



(一)总体与样本
数理统计中,我们把“研究对象的全体”称为总体(population),而总体中的每个成员被称为个体(individual),因此,个体可能是人,也可能是动物或物体。总体中所包含个体数称为总体的容量。容量为有限的称为有限总体(finite population),容量为无限的称为无限总体(infinite population)。数理统计学要研究的并不是总体或个体的本身,而是描述总体的某些指标。
例6.1.1 现要研究某一个公司员工工资水平及其影响工资水平的因素。这个公司的每个员工就是一个“个体”,而所有员工构成一个“总体”。由于公司的员工总数是有限的,因此,是一个有限总体。每个员工都附着有年龄、性别、工种、工资、受教育程度等指标(变量),均为描述总体特征的指标。
为了采用数理统计方法对公司员工工资水平及其影响工资水平的因素进行分析,首先要收集个体的各个指标的数据,并一一列出,即得到数理统计分析、推断所需要的数据集。数据集是数理统计研究的基础,所以正确收集数据的方法应该是数理统计学习的开始。一般在收集数据前,我们必须明确研究范围,研究对象,并确定需要研究对象的具体特征等等。数据收集方法一般有两种。
(1)通过调查收集数据。如上面的例子中,我们要得到公司员工的“年龄、性别、工种、工资、受教育程度”这些资料,只要到公司的人事部门调出公司员工的档案,并一一记录就可以得到所需要的资料。有时也可以通过问卷调查得到所要的数据资料。
(2)通过实验收集数据。如为研究某种药物在血液中被吸收的情况,研究人员将这种药物注入24个人体内,注射后30分钟测量人体血液中的药物浓度。这种试验的目的是揭示出一些变量在其他变量变化时作出的响应。根据研究问题的需要,通常会将24个人分成几组(如三组),每组人的药物注射量不一样,由此收集到的注射后30分钟后人体血液中的药物浓度可以说明注射量对血液中药物浓度的影响。
在数理统计的课程中分别有“抽样方法”和“试验设计”两门课程专门研究如何正确有效地收集数据的方法。这里不作详细介绍。
总体的某个指标X,对于不同的个体来说有不同的取值,这些取值可以构成一个分布,因此X可以看成一个随机变量。有时候就把X称为总体。假设X的分布函数为 ,也称
,也称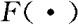 为总体。如果我们关心总体两个或两个以上的指标,可用随机向量
为总体。如果我们关心总体两个或两个以上的指标,可用随机向量 来表示。如上例中,采用X表示年龄,Y表示性别,Z表示工种,W表示工资,V表示受教育程度,即可用(X,Y,Z,W,V)表示总体。为了方便,今后不再特别区分总体和相应指标,均记为总体X,或总体
来表示。如上例中,采用X表示年龄,Y表示性别,Z表示工种,W表示工资,V表示受教育程度,即可用(X,Y,Z,W,V)表示总体。为了方便,今后不再特别区分总体和相应指标,均记为总体X,或总体 。在实际中,总体的分布一般是未知的,或只知道它具有某种形式,但其中包含着未知参数。数理统计主要任务是从总体中抽取一部分个体,根据部分个体的数据对总体分布给出推断。被抽取的部分个体叫总体的一个样本(sample),被抽取个体数称为样本容量。
。在实际中,总体的分布一般是未知的,或只知道它具有某种形式,但其中包含着未知参数。数理统计主要任务是从总体中抽取一部分个体,根据部分个体的数据对总体分布给出推断。被抽取的部分个体叫总体的一个样本(sample),被抽取个体数称为样本容量。
假设我们从总体X中随机地抽取n个个体,随着抽取的个体的不同,指标X的取值也不同,分别记为 ,称其为随机样本(random sample)。按不同的抽取方法可得到不同的随机样本。如果在抽取样本时,确保总体中的每个个体均有相同的被抽中的概率,即Xi可能是总体中的任意一个个体,从理论上看,Xi与总体X有相同的分布,进一步,假设每个个体独立抽取,则随机样本
,称其为随机样本(random sample)。按不同的抽取方法可得到不同的随机样本。如果在抽取样本时,确保总体中的每个个体均有相同的被抽中的概率,即Xi可能是总体中的任意一个个体,从理论上看,Xi与总体X有相同的分布,进一步,假设每个个体独立抽取,则随机样本 是简单随机样本(simple random sample)。简单随机样本
