



10.3 反应模式分析
对3组留学生被试和汉语被试反应模式进行多因变量线性模型方差分析,Wilks’Lambda F=4.600,P=0.000<0.001,总体有显著差异。组间方差检验有显著效应的句式涉及主动宾1、主动宾3、施宾句、主领句、主受句、把字句1、被字句、把字句2、被把句9个句式共有20个反应项目。位置在后(主动宾1)为F(3,76)=4.899,P=0.004;位置在前(主动宾3)为F(3,76)=4.200,P=0.008;位置在后(主动宾3)为F(3,76)=4.600,P=0.005;不好确定(主动宾3)为F(3,76)=3.365,P=0.023;位置在前(施宾句)为F(3,76)=6.341,P=0.001;位置在后(施宾句)为F(3,76)=16.688,P=0.000<0.001;位置在前(主领句)为F(3,76)=5.738,P=0.001;不好确定(主领句)为F(3,76)=6.300,P=0.001;位置在前(主受句)为F(3,76)=8.589,P=0.000<0.001;位置在后(主受句)为F(3,76)=7.778,P=0.000<0.001;不好确定(主受句)为F(3,76)=2.900,P=0.040;位置在前(把字句1)为F(3,76)=6.127,P=0.001;位置在后(把字句1)为F(3,76)=5.923,P=0.001;位置在前(被字句)为F(3,76)=3.685,P=0.016;位置在后(被字句)为F(3,76)=6.162,P=0.001;位置在前(把字句2)为F(3,76)=9.730,P=0.000<0.001;位置在后(把字句2)为F(3,76)=8.865,P=0.000<0.001;不好确定(把字句2)为F(3,76)=5.910,P=0.001;位置在前(被把句)为F(3,76)=4.051,P=0.010;位置在后(被把句)为F(3,76)=4.810,P=0.004。
4组被试在各个句式上反应模式均值参见附录4中的表6-7。多重比较(见附录7中的表10-3)发现,被试在15个反应项目上存在显著差异,这些项目涉及施宾句、主领句、主受句、把字句1、被字句、把字句2、被把句共7个句式。
此外,被试组间差异在未涉及的主动宾1和主动宾3上也有所表现,具体为:韩语被试跟汉语被试、日语被试在“位置在后(主动宾1)”上均值差异水平均为P=0.059(MD=0.033333,SE=0.011364),接近显著水平;汉语被试与韩语被试在两个反应项目“位置在前(主动宾3)”、“位置在后(主动宾3)”均值差异水平分别为P=0.051(MD=0.138889,SE=0.040375)、P=0.055(MD=-0.077778,SE=0.023997),也都接近显著水平。
