



二、一元线性回归分析
在相关分析中,虽然可以利用相关系数r来表示两变量相关关系的方向和相关关系的密切程度,但是,相关分析却不能解决当一个变量X发生变化时,另一个变量Y相应地发生了多大的变化。回归分析则度量了一个变量的变化量对另一个变量变化量的贡献,因此常用于对实验数据的分析。
(一)相关分析和回归分析
回归分析和相关分析都是对变量间依存关系的分析,在理论基础和方法上具有一致性。只有对存在相关关系的变量才能进行回归分析,相关程度越高,回归测定的结果越可靠,相关系数也是判定回归效果的一个重要依据;另外,相关系数和回归模型中的参数可以相互换算。
但回归分析和相关分析也有如下差别:
第一,相关分析是研究变量之间的共同变化关系,这些变量相互对应,不必分主次和因果关系。回归分析却是在控制或给定一个或多个变量的条件下来观察另一个变量的变化,控制的变量称为自变量,不是随机变量,被观察的变量称为因变量,是一个随机变量。当给定一个自变量数值时,因变量可能有多个取值,而且在通常的研究中也假定它们呈正态分布,并且具有相同的方差。因此,回归分析必须根据研究的目的和对象的性质确定哪个是自变量(也称为解释变量),哪个是因变量(也称为被解释变量)。
第二,相关分析主要是测定变量之间关系的密切程度和变量变化的方向。而回归分析却可以对具有相关关系的变量建立一个定量模型来描述变量之间具体的变动关系,通过控制或给定自变量的数值来估计或预测因变量可能的数值。
相关分析和回归分析既有联系又有差别,实际研究中,通常把它们结合在一起应用。回归分析根据研究的问题和收集的资料也有很多形式,一元线性回归是最简单的也是最基本的一种回归分析。
(二)一元线性回归模型
一元线性回归模型是用于分析一个自变量(X)与一个因变量(Y)之间线性关系的数学方程式。一般的形式是:
![]()
这个方程在平面坐标系中表现为一条直线,回归分析中称之为回归直线。其中X是自变量,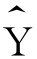 是因变量Y的估计值,也称理论值,它是根据回归模型和给定的自变量X的值计算得到的结果。
是因变量Y的估计值,也称理论值,它是根据回归模型和给定的自变量X的值计算得到的结果。
a和b通称为回归模型的参数。a是回归直线的截距,即X=0时的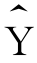 值,b是回归直线的斜率,也称为回归直线的斜率或回归系数,表示自变量每变化一个单位时
值,b是回归直线的斜率,也称为回归直线的斜率或回归系数,表示自变量每变化一个单位时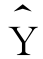 的增量
的增量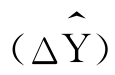 ,它的符号同相关系数r是一致的。当b>0时,它就表示X每增加一个单位时
,它的符号同相关系数r是一致的。当b>0时,它就表示X每增加一个单位时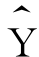 的增加量,X与
的增加量,X与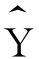 同方向变动;当b<0时,它就表示X每增加一个单位时
