



6.4.4 多尺度图形数据的融合
由于采集技术、采集时间的不一致以及不同地区、部门经济条件及应用需求的差异,土地管理数据的空间尺度并不统一,如DEM数据主要以1∶25万、1∶5万为主,地形图为1∶1万,土地利用基本为1∶1万、1∶5万,地质调查数据则以1∶25万为主,等等。为了有效利用具有多时间、多尺度、多属性以及多种类型特征的系列数据,有必要进行尺度融合,通过对数据进行深层次加工,获得更高质量的信息。
1.尺度转换
尺度转换是利用某一尺度上所获得的信息和知识来推测其他尺度上的现象,既可以是向上尺度转换,也可以是向下尺度转换。目前国内对“尺度转换”的中文表达多种多样,难以统一,如有的用“尺度上推”和“尺度下推”来分别表示向上和向下的尺度转换过程,有的又称之为“尺度推绎”。根据王劲峰等对尺度转换的定义,将较小尺度观测结果获得较大尺度信息的向上尺度转换过程称为尺度扩展;而把大尺度上的信息分解到更小的尺度向下尺度转换的过程称为尺度收缩。
尺度扩展(尺度上推):从较小尺度(空间)观测中获得较大尺度(空间)上信息的过程,是将信息从精确的尺度(高分辨率)向模糊的尺度转换的过程;
尺度收缩(尺度下推):从较大尺度(空间)的信息分解到更小的尺度(空间)上信息的过程,是将信息从模糊的尺度向精确的尺度转换的过程(见图6-39)。
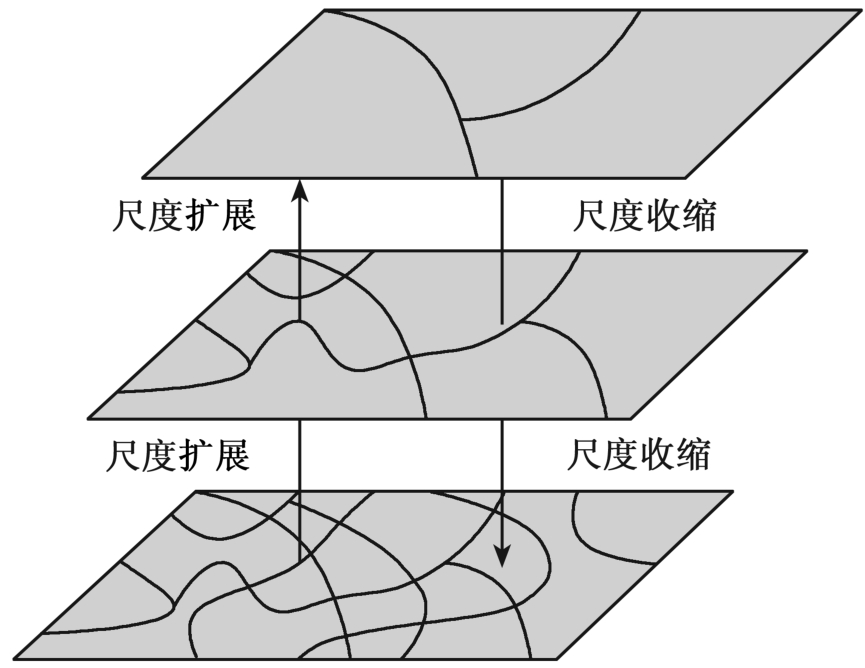
图6-39 尺度扩展和尺度收缩过程示意图示意图
2.尺度转换的主要方法
尺度转换可以有两种途径:确定性方法和随机性方法,确定性方法主要适用于尺度扩展的过程,它一般通过分配由较小尺度所确定某一时间或空间尺度下的结构或类型,然后再聚集成单个大尺度上的均值;而随机性方法主要适用于尺度收缩的过程,它是通过某种分布函数或协方差函数来聚集,通常以矩阵的形式表示;它也比较适合于在具体的时空结构或类型未知的情况。
1)尺度扩展的主要方法
向上尺度转换是将较小尺度的信息转换到较大的尺度范围,这一过程与空间插值类似,即通过对样本比较精确信息的分析,获取更大范围(整体)的一般信息,如均值、方差等。因此,向上尺度转换总体来说是一个“集聚”的过程,点与多边形叠加和地统计分析是常常采用的方法。
(1)点与多边形叠加。点与多边形叠加是基于点对多边形的插值,其本质上是点与多边形的空间叠加过程。由于点在空间只有位置属性,而多边形则具有面积属性,因而可以将点的信息向面要素的转化过程理解为向上尺度转换,多边形根据其覆盖的点(或多个点)赋值,当有多个点时,可以以出现次数最多的点来赋值或者值最大的点来赋值。
(2)地统计方法。地统计方法是一种优化估计的技术,其基本假设是建立在空间相关的先验模型之上的,假定空间随机变量具有二阶平稳性,或者是服从地统计的本征假设(Intrinsic Hypothesis)。因此它具有这样的性质:距离较近的采样点比距离远的采样点更相似,相似的程度或空间协方差的大小,是通过点对的平均方差度量的。点对差异的方差只与采样点间的距离有关,而与它们的绝对位置无关。由于可以通过比较被特定滞后距离分隔的同一随机变量的不同值和在多个尺度上对区域化随机变量的变异性进行量度,因而地统计方法也常常用来作为向上尺度转换的一种解决方案。
