



4.3 主题语言互操作技术
从20世纪60年代起我国开始研究主题受控词表,到目前为止,据不完全统计已编制主题词表大约100多种,这些众多词表无规律、不受任何控制地增长,给文献检索增添了新的困难和麻烦。于是,出现了叙词表兼容化的趋势。由于各个叙词表的编制人员、编表原则、收录范围等因素的不同,各个叙词表之间存在着较大的差异,要实现叙词表之间的转换是一项非常复杂的工作。如果仅靠人工进行词汇的对应,不仅费时费力,而且效果并不理想。借助计算机技术,辅助完成词表之间的转换是目前通用的方法,而国内对这一方面的研究还很少,本系统探讨以下几种方法来实现《教词表》、《社科表》到《中分表》的互操作,从而完成教育集成词库的构建。
主题词表互操作不同于分类法,尽管叙词的概念含义也受语言环境影响,但这毕竟是次要的,基本上可以利用词汇的表达形式来判断。主题词表的互操作主要就是进行词汇的规范和协调。主题词表都具有规范的结构形式,除主题词本身外,还包括代、属、分、参等参照项内容,在实现不同主题词表间的互操作时,也要考虑这些参照项内容,最终将表达同一概念的不同表达形式的主题词之间建立映射关系。
4.3.1 基于词表结构的自动匹配
自动匹配转换实质是借助各词表本身结构的兼容性,当词汇以机器可读形式存在时,使两词表相互对应的词可由计算机自动进行匹配转换。通常情况下,两词表的结构越相似,学科覆盖重合率越高,则可自动转换的词就越多。对词表兼容性影响较大的主要是词表的微观显示结构,即每一条叙词款目的构成。如果两表的显示结构越相似,数据处理就越容易,二者的兼容转换就越容易实现。张雪英在她的硕士论文中曾利用这种方法设计了经济叙词表—叙词表的转换系统,证明了该方法的可行性5。本系统也利用这种思想,通过词表本身的结构形式和款目参照关系,进行自动匹配转换,实现词表中部分词汇的转换。选用的《中分表》、《教词表》和《社科表》,都属于分面叙词表,其款目格式见表4-3所示。
