



第三节 相关分析
一、定距变量的相关分析
按照数量的类型,相关系数可以分为定距变量的相关系数和定序变量相关系数两类。
1.相关系数的定义
单相关分析是对两个变量之间的线性相关程度进行分析。单相关分析所采用的尺度为单相关系数,简称相关系数。通常以ρ表示总体的相关系数,以r表示样本的相关系数。
总体相关系数ρ因为涉及样本量太多,一般为未知。能够计算的是样本相关系数r。
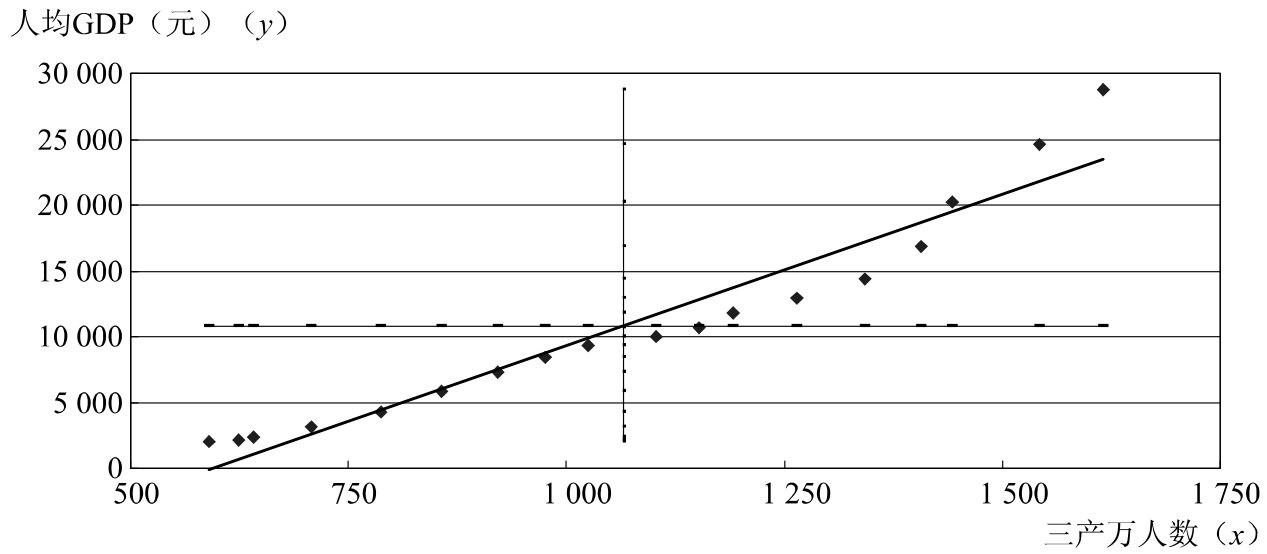
图10.1 1989-2006年江苏人均GDP与三产人数
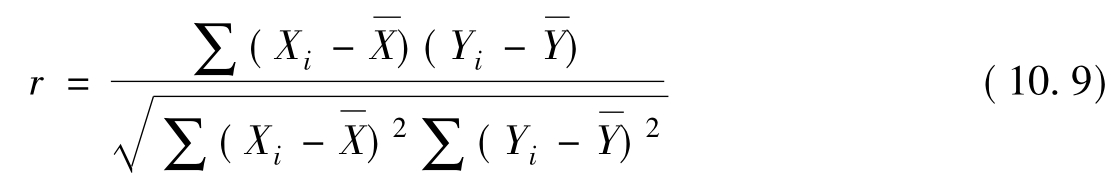
应该说明的是,根据样本观测值计算出来的是样本相关系数r,由于抽取的样本不同,其具体的数值也会有所差异,样本相关系数和总体相关系数ρ是有差异的。
2.相关系数的特点
样本相关系数r有以下特点:
(1)线性相关关系r的取值介于-1与1之间。在大多数情况下,0<|r|<1,即样本观测值X与Y之间存在着一定的线性关系,当r>0时,X与Y为正相关;当r<0时,X与Y为负相关。
(2)当r=0时,X与Y的样本观测值之间没有线性关系,有可能存在非线性相关关系。若|r|=1,则表明X与Y完全线性相关,当r=1时,称为完全正相关,而r=-1时,称为完全负相关。
3.相关系数的计算
