



21.2.2 自适应动态规划
为了利用状态间的约束,智能体必须学习状态之间的联系。一个自适应动态规划(或缩写为ADP)智能体通过在运行中学习环境的转移模型来工作,并且运用动态规划方法求解相应的马尔可夫决策过程。对于一个被动学习智能体而言,这意味着把学到的转移模型T(s, π (s), s' )以及观察到的回报R(s)代入到贝尔曼方程(21.2)中,计算状态的效用。如在第十七章中我们关于策略迭代的讨论谈到的,这些方程是线性的(没有取最大值),所以可以使用任何线性代数工具进行求解。作为另一种选择,我们还可以采用改进的策略迭代方法(参见第 17.3 节),在每一次对学习到的模型进行修改之后,利用一个简化的价值迭代过程来更新效用估计。由于每次观察后该模型通常只发生轻微的变化,价值迭代过程可以将先前的效用估计作为初始值,并且应该收敛得相当快。
由于环境是完全可观察的,因而学习模型本身的过程是容易的。这意味着我们面临一个有监督的学习任务,其输入是一个状态-行动对,而输出是结果状态。在最简单的情况下,我们可以将转移模型表示为概率表的形式。我们记录每个行动结果发生的频繁程度,并根据该频率对当在状态s执行a后能够达到状态s'的转移概率T(s, a, s')进行估计[28]。例如,在第21.2节中给出的3条行进路线中,在状态(1, 3)上Right被执行了3次,其中2次的结果状态为(2, 3),所以T((1, 3), Right, (2, 3)) 被估计为2/3。
一个被动ADP智能体的完整智能体程序如图21.2所示。其在4 × 3世界中的性能表现如图21.3所示。就其价值估计的改进速度而言,受限于它学习转移模型的能力,这个ADP智能体的表现已经是尽可能地好了。在此意义上,它提供了一个用以度量其它强化学习算法的标准。然而对于大规模的状态空间来说,它多少是有些不可操作的。例如,在西洋双陆棋游戏中,将涉及处理大约1050个未知量的1050个方程。

图21.2 一个基于自适应动态规划的被动强化学习智能体。为了简化代码,我们假定所有感知信息都可以分解成一个可感知的状态和一个回报信号
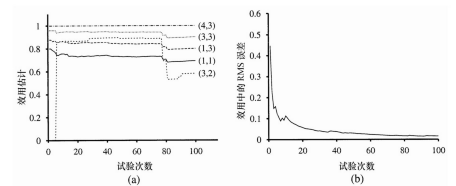
图21.3 在4×3世界中被动ADP的学习曲线,给定如图21.1所示的最优策略。(a)挑选出来的状态子集的效用估计,作为试验次数的函数。注意在第78次试验附近发生的巨大变化——这是智能体第一次落入−1终止状态 (4,2)。(b)对U(1,1)进行估计的均方根误差,20次运行的平均值,每次进行100次试验
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











