些检索实现方案和实验系统也都只是在一定程度上对少量实验样本所进行的。同时,对汉语自然语言检索的研究较少,缺乏较为深入的研究。刘华梅、侯汉清介绍了一种自然语言转换为受控语言的语义工具——入口词表模块(EVM)(52)。该模块系美国伯克莱大学开发设计,其目标是实现自然语言到受控语言的转换。刘华梅、侯汉清详细地介绍了EVM的创建过程和实现机制,即首先利用数据检索代理和清洗代理从远程数据库中下载记录;然后抽取代理和构建代理利用下载的数据,采用统计学的方法计算自然语言词汇和受控语言词汇之间的关系,构建关联词典;最后由桌面代理和领域代理提供给用户感兴趣的领域,帮助用户进行检索。此法可为汉语自然语言检索所借鉴。
近年来,随着国内本体研究热的兴起,业内从另一个角度开始探讨自然语言与受控语言的结合和融合,探索自然语言检索的新发展。李雅琼认为(53),本体具有与情报检索语言相类似的一些性能特征,首先,本体也是由概念及其相互之间的关系构成,而且构成本体的概念可以更加系统、更加全面地揭示概念之间的关系,其表达能力更强;其次,本体也具有描述词间关系的功能,不仅可以表达概念之间的各种关系,而且还可以表达概念的继承关系、属性关系、实例关系、函数关系等;再次,本体也具有信息标引和组织功能,也能对信息加以集中并揭示其相关性。更重要的是本体描述与揭示信息的方法在于系统中的概念、特性、限定条件等内容是计算机可读的,其信息描述与揭示方法中,概念之间关系的表达要比受控语言(分类法、主题法)更广、更深。因此,本体完全可以替代情报检索语言对自然语言加以控制。
基于本体的自然语言检索方法最关键的就是在自然语言检索的词法分析、句法分析阶段使用本体语言对其进行规范。焦玉英、张璐提出了一个基于Otology的Web环境下的语义检索系统结构模型(54)。在目前的Web信息检索中,普遍存在检索效率低下的问题,也不具备语义推理能力,无法实现智能化检索的要求。构建一个基于Otology的语义检索系统结构模型,有利于对自然语言检索进行有效控制,从而提高检索效率。因为该模型具有这样几个特点:①其检索不是基于关键词匹配式,而是问答式;②检索的处理对象是网络信息资源,它们是异构的,非结构化的;③系统具备自然语言的语义分析能力,它建立在本体的构建和应用之上;④系统具有一定的推理能力,是智能化的知识库,且依赖于本体技术的应用。在自然语言检索的基础上应用Otology技术,把语义信息融入其中,利用Otology的概念词典能够提高检索结果的相关性和扩展性,提高检全率和检准率。
目前,对自然语言的处理,已从语法阶段上升到语义阶段,要使计算机准确地分析、表达和传输知识,必须使它具备理解自然语言的能力。当代人工智能技术的发展,为信息资源的动态结构揭示和智能化控制提供了可能。智能技术将信息揭示与文献控制融为一体,除提供动态信息外,还可在更广的范围内进行知识组织与处理,将反映相关知识的信息资源进行有机结合。饶娟对自然语言的智能检索技术进行了研究,应用Otology的理论与方法对文本分类进行概控制,将信息检索从基于关键词层面提高到基于知识(概念)层面,从概念层认识和处理用户的检索请求,从而有效地提高了检索系统的检全率和检准率。
本体是近年来随着计算机信息处理、人工智能和知识工程等学科的发展而兴起的一个具有活力的研究领域。李雅琼认为,在图书情报领域,本体是对情报检索语言的继承,而自然语言检索发展到今天又需要借助情报检索语言予以规范控制,因此与本体结合是自然语言检索的发展方向。从本质上讲,自然语言检索是一种概念检索,它需要一定的概念体系或知识库支持,而本体就是一种概念体系、一种知识库。
5.2 自然语言处理技术
自然语言处理是自然语言得以应用首先要解决的核心问题。虽然对自然语言检索的研究已经有一段时间,取得了一些成果,但是由于自然语言现象本身的复杂性和多样性,仍然有很多值得深入探讨和研究的问题,“包括自然语言的文本的分析和处理、面向自然语言检索的标引、用户提问的机器处理、匹配过程的控制和查询扩展等”。(55)近几年来,人们没有间断对自然语言处理技术的研究,尤其是汉语自然语言的研究。熊回香、夏立新在综述近20年来国内语言学界、人工智能领域和图书情报界学者对中文分词技术成果、中文全文检索技术的基础上,认为中文分词技术经过十几年的研究,取得了瞩目的成就,但在分词算法、分词词典与分词规范、歧异消除、未登录词识别等方面还存在一些局限,提出了加强汉语语料库建设、词索引数据库研究的发展思路(56)。何莘、王琬芜通过在国内外著名数据库中进行的相关检索,研究了自然语言检索中中文分词技术及其在搜索引擎中的应用,认为中文分词技术是实现自然语言检索的重要基础,无论是专业信息检索系统还是搜索引擎都依赖于分词技术的研究成果(57)。目前,国内外都很重视中文分词技术在搜索引擎中应用的研究。关于搜索引擎技术,雅虎中国网页搜索部总监认为,中文分词是搜索技术的基础,只有做好了分词,才能有好的搜索。雅虎在中文分词技术上就花费了很多精力,在美国成立了研究所,共有300多人进行相关研究,而且拥有自己开发的中文分词技术。Google的中文分词技术采用的是美国Basis Technology公司提供的中文分词技术。国内研究中文分词的多是科研院校,而真正研究中文分词技术的商业公司很少。现实情况是,科研院校研究的技术,大部分不能很快产品化,而一个专业公司的力量是有限的。由此看来,中文分词技术要想尽快产品化,并提供优良服务,应该走科研院校与商业公司共同开发的道路。
当前,解决中文分词技术的问题已经成为中文信息处理的一项战略任务。刘迁、贾惠波在对基于机械匹配分词法、基于统计语言模型分词法和基于人工智能技术分词法等3种中文自动分词方法进行比较研究的基础上,指出汉语文本与西文文本信息处理不在一个层面,西文文本信息处理是基于词平面,而汉语文本则是基于字平面,并且认为这个层次的差异是根本性的、全局性的,因而中文文本自动分词问题是制约中文信息处理的最大瓶颈。当前中文文本自动分词技术需要研究的主要问题有三:一是对分词词表的建立和完善,包括建立通用的核心词表,构造各个领域的基本专用词表;二是分词方法的研究,包括加强对汉字串统计性质的研究,分词策略及分词算法的研究,以及如何更加有效地解决切分歧义及未登录词的问题;三是研究汉语的规律和特点,从汉语书写规则出发来寻求中文分词技术的突破口(58)。孙铁利、刘延吉在概述了中文分词的基本方法后也认为(59),中文的词与词之间不像西文那样有明显的分隔符,所以就构成了中文在自动分词上的困难。中文分词的主要困难不在于词典中词条的匹配,而是在于切分歧义的消解和未登录语词的识别。这样,在建立一系列规范的基础上,书写或录入时在词与词之间增加分隔符,使计算机能自动识别和切分,从而可以解决中文文本信息处理与西文同一个层次的问题,将中文文本信息处理的起步点建立在词平面上,这种方法将是中文自动分词未来新的方向。