反应模式上的差异与反应时基本类似,表现为以下两个特点。首先,表现在汉语是否为母语方面;其次,表现在留学生被试的母语类型差别方面。例外的是,日语被试和韩语被试在把字句1上的两个反应项目“位置在前”和“位置在后”的选择比率存在显著差异,产生这一结果的原因可能是,日语和韩语中使用的文字跟汉字的联系程度不同(具体参见9.3)。
下面结合图示和相关表格里的数据(见附录4中的表6-7、附录7中的表10-3),对上述有显著差异的句式进行比较分析。需要说明的是,语言实验要求被试对每个句子的三个可选项目只能选其中的一个,因此被试在一个项目上的结果与其他两个项目的结果有直接关系。因此,在下面的分析中,只分析比较重要的反应项目,尤其是正确的选项和容易出错的选项。通过对被试在某一或某些语言项目上反应模式的分析,我们可以全面把握汉语作为第二语言的学习者在上述语言项目上的掌握情况,这是探索他们在习得汉语过程中的中介语系统的一个有效方法。
4组被试在7个句式上的反应模式差异可以用直方图直观地表示出来。
先看4组被试在施宾句上的反应差异。
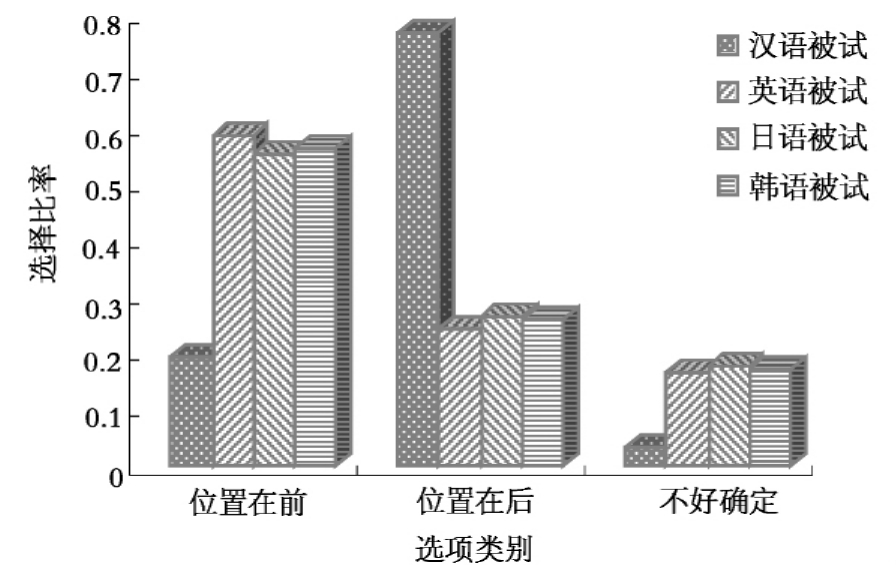
图10-1 4组被试在施宾句三个项目上选择率比较
图10-1是4组被试在施事指认任务中对施宾句三个反应项目的选择情况。4组被试在施宾句的两个反应项目“位置在前”(汉vs英、日、韩)和“位置在后”(汉vs英、日、韩)上选择比率存在显著差异(多重比较有显著差异反应项目均参见附录7中的表10-3,下同)。
对于第一个反应项目,汉语被试、英语被试、日语被试、韩语被试的选择比率分别为0.1944444、0.58888885、0.5555556、0.56666665(4组被试在不同句式上反应模式均值均参见附录4中的表6-7,下同),汉语被试与英语被试、日语被试、韩语被试在这个项目上的选择比率差异水平分别为P=0.000<0.001、P=0.001、P=0.001。
对于第二个反应项目(也是施宾句的正确选项),汉语被试、英语被试、日语被试、韩语被试的选择比率分别为0.77222225、0.2444443、0.2666665、0.26111115,4组被试在这个项目上选择比率都比较低。
从前面7.5的反应时多因素方差分析和讨论中发现,4组被试对施事前置的句子的反应时要短于施事后置,可能是施事后置造成4组被试在理解这一句式时,需要抑制施事通常前置的干扰,从而正确率低。对于汉语被试来说,由于汉语是其母语,因此他们在这个句式上正确率高于以汉语为外语的3组留学生被试,与3组留学生被试正确率差异水平均为P=0.000<0.001。
4组被试在主领句上的反应差异如图10-2所示。

图10-2 4组被试在主领句三个项目上选择率比较