2)尺度收缩的主要方法
尺度收缩是一个将信息从模糊的尺度向精确的尺度拆分的过程。它主要包括无辅助变量的尺度收缩和有辅助变量的尺度收缩。
(1)无辅助变量的尺度收缩。无辅助变量,是指没有“尺度”和研究对象之外的辅助信息。面域加权和最大保留法(Pycnophilactic)方法是针对无辅助变量情况最为常用的两种方法。其中,面域加权法基于多边形叠加分析,将目标区和源区叠加,分别计算各交叉区域的属性值,再按目标区进行计算。这种算法虽然能够保证源区与目标区的属性值相等,但是它假定属性值在源区内均匀分布的假设是不符合实际的。最大保留法是简单面域加权的扩展,它假定一个光滑密度函数,该密度函数在变量一致的前提下,考虑了相邻区域的影响。平滑条件是通过要求每个网格单元的数值接近它周围四个邻近网格单元的平均值达到最小化估计表面曲率的目的。该算法不仅保证了源区和目标区之间属性值保持一致,而且不要求源区中属性值分布的均匀性,但是单元边界处属性值的较大变化会影响插值的效果。
(2)有辅助变量的尺度收缩。辅助变量可分成两类:限制变量(Limiting Variables)和相关变量(Related Variables)。限制变量严格定义事件的发生与否,如对于人口分布变量来说,水体中不会有人口分布,居民地中有人口分布,在叠加分析中使用布尔方法。相关变量与事件的发生有一定关系,如对于人口的分布变量,研究区内不同类型的土地使用类型可能与人口的分布有关联,经常用相关分析和回归分析方法来分析变量间的相关程度,在叠加分析中通常使用数学方法。这主要包括修正的面域加权和小区域统计学。
①修正的面域加权。它可以分为使用控制区的面域加权和使用回归关系的面域加权。使用控制区的面域加权是当源区和目标区内的属性值都不是均匀分布时,引入控制区(Control Zones)的概念,先将源区与控制区叠加,计算控制区的属性信息的密度;再将控制区与目标区叠加,求得目标区的属性值;使用回归关系的面域加权主要针对当源区和目标区内的属性都不是均匀分布但也没有所谓的控制区信息的情况下,该算法假设所求目标区的属性值与源区若干要素相关,利用要素间的回归关系来计算目标区的属性值。
②小区域统计学。所谓“小区域”是指区域内样本点较少的地理区域,在对其进行统计分析的过程中,需要从相关区域“借力”来获得可靠的分析结果。小区域统计学本质上是一种间接估计,其核心问题是建立相关区域(数据)的联系模型。小区域统计主要包括“综合估计”、“复合估计”(Composite Estimators)和“基于模型的估计”(Modelbased Estimators)等几大类方法。综合估计假定较大区域中属性值可以通过直接估计获得,在此基础上假设不同大小区域的某些属性具有相同特征,实现对小区域的估计。复合估计是一种平衡综合估计和直接估计的方法,通过确定两者权重实现。基于模型的估计又可以分为“区域模型”(Area Level Models)和“单元模型”(Unit Level Models)。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。