表4-3 叙词款目格式对照表
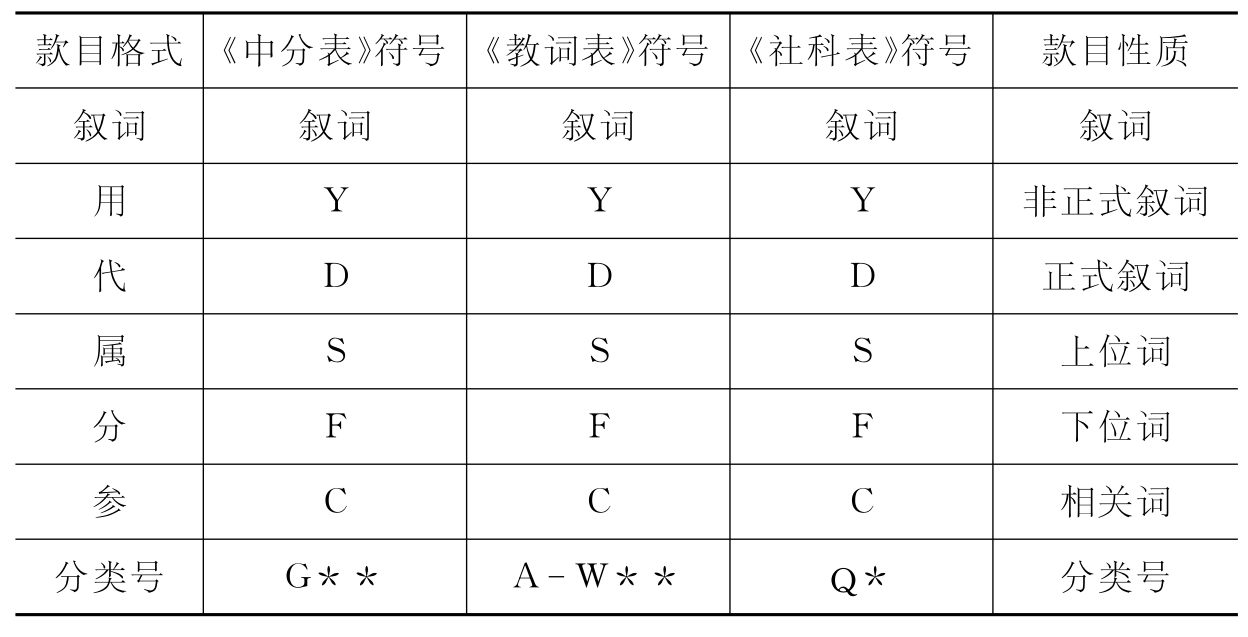
从上表中可以看出,《中分表》、《教词表》和《社科表》的款目格式几乎完全相同,所以利用其结构形式进行词表间的自动匹配是完全可行的。下面详细来说明该方法的可行性。
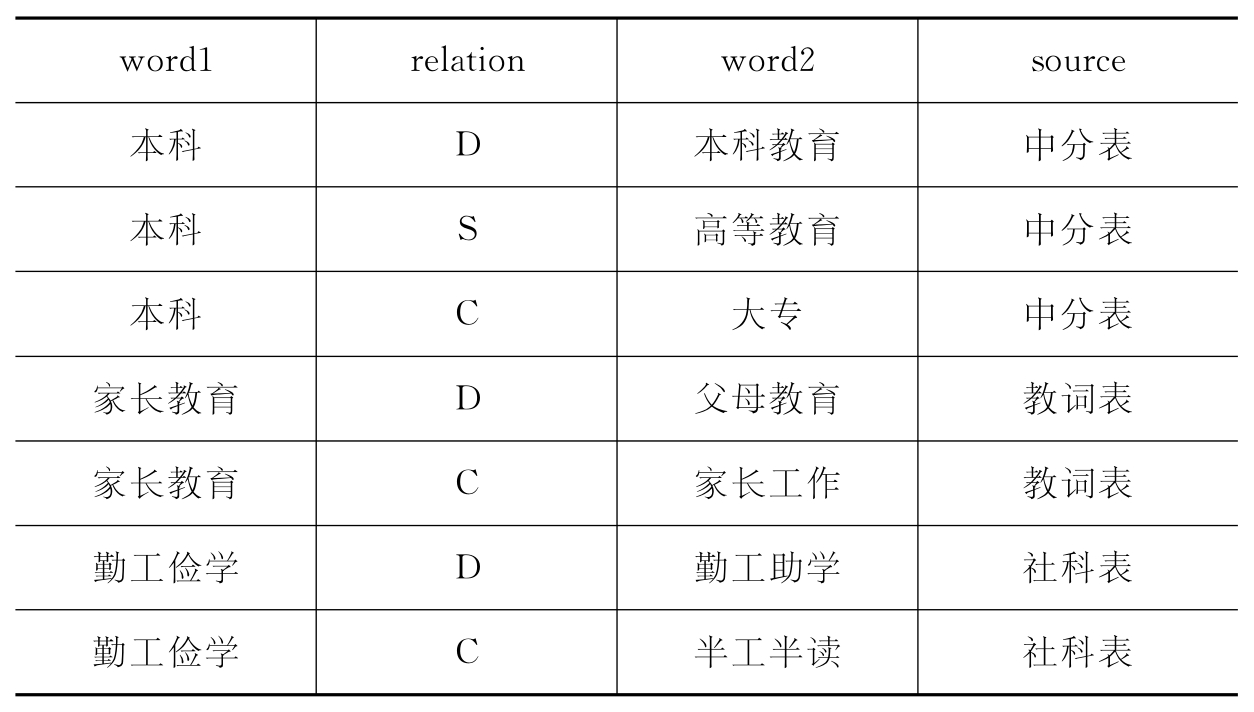
(1)词表数据格式转换:主题词表对应的记录字段包括主题词、分类号、用、代、属、分、参等,即将每个词汇及其所有参照项组成一条记录。通常情况下,人们习惯用这种方式存储词表,以尽可能与原表保持一致。但在联机集成词表中,这样的存储格式既不便于词表数据的读取,也不便词表的动态维护。所以,利用程序进行转换,将每个词汇对应的参照项逐条显示,形成词、关系、词及其词表来源的格式,具体格式如表4-4所示。
表4-4 词汇关系表
(2)反参照的生成:对步骤1中生成的对应词汇,利用计算机程序生成对应的反参照条目,“D”对应“Y”,“S”对应“F”,“C”对应“C”。
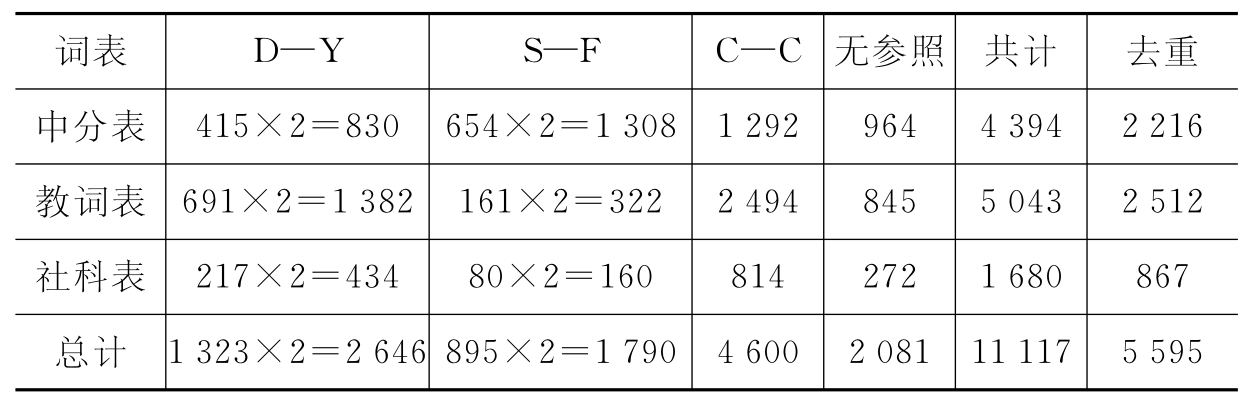
经过上述处理后,将所有叙词、非叙词及其对应参照项集成在一起,方便数据的读取。《中分表》、《教词表》和《社科表》转换后的数据统计如表4-5所示。
表4-5 《中分表》、《教词表》和《社科表》教育类数据统计