相关系数(包括下章讲的回归系数)的计算有多种方法,大致分由计算机计算和计数器计算两种。前者又分由Excel软件、SPSS软件或其他软件计算,一般常用的是Excel软件。该软件有电子表格计算、函数和固定模块程序三种计算方法(这些见附件);若使用电子表格可以直接使用公式(7.1)进行计算,公式(7.1)的优点是容易记忆,但计算需要用两步,首先计算X、Y的平均值,然后才能计算相关系数;若由公式(10.9)通过数学变化而获得公式(10.10),则可以一步计算成功。
若将公式(10.9)的平方和进行分解,可以获得如下计算公式:
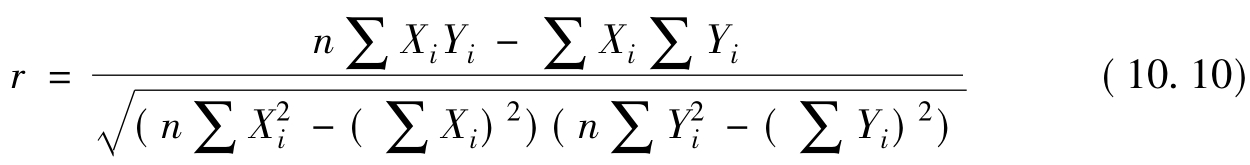
上式虽难以记忆,但计算过程清楚,可一步到位直接计算出来。兹以例10.5为例。
[例10.5]1989~2006年三产人口数(X)和江苏人均GDP(Y)资料如表10.4所示。试计算样本间相关系数。
表10.4 1989-2006年某省三产人口数(X)和人均GDP(Y)数据
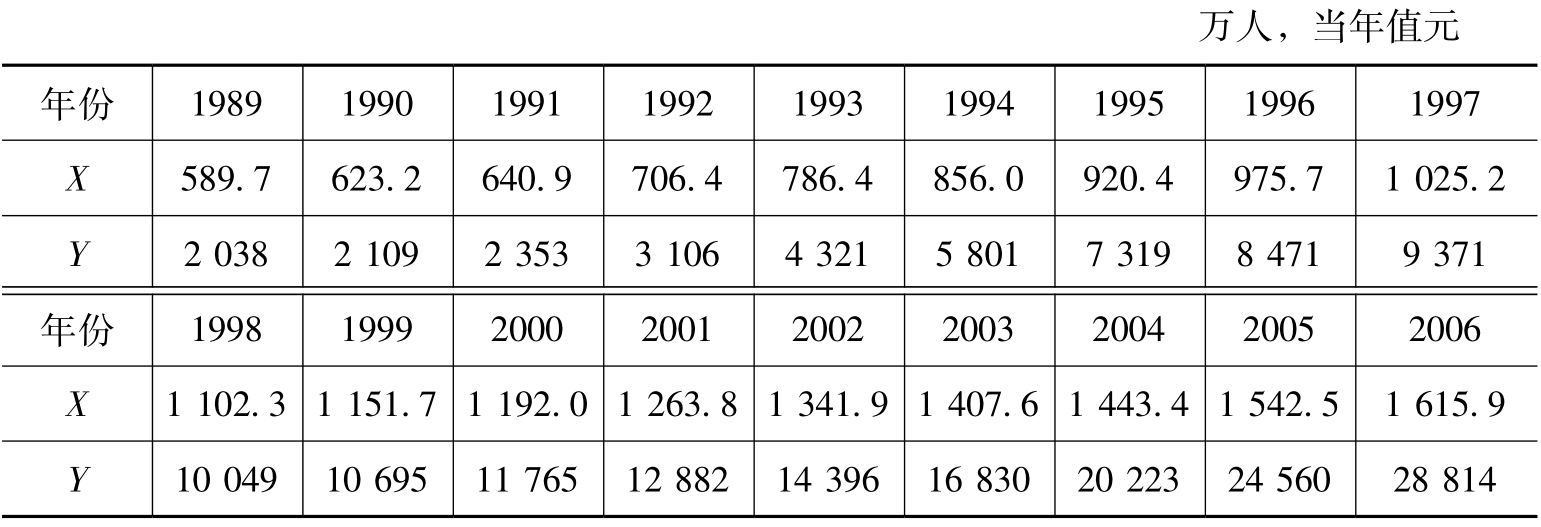
表10.5 Excel通用表格计算方案
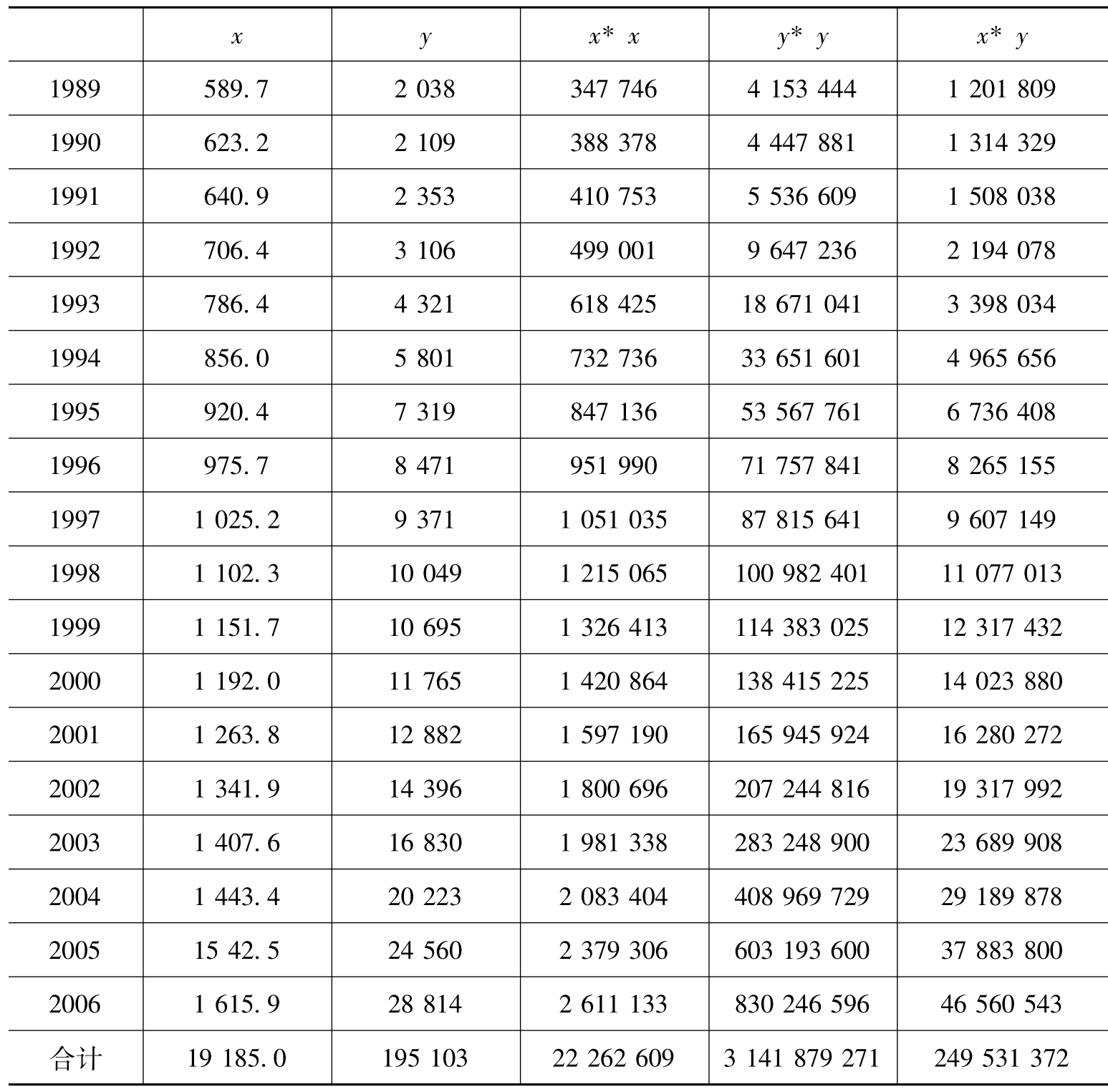
[解]将表10.4中的有关数据代入(10.10)式,可得
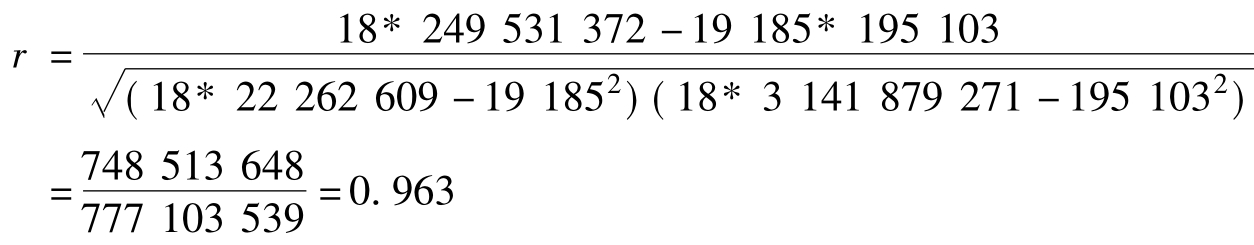
4.相关系数的检验