6 关于自动标引的研究
自动标引是根据自然语言检索的需要发展起来的,是电子环境下出现的一种新的标引形式,是自然语言检索研究的重要内容之一。虽然自动标引研究早在50多年前便开始了,但到目前为止,对于自动标引所涉及的一些技术问题、应用问题、网络环境下的发展问题,仍然是业内的研究热点。
6.1 自动标引理论
文献自动标引是指利用计算机从各种文献中自动提取有关标识引导的过程(60)。也有学者将自动标引定义为机器标引,即使用机读分类表,通过语义分析和概念分析等手段,自动发现和标引各种文献,包括网络信息。
最早开展文献自动标引研究的人是美国学者卢恩(H.R.Luhn),他在1956年首次开展了自动标引试验,1957年在IBM公司的研究刊物上,发表了第一篇有关自动标引的论文,题名为《文献处理机械化编码和检索用的统计学方法》,1958年又发表了有关自动编制文摘的论文(61),明确提出了词频统计加权方法,首次将计算机技术引入文献标引领域,开创了以自动标引为特征的现代标引方法。此后,来自计算机、语言学以及图书情报等领域的众多研究人员对文献自动标引进行了深入研究,提出了多种自动标引方法和理论,并产生了机辅标引和自动标引两个分支。机辅标引使人们从手工标引的机械劳动中解放出来,而自动标引则致力于让计算机从事标引工作中的脑力劳动(62)。直到20世纪90年代初国内外学者都致力于关键词自动提取的不同思路和方法的研究,但90年代末由于全文索引的兴起,传统自动标引方法的效率达到极限,网络兴起之初的冲击和信息需求环境的改变,自动标引研究渐入低潮。尔后,随着全文索引功能越来越难以满足实际需求以及互联网很多服务对于关键词自动提取技术的依赖,对自动标引的研究又逐渐深入起来。
我国对文献信息自动标引的研究始于20世纪80年代初,由于汉语信息的表达与组织所固有的特点,最初的20年我国的自动标引研究主要集中在解决汉语的分词问题上。目前,国内语言学界、人工智能领域和情报检索界的学者们提出了许多解决汉语自动分词的方法,归纳起来有:基于词典的分词方法、基于统计的分词方法、基于理解的分词方法和基于人工智能的分词方法等。
随着研究的不断深入,国内自动标引研究的重心逐渐由分词研究向实际标引研究转移。上海交通大学、中国软件技术开发总公司、北京航空航天大学、北京大学等单位都先后建立了各自的试验性汉语文献自动标引系统。而世纪之交,图书情报界提出的中文全文标引研究也成为业界讨论热烈的话题,为信息检索自动化做了技术准备,一些具有全文标引功能的系统,如《中国学术期刊》、万方数据、维普期刊、中国专利数据库等纷纷投入使用。
对于目前国内自动标引研究的状况,在2008年中国索引学会第三次全国会员代表大会上,谢坤生认为“标引自动化已成为文献加工自动化的趋势”,而当前“我国的自动标引进展缓慢”(63)。主题词标引进展较快,已基本取得成功,机辅主题标引已在许多图书馆、情报所和索引工作中得到了广泛的应用,但还需在图书情报界、编辑界的一次文献和二次文献的标引工作中不断改进、完善。自动分类标引难度较自动主题标引更大,目前,国内研究这一方面的学者不多,且基本上都处于“实验”阶段。国内的自动标引研究与推广工作任重而道远。
6.2 自动标引技术
文献自动标引可以分为自动抽词标引(关键词自动提取)和自动赋词标引。
自动抽词标引也被称为关键词自动提取,它是指直接从原文中抽取词或者短语作为标引词来描述文献主题内容的过程。它涉及如何从原文中抽取能够表达其实质意义的词汇,以及如何根据这些词汇确定标引词(64)。章成志认为,抽词标引方法可以分为三大类,包括语言分析方法、统计学习方法和混合方法,其中语言分析方法包括词法分析方法、句法分析方法、语义分析方法和篇章分析方法等,统计学习方法包括简单统计方法、一般机器学习方法、集成学习方法,而混合方法则是上述方法的总和运用,或加入启发式知识(65)。
自动赋词标引是指使用预先编制的词表中的词来代替文本中的词汇进行标引的过程。即将反映文本主题内容的关键词(欲用作标引的关键词)转换为词表中的主题词(或叙词等),并用其标引的方法(66)。章成志将赋词标引分为机器学习方法和构建标引用词典资源方法(67)。
前些年,国内对自动标引的研究基本集中在词典标引法、统计分析法、语言分析法、人工智能法等几种典型的自动标引方法上。
词典标引法的基本思想是:首先构造一个机内词典(主题词典、关键词典、部件词典等),然后设计相应算法与词典匹配,若匹配成功则将其抽出作为文献的标引词。词典标引法是一种传统的自动标引方法,在当前汉语自动标引中占主要地位,最大匹配法、最小匹配法、切分抽词和综合加权法都是基于词典标引的主要方法。许剑颖认为词典标引法标引文献检索速度快,并且可提供扩检和缩检功能,但词典的构造和更新较为困难,词典编制的完善与否直接影响标引质量的好坏(68)。
切分标记标引法的基本思想是:将能够断开句子或表示汉字之间联系的汉字集合组合成切分标记词典输入计算机。切分标记词典有词首字、词尾字和不构成词的单字,也有人用“表外字”、“表内字”、“非用字”、“条件用字”等来组成切分词典。当原文本被切分词典分割成词组或短语后,再按照一定分解模式将其分成单词或专用词(69)。
这种方法对切分后的词组或短语需要再分解,但是分解后的模式以及分词知识库难以适应汉语灵活的构词变化,标引错误率较高。
统计分析法自动标引实质是词典分词、词频统计、位置加权三者结合选定标引词的方法。其中词频统计标引法的理论基础是齐夫第一定律(即Zipf定律),它以词汇在文献中出现的频次来确定其对于文献主题的贡献大小,通过预先设定的阈值筛去出现频率较低的词,将频率较高的词作为标引词。由于它建立在较成熟的语言学统计研究成果基础之上,客观性和合理性较强,且简单易行,因此在自动标引中占有重要地位。但许剑颖认为这种方法将文献任何部位的词不加区别地对待,不能很好地反映标引词与文献主题内容的相关程度。并且认为当采用加权统计的方法确定标引词之后才真正开始了汉语文献标引研究(70)。
加权统计法相对于单纯的词频统计是一种进步,但在实践中,权值的大小较难确定。由于文献类型不同,很难设计出一套广泛使用各种文献的权值体系。有学者提出了词相关性加权标引模型和价值测度加权标引模型,这两种模型既考虑到了词在某一特定文献或整个文献集合中的频率特征,又考虑了标引词在相关文献集合和无关文献集合中的频率特征,以及检索结果的效益值。但是由于权值函数中的等值量在标引之前是未知的,只能近似估计,因此这两种方法在实际应用中也具有一定的局限性(71)。许剑颖认为可以将仿人算法的思想引入自动标引。所谓仿人算法是指受人工处理经验的启发而建立的适合计算机处理的类似人工的算法。并从分析文章的具体特点入手,提出根据文献结构、文献特点、“邻句相关度”、句子“相似度”等不同文章的不同特点调整相应的权值(72)。
