



4.4 自然语言与受控词表的互操作
本系统前面已实现了不同分类表、主题词表到《中分表》的互操作,从而使用户可以通过分类号或主题词方便、快捷地查看其他词表的对应信息。但是前提是用户对《中分表》有一定的了解,才能进行查找。而对于不熟悉受控词表的用户来说,系统就不具有实用性,他们更希望直接用自然语言进行查找,进而浏览其对应信息。所以本系统也加入了自然语言的互操作,通过自然语言到受控词表的转换,提供一个自然语言入口,供用户进行检索。主要分为两部分:一是自然语言和分类语言的转换,即实现关键词到《中图法》分类号的互操作;二是自然语言和主题语言的转换,即实现关键词(自然语言)到《中分表》主题词的互操作。
4.4.1 自然语言到分类语言的转换
自然语言到分类语言的转换,主要实现的是关键词到《中图法》分类号的转换,即在关键词和分类号之间建立联系。众所周知,一个词在不同的语言环境中可以表达不同的含义,归属到不同的类中,也就是说,一个词可以对应多个不同的分类号。所以要直接将一个词划分到某一类下是不太可能的,必须要借助一定的语言环境。一般情况下,经常同时出现的两个事物之间具有一定的相互关联性,所以本文基于关键词和分类号的同现信息实现二者的转换。
国内各图书情报机构、信息中心以及文献数据库等这些机构都积累了大量的标引记录,这些标引记录包含了分类标引和主题标引双重数据,而且分类标引大都采用《中图法》作为分类工具,主题标引包括主题词和关键词。所以可以批量下载这种标引记录,对这些数据进行有效整理,然后通过一定的算法建立关键词和分类号的联系。
本系统直接利用本实验室开发的“基于知识库的中文信息自动标引和自动分类系统”的现有知识库数据。该知识库是在《中图法》的基础上,通过机器标引统计归纳出众多人工标引记录中所凝结的标引经验,建立分类号、主题词、关键词之间的概念对应关系。它的主体是“分类号—关键词串”对应表,其中的分类号采用的是《中图法》类号,关键词串是从标引数据中下载来的,通过共现统计的算法计算两者之间的相关度,进而确定它们的关系,它们之间建立的是一对一或一对多的对应关系。如《中图法》分类号“G41/思想政治教育、德育”,对应的关键词串有“学校教育—德育;道德—德育;公民教育—学校—德育;生命科学—教育—学生—德育;思想政治教育—学校教育”等。本系统在此“分类号—关键词串”对应表的基础上,再设计算法实现关键词到分类号的对应,此处利用文7中提到的归属度来测定二者的相关性。
