



6.3 α-β剪枝
极小极大值搜索的问题是必须检查的游戏状态的数目随着招数的数量指数级增长。不幸的是我们没有办法消除这种指数级增长,不过我们可以有效地将其减半。这里的技巧是有可能不需要遍历博弈树中每一个节点就可以计算出正确的极小极大值策略。于是,我们借用第四章中的剪枝技术从考虑中消除搜索树的很大一部分。我们要考察的特别技术称为α -β剪枝。应用到一棵标准的极小极大值树上,它剪裁掉那些不可能影响最后决策的分支,仍然可以返回和极小极大值算法同样的结果。
重新考虑图 6.2 中的两层博弈树。让我们再次全面观察最优决策的计算过程,这一次仔细注意过程中在每个节点我们所知道的。图 6.5 显示了每一步的解释。结果是我们可以在不评价其中两个叶节点的情况下就可以确定极小极大值决策。
从另一个角度来看,可以把这个过程视为对 MINIMAX-VALUE公式的简化。令在图 6.5 中的 C节点的两个没有评价的后继节点的值是x和y,并且z是x和y中的最小值。根节点的值由下面公式给出:
图6.5 计算图6.2中博弈树的最优决策的各阶段。在每一步,我们显示了每个节点可能的取值范围。(a)B下面的第一个叶节点值为3。因此,B这个MIN的点的值至多为3。(b)B下面的第二个叶节点值为12。MIN不会采用这个招数,所以B的值仍然至多为3。(c)B下面的第三个叶子值为8;我们已经观察过B的所有后继,所以B的值就是3。现在我们可以推断根节点的值至少为3,因为MAX在根节点有一个值为3的选择。(d)C下面的第一个叶节点值为2。因此C这个MIN节点的值至多为2。不过我们已经知道B的值是3,所以MAX绝不会选择C。因此,再考察C的其它后继已经没有意义了。这就是α-β剪枝的一个例子。(e)D下面的第一个叶节点值为14,所以D的值至多为14。这比MAX的最佳选择(即3)还大,所以我们必须继续探索D的其它后继。还要注意我们现在知道根的所有后继的界限,所以根节点的值至多为14。(f)D的第二个后继值为5,所以我们又必须继续探索。第三个后继值为2,所以D的值就是2了。于是MAX在根节点的决策是移动到值为3的B
MINIMAX-VALUE(root)=max(min(3,12,8),min(2,x,y),min(14,5,2))
= max(3, min(2, x, y), 2)
=max(3,z,2) 其中z≤ 2
=3
换句话说,根节点的值以及因此做出的极小极大值决策独立于被剪枝的叶节点x和y。
α -β剪枝可以用于树的任何深度,而且很多情况下可以剪裁整个子树,而不是仅剪裁叶节点。一般原则是:考虑在树中某处的节点 n(参见图 6.6),游戏者可以选择移动到该节点。如果游戏者在 n的父节点或者更上层的任何选择点有一个更好的选择 m,那么在实际的游戏中就永远不会到达n。所以一旦我们发现关于n的足够信息(通过检查它的某些后代),能够得到上述结论,我们就可以剪裁它。
记住极小极大搜索是深度优先的,所以任何时候我们不得不考虑树中一条单一路径上的节点。α -β剪枝的名称就是从下面两个描述这条路径上任何地方的回传值界限的参数得来的:
α= 到目前为止我们在路径上的任意选择点发现的MAX的最佳(即极大值)选择
β= 到目前为止我们在路径上的任意选择点发现的MIN的最佳(即极小值)选择
α -β搜索不断更新α 和β 的值,并且当某个节点的值分别比目前的MAX的α 或者MIN的β 值更差的时候剪裁这个节点剩下的分支(即终止递归调用)。完整的算法由图6.7给出。我们鼓励读者跟踪把这个算法用于在图6.5中的树上的行为表现。
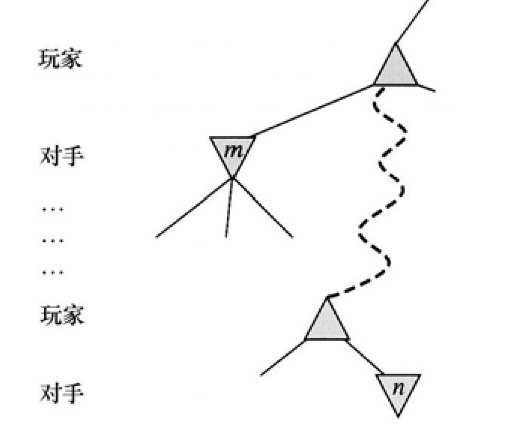
图6.6 α-β剪枝:一般情况。如果对于游戏者而言m比n好,我们就不会走到n

图6.7 α-β搜索算法。注意这些例程几乎和图6.3中的极小极大值算法一样,除了在MIN-VALUE和MAX-VALUE中维护α和β的值的两行(还有用来传递这些参数的记录)
α -β剪枝的效率很大程度上取决于检查后继的顺序。例如,图 6.5(e)和(f)中,我们根本不能剪掉D的任何后继,因为首先生成了最差的后继(从MIN的角度)。如果第三个后继先生成,那么我们就能够剪掉其它两个。所以这暗示着先尝试检查那些可能最好的后继是值得的。
如果我们能够做到先检查那些可能最好的后继[29],那么α -β算法只需要检查O(bd/2)个节点来决定最佳招数,而极小极大值算法需要检测O(bd)。这意味着有效分支因子由b变成了——对于国际象棋而言就是从35变成6。换一个角度,在同样的时间里,α -β算法能够比极小极大值算法多向前预测大约两倍的步数。如果后继者不是按照最佳优先的顺序,而是按随机的顺序检查的,那么对于适当的b,要检查的总节点数大约是O(b3d/4)。对于国际象棋,一种相当简单的排序函数(如:吃子优先,然后是威胁、向前走子、向后走子)可以提供你最佳情况O(bd/2)的2倍以内的结果。增加动态行棋排序方案,诸如先试图采用那些以前走过的最好行棋,可以让我们非常接近理论极限。
在第三章中我们提到过在搜索树中的重复状态会使搜索的代价呈指数级增长。在游戏中,重复的状态频繁出现往往是因为调换——导致同样棋局的不同行棋序列的排列。例如,白棋走a1,黑棋要用b1应对,而白棋在棋盘另一边的无关的一招a2,黑棋要走b2来应对。于是序列[a1, b1, a2, b2]和[a1, b2, a2, b1]都结束于同样的局面(以 a2开始的排列也一样)。第一次遇到某棋局时把对于该棋局的评价存储在哈希表里是值得的,这样当它后来再出现时不需要重新计算。存储以前见过的棋局的哈希表一般被称作调换表;它本质上和图搜索中的closed表相同(参见第3.5节)。使用调换表可以取得好的动态效果,在国际象棋中,有时可以把可到达的搜索深度扩大一倍。另一方面,如果我们可以每秒钟评价一百万个节点,那么在调换表中保存所有评价就不切实际了。为了选择最有保留价值的节点,许多不同的策略被使用过。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