单汉字标引是汉语自然语言处理的一种独特方式,它避开了以往汉语分词的困难,另辟蹊径,从汉字组配的角度出发,寻找到了一种新的语言处理模式。
很多业内人士对其进行了深入的研究,认为单汉字标引法的优势在于:①符合汉语文字的特点,绕开了自动分词的难关;②适合计算机自动处理;③能够确保标引的一致性;④组配灵活,利于字面成族的检索;⑤具有高容量、高弹性,易于维护存取等。单汉字标引方法一经提出便引起了学术界的关注,在1989—1993年,全国情报学界兴起了一股研究单汉字标引的热潮。但由于单汉字检索自身存在诸如以单汉字为处理单位,容易产生虚假组配以及检索噪声大且筛选负担重等缺陷,1993年后我国对单汉字标引的研究逐渐走向了低潮。
然而许多专家认为单汉字标引方法是一种极具潜力的自动标引方法,如果能彻底解决检索时的各种缺陷,那么它不仅能节约大量的智力劳动,而且也能把人们从自动分词的困境中解脱出来。现在仍然有很多学者致力于这种标引方法的研究,并认为对单汉字标引的研究应继续深入开展下去。罗雪英认为,要彻底解决单汉字标引的各种检索问题,应该在后控词表上下功夫,把对单汉字标引的研究重点放在后控词表的研究上,建立一个功能强大的后控词表。在词表中应对隐含性主题进行加注、标引,在单汉字检索的模式上适当建立粗泛的控制词汇结构或对题名、摘要等进行单汉字标引,要能提高检索算法,实现左截断、右截断、中间截断,要能在不同层次上实现扩检和缩检(73)。彭冬莲认为,单汉字标引和检索技术的发展趋势之一是引入人工智能技术,以有助于发展检索系统的语义分析、自动搜索、逻辑推理等功能,使系统实现自扩展、自学习,检索策略的自动优化,检全率、检准率的提高(74)。
语言标引法是指对被标引对象进行句法分析和语义分析,从而达到自动标引的目的,但章成志认为语言标引法还应当包括词法分析和篇章分析(75)。
人工智能是计算机科学的一个分支,旨在研究如何利用计算机设计一种系统来模仿人类智能系统的活动。人工智能标引法的目的是让计算机模拟标引员完成文献的标引工作。
人工智能在标引中的具体应用技术是专家系统,它将特定领域专家的知识经验通过编程组织成知识库,为他人在解决相应问题时提供借鉴和使用。专家系统的知识表示方法主要有产生式表示法、语义网络表示法和框架表示法。
与自动标引的其他方法相比,人工智能法尽管复杂,但它从标引员思维的角度模拟了标引员的标引过程,能够比其他自动标引方法获得更为理想的标引效果。虽然目前这方面的技术还处于试验阶段,不够成熟,但可以说人工智能标引法是汉语自动标引技术发展的必然趋势。
近几年来,人们对基于集成学习的标引方法、基于词平台汉字编码的自动标引方法和基于关联概念空间的自动标引方法进行了研究。
集成学习是通过利用多个学习器来解决同一个问题,即构建多分类器进行自动标引的方法,又称为组合方法。由于使用多个学习器解决同一问题比单个学习器具有更强的泛化能力,因此这种方法受到了机器学习界的广泛重视,成为当今机器学习的四大研究方向之首。国内学者对这一方法也进行了介绍并试验,如章成志曾将基于集成学习的自动标引方法进一步分为基分类器不加权集成学习标引与基分类器加权集成学习标引的方法进行试验和测评,结果表明基于集成学习方法的自动标引,利用各种标引模型进行投票表决方式的自动标引,能提高标引结果的查准率和召回率,其效果由于基分类器未加权集成学习标引的结果(76)。
基于集成学习的标引方法是自动标引方法发展的方向之一,这种标引方法已经引起了国内学者的极大关注和深入研究。
集成学习标引方法从“词”的角度出发,在计算机内采用以词为基本单元的表达方法,对每个词进行编码,将汉语文章中的词汇用四字节码字的形式表示出来,每四字节代表一个完整意义的词,标引时根据需要直接抽取出能表示文章内容的词。
基于词平台汉字编码的自动标引方法,是近两年来计算机领域的学者提出的一种新的自动标引方法。专家认为,目前大多数中文信息处理研究都是基于字平台的,而由于汉语结构的特殊性,自动分词的切分问题依然存在,并且遇到了瓶颈,而理想的自动标引,需要准确找出关键词,并通过对关键词的分析处理,析出主题概念,挑选出相关标引词,这样才可以称为是完全的自动标引。
目前对于这一方法的研究还处于初级阶段,一些学者从文章标题的关键词抽取开始进行了初步研究,取得了良好的效果,可以说这种基于词平台汉字编码的自动标引方法开拓了一种自动标引方法的新理念,值得今后进一步予以研究。
概念空间是由情报学专家G.Salton在其经典著作《现代信息检索》中首先提出的,是指某一领域中概念的集合及这些概念之间的语义关联度。应用这种方法的系统需要自动构建关键词-主题词概念空间,然后将待处理文本经过预处理后,用停用词表、关键词表、主题词表分别对其进行分词,统计词频并结合出现位置、词长进行加权,得到关键词集合和主题词集合;再利用已经建立的关键词-主题词概念空间,根据关键词-主题词的对应,将关键词集合向主题词集合中筛选出权值较高的一组主题词作为自动标引的结果。
这种方法还处于试验阶段,但从试验结果来看,应用该方法的系统标引结果与人工标引结果一致性较好。
6.3 自动标引系统与应用
自动标引研究自开始以来,虽然人们对其效果的评价一直不高,认为“绝大多数自动标引系统始终未能走出实验室大门,投入使用”。(77)但自动标引一直在研究改进中。目前,我国的自动标引研究已经进入了实用性研究阶段,基于多种方法、载体的自动标引系统不断得到开发。
《中国图书馆分类法》(《中图法》)知识库是南京农业大学信息管理系近年来开发的一种知识组织系统,或称为用于自动标引和分类的专家系统,它建立在《中图法》的基础上,利用机器统计归纳出众多人工标引记录中所凝结的标引经验,通过分类检索语言、主题检索语言、自然语言之间的兼容互换原理,建立分类号、主题词、关键词之间的概念对应关系,从而实现对文献的自动标引和自动分类,进而实现概念检索(78)。
《中图法》知识库将情报语言学的方法与计算语言学的方法结合起来,通过对大规模语料库的统计分析,利用计算机进行自动编制,克服了人工标引时可能产生的种种弊端。它以《中图法》为主干构建,却又比《中图法》具有更为广泛的功能。《中图法》知识库利用抽词词典和停用词表进行分词,并借助同义词表进行主题规范,可以实现中文信息的主题自动标引;借助分类号-关键词串对应表、同义词表,以及地名表、时代表、文献类型表可以实现文献信息的自动分类;在自动标引和自动分类结果的基础上,结合同义词表,可以实现中文文献信息的概念检索和多途径检索。