(3)自动匹配:通过上述转换后,将词表中所有叙词、非叙词逐一列出,然后分别实现由《教词表》、《社科表》到《中分表》的自动匹配转换,匹配类型分为如下三种:
①完全匹配:是指将两词表的叙词进行完全匹配,即《教词表》或《社科表》中的叙词在《中分表》中可以找到完全对应的叙词,则直接将其对应到该词下。例如“暗示教学”一词,在《教词表》、《社科表》及《中分表》中都以叙词存在,将其直接添加到主题兼容矩阵中的“暗示教学”词下。
②同义词匹配:此处的同义词是指在某一词表中具有“用”、“代”关系的词汇。由于编表人员和收词原则的不同,同一词汇在不同词表中可能与不同的词汇具有“用”、“代”关系,因而可以根据各表提供的不同参照将这些词汇集中起来,即将两词表的叙词与非叙词、非叙词与非叙词之间进行匹配。例如“罢课”一词,在《中分表》为正式叙词,而在《教词表》中用“学潮”作为正式叙词,“罢课”作为非叙词。通过转换可以在“罢课”和“学潮”之间实现匹配。
③组配匹配:因为《中分表》主题词中很多是采用组配方式构成的主题词串,而《教词表》、《社科表》中都是独立的叙词,在这种情况下,将独立叙词也同样采用组代形式构成词串,进而与《中分表》的主题词串对应,这种情况是直接可以找到对应的独立叙词进行组配。例如《中分表》中的主题词串“初等教育/教学法”,而《教词表》有独立叙词“初等教育/ED2”、“教学法/MQ”,则将其进行组配对应到“初等教育/教学法”主题词串下。另外对于一些表达两个或两个以上复杂概念的主题词,需要先将其进行手工概念的分解,然后再进行组配。如主题词“教育改革与发展”,可以用“教育改革/DM”、“教育发展/DQ”,进行组配表示。
整个匹配模式可用图4-5表示如下:
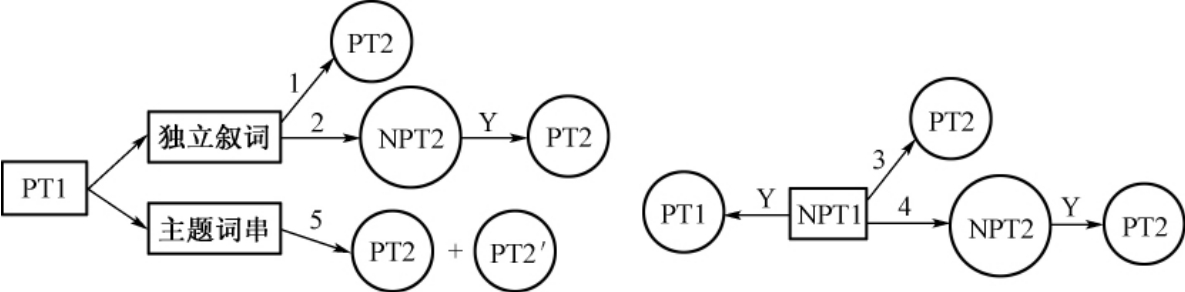