汉语被试与日语被试在主领句的两个项目“位置在前”和“不好确定”选择比率存在显著差异。前一个项目选择比率分别为0.56666665、0.8611112,均值差异水平为P=0.000<0.001;后一个项目选择比率分别为0.36111105、0.06666665,均值差异水平为P=0.000<0.001。汉语被试在主领句的一个项目“位置在前”上选择比率低于日语被试,原因在于不少汉语被试把这个句式当作领属句,即难以抑制解释为无施事的领属句。主领句是一个可以解释为两种句子结构的句式,其一为主谓谓语句,其二为无施事的领属句。是前者应该选施事“位置在前”,是后者应该选“不好确定”施事。不少汉语被试认为这个句式是领属句,因此,与日语被试选择结果相比,他们在“位置在前”选择比率少,而在“不好确定”选择比率多。
汉语被试与英语被试在主领句的一个项目“位置在后”选择比率分别为0.07222215、0.1222221,均值差异水平为P=0.034。
英语被试与日语被试在主领句的两个项目“位置在前”和“位置在后”选择比率存在显著差异。前一个项目选择比率分别为0.638889、0.8611112,均值差异水平为P=0.039;后一个项目选择比率分别为0.1222221、0.07222215,均值差异水平为P=0.034。
日语被试在主领句的反应项目“位置在前”选择比率比英语被试高,原因可能在于这个句式是汉语主题句,日语被试对这种句式比较熟悉有关(从正确率指标看,尽管这个句式存在歧义,但被试在该句式上的正确率并不低)。日语在语种类型上是主语和主题皆突出的语言,日语被试在理解与其母语结构规则类似的汉语主题句时,易于激活和提取母语中与汉语相似的主题句,能够比较容易从其母语中迁移相关语言规则。
再看4组被试在主受句上的反应情况(图10-3)。
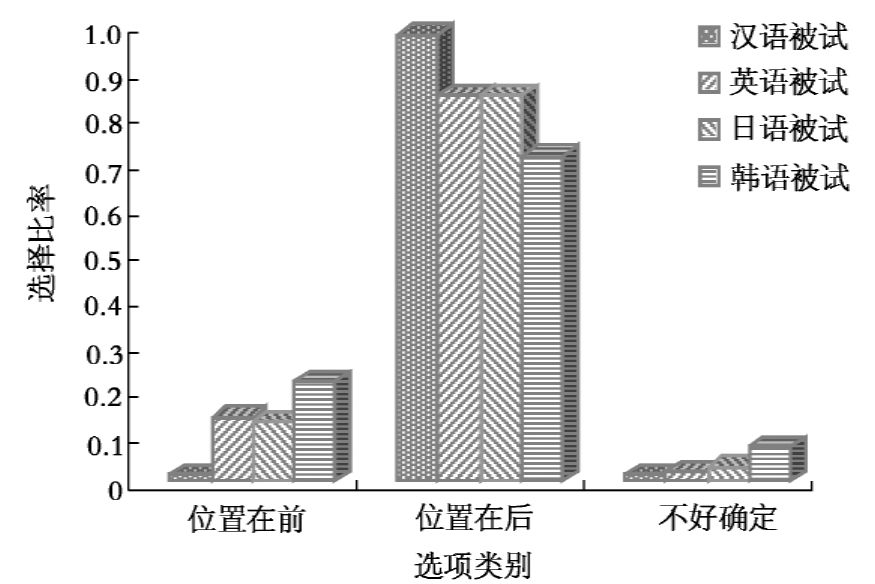
图10-3 4组被试在主受句三个项目上选择率比较
在施事指认任务中,汉语被试与英语被试、日语被试、韩语被试在主受句的一个项目“位置在前”选择比率分别为0.0111111、0.13888875、0.127778、0.2166665,均值差异水平分别为P=0.000<0.001、P=0.005、P=0.001。
汉语被试在主受句的一个反应项目“位置在前”(为该句式的错误选项)选择比率低于日语被试。汉语被试与英语被试、韩语被试在这个项目上的差异,与他们在相关的另外一个项目“位置在后”上的差异有联系,具体见下面分析。
汉语被试与英语被试、韩语被试在另外一个项目“位置在后”选择比率分别为0.9777778、0.8444446、0.7111112,均值差异水平分别为P=0.000<0.001、P=0.001。
汉语被试在主受句的第二个反应项目(也是主受句的正确选项)选择比率比英语被试、韩语被试高。从前面7.5的反应时多因素方差分析和讨论中发现,英语被试和韩语被试对施事前置的句子的反应时要短于施事后置。被试选择施事后置需要抑制施事前置的干扰,造成两组留学生被试理解这一句式正确率低。对于汉语被试来说,由于汉语是他们的母语,因此他们在这个句式上正确率高于以汉语为外语的英语被试和韩语被试。
图10-4是4组被试在把字句1上的反应情况。
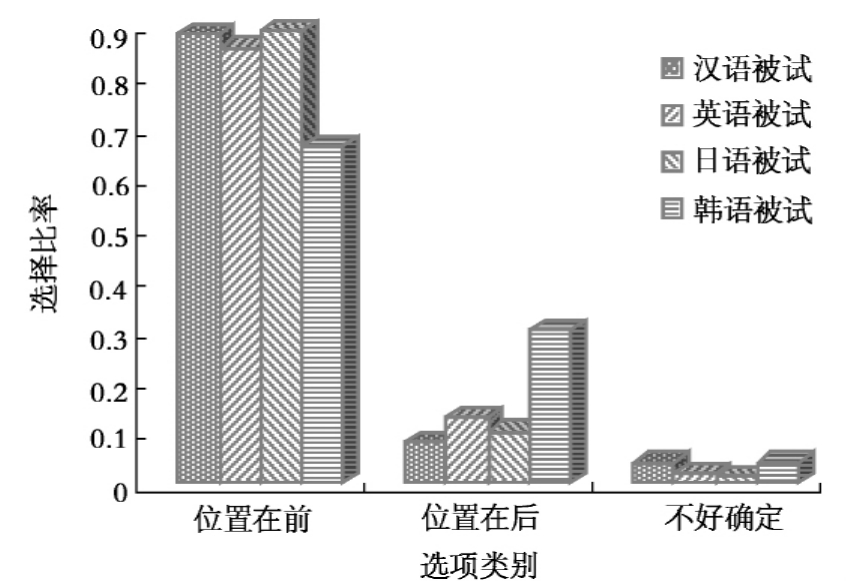