目前,这一知识库系统已经能够成功地应用于网页和期刊论文的自动标引和自动分类,图书的应用尚在试验当中,可以说这一自动标引系统有很好的发展前景。
基于多因子综合算法的自动标引系统是在西文环境下,试图将信息检索技术、文本自动标引技术、数据库技术相互结合应用于知识库的设计,并以此为基础设计一个适用于Web半结构化文档的外国教育信息知识库系统的自动分类标引器。这一系统试图对网页资源进行面向主题的信息标引,并以此来提高Web挖掘的效率,实现个性化的Web概念挖掘(79)。
该系统以特征词抽取模块和文本标引模块作为系统的核心部分,以词频、反文献频率因子、位置因子作为标引加权因子,通过一系列标引算法,以实现系统自动标引的目标。
目前该系统也处于试验阶段,但在试验过程当中,研究者发现,除了还需进一步完善信息类定义,改进特征词抽取算法等问题,整体的试验结果和效果均达到了比较令人满意的程度。
自动标引不仅仅是图书情报领域的研究对象,如今很多学科领域都已经看到了自动标引的优势所在,纷纷开始了相关研究,开发应用于本学科的自动标引系统。
张敏将改进的MM算法应用在生物学文献领域的自动分词中,通过在生物学文献的自动分词过程中引入正向匹配算法和逆向匹配法,实现了对生物学文献的自动分词,并以此为基础,实现了基于词典的生物学文献的自动标引系统,为词典切分标引法在生物学文献领域的应用提供了范例(80)。
顾燕萍、侯汉清、王晓红对中文图书进行自动标引和分类的实验主要是基于《中图法》知识库的中文信息自动标引和自动分类系统,对中文图书进行计算机自动标引与自动分类、人工打分测评、测试结果统计分析,并对中文图书各个标引源的主题表达能力进行加权设计。通过对此研究,发现基于《中图法》知识库的自动标引和分类系统,如果能够针对图书的特点对系统稍加改进,其用于图书的自动标引和分类是可以的(81)。
对中文期刊论文的自动标引研究主要集中在自动标引的加权设计方面,专家们经过试验研究,得出期刊论文标引源的主题表达能力先后次序为:文摘(Wz)>题名(Tm)>关键词(Gjc)>首段(Sd)>尾段(W d)>参考文献(Ck)>第二段(D2)>倒数第二段(d2),其加权值为5∶5∶5∶4∶4∶3∶2∶2(82)。
6.4 网络信息资源的自动标引
随着信息技术的迅猛发展,互联网已经逐渐成为世界上最大的信息资源宝库,给人们的生活、工作带来巨大的改变和影响。与传统信息资源相比,网络信息资源具有广泛的可存取性和易用性的优势,但另一方面由于其数量巨大、动态性强、缺乏组织和质量控制,加之检索技术落后,已导致出现网络信息无限、无序、优劣混杂、利用率不高的发展态势。随着用户对高质量网络信息的需求不断扩大,如何高效率地组织管理网络信息,为用户提供准确、方便、快捷的信息检索服务已经成为目前研究开发的重点。
对网络信息进行标引是实现这一目标的有效方法。研究行之有效的自动标引工具,对大量的网络信息进行甄别,去其糟粕取其精华,可以大大提高用户利用网络信息资源的效率。另一方面,网络环境也使得自动标引研究产生了一些新变化,对自动标引的发展提出了一些新要求。当前,除了对于自动标引方法进行一些传统的研究外,诸如网络信息自动标引的对象研究、网页标引源主题表达能力研究、人机结合的自动标引研究、中文互联网导航系统标引研究等问题,也成了网络环境下自动标引研究的热点课题。
吴凌星提出了网络环境下中文文本的过滤信息分流机制,认为信息分流是在过滤系统对多个用户进行信息过滤服务时,将具有相同或相似信息需求的用户合理地组织在一起,使其公共信息部分得到最大限度的体现,依据这些需求将文本分流,达到提高效率的目的(83)。这种分流机制对有效地进行文本的自动标引可以起到较好的作用,这也是目前吸引学者们予以研究的热点。
侯汉清、章成志、郑红对网页文本标引源的主题表达能力进行了相关的研究,他们将网页的12个标引源分为:网页题名(title项),文章标题(bt),第一段首句(ds1),第一段尾句(dw1),第二段首句(ds2),第二段尾句(dw2),第三段首句(ds3),第三段尾句(dw3),首段(sd),尾段(wd),其他段(qt,即除sd、wd,并且不包括ds2、ds2、dw2、dw3之外的文本其他部分)、html标记(html)。并得出结论:①题名具有很强的主题表达能力。Sd、html项也在第一等级,也具有较强的主题表达能力。②网页的title项主题表达能力有限。③html标记项对Web概念挖掘有重要意义。④每段的首句的主题表达能力强于该段的尾句。⑤首段相对尾段和其他段相比,具有较强的主题表达能力。12个标引源的主题表达能力的先后顺序为:bt>html>sd>ds1>title>dw1>qt>wd>ds2>dw2>ds3>dw3,位置权重方案为5∶5∶5∶4∶4∶4∶2∶2∶2∶2∶2∶2(84)。在作者的Web文本挖掘系统中,进行加权对比试验表明,此权重方案优于前人的方案。
7 关于本体的研究
本体是共享领域知识的明确、规范的说明,用于共享、交流和重用,主要供机器使用,并可用数学方式表达。自引进以来就已成为知识组织、语义网、人工智能等多个领域的重要课题。近年来,业内学者根据网络信息组织和检索中的问题,就本体相关理论、本体构建、本体相关技术、本体与其他知识组织方式的比较研究和互操作等进行了广泛的探讨。
7.1 本体相关理论
随着本体研究的不断深入,研究者们尝试从宏观角度、全局视野把握本体。邹瑾从情报语言学视角对本体进行了考察(85),认为情报检索语言的发展趋势是:①语义性的加强。从潜在向清晰发展,从非形式化向形式化发展,从面向人的处理过程向面向机器的发展。②使用主体范围的扩大。③情报检索趋向于“无形”。它有两层含义,一方面检索语言的载体形态或物理状态趋向于“无形”;另一方面,语言工具在检索系统中逐渐透明化,其作用发挥从前台转向后台,有利于用户使用自然语义与检索系统进行交互。④概念关系模型的清晰化和概念关系推理。⑤共享和兼容。本体的发展是以上趋势的具体体现。
既有的本体分类方法中,存在将本体分为顶级本体、领域本体、任务本体和应用本体的四分法和将本体分为知识表示本体、普通本体、顶级本体、元(核心)本体、领域本体、语言本体、任务本体、领域-任务本体、方法本体和应用本体的十分法。马文峰、杜小勇认为,上述两种分类方法存在内容上的交叉性和概念上的模糊性,因此应该删汰繁芜,主要关注领域本体和通用本体,领域本体面向应用并针对特定学科领域或特定社会领域,通用本体处于各领域本体的顶层,在整合各领域本体使多个领域本体成为一个整体的过程中发挥整合器的作用。本体的功能是为实现资源一体化的整合奠定基础,使得领域知识可以重用和共享,实现基于语义的检索。在语义网时代,本体正担负起知识组织的重任(86)。