同方向变动;当b<0时,它就表示X每增加一个单位时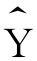 的减少量,X与
的减少量,X与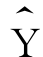 反方向变动。当b=0时,表示自变量X与因变量
反方向变动。当b=0时,表示自变量X与因变量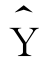 之间不存在线性关系,无论X取何值,
之间不存在线性关系,无论X取何值,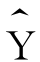 为一个常数。
为一个常数。
回归模型表明的是两个变量之间的平均变动关系。当给定自变量X某一个数值时,因变量Y的实际值可能有不止一个,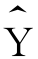 只是这些众多数值的均值。当控制X为某一取值时,Y的实际值可以看做由两部分组成:一部分是X对Y均值的线性影响而形成的系统部分,由回归量a+bX来测定;另一部分是由ε所代表的各种偶然因素、观察误差以及被忽略的其他影响因素所带来的随机误差。如图3—34所示。
只是这些众多数值的均值。当控制X为某一取值时,Y的实际值可以看做由两部分组成:一部分是X对Y均值的线性影响而形成的系统部分,由回归量a+bX来测定;另一部分是由ε所代表的各种偶然因素、观察误差以及被忽略的其他影响因素所带来的随机误差。如图3—34所示。
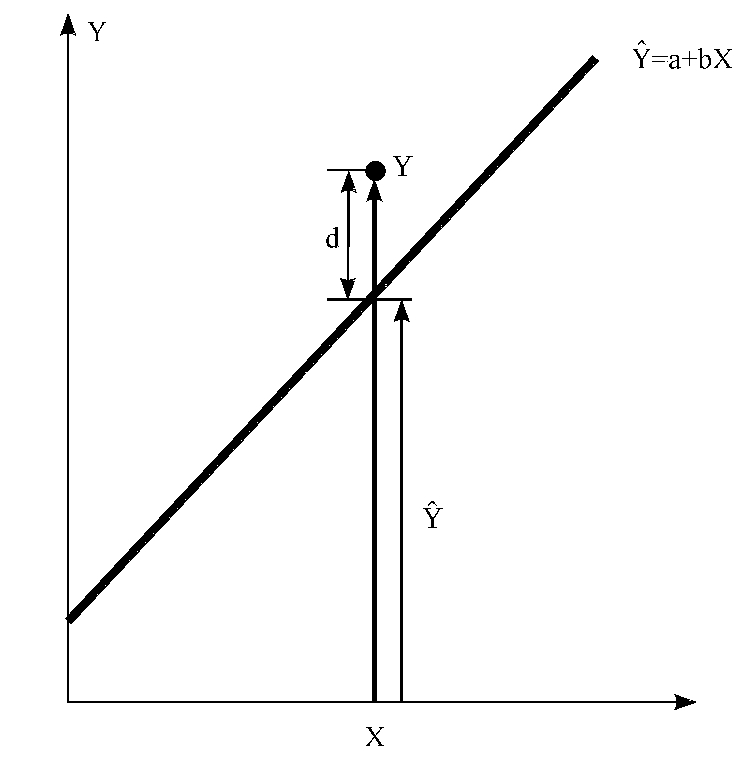
图3—34 回归关系中Y的实际值由两部分组成
回归分析的主要目的是建立回归模型,借助给定的X值来估计Y值,并判断模型是否合适、估计的精度等。对于给定的一组X和Y值,按照不同的法则可以拟合出不同的直线,但最常用的方法是用最小二乘法拟合这条直线。
最小二乘法的原则是让所有的Y和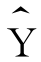 的偏差都尽可能地小。为了克服正负号的抵消,先将所有的偏差都进行平方计算,然后求和,令它最小,即让
的偏差都尽可能地小。为了克服正负号的抵消,先将所有的偏差都进行平方计算,然后求和,令它最小,即让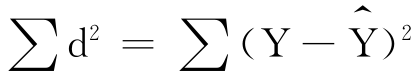 取最小值。这就是最小二乘法原则。
取最小值。这就是最小二乘法原则。
按照这个原则,得出斜率b的计算公式是:
b=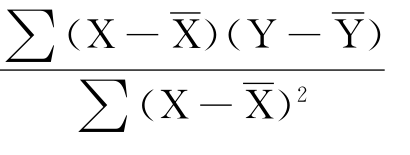
和计算相关系数时一样,令
x=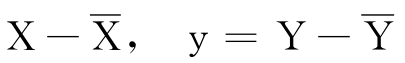
求b的公式就简化为:
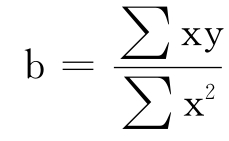
求出了斜率b之后,截距a就可以用下面的公式求得:
![]()
下面用一个例子来说明回归模型的计算过程。例如,有人相信儿童对电视的接触时间(平均每天看电视的时间X)和儿童的知识量(Y是用5级量表测量到的知识量得分)之间有因果关系,他们对20个儿童进行了测量,结果如表3—17的前3列所给出,回归模型的计算过程如下:
表3—17 儿童对电视的接触时间和儿童知识量的回归分析

表3—17的后四列是回归系数的计算过程,根据上表的结果,可以得出回归系数为:
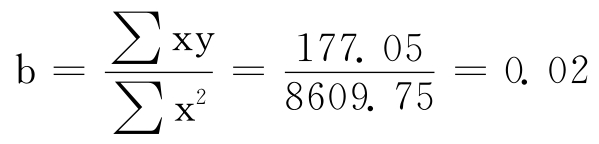
a= -b
-b =3.77-0.02×89.25=1.99
=3.77-0.02×89.25=1.99
代入回归模型中,得到:
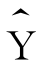 =1.99+0.02X
=1.99+0.02X
即,当X增加一个单位(分钟)时,Y的增加量是0.02(评分值),直线的截距是1.99。用这个模型可以进行预测,比如某个儿童平均每天看电视的时间为90分钟,便可以预测出他的知识量的得分是:
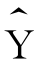 =1.99+0.02X=1.99+0.02×90=3.79
=1.99+0.02X=1.99+0.02×90=3.79
(三)判定系数r2
用最小二乘法求得的回归直线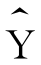 =a+bX确定了X与Y在数量上的变动关系。但是得出的模型应用价值如何,必须通过对回归直线的拟合优度加以测定。判定系数r2便是测定回归直线拟合优度的一个重要指标。
=a+bX确定了X与Y在数量上的变动关系。但是得出的模型应用价值如何,必须通过对回归直线的拟合优度加以测定。判定系数r2便是测定回归直线拟合优度的一个重要指标。
设Y的实际值到 的离差
的离差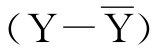 )被回归直线分割成两部分:(Y-
)被回归直线分割成两部分:(Y-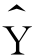 )和
)和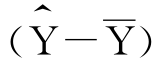 )。对于所有的实际值Y,总有下式:
)。对于所有的实际值Y,总有下式:
总变差=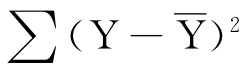
回归变差=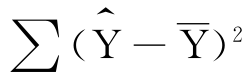
剩余变差=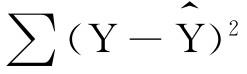
由于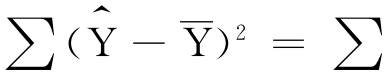 (a+bX-a-
(a+bX-a-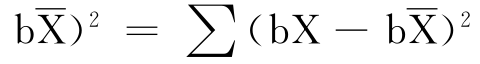 =
=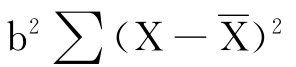 ,其中b为回归系数,可见回归变差很大程度上决定于回归系数,所以也称为被回归解释的变差;剩余变差也称为未被解释的变差或残差。
,其中b为回归系数,可见回归变差很大程度上决定于回归系数,所以也称为被回归解释的变差;剩余变差也称为未被解释的变差或残差。
可以证明,上述三类变差的关系是总变差=回归变差+剩余变差,即:
![]()
Y的实际值同Y的均值的总变差包括两个部分:一部分是回归变差,即X与Y依存关系影响的变差;另一部分是各种不确定因素引起的随机误差。在总变差一定时,回归变差越大,剩余变差就越小;反之,回归变差越小,剩余变差就越大。由此推论,如果实际值Y都紧密分布在回归直线两侧,剩余变差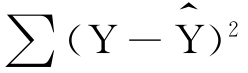 很小,说明X与Y的依存关系很强,总变差
