



14.2.1 表示全联合概率分布
贝叶斯网络提供了对域的一个完整描述。全联合概率分布(后面可能简称为“联合”或“联合分布”)中的每个条目都可以通过贝叶斯网络的信息计算出来。联合分布中的一般条目是在对每个变量赋予一个特定值的情况下的合取概率,比如P(X1= x1∧ … ∧Xn= xn)。我们用符号P(x1, …, xn)作为这个概率的简化表示。此条目的值可以通过下面的公式给出:

其中parents(Xi)表示Parents(Xi)中的变量的一个特定取值。于是联合概率分布中的每个条目都表示为贝叶斯网络条件概率表(CPT)中适当元素的乘积。因此,CPT 提供了联合概率分布的一种分解表示方法。
为了说明这一点,我们可以计算报警器响了,但既没有盗贼闯入,也没有发生地震,同时 John和Mary都给你打电话的概率。下面我们使用单个字母变量名:
P(j∧m∧a∧¬b∧¬e)
= P(j|a) P(m|a) P(a|¬b∧¬e) P(¬b) P(¬e)= 0.90 × 0.70 × 0.001 × 0.999 × 0.998 = 0.00062
在第13.4节中阐述了可以利用联合概率分布回答任何关于域的查询。如果贝叶斯网络是对联合概率分布的一种表示,那么通过对相关的所有联合条目进行求和,它也可以用于回答任何查询,第14.4节将解释如何做到这一点,同时也描述一些更有效的方法。
一、一种构造贝叶斯网络的方法
公式(14.1)定义了一个给定的贝叶斯网络的含义是什么。然而,它没有解释应如何构造一个贝叶斯网络,以使所产生的联合分布是对给定域的良好表示。现在我们将说明公式(14.1)蕴含了一定的条件独立关系,可以被用于引导知识工程师们构造网络的拓扑结构。首先,我们利用乘法规则(参见第十三章)按照条件概率重写联合概率分布:
P(x1, x2, …, xn) = P(xn|xn–1, …, x1) P(xn–1, …, x1)
然后我们重复这个过程,把每个合取概率简化成更小的条件概率和更小的合取式。最后我们得到一个大的乘法式:
P(x1, …, xn) = P(xn|xn–1, …, x1) P(xn–1|xn–2, …, x1) … P(x2|x1) P(x1)

这个恒等式对于任何随机变量集合都是成立的,称为链式法则(chain rule)。将它与公式14.1进行比较,我们看到联合分布的详细描述等价于对于每个网络中的变量Xi的一般断言,即:

倘若Parents(Xi) ⊆ {Xi–1, …, X1}。这最后一个条件可以通过按照与隐含在图结构中的偏序关系相一致的任意次序对节点进行标号而得到满足。
公式(14.2)说明,只有当给定了父节点之后,每个节点都与它按照节点顺序排列的祖先节点条件独立时,该贝叶斯网络才是对域的一个正确表示。因此,为了用针对域的正确结构构造贝叶斯网络,我们需要为每个节点选择合适的父节点以使这个性质成立。直观上看,节点Xi的父节点应该包含X1, …, Xi–1中所有那些直接影响Xi的节点。例如,假设我们已经完成了图14.2中的网络,除了对MaryCalls的父节点的选择。MaryCalls肯定受到是否有Burglary或者Earthquake的影响的,但这种影响不是直接的。从直观上,关于域的知识告诉我们,这些事件仅仅是通过它们对报警器产生的效果而影响Mary打电话的行为的。而且,已知报警器的状态,John是否打电话对Mary打电话的行动没有任何影响。形式化地说,我们相信下面的条件独立性语句成立:
P(MaryCalls|JohnCalls,Alarm,Earthquake,Burglary)=P(MaryCalls|Alarm)
二、紧致性与节点排序
作为对域的一种完备而无冗余的表示,贝叶斯网络往往比全联合概率分布紧凑得多。正是这个特性使得对包含许多变量的域进行处理成为可行的。贝叶斯网络的紧致性是局部结构化(locally structured,也称为稀疏,sparse)系统一个非常普遍特性的实例。在一个局部结构化系统中,每个组成部分都只与数量有限的其它部分发生直接的相互作用,而不考虑组成部分的总数量。局部结构通常与线性增长而不是指数增长的复杂度相关联。在贝叶斯网络的情况下,假设大多数域中每个随机变量受到至多k个其它随机变量的影响是合理的,其中k是某个常数。简单起见,如果我们假设有n个布尔变量,那么指定每个条件概率表所需信息量至多为2k个数据,则整个网络可以由不超过n 2k个数据完全描述。与之相反,联合概率分布中将包含2n个数据。为了使其更具体,可以假设我们有n = 30个节点,每个节点有5个父节点(k = 5)。那么贝叶斯网络需要960个数据,而全联合概率分布需要的数据将超过10亿个。
当然也存在一些域,其中每个变量都受到所有其它变量的直接影响,因此这样的网络是全连通的。那么指定贝叶斯网络的条件概率表所需的数据量就和指定联合概率分布所需的数据量是同样多的。在某些域中,存在一些微弱的依赖关系,严格地说要通过增添新的边把这样的关系包含到网络中。但是,如果这种依赖关系太微弱,也许不值得为了那么一点精度的提高而增加网络的复杂度。例如,有人也许会反对我们的防盗网络,理由是当地震发生的时候,John和Mary即使听到了警报声也不会打电话,因为他们感觉到地震后会认为地震是报警的原因而不是盗贼的闯入。是否需要增加从节点Earthquake到节点JohnCalls以及节点MaryCalls的边(条件概率表也会随着边的增多而扩大)取决于对更高精度概率的重要性与指定额外信息的代价之间的对比。
即使在一个局部结构化的域中,要构造一个局部结构化的贝叶斯网络也不是一件微不足道的事情。我们不仅要求每个变量只受到少数几个其它变量的直接影响,还要求网络的拓扑结构确实反映了合适的父节点集对该变量的那些直接影响。由于网络构造过程的工作方式,“施加直接影响者”将不得不先添加到网络中,如果希望它们成为受它们影响的节点的父节点的话。因此,添加节点的正确次序是首先添加“根本原因”节点,然后加入受它们直接影响的变量,依此类推,直到我们到达“叶节点”,即对其它变量没有直接因果影响的节点。
如果我们选择了错误的次序会发生什么样的事情呢?让我们再次考虑前面的防盗例子。假设我们决定按照MarryCalls,JohnCalls,Alarm,Burglary,Earthquake的次序加入各个节点。那么我们会得到一个稍微复杂一些的网络,如图14.3(a)所示。这个过程如下进行:
• 添加节点MaryCalls:没有父节点。
• 添加节点JohnCalls:如果Mary打电话,很可能意味着报警器的警铃已响,John打电话的几率当然增大了。因此JohnCalls需要MaryCalls作为父节点。
• 添加节点 Alarm:显然,如果两人都打电话,报警器确实已经发出警报的可能性比只有一个人打电话或根本没有人打电话时的可能性要高得多。因此,我们需要把MaryCalls和JohnCalls都当作Alarm的父节点。
• 添加节点Burglary:如果我们知道了报警器的状态,那么来自John或者Mary的电话或许能为我们提供关于我们的电话是否响了或者 Mary 是否在听音乐的信息,但是没有关于盗贼的信息:
P(Burglary|Alarm,JohnCalls,MaryCalls)=P(Burglary|Alarm)
于是,我们只需要Alarm作为Burglary的父节点。
• 添加节点Earthquake:如果报警器发出了警报,那么发生地震的可能性增加了。(因为我们的报警器其实也是一种地震探测器)。但是如果我们了解到确实有盗贼闯入,那么这解释了报警器报警的原因,而这种情况下发生地震的概率只略微高于正常情况。于是,我们需要 Alarm和Burglary作为Earthquake的父节点。
得到的网络比图14.2中的原始网络多了两条边,并需要多指定3个概率值。但是更糟糕的是,某些边表达的关系非常微弱,需要困难和不自然的概率判断,比如给定Burglary和Alarm,为Earthquake赋概率值。这种现象非常普遍,它和第八章中介绍的因果模型与诊断模型之间的区别有关。如果我们坚持因果模型,最终我们需要指定更少的数据,而且这些数据也更容易得到。例如,在医学领域,Tversky和 Kahneman(1982)发现相对于诊断规则,老练的医生更愿意提供因果规则中的概率判断而不是诊断规则的概率判断。
图14.3(b)显示了一种非常糟糕的节点次序:MaryCalls,JohnCalls,Earchquake,Burglary,Alarm。这个网络需要指定 31 个不同的概率——其数目与全联合概率分布完全相同。然而,非常重要的一点是要认识到上述3种网络的任何一个都能够表示完全相同的联合概率分布。但是,后两个版本的网络并没有表示出所有的条件独立关系,因此最终要指定很多不必要的数据。
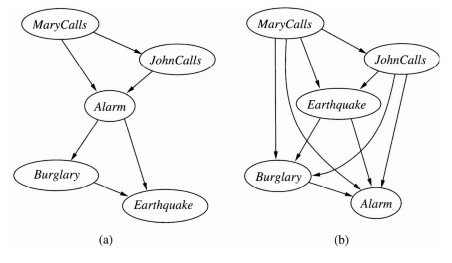
图14.3 依赖于引入节点的次序的网络结构。在每个网络中,我们都按照从上到下的次序引入节点
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