在实际的社会现象分析研究中,相关系数一般都是利用部分样本数据计算的,因而带有一定的随机性。相关系数大,比如0.7、0.8,不一定就具有相关意义;相关系数小,比如0.3、0.4,同时不一定就不存在相关关系。一般认为,样本容量越小、其可信程度就越差,因此也需要进行检验。
假定X与Y都服从于正态分布,当相关系数符号或方向未知时,可采用双向(双侧)检验,总体相关系数ρ为零;反之,若已知相关方向的情况下,应采用单向(单侧)检验。相关系数检验一般采用t检验来确定r的显著性。其步骤如下:
首先,H0∶ρ=0 H1∶ρ≠0
其次,计算样本相关系数r的t值:
![]()
最后,根据给定的显著性水平和自由度(n-2),查找t分布表中相应的临界值tα/2。若|t|≥tα/2,即否定原假设,表明r在统计上是显著的;若|t|≤tα/2,即没有足够证据否定原假设,表明r在统计上是不显著的。
实际上,由t的临界值可计算出相关系数r的临界值:
![]()
若计算的r绝对值大于表载值rα/2,则相关显著;反之,认为没有相关关系。
当已知为正相关方向的前提下,如小孩年龄与身高等,即需假设H0∶ρ≤0,H1∶ρ>0;若在已知是负相关方向的前提下,如受教育年数和生育子女数,假设H0∶ρ≥0,H1∶ρ<0。
若在单侧检验的情况下,同样可以计算样本相关系数r,进而计算t值。根据给定的显著性水平和自由度(n-2),查找t分布表中相应的临界值tα。若t≥tα,即否定原假设H0,表明r在统计上是显著正(负)相关;反之,若t<tα,即没有足够证据否定原假设,表明r在统计上是不显著的,可能没有线性相关关系。单侧检验比较难,但双侧检验一定要掌握。