图4-5 自动匹配模式
其中,PT1表示源词表中的叙词,NPT1表示源词表中的非叙词;
PT2表示兼容词表中的叙词,NPT2表示兼容词表中的非叙词;
1 表示叙词和叙词匹配,即PT1和PT2直接匹配;
2 表示叙词和非叙词匹配,即PT1和NPT2匹配,又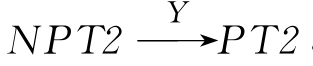 ,则PT1和PT2匹配;
,则PT1和PT2匹配;
3 表示非叙词和叙词匹配,即NPT1和PT2匹配,又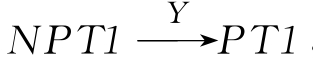 ,则PTI和PT2匹配;
,则PTI和PT2匹配;
4 表示非叙词和非叙词匹配,即NPT1和NPT2匹配,又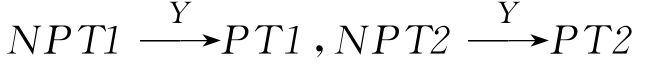 ,则PTI和 PT2匹配。
,则PTI和 PT2匹配。
5 表示如果PT1是主题词串,则用PT2+PT2′组配匹配。
匹配过程按1、2、3、4、5的顺序进行,最终在各词表的正式叙词之间建立关系。
通过上述方法,分别完成《教词表》和《社科表》到《中分表》的匹配,匹配结果如表4-6所示。
表4-6 自动匹配结果统计
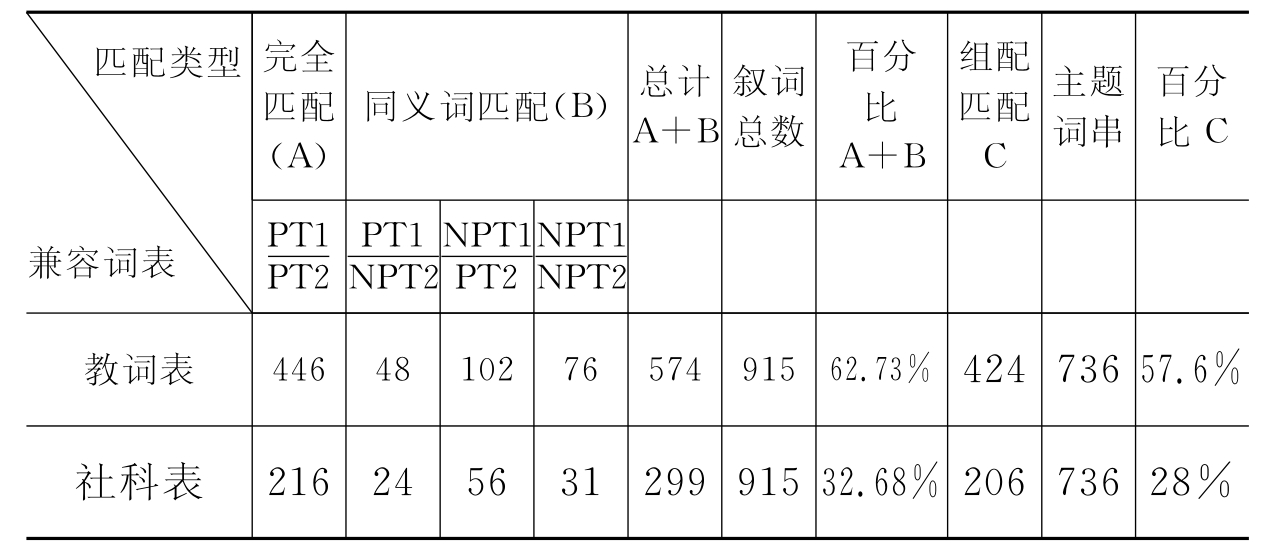
由上表数据可以看出,采用自动匹配转换实现叙词表之间的互操作是完全可行的,可以将各词表中完全相同或同义词相同的叙词之间实现兼容,尤其是《教词表》,其覆盖度达到了62.73%,也就是说一半多的独立叙词可以通过自动匹配实现转换,因为该词表是教育专业词表,本身收录有《中图法》教育类目数据,所以转换率比较高;而对于《社科表》,其覆盖度偏低,因为它是一部综合词表,教育类只是其中的一个小类,参与转换的数据就少,所以会影响整个覆盖度。另外,通过组配也可以实现《中分表》中主题词串的部分匹配。针对词表中不能实现自动匹配的叙词,考虑采用其他方法来解决。