10-4 4组被试在把字句1三个项目上选择率比较
汉语被试与韩语被试在把字句1的两个项目“位置在前”和“位置在后”选择比率存在显著差异。前一个项目的选择比率分别为0.8833335、0.6611110,均值差异水平为P=0.025;后一个项目的选择比率分别为0.0777777、0.3000000,均值差异水平为P=0.018。
汉语被试在把字句1反应项目“位置在前”(为把字句1的正确选项)选择比率比韩语被试高。一般认为韩语无补语,表示补充说明的成分一般放在动词之前,与汉语补语的位置在动词之后有明显的差别。可能是这个句式带补语,造成了韩语被试理解这一句式正确率低。由于汉语是其母语,因此汉语被试在这个句式上正确率高于以汉语为外语的英语被试和韩语被试。
日语被试与韩语被试在上述两个项目选择比率存在显著差异。前一个项目的选择比率分别为0.8888890、0.6611110,均值差异水平为P=0.023;后一个项目的选择比率分别为0.0999999、0.3000000,均值差异水平为P=0.047。
日语和韩语语法结构规则类似,然而他们在把字句1上却表现出了有差异的结果,其原因可能跟两种语言使用的文字有关(参见9.3)。
4组被试在被字句上选择结果如图10-5所示。
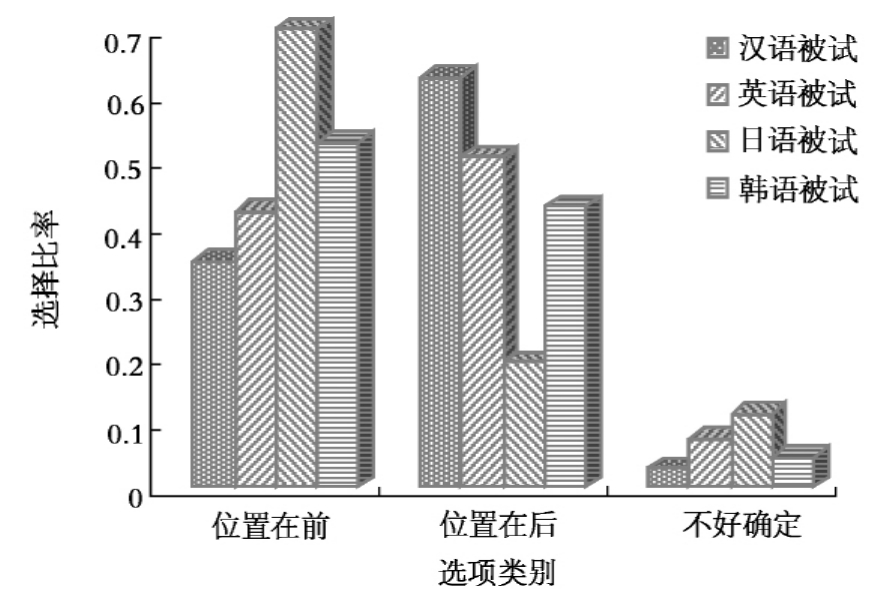
图10-5 4组被试在被字句三个项目上选择率比较
在施事指认任务中,汉语被试与日语被试在被字句的两个项目“位置在前”和“位置在后”选择比率差异显著。前一项目的选择比率分别为0.3444445、0.7000000,均值差异水平为P=0.004;后一项目的选择比率分别为0.6277778、0.1888888,均值差异水平为P=0.000<0.001。
汉语被试和日语被试在被字句的“位置在后”(也是该句式的正确选项)选择比率都比较低,原因在于这个句式的施事为生命度低的名词,与通常作施事的是生命度高的名词性成分有明显差别。此外,该句式里的施事后置也是选择比率低的一个原因。在前面7.5反应时多因素方差分析和讨论中我们发现,所有4组被试对施事后置的句式理解比较困难。被试在理解这个句式时需要抑制生命度高的施事和施事位置通常在前面两方面因素的干扰,这两方面因素共同造成这两组被试在这个句式上正确率比较低。以汉语为外语的日语被试在这个项目上的选择比率远低于汉语被试。
英语被试与日语被试在这个句式的“位置在后”选择比率分别为0.5055555、0.1888888,均值差异水平为P=0.017。
英语被试在被字句的“位置在后”选择比率高于日语被试,原因可能在于英语被试利用形式标记“被”这一可靠线索,激活和提取跟汉语功能类似的形式标记的相关知识。从前面7.2的反应时多因素方差分析中我们发现,英语被试对汉语中的“把”、“被”形式标记有一定程度的易化效应,他们对带形式标记的句子要比不带形式标记的句子反应时短,理解比较容易。