[例10.6]设根据对样本观测数据计算出某公司的股票价格与气温的样本相关系数r=0.50,试问是否可以根据5%的显著水平认为该公司的股票与气温之间存在一定程度的线性相关关系?
[解]H0∶ρ=0H1∶ρ≠0
将以上数据代入(10.4)式,计算r的t检验值
![]()
查表可知:显著水平为5%,自由度为4的临界值,tα/2=2.776,上式中的t值小于2.2776,因此,r不能通过显著性检验。这就是说,尽管根据样本观测值计算的r达到0.5,但是由于样本单位过少,这一结论并不可靠,它不足以证明该公司的股票与气温之间存在一定程度的线性相关关系。
5.Excel函数计算方案
现在,计算相关和回归系数的方法很多,以Excel软件为例,除了前文讲的通用方案外,还有函数计算和应用程序块两大类。这里讲函数计算,下一节讲应用程序块(数据分析)进行分析和计算。
按∑旁的下拉箭头,打开其他函数,在选择类别中选择全部,具体选择CORREL而后确定,在Array1旁选择变量1,比如B2……B19;在Array2旁选择变量2,比如C2……C19。
按确定键即可输出函数计算结果,相关系数为0.96315。类似可以计算回归系数等。
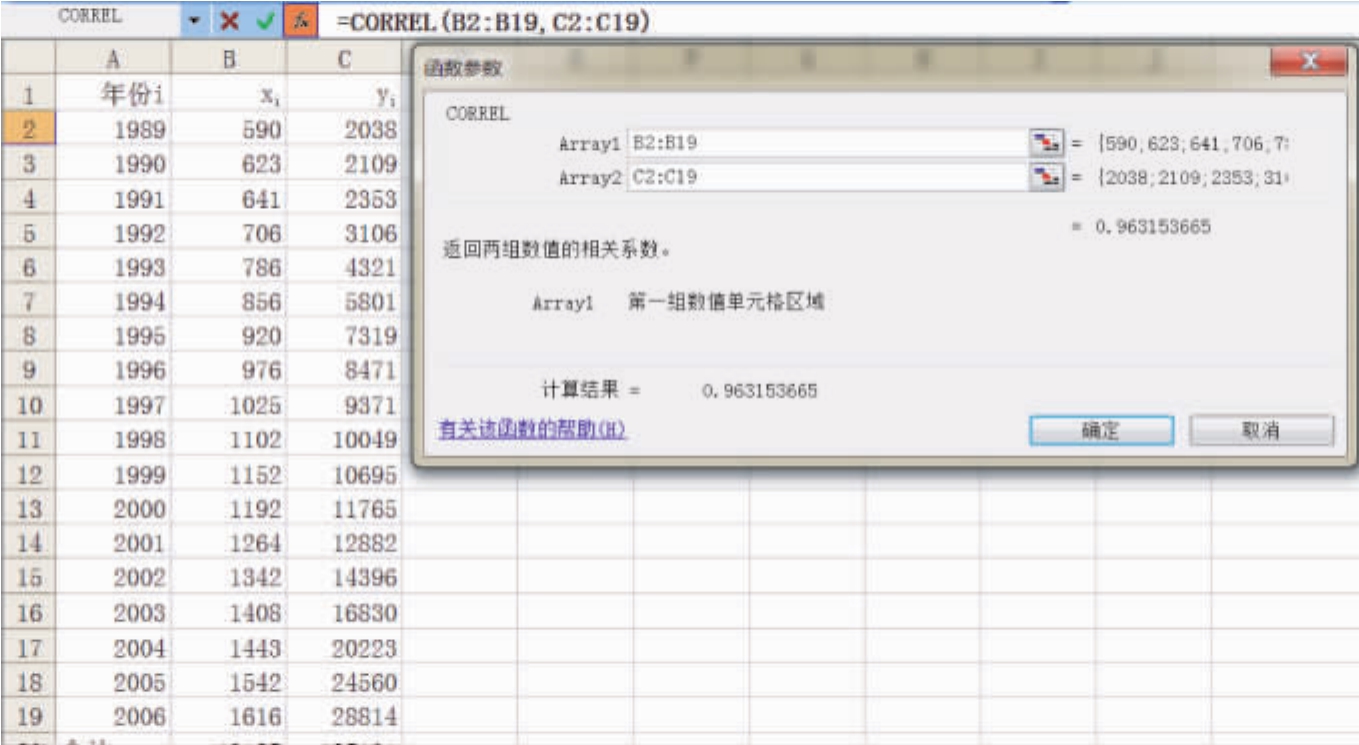
图10.2 相关系数的Excel函数计算示意图
二、定序与定序变量之间的秩相关分析