7.2 本体构建
本体构建的工具与方法一直是本体研究的热点所在。本体构建工具的比较与选择,本体构建素材的提取与优化,本体构建方法的评估都在讨论之列。
李景介绍了5种主要的本体构建工具(87):Ontolingua、Ontosaurus、WebOnto、Protégé2000和OntoEdit,认为它们都存在如下问题:①当前的本体构建工具一般不提供通用的概念/类的体系。②各有不同的本体导入和输出格式,缺乏统一的Web标准。③绝大多数的工具都具有不同程度上对系统环境及软件版本的依赖性。④不同工具构建的本体无法相互兼容,并且在异构系统中无法被复制使用。⑤构建工具的使用与基于本体的专家系统、检索系统以及机器翻译系统的改造换代脱节,使得本体的应用和构建脱节,导致生成的本体缺乏“生命力”。要解决这些问题,还有待于出现一种标准化工具,提供通用概念体系和常识库,具有符合Web标准的统一的输入输出语言,在人工智能领域和知识表示领域广泛应用,得到领域专家和IT专家的认可。
有研究者认为,现行条件下比较理想的本体构建模式是采用人工干预的半自动方式。由领域专家给出领域的上层知识模式,通过机器学习技术从领域预料中学习等级关系和相关关系,在这一步骤中可以借鉴图书馆学中叙词表和分类表的编制技术以及机器学习中的自动技术。获取相关关系的方法有:①共现统计算法;②关联规则算法;③隐含语义索引;④Hopfield联想算法。获取等级关系的方法有:①聚类算法;②字面成族;③模式组配。将软件工程中面向对象的建模技术引入本体的构建,为本体模型构建提供一套规范科学的管理流程,从而提高本体的复用和更新效率,引入的构建原则有:①完整性和充分性;②原始性;③高内聚;④低耦合(88)。
李光达、常春认为,概念是本体的核心,获取本体概念的方法有(89):从叙词表获取,从专业词典或专业书籍的术语表(Glossary)中获取,复用领域本体或顶级本体如Cyc本体、M ikrokosmos本体、PENMAN本体、SUMO本体,从《中国图书馆分类法》获取,从领域论文的关键词中获取,由搜索引擎获取和对核心文章作词频分析提取。这些方法各有其适应范围。叙词表和专业词典系统性较好,适合初始构建;专业术语表和《中国图书馆分类法》可作为补充;复用领域本体和顶级本体既可搭建初始框架,也可从宏观角度重新对本体进行检视;通过搜索引擎能补充最新概念,使领域本体和领域知识同步更新。
朱晓冰、寇雅楠建议使用Platypus等语义维基系统作为构建领域本体的平台,吸取维基百科的成功经验和精神理念,增强本体建构的开放性,由领域专家、知识工程师和大众共同参与,促进本体知识的集成、共享和重用(90)。
董慧、聂曼曼讨论了半自动构建中文本体的方法和思路(91)。在构建本体过程中,应重视素材的选择。素材选择原则有:①结合领域特征和项目需求,善用用户提供的数据;②优先选择结构化程度高的数据;③考虑结构化程度的同时应考虑与领域需求的匹配程度。基于结构化知识源构建本体库主要指用关系数据库建立本体。半结构化知识源则有XML/HTML文件、词表和知识库等。对于XML文件文档,首先分析其标签结构,然后与本体库的类属结构进行映射,添加实例和属性值的工作用Jena等工具完成。词典的结构非常利于生成本体三元组,但类属结构的确定仍需人工干预,知识库的情况与之类似。基于纯文本构建本体库,难点在于中文自然语言处理技术尚不足以生成无歧义的描述,在对素材做出较严格的限制后,可由领域专家手动建立本体的类属结构,再通过模式匹配添加实例和属性值。通过半自动建库方式构建本体,能够充分利用现有资源,节省人力成本。
7.3 本体相关技术
在本体的生命周期之中,本体的构建、管理、评估、改进都依赖于本体相关技术的发展。本体技术的改进和完善还有待于更多参与和贡献。
“国共合作”本体是武汉大学信息管理学院董慧主持开发的大型历史领域本体,马费成、罗志成、曾杰在此基础上使用计算语言学中的相似度度量方法结合真人判断结果进行测评。具体进行的实验方法有:①基于释义重叠法的实验,实际实验中又分为最大串匹配、分词后词语计算重叠词语数量和将属性分割为子释义进行计算;②基于树状结构的实验,利用概念的结构特点如最短路径长度、概念在树状结构中的深度进行计算,实际实验中选择了Wu-Palmer算法和Leacock-Chodorow算法;③对比实验包括:使用哈尔滨工业大学《同义词词林》扩展版做相似度计算、使用Google度量成对概念的共现频率、使用“国共合作”数字图书馆系统(GGHZ-DL)自带的“深度”功能。为评价以上方法,实验者人工挑选了30对“国共合作”本体中的节点,由51名受试者对成对节点作相关程度的主观判断并取平均值,使用SPSS求得各度量方法与真人判断结果的相关系数。实验的结论是:《同义词词林》包含的知识为通用知识,无法用来测度领域知识;用Google测度概念共现频率的问题在于搜索引擎返回的结果数是估计值,精确度不足;利用树状结构的方法结果较差;释义重叠法中最大串匹配的方法优于分词后计算和分割属性的方法,效果最佳(92)。实验所使用的释义重叠法与真人判断结果的拟合度较好,优于本体推理所得的结果,有助于优化本体检索结果排序,同时这一方法也将有助于本体的半自动建库。
有研究者从本体管理的角度对Ontolingua、Starlab ontology server、ACOS、KAON、OWS、FIPA ontology server 6种本体服务器进行了调查,包括浏览方式、编辑权、存储体系、复用机制、管理工具等多个方面(93)。大部分本体服务器提供层级浏览和有限的推理。编辑权方面,ACOS颇具特色,所有参与者都被纳入“共同体”(community),各用户在知识领域内的贡献由系统自动计算打分,并依此得出用户的权重分值(users'importance score),决定各自不同的编辑权限。本体服务器在存储体系上的差异较大,首先体现为所使用的本体语言不同,其次存储量级有轻重之分。存储方式上,Ontolingua和ACOS采用文件存储,Starlab ontology server采用数据库管理系统方式,KAON兼而有之,OWS特有的输入(input)机制可视为一种文件存储,FIPA则采用Ontology Agent(OA)。复用机制方面,Ontolingua支持10种表示语言,KAON有丰富的API,OWS延续了其灵活性。综合各方面因素,重量级存储方式更利于本体系统的互操作,采用数据库和Java平台是本体存储和管理的未来趋势。
7.4 比较研究和互操作
业内学者对本体与叙词表、分类法、Folksonomy的共同点和不同点进行了广泛而深入的探讨。其中,叙词表和本体的比较研究及两者之间的互操作尤为研究者所关注。