4组被试在把字句2上的反应情况如图10-6所示。

图10-6 4组被试在把字句2三个项目上选择率比较
汉语被试与英语被试在把字句2的两个反应项目“位置在前”和“位置在后”的选择比率存在显著差异。两组被试在前一个项目选择比率分别为0.1388889、0.5500000,均值差异水平为P=0.000<0.001;在后一个项目选择比率分别为0.8611112、0.4277779,均值差异水平为P=0.000<0.001。汉语被试与韩语被试在这个句式的反应项目“位置在后”的选择比率分别为0.8611112、0.6333334,均值差异水平为P=0.015。
把字句2里的“把”的形式标记映射了一个使用频率低的语义成分“施事”,使被试对该句式的理解普遍出现困难。英语被试、韩语被试在这个句式的“位置在后”(也是该句式的正确选项)上选择比率低于汉语被试。
对于该句式的两个反应项目“位置在前”和“位置在后”,英语被试分别与日语被试、韩语被试选择比率均值存在显著差异。前一个项目的选择比率分别为0.5500000、0.2055555、0.2388888,差异水平均为P=0.000<0.001;后一个项目的选择比率分别为0.4277779、0.7944445、0.6333334,差异水平分别为P=0.000<0.001、P=0.028。
3组留学生被试理解把字句2都有困难。这个句式VP后置的语法规则与日语、韩语的句子结构规则类似,而与英语句子结构规则VP在通常位置有明显的差别。尽管该句式有形式标记,但这一标记映射了与其通常功能对立的语义成分,并不是可靠的理解线索,被试理解这个句式时需要抑制“把”通常作为受事前的标记的干扰。此外,英语被试理解时还需要抑制VP在通常位置的干扰,因此他们在这个句式的“位置在后”(也是正确的选项)选择比率就比日语被试、韩语被试低。
最后,看4组被试在被把句上的反应情况,如图10-7所示。
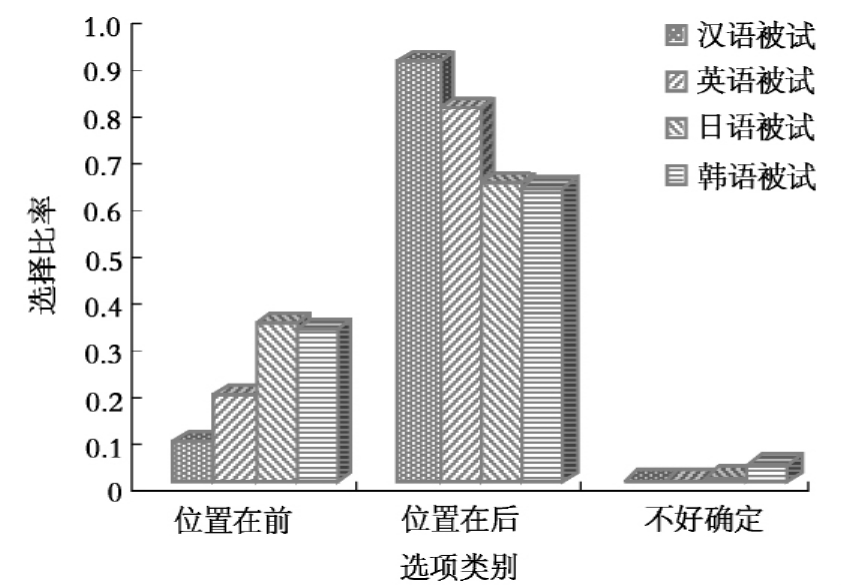
图10-7 4组被试在被把句三个项目上选择率比较
在施事指认任务中,汉语被试与日语被试、韩语被试在被把句的两个反应项目“位置在前”和“位置在后”的选择比率存在显著差异。前者选择比率分别为0.0888889、0.3444444、0.3277777,均值差异水平分别为P=0.045、P=0.011;后者选择比率分别为0.9055556、0.6444445、0.6333334,均值差异水平分别为P=0.034、P=0.004。
被把句是“被”字结构和“把”字结构的套用格式,实际使用率低,理解这一句式需要同时激活和提取两种结构,加工过程复杂。日语被试和韩语被试理解这一句式有一定的困难。日语被试和韩语被试在这个句式的“位置在后”(也是正确的选项)选择比率低,分别与汉语被试存在显著差异。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