4.3.2 基于同义词表的语词匹配
自动匹配转换可以将各词表中完全相同的叙词或非叙词之间以及组配的主题词串之间实现兼容,而对于那些不能完全兼容的语词则需要采用其他方法来匹配。基本思想是识别出不同词表中的同义词,将其进行匹配,此处的同义词包括意义完全相等的词以及意义相近或相关的词。由于汉语构词特点,大部分意义相同或相近的语词大多包含有相同的字,所以基于单汉字或词素的字面相似度算法是比较常用的一种方法;但该方法最大的不足是对于字面不相似的异形同义词不能很好的识别。针对上述不足,本系统考虑在该算法中引入同义词表,以此提高计算的准确度。
基本思想是首先利用现有的各种技术编制一部语义精良的同义词表,该同义词表可以包括受控词、非受控词、表达完整概念的语词以及不可再切分的词素等;然后将匹配词采用自动分词技术,基于上述同义词表进行切分,切分成一系列词或词素的集合;再根据切分的词或词素设计算法计算相似度,在设计算法时,先将同义词表中有的词或词素进行语义匹配,对无法采用语义匹配方法的词采用基于词素的字面匹配;最后提取相似度在一定阈值范围内的词作为同义词或相关词,匹配到对应《中分表》主题词下。具体实现步骤如下:
(1)同义词表的编制:通过各种途径收集教育类语词,编制同义词表。为计算方便,为每个词赋予一个ID号,则将同义词用相同的ID号标注。主要利用以下几种途径来完成同义词表的编制。