一个类目概念可由若干个关键词匹配表达,即同一关键词可以表达多个不同的类目概念,对应多个不同的分类号,其中每个关键词在表达类目概念中所处的地位和作用是不同的,也就是说每个关键词与类目之间在概念上的归属程度是不同的。若该关键词表达类目概念的能力越强,说明该关键词对该类目概念的归属程度越大,反之则越小。因此,可以通过测度关键词到类目概念的这种归属度,进而确定二者的相关性,归属度越大,说明关键词和该类号的相关性越大,归属到该类的可能性就越大。可用如下公式表达:
![]()
其中,Class表示《中图法》某一类目概念对应的分类号,该类目概念在主题描述上由n个关键词keyword组配表达,association表示该关键词对表达类目概念描述的贡献,即归属度,归属度可通过一定的文本统计方法计算出来。
具体思路如下:
(1)首先将上述的分类号—关键词串对应表进行预处理,将关键词串进行拆分,使词和类号之间形成一对一的形式,建立分类号—关键词对应表,其中,一个分类号可以对应若干个关键词,一个关键词也可对应若干个分类号。
(2)词频统计。利用程序及SQL语句分别统计分类号和关键词出现的频次及二者同时出现的频次。
(3)相关度计算。用相关度的度量来确定关键词和分类号之间的归属度。有关相关度度量的方法有多种,采用上文中用到的Dice测度方法作为统计方法。
![]()
其中:freq_gx为分类号和词共同出现的频次,fre_flh为分类号出现的频次,fre_ztc为关键词出现的频次。
(4)根据上述计算公式,可以计算出每个关键词和不同类号的归属度,将每一分类号对应的关键词按归属度大小排序,取值排在前十位的词,即允许每个分类号最多对应十个关键词。
至此完成关键词到分类号的互操作,建立关键词—分类号对应表。本系统主要是为用户提供自然语言入口,当用户以关键词检索时则到该知识库中查找,如果找到对应的关键词,则直接提供对应的分类号,进而在此分类号的基础上再查看其他对应词表的信息。如果没有找到对应关键词,则再进行关键词和主题词的转换,下面将做详细介绍。
4.4.2 自然语言到主题语言的转换
自然语言到主题语言的转换,就是要实现关键词和主题词之间的转换,即在关键词和主题词之间建立联系。近年来,很多学者都致力于这方面的研究,也提出了一些解决方法,综合这些方法来看,不外乎两种基本思想:一是基于词汇同现信息进行相关度计算;二是计算语词之间的相似度。计算方法基本上都是在这两种思想的基础上,作一些算法上的改动或创新,从而提高转换的准确性。