很小,说明X与Y的依存关系很强,总变差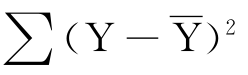 主要由回归变差
主要由回归变差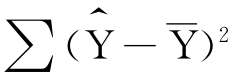 来解释;极端而言,如果Y都落在回归直线上,
来解释;极端而言,如果Y都落在回归直线上,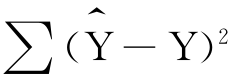 =0,这时总变差就完全由回归变差来解释了。
=0,这时总变差就完全由回归变差来解释了。
判定系数r2便是用回归变差占总变差的比例来表示回归模型拟合优度的评价指标:
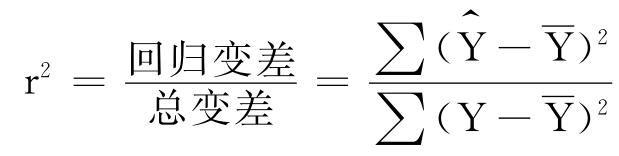
或
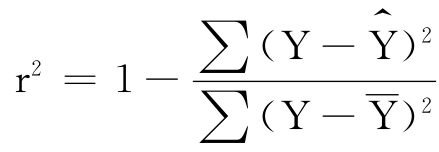
当X与Y两变量依存关系很密切,以至Y的变化完全由X引起时,X与Y为确定的函数关系,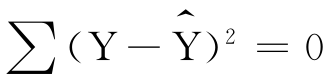 ,r2=1;当X与Y两变量不存在线性依存关系,即Y的变化与X无关,
,r2=1;当X与Y两变量不存在线性依存关系,即Y的变化与X无关,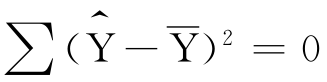 ,r2=0。一般情况下,r2在0~1之间,r2的值越大,说明回归的效果越好。
,r2=0。一般情况下,r2在0~1之间,r2的值越大,说明回归的效果越好。
判定系数r2和相关系数r具有一致性。可以证明,一元线性回归的判定系数r2的平方根就是简单线性相关的相关系数r。r的正负号,应根据回归模型中回归系数的符号来决定。
(四)回归系数b的假设检验
从总体中随机抽取一个样本,根据样本中n对X、Y值得出的线性回归模型,由于受到抽样误差的影响,它所确定的变量之间的线性关系是否显著,以及按照这个模型给值估计因变量Y是否有效,必须通过假设检验才可做出结论。一元线性回归模型的假设检验包括对回归系数b的t检验和对模型整体的F检验。
回归系数是决定X与Y变量依存关系存在形式的重要参数。如果b=0,说明X与Y不存在线性关系。因此,对回归系数的检验就是检验总体回归系数β是否等于0,即H0∶β=0。
可以证明,回归系数b的抽样分布也是近似正态的,其均值为总体斜率β,标准误差为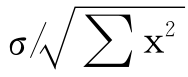 。其中,x=
。其中,x=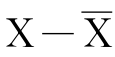 是X离开均值的偏差,σ是Y的观测值关于总体回归直线的标准差,可以用以下公式估计:
是X离开均值的偏差,σ是Y的观测值关于总体回归直线的标准差,可以用以下公式估计:

称S2为“剩余方差”,用S替代σ,可以得到b的标准误差的估计值是:
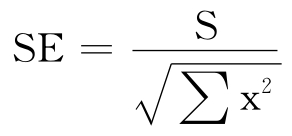
现在知道了b的标准误差,就可以对其进行假设检验了。根据假设检验的一般原则,构造b的检验统计量为:
![]()
如果原假设是H0∶β=0,则简化为:
![]()
然后,查t分布表中超过这一观测值t的概率,就得到了原假设的单侧概率,如果是双侧检验,概率值加倍。在大样本的情况下,可以按Z分布去查表。