赵焕洲、唐爱民认为叙词表和本体的不同点表现在组成要素、逻辑表达形式、组织结构、形式化、词间关系、表示语言、构建方法等方面(94)。本体具有广阔的发展前景,但需要解决构建的成本问题。
李金定研究了本体与元数据的互补关系。元数据和本体的共同之处在于:都可以采用标准的编码语言进行形式化处理,因而能为资源提供语义基础,可用于资源组织和知识发现。其差异表现在元数据难以对不同知识体系、不同粒度的资源进行描述,而本体则提供了不同元数据间的相互映射机制,可实现异构系统之间的互操作(95)。
王翠英对本体与Folksonomy进行了比较研究(96)。本体与Folksonomy的共同点有:①二者都是一种分类方法;②二者都是共识,而非个人的知识;③二者都以提高检索效率为目的。本体与Folksonomy的区别是:①结构。本体强调概念的类级关系,用父类—子类(Class-subclass)显示概念之间的形式化关系,Folksonomy的类目是非等级的。②创建者。本体的创建依靠领域专家和开发人员。Folksonomy依靠系统用户。③同义词控制。本体进行控制,而Folksonomy不进行控制。④准确性。本体准确性高,Folksonomy存在语义的模糊。⑤灵活性。本体灵活性低,维护需要专业知识与权限,Folksonomy便于普通用户维护。⑥成本。本体创建成本高,而Folksonomy创建成本较低。⑦变化程度。本体相对来讲较为刚性,而Folksonomy非常动态,不断变化。⑧可用性。本体需要学习,而Folksonomy不要求用户预先学习专门的知识和技能。⑨可测量性。本体在小范围内操作性好,Folksonomy在大范围内操作性好。
有研究者分别用Taxonomy和Folksonomy与Ontology进行比较(97)。Taxonomy和Ontology都是概念和概念关系的集合,都具有相对严格的规范,其基本功能是一致的。在体系结构方面两者明显不同,单一树状体系的Taxonomy难以修订,Ontology的词间关系更为丰富,而且其词间关系是网状的。Folksonomy基于大众的共享和协作,Ontology需要领域专家与系统开发人员的合作。Folksonomy是非形式化的,包含稀疏语义,Ontology是形式化的,包含丰富语义。Folksonomy为Ontology的构建提供了一个新的角度。
孙兵从逻辑表达形式、组织结构、关系描述、结构性能、功能描述和交互功能等方面对分类表、叙词表和本体进行了综合比较(98)。相对分类表和叙词表而言,本体对概念间关系的揭示更为广泛、深入、细致和全面,具有推理功能,能在一定程度上实现人与机器之间的知识交互,因此在知识表示、关系描述、性能和功能等方面具备明显优势。
有研究者提出将《中国分类主题词表》自动转换为SKOS描述形式,并进行了具体实践。SKOS为传统知识组织系统(叙词表、分类表、术语表等)提供了一套语义Web环境下简单灵活的描述和转换机制,作为一种知识描述语言,SKOS语言比OWL本体描述语言更简单,且又非常容易扩展。《中国分类主题词表》是我国目前规模最大的分类主题一体化标引工具。SKOS非常适用于《中国分类主题词表》网络改造。研究者使用Java程序从《中国分类主题词表》电子版的HTML文件中提取主题词、词间语义关系、分类号和注释等,存储到关系数据库中,包括族首词表、词族表和语义关系表(用、代关系和相关关系),最后通过SQL语言中数据库中提取字段,并用Java语言写入SKOS描述的对应标签。选择《中国分类主题词表》的F类(经济)、Q类(生物科学)、X类(环境科学、安全科学)3个类目的词条进行自动转换实验,生成的代码完全符合SKOS语法要求。该实验为其他受控词表的自动转换提供了参考(99)。
通过对本体研究进展的回顾,笔者认为应从以下几个方面拓展本体的研究与应用:
善用传统知识组织系统,并灵活引入新方式。本体与传统知识组织系统如分类表和叙词表不是替代关系而是共生关系,分类表和叙词表是构建本体的重要资源。同时,Folksonomy也为本体的构建提供了大量素材,基于Folksonomy构建的本体对其他领域本体的评估和优化亦有裨益。
《中国分类主题词表》应继续向网络化方向发展,在现有SKOS转换实验的基础上进一步加以完善,提供如同LCSH网络版一样的语义服务,使本体在海量网络信息的组织中发挥作用。同时,应发展卫星词表,并在此基础上积极开发领域本体。
分布式本体的构建,多语言本体的构建,本体的全自动化构建,对既有领域本体的深入的计量分析,这些都有待于我们继续探索。
8 结 语
主题检索语言是完全建立在自然语言基础之上的一种情报检索语言,在一个多世纪的发展历程中,曾经有过辉煌,尤其在20世纪后半叶,一度成为信息组织的主流方法。计算机技术的应用和网络技术的普及,既为主题检索语言提供了推广应用的平台,也对主题检索语言提出了挑战。当自然语言“回归”,用户的信息需求和检索方式发生变化时,包括主题检索语言在内的受控语言受到质疑,同时,也引起业内人士的高度关注。近年来,人们在寻求情报检索语言更佳结合模式的过程中,对受控语言和自然语言的性能、特征进行比较研究,发现两者在信息检索领域都有各自性能上的优势,不可能完全取代对方,而受控语言与自然语言的发展趋势应当是两者的互相结合,甚至达到完全融合的状态。
主题语言来自自然语言,具有自然语言的某些特征;主题语言优于自然语言,它是一种受控的情报检索语言,通过字顺及词间关系的显示方式为用户提供检索查询服务。随着网络技术的发展,业内对主题检索语言的研究更加深入,主题检索语言的研究领域更加广泛,涉及分类主题一体化、受控语言与自然语言结合或融合、自然语言检索及自动标引、主题语言在网络信息组织中的应用以及叙词表与本体等。实际上,主题语言已不仅仅是标引查词的工具,而逐渐成为网络信息资源的一部分,并运用到构建知识组织系统之中,因而对主题检索语言的研究是信息组织领域一个长期的重要课题。
【作者简介】

张燕飞,男,1950年9月出生,武汉大学信息管理学院图书馆学系副教授。主要研究方向为:信息组织与管理。主讲“文献分类法与主题法”、“连续出版物管理”、“信息产业概论”等课程。曾荣获湖北省教学科研成果三等奖。参加过《中国图书馆图书分类法》(第2版)索引、《服装主题词表》的编制,《中国科学院图书馆图书分类法》(第3版)的修订,发表学术论文多篇,编写(含参编)著作多部。
刘元珺,武汉大学信息管理学院硕士研究生。
孙珑琦,武汉大学信息管理学院硕士研究生。
【注释】
(1)张燕飞,傅晓燕.近五年来国内主题法研究综述[J].高校图书馆工作,2008(2):22-26.