是简单随机样本(simple random sample)。简单随机样本 可以看成是相互独立同分布的随机变量。
可以看成是相互独立同分布的随机变量。
对所抽取的样本进行观察,得出一组实数: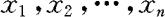 ,我们称
,我们称 为样本
为样本
 的一组观察值(或样本值)。综合上述,我们给出以下的定义。
的一组观察值(或样本值)。综合上述,我们给出以下的定义。
定义6.1.1 设总体X是具有分布函数 的随机变量,
的随机变量, 是来自总体X的随机样本。若满足
是来自总体X的随机样本。若满足
(i) 是相互独立的随机变量;
是相互独立的随机变量;
(ii)每一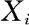 与总体X有相同的分布函数;
与总体X有相同的分布函数;
则称 为取自总体X的简单随机样本。为方便计,本书以后提到的“样本”均指的是简单随机样本。
为取自总体X的简单随机样本。为方便计,本书以后提到的“样本”均指的是简单随机样本。
如果总体的分布函数为F(x),则根据上述定义,样本的联合分布函数为:
如果总体的概率密度为f(x),则样本的概率密度为:
注 对于有限总体,采用放回抽样就能得到简单随机样本。但当总体容量很大的时候,放回抽样有时候很不方便,因此在实际中当总体容量比较大时,通常将不放回抽样所得到的样本近似当作简单随机样本来处理。对于无限总体,一般采取不放回抽样。
(二)统计量
样本是进行统计推断的依据。在获得了样本之后,下一步就要对样本进行统计分析和对总体进行统计推断,即对样本进行加工、整理,从中提取有用信息,并根据这些信息对总体作出推断,例如,假设流水线上生产的产品的重量服从正态分布 (参数
(参数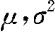 未知),现从生产流水线上抽取样本,其重量为
未知),现从生产流水线上抽取样本,其重量为 ,我们可以计算它们的平均值
,我们可以计算它们的平均值 ,用
,用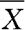 作为总体均值μ的估计。这里
作为总体均值μ的估计。这里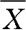 是样本
是样本 的函数,称为统计量(statistic)。
的函数,称为统计量(statistic)。
定义6.1.2 设 是来自总体X的一个样本,
是来自总体X的一个样本, 是样本
是样本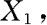
 的函数,若g中不含未知参数,则称
的函数,若g中不含未知参数,则称 是一统计量。
是一统计量。
由于统计量是样本的函数,不包含任何的未知参数,所以一旦有了样本观察值,就可以算出统计量的值。在统计学中,根据不同的目的可以构造出许多不同的统计量。下面是几种常用的重要统计量。
1.样本平均值
2.样本方差
3.样本标准差
4.样本k阶(原点)矩
5.样本k阶中心矩
对于上面的几个常用的统计量,作如下的说明:
(1)一般,用样本均值 ;作为总体均值μ的估计;用样本方差S2作为总体方差σ2的估计;用样本原点矩Ak(样本中心矩Bk)作为总体原点矩产μk、(总体中心矩Vk)的估计。
;作为总体均值μ的估计;用样本方差S2作为总体方差σ2的估计;用样本原点矩Ak(样本中心矩Bk)作为总体原点矩产μk、(总体中心矩Vk)的估计。
(2)总体方差的估计可以用S2也可以用B2,主要的区别是S2作为总体方差估计是无偏估计,但B2作为总体方差的估计是有偏的(关于估计的无偏性我们将在下一章讨论)。
(3)总体的任一个未知参数可以有多个不同的估计,因此,参数估计不唯一
(4)假设 是一个从总体X中抽取的简单随机样本,假设
是一个从总体X中抽取的简单随机样本,假设 存在,由辛钦大数定律可知,
存在,由辛钦大数定律可知,
进一步,如果 是一个连续函数,由依概率收敛的性质,
是一个连续函数,由依概率收敛的性质,
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