(五)F检验
回归模型的F检验是将总变差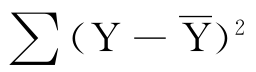 进行分解的一种检验方法。我们已经知道了总变差等于回归变差和剩余变差之和。各种变差都和一个自由度相联系,总变差的自由度为n-1,一元线性回归的回归变差的自由度为1,剩余变差的自由度为n-2,这三种变差的自由度也存在类似的和的关系:
进行分解的一种检验方法。我们已经知道了总变差等于回归变差和剩余变差之和。各种变差都和一个自由度相联系,总变差的自由度为n-1,一元线性回归的回归变差的自由度为1,剩余变差的自由度为n-2,这三种变差的自由度也存在类似的和的关系:
总自由度=回归变差的自由度+剩余变差的自由度
即n-1=1+n-2
将回归变差和剩余变差各自除以它们的自由度以后作比值,便得到检验统计量F:
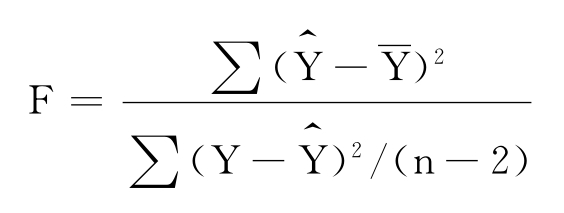
也可以用判定系数计算F统计量,因为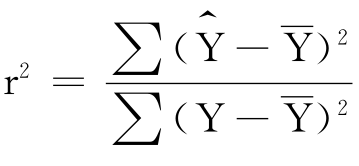 ,因此:
,因此:
![]()
根据F比值的大小就可以查附录Ⅳ(自由度为1和n-2),就可以得到原假设的概率值,然后和显著性水平进行比较,决定是否接受原假设“回归模型没有解释力”。
在计算F值的时候,常常会列出如表3—18的方差分析表。
表3—18 一元线性回归的方差分析表

对同一线性回归模型采用t检验和F检验,结论是一致的。在一元线性回归分析中,二者只进行一个检验就可以了,但是在多元回归分析中,它们是不等价的,t检验只是检验回归模型中各个回归系数的显著性,而F检验则是检验整个回归模型的显著性。
(六)自变量为定类变量时的回归
前面讲述的相关和回归都是针对数值型变量进行的,即因变量和自变量均为定距或定比变量的情形,定序变量可以近似地按定距变量来处理。而对于定类变量,可以先变为哑变量再进行相关分析或回归分析。下面就来看一下当自变量为定类变量时如何进行回归分析。
如果定类变量只包含两种类型,如男和女或看电视和不看电视,这样的情况下可以用数字0和1分别代表两种取值(哑变量),这样就转换为一般的数值型变量,从而可以采用高级别的统计办法进行处理。下面用一个具体的例子来说明。
在一个n=20的样本中,看过某则广告和没看过某则广告的人对该品牌的认知程度用5级量表在表3—19中列出,表的后面几列是计算的过程。
表3—19 看过广告和没看过广告的人的品牌认知度

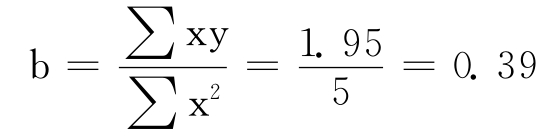
![]()
回归模型是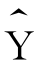 =3.58+0.39X
=3.58+0.39X
原假设H0∶β=0
S2=5.947/18=0.3304,S=0.57
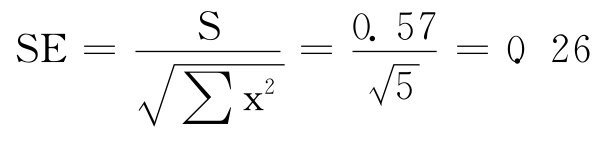
t=b/SE=0.39/0.26=1.5,Pr(t>1.5)>0.05
在α=0.05的显著性水平下,接受原假设,即认为是否看过这则广告和人们对该品牌的认知度之间没有显著的线性依存关系。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