①主要是采用陆勇的硕士论文中提到的基于模式匹配的汉语同义词自动识别方法6,对不同的语料库定义不同的模式,从而提取和挖掘相应的同义词。
首先,《教育大辞典》作为教育专科词典,汇集并解释了教育学科的术语、概念,提供最基本的学科知识,通过同义词定义模式,例如“亦称…”,“也称…”,“简称…”,“…的简称”,“俗称…”等等,可以从中提取出常用的教育名词、术语及其同义词。如教育功能亦称“教育作用”或“教育智能”,则提取“教育功能、教育作用、教育智能”为同义词。
其次,Web网页和期刊论文包含的信息量大,种类多,更新快,可以获取更多的、最新的同义词,通常以括号( )这个特殊的标志引出,同义词类型主要包括一些译词和缩略语等。如高等教育文献保障系统(CALIS);大学招生策进会(招策会)。
最后,不同的语料库,同义词出现的模式有其自身的特点,通过分析发现,有一些含有同义词信息的语句,对其模式很难统一定义、规范,从而遗漏掉一些同义词。可以利用模式直接将语料库中一些含有同义词信息的语句提取出来,然后进行人工识别,从中挑选出同义词。
②现有词表中具有“用”、“代”关系的词汇,直接作为同义词对,赋予其相同的ID号,加入到同义词表中。此处包括《中分表》、《教词表》及《社科表》的所有具有“用”“代”关系的叙词和非叙词。
③《同义词词林》中的同义词对。《同义词词林》是一部对汉语词汇按语义全面分类的词典,对不同的词汇进行分类,并赋予相应的语义编码,具有相同语义编码的词即为同义词。根据上文已建立的词素词典,从《同义词词林》中抽取这些词素及其对应编码,并将同一语义编码下的词作为该词素的同义词。
经过上述处理,将收集到的三种同义词数据整合去重,加入适当的人工识别,删除掉一些明显错误的记录,基本的同义词表编制完成,每个词对应一个ID号,同一ID号下的词为同义词,其格式如下:

因为此处的同义词表还将作为分词词典使用,对于没有同义词的词素也要添加在内,供下面分词使用,对这些词素可以不赋ID号。
(2)对匹配词进行切分,将其切分成多个词或词素的集合。采用最大正向匹配算法(MM法)对匹配词进行分词。基于步骤1中建立的同义词表进行分词,分词分为以下三种情况:如果匹配词可以直接在同义词表中找到,则直接用对应的ID号来标识该词;如果匹配词被切分的词素有对应的ID号,也将其用词素对应的ID号标识;如果词素没有对应ID号,则直接用对应的词素对其进行标记。如:

分词完成之后,由人工进行进一步的判断,修改、删除明显切分错误的记录。
(3)利用相似度计算公式,计算两个词之间的相似度。经过上述分词后,将每个词用词素或ID号进行标识,然后采用上文提到的基于词素的相似度计算公式来进行计算。此处的计算单位可以是ID号也可以是词素,通过计算两个词所含的相同ID号或词素个数以及它们在各词中的位置来计算其相似度,仍然根据“重心后移”的特点取不同权重计算。
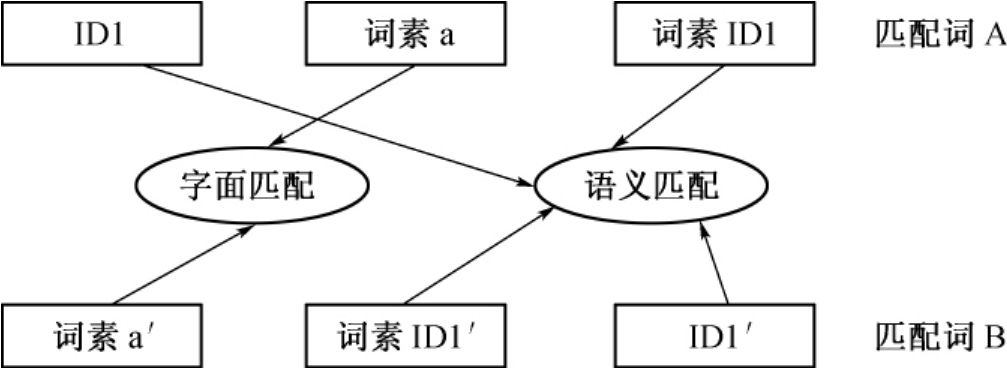
图4-6 同义词相似匹配算法示意图
(4)确定上述计算公式后,然后利用程序进行计算。实际计算过程中,仍然要考虑不同词表的不同表达形式,分别计算匹配词表和源词表中的叙词与叙词、叙词与非叙词以及非叙词与非叙词之间的相似度,需要进行四次交叉匹配,这里用PT表示叙词,NPT表示非叙词,则需要进行如下匹配:PT1/PT2、PT1/NPT2、NTP1/PT2、NPT1/NPT2。