(2)邱桂梅.主题语言在网络信息组织与检索中的应用[J].现代情报,2005(2):152-154.
(3)康艳,张虹,侯汉清.情报检索语言不是“明日黄花”[J].图书情报工作,2007(10):139-142.
(4)刘竟,侯汉清.情报检索语言与主题网关[J].新世纪图书馆,2005(1):30-33.
(5)崔瑞琴,孟连生.数字信息资源整合问题研究[J].图书情报工作,2007(7):35-37,70.
(6)[美]兰开斯特著.情报检索词汇控制[M].侯汉清,等译.上海:同济大学出版社,1992.
(7)侯汉清,刘华梅,郝嘉树.60年来情报检索语言及其互操作进展[J].图书馆杂志,2009(12):2-13.
(8)张琪玉.情报检索语言的若干研究心得和收获——张琪玉学术思想自述[J].图书情报工作,2009(10):5-9,29.
(9)侯汉清.建立以《中国分类主题词表》为核心的检索语言兼容体系[J].北京图书馆馆刊,1998(4):35-39.
(10)李育嫦.国外情报检索语言互操作研究:模式、方法及启示[J].图书馆,2009(1):43-45.
(11)刘华梅,侯汉清.叙词表互操作技术研究——教育集成词库的试验[J].中国图书馆学报,2008(9):95-99.
(12)司莉.知识组织系统的互操作及其实现[J].现代图书情报技术,2007(3):29-34.
(13)陈红艳,司莉.网络叙词表构建的现状调查与分析[J].图书馆理论与实践,2008(5):33-36.
(14)曹树金,郭菁.网络叙词表的组织结构及优化模式研究[J].图书情报工作,2005(3):31-35.
(15)曹树金,郭菁.网络叙词表的组织结构及优化模式研究[J].图书情报工作,2005(3):31-35.
(16)陈红艳,司莉.网络叙词表构建的现状调查与分析[J].图书馆理论与实践,2008(5):33-36.
(17)曹树金,郭菁.网络叙词表的组织结构及优化模式研究[J].图书情报工作,2005(3):31-35.
(18)侯汉清,刘华梅,郝嘉树.60年来情报检索语言及其互操作进展[J].图书馆杂志,2009(12).
(19)张敏,邓胜利.基于内容揭示的信息资源控制的演进[J].图书情报工作,2009(2):117-120.
(20)张琪玉.情报检索语言实用教程[M].武汉:武汉大学出版社,2004.
(21)杜慧平,侯汉清.网络环境中汉语叙词表的自动构建研究[J].情报学报,2008(6):863-869.
(22)曾建勋,常春.网络时代叙词表的编制与应用[J].图书情报工作,2009(8):8-11,16.
(23)曾建勋,常春.网络时代叙词表的编制与应用[J].图书情报工作,2009(8):8-11,16.
(24)杜慧,侯汉清.网络环境中汉语叙词表的自动构建研究[J].情报学报,2008(6):863-869.
(25)司莉,陈红艳.网络叙词表用户界面设计策略[J].现代图书情报技术,2008(5):14-20.
(26)陈树年,刘惠敏.从网络信息组织看《中国分类主题词表》[J].国家图书馆学刊,2006(2):21-27.
(27)侯汉清,李华.《中国分类主题词表》(第2版)评介[J].国家图书馆学刊,2006(2):15-20.
(28)国家图书馆《中国分类主题词表》编辑委员会.《中国分类主题词表》(第2版)编制说明[M].北京:北京图书馆出版社,2005.
(29)李青华,马然.从入口率和参照度谈《中国分类主题词表》的修订[J].国家图书馆学刊,2006(2):28-31,58.
(30)侯汉清,李华.《中国分类主题词表》(第2版)评介[J].国家图书馆学刊,2006(2):15-20.
(31)陈树年,刘惠敏.从网络信息组织看《中国分类主题词表》[J].国家图书馆学刊,2006(2):21-27.
(32)侯汉清,李华.《中国分类主题词表》(第2版)评介[J].国家图书馆学刊,2006(2):15-20.
(33)国家图书馆《中国分类主题词表》编辑委员会.《中国分类主题词表》(第2版)编制说明[M].北京:北京图书馆出版社,2005.
(34)卜书庆,贺玲勇.《中国分类主题词表》电子版研制概述[J].国家图书馆学刊,2006(2):10-14.
(35)侯汉清,李华.《中国分类主题词表》(第2版)评介[J].国家图书馆学刊,2006(2):15-20.
(36)朱芊.《中国分类主题词表》电子版文献标引分析[J].国家图书馆学刊,2006(2):32-36.
(37)黄星亮.利用《中国分类主题词表》电子版标引文献的技巧[J].图书馆学刊,2009(8):83-84,103.
(38)刘英杰.《中国分类主题词表》(第2版)电子版在文献标引中的使用价值及修改意见[J].农业图书馆情报学刊,2008(5):51-53.
(39)李楠.关于使用《中国分类主题词表》电子版标引文献若干问题分析[J].图书馆建设,2009(11):44-46,51.
(40)卜书庆,汪东波.网络时代《中国分类主题词表》的发展与应用[J].图书情报工作,2005(7):25-28.
(41)侯汉清.新闻信息数据库后控词表的设计与编制[J].江苏图书馆学报,2000(2):12-16.
(42)薛云,叶冬毅,张文德.基于《中国分类主题词表》的领域本体构建研究[J].情报杂志,2007(3):15-18.
(43)任瑞娟.基于《中国分类主题词表》构建分布式Otology[J].情报杂志,2008(8):23-25.
