



【摘要】:11.1.2 训练样本数量对自动分类的影响分析冯是聪对训练样本的最佳数量进行了实验,得出结论是最小样本数是在15个[1]。对此本系统采用15个为起点,分别将训练样本增加至50、100、150、300及以上进行分类测试(其中测试集保持不变,均为每类50篇文本。可见训练集的规模对分类系统的性能有一定影响。
训练样本数量对自动分类的影响分析_文本自动标引与自动分类研究
11.1.2 训练样本数量对自动分类的影响分析
冯是聪对训练样本的最佳数量进行了实验,得出结论是最小样本数是在15个[1]。对此本系统采用15个为起点,分别将训练样本增加至50、100、150、300及以上进行分类测试(其中测试集保持不变,均为每类50篇文本。本次测试以向量距离法为分类器进行,特征选择采用TF-IDF,测试语料为ChinaInfoBank),结果如图11-1所示。
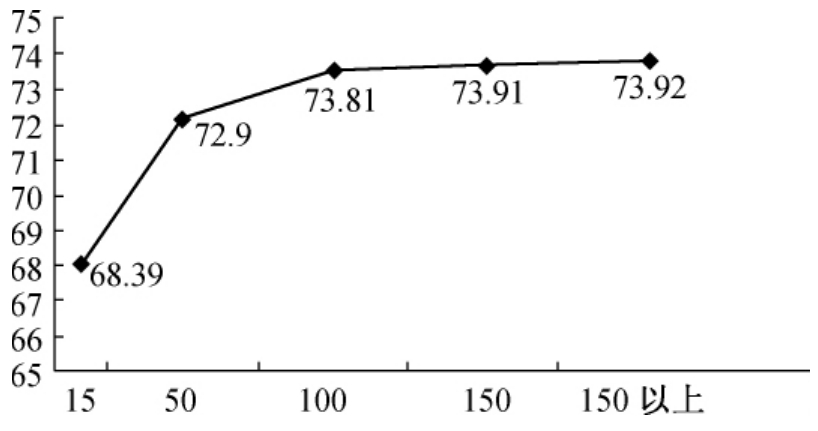
图11-1 不同训练样本的分类结果对比
从图11-1中可以看出,除了在训练语料从15篇到50篇增加时,正确率有较大幅度增长(从68.39%到73.92%),在随后的语料增加中,正确率已基本趋于稳定,保持在73%左右。可见训练集的规模对分类系统的性能有一定影响。随着训练规模的增大,分类性能逐渐改善,但是到了一定的规模后分类性能变化不大,并保持在一个较稳定的值上。
有一点也必须注意,就是当训练规模增大时,虽然对分类性能有所改善,但是训练时间也成倍增加,相应特征项潜在增加,分类时间也会加大。所以在实际应用中应综合考虑分类性能和时间要求。
如果将语料增加的幅度值变小,可能会更好地看出其变化情况。因数据收集原因,本书在选择训练集时,不同类目的训练文本数有一些差别,多的为400条(上限),最少的也有119条以上,因此本系统所用语料库的数据量的差异不会对分类效果造成影响。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