(5)确定阈值,筛选主题词。通过上述公式可以计算出不同词表中每两个词之间的相似度,但不可能都作为映射结果,需要设定一个标准,筛选出合理的对应主题词,即可为《中分表》每个主题词提供一系列对应的主题词数据,供用户进行进一步的选择。系统通过一定的实验后,确定阈值为0.6,即提取出结果大于等于0.6的词,认为这两个词相似,将其添加到对应《中分表》主题词后。
(6)通过上述处理过程,基本完成了不同主题词表间的互操作,还需人工判断,删除掉其中错误的及不合理的兼容词,并通过适当识别加入一些对应兼容词,结果允许一个主题词对应多个主题词现象的存在。
(7)通过程序将上述两种匹配结果进行合并去重,以《中分表》主题词为主干竖向展示,将对应的兼容词表的主题词及分类号(一个或多个)放入一个字段中,横向展示。最终能够通过《中分表》主题词,可以方便、快捷的找到其完全对应的或相关的主题词,以供用户进一步选择。
整个过程可用以流程图4-7表示。
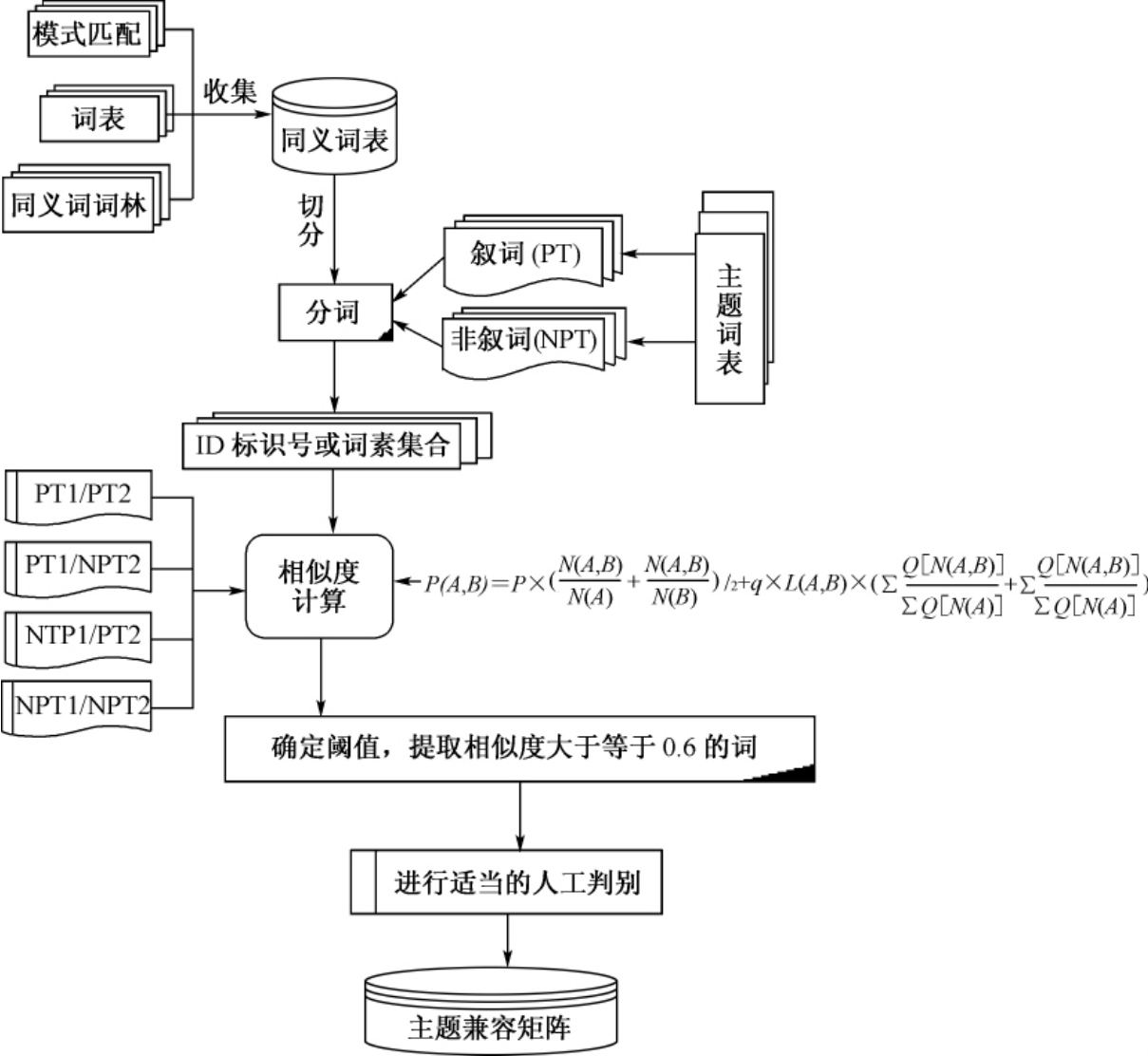
图4-7 基于同义词表的语词匹配流程图
通过上述方法,分别完成《教词表》和《社科表》到《中分表》的匹配,匹配结果如表4-7所示。
表4-7 相似度匹配结果统计
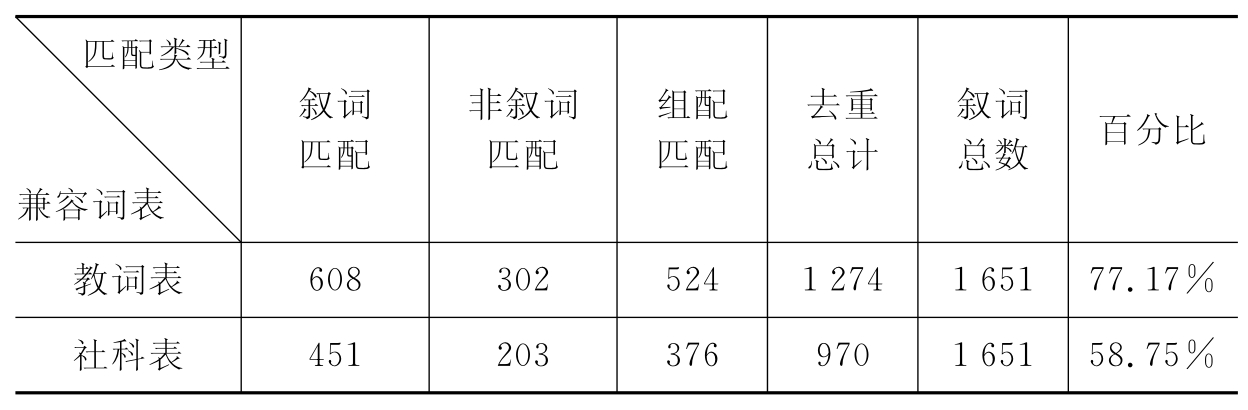
由上表数据可以看出,采用基于同义词表的语词匹配算法是完全可行的,加入同义词表,明显提高了相似度计算的准确性,从而使匹配覆盖度有了明显的提高。《教词表》的覆盖度达到了77.17%,也就是说通过这种方法可以使一大部分的叙词实现转换,证明了该种方法的可行性。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