伯克莱大学的SIMS学院在其数字图书馆项目中就研究了如何将用户的自然语言转换成受控词表。主要是创建一个入口词汇模块(Entry Vocabulary Modules,EVM),从受控词表数据库MELVYL系统下载训练集记录,通过统计自然语言词和受控词表词的频次,采用最大似然估计法(LogL)计算其相似度,进而确定两者的对应关系,从而完成EVM的构建。然后在这部词典的基础上将用户输入的自然语言词汇转换为最有可能的受控词表,如DDC分类号、LCSH中的标题词等8。
基于词汇同现信息分析的方法的前提假设就是同义词或者相关词经常一起出现,经常一起出现的词是同义词。这种算法需要收集大量的同现数据,有足够大的语料库,计算的准确度才能得到保证。另外这种方法需要事先建好关键词和主题词的对应关系,所以对于识别新词、未登录词,就会比较困难。鉴于此,本系统采用第二种思想,通过计算语词相似度来确定关键词和主题词的对应关系。计算语词相似度的方法有很多,上文也已作了介绍,每种方法各有利弊,这里,我们仍然采用基于同义词表的方法来进行计算。
上文已通过几种途径建立了同义词表,该同义词表中包含有主题词,也有关键词。系统主要是为用户提供自然语言入口,对用户输入的关键词经过匹配转换后,将对应的或相关的主题词提供给用户,从而使用户进一步查看其他词表的信息。关键词到主题词的转换主要包括三种情况:一是直接找到同义主题词或准同义主题词;二是经过相似度计算,提供相关主题词;三是找不到匹配结果,直接将关键词作为新的主题词加入词表。整个匹配转换过程如图4-8所示。
首先判断用户输入的检索词是否是主题词,如果是则直接返回其对应的主题词信息;如果不是则基于同义词表对其进行切分,若不可以切分,说明该词是新词,同义词表中没有收录,则将其加入到同义词表及主题词表中。若可以切分,又分为两种情况:一是切分结果有对应ID号,说明同义词表中收录有该词及其同义词,再判断其同义词,如果是主题词,则直接提供给用户,如果也是关键词,则继续计算其相似度。另一种切分结果是多个ID号或词素的集合,则利用相似度计算公式计算该词和《中分表》主题词的相似度,设定阈值大于等于0.6的词为同义词,如果没有对应主题词,也将该词作为新词加入到同义词表和主题词表中,如果有对应的或相关的主题词,则提供给用户,从而使用户在主题词的基础上查看其他词表的相关信息。
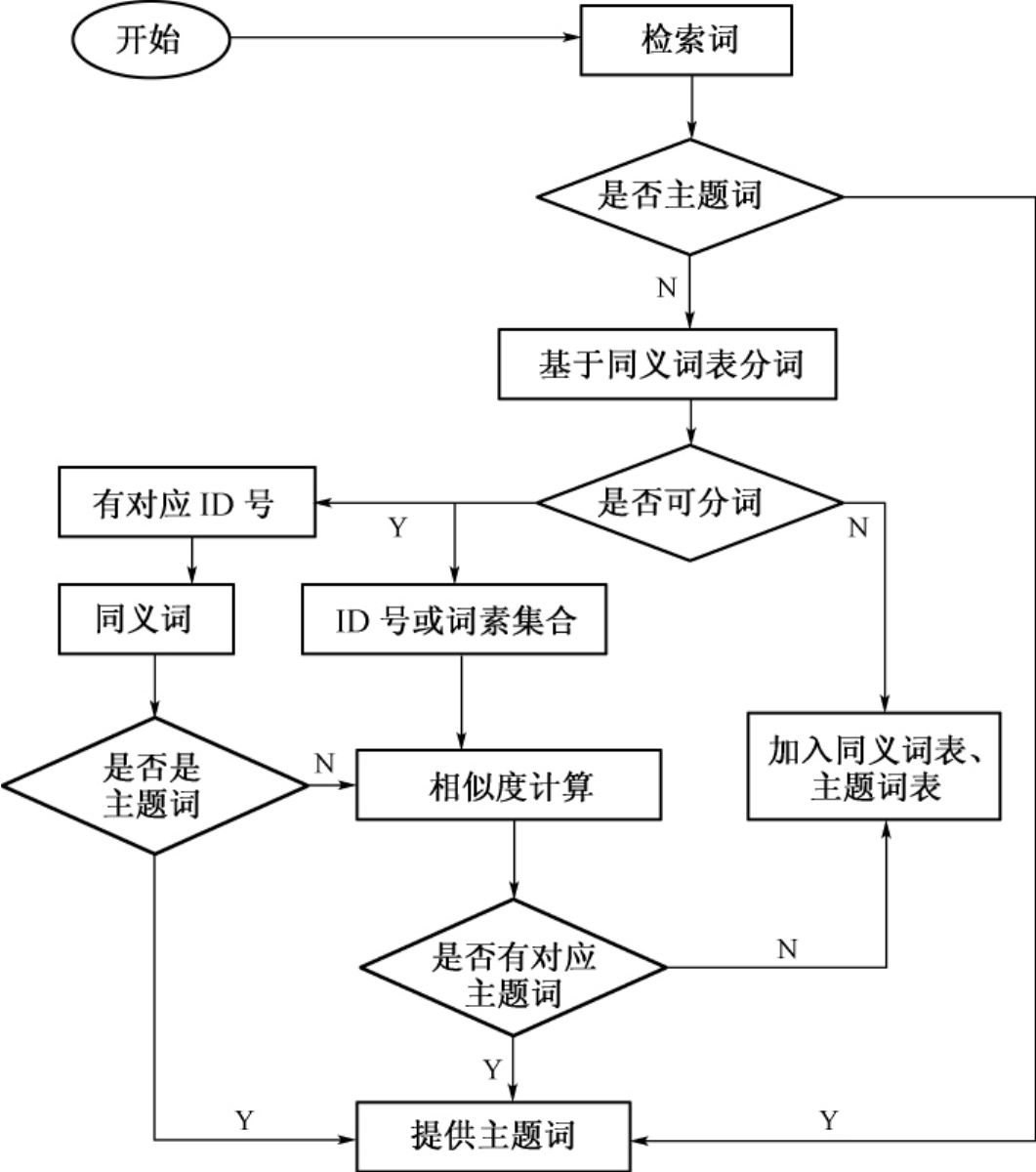
图4-8 对应转换基本流程
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