(44)陈树年,刘惠敏.从网络信息组织看《中国分类主题词表》[J].国家图书馆学刊,2006(2):21-27.
(45)戴维民主编.信息组织[M].北京:高等教育出版社,2004.
(46)张琪玉.网络信息检索用语言的发展趋势[J].图书馆杂志,2001(3):5-7,22.
(47)张琪玉.寻找更佳结合模式是情报检索语言创新的主流[J].图书馆杂志,2005(2):16-18.
(48)张琪玉.寻找更佳结合模式是情报检索语言创新的主流[J].图书馆杂志,2005(2):16-18.
(49)张燕飞.信息组织中的主题语言[M].武汉:武汉大学出版社,2005.
(50)戴维民.信息组织[M].北京:高等教育出版社,2004.
(51)朱丹.情报检索语言的自然语言化[J].情报探索,2005(3):3-4.
(52)刘华梅,侯汉清.自然语言转换为受控语言的语义工具——入口词表模块[J].情报科学,2007(1):93-96,112.
(53)李雅琼.自然语言检索的新发展:与Otology相结合[J].情报理论与实践,2007(2):248-251.
(54)焦玉英,张璐.基于Otology的语义检索模型构架[J].图书馆学刊,2006(6):112-114.
(55)耿骞,赖茂生.自然语言检索的实现及其关键问题[J].情报科学,2007(5):733-741.
(56)熊回香,夏立新.汉语分词技术综述[J].图书情报工作,2008(4):81-84.
(57)何莘,王琬芜.自然语言检索中的中文分词技术研究进展及应用[J].情报科学,2008(5):787-791.
(58)刘迁,贾惠波.中文信息处理中自动分词技术的研究与展望[J].计算机工程与应用,2006(3):175-177,182.
(59)孙铁利,刘延吉.中文分词技术的研究现状与困难[J].信息技术,2009(1):187-189,192.
(60)刘宁,柴雅凌.自然语言在智能信息检索中的应用[J].图书馆杂志,2005(10):47-51.
(61)Luhn,H.P..The Automatic Creation of Literature Abstracts[J].IBM Journal ofResearch&Development,1985(2):159-165.
(62)储荷婷.索引工作自动化:自动标引的主要方法[J].情报学报,1993(3):23-25.
(63)谢坤生.关于后四年索引工作趋向的几点思考[A]//中国索引学会第三次全国会员代表大会暨学术论坛论文集,105-108.
(64)苏新宁.信息检索理论与技术[M].北京:科学技术文献出版社,2004.
(65)章成志.自动标引研究的回顾与展望[J].现代图书情报技术,2007(11):33-39.
(66)许剑颖.统计分析法自动标引的改进研究[J].现代图书情报技术,2004(2):92-95.
(67)章成志.自动标引研究的回顾与展望[J].现代图书情报技术,2007(11):33-39.
(68)苏新宁.信息检索理论与技术[M].北京:科学技术文献出版社,2004.
(69)苏武华.汉语自动分词和自动标引方法研究[J].农业图书情报学刊,2004(7):103-105.
(70)许剑颖.统计分析法自动标引的改进研究[J].现代图书情报技术,2004(2):92-95.
(71)苏武华.汉语自动分词和自动标引方法研究[J].农业图书情报学刊,2004(7):103-105.
(72)许剑颖.统计分析法自动标引的改进研究[J].现代图书情报技术,2004(2):92-95.
(73)罗雪英.也谈单汉字标引[J].湘潭大学社会科学学报,2003(5): 212-214.
(74)彭冬莲.单汉字标引及其检索技术的优化[J].农业图书情报学刊,2005(4):61-62.
(75)章成志.基于集成学习的自动标引方法研究[J].中国索引,2009(2):16-23.
(76)章成志.基于集成学习的自动标引方法研究[J].中国索引,2009(2):16-23.
(77)张琪玉.情报检索语言的发展趋势.张琪玉情报语言学论文集[M].北京:北京图书馆出版社,1999.
(78)顾燕萍,侯汉清,王晓红.中文图书自动标引与分类加权设计研究[J].中国图书馆学报,2006(6):69-72.
(79)周霜菊,孙济庆.西文环境下基于多因子综合算法的自动标引系统研究与实现[J].情报探索,2007(1):51-54.
(80)张敏.生物学文献的自动标引系统的研究与开发[D].上海:东华大学,2006.
(81)顾燕萍,侯汉清,王晓红.中文图书自动标引与分类加权设计研究[J].中国图书馆学报,2006,(6):69-72.
(82)赵妍,侯汉清等.中文期刊论文自动标引加权设计研究[J].新世纪图书馆,2004(1):40-43.
(83)吴凌星.浅析网络信息自动标引[J].科技情报开发与经济,2005(20):84-85.
(84)侯汉清,章成志,郑红.Web概念挖掘中标引源加权方案初探[J].情报学报,2005(1).
(85)邹瑾.结合本体考察情报语言学的发展[J].图书情报工作,2006(1):68-71,92.
(86)马文峰,杜小勇.关于知识组织体系的若干理论问题[J].中国图书馆学报,2007(2):13-17,46.
(87)李景.主要本体构建工具比较研究(上、下)[J].情报理论与实践,2006(1):109-111,81;2006(2):222-226.
(88)何琳,杜慧平,侯汉清.领域本体的半自动构建方法研究[J].图书馆理论与实践,2007(5):26-27,38.
(89)李光达,常春.构建本体时获取概念方法研究[J].情报科学,2009(5):713-716,722.
(90)朱晓冰,寇雅楠.基于维基技术的本体构建方法探讨[J].图书馆学研究,2009(1):54-56.
(91)董慧,聂曼曼.中文本体的半自动构建研究[J].情报杂志,2009(11):146-149.
(92)马费成,罗志成,曾杰.知识相关度的计量研究[J].情报科学,2008(5):641-646,656.
(93)李睿.从“本体管理”的视角调查六种本体服务器[J].现代情报,2008(5):153-155.
(94)赵焕洲,唐爱民.对两种知识组织系统——叙词表与Ontology的比较研究[J].情报理论与实践,2005(5):469-471.
(95)李金定.叙词表、元数据与本体之间关系探究[J].图书馆学研究,2007(8):61-64.
(96)王翠英.本体与Folksonomy的比较研究[J].图书馆建设,2008(5)):85-88.
(97)岳爱华,孙艳妹.Taxonomy、Folksonomy和Ontology的分类理论及相互关系[J].图书馆杂志,2008(11):21-24.
(98)孙兵.知识组织工具的发展趋势浅析——基于分类表、叙词表和知识本体的比较研究[J].图书馆学刊,2009(11):86-88.
(99)刘丽斌,张寿华,濮德敏等.《中国分类主题词表》世纪SKOS描述自动转换研究[J].中国图书馆学报,2009(6):56-60.
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