当遇到非正态分布的变量或者定序变量时,就无法使用Pearson定比(定距)相关模型,需要计算秩模型。或者当定比数据质量不高,不得不将其分组作为定序数据处理。常用的秩相关模型有二,分别介绍如下。
1.Spearman秩相关模型
该模型计算方法是,将相关变量按其值大小排队或评秩,如某一批n个学生入学成绩不符合正态分布,于是将其按高低排队,分别记为Rx1,Rx2,Rx3,……Rxn;对应这批学生的毕业成绩也按高低排队,记为Ry1,Ry2,Ry3……Ryn,则可以用秩相关度量来决定RX和Ry之间的相关性。Spearman秩相关系数计算公式仍为:
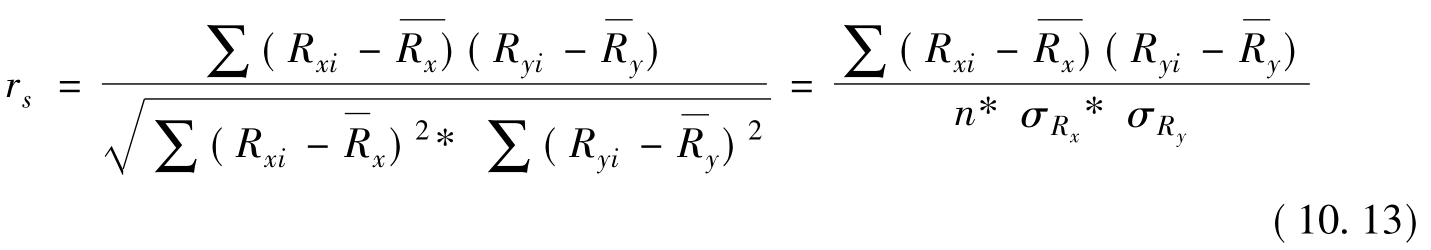
实际上,(10.13)与Pearson相关模型公式(10.9)完全一致,仅是将Xi、Yi的秩次资料Rxi和Ryi取代Xi、Yi原始数值,即(10.13)中的Rxi和Ryi是在相应X、Y变量在i批次人数或频次中的位置值(秩),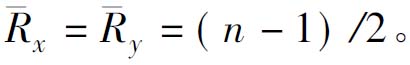 若设等级差di=Rxi-Ryi,则
若设等级差di=Rxi-Ryi,则
![]()
两个计算公式结果完全一致,而公式(10.14)使用更为频繁。
[例10.7]男性消费者和女性消费者对10种商品的主观评分,因为这种评分没有明确标准,如果研究其之间是否一致,则需要计算等级相关系数,如Spearman秩相关系数。
表10.6 男女性对某商品的评分及其等级(秩)
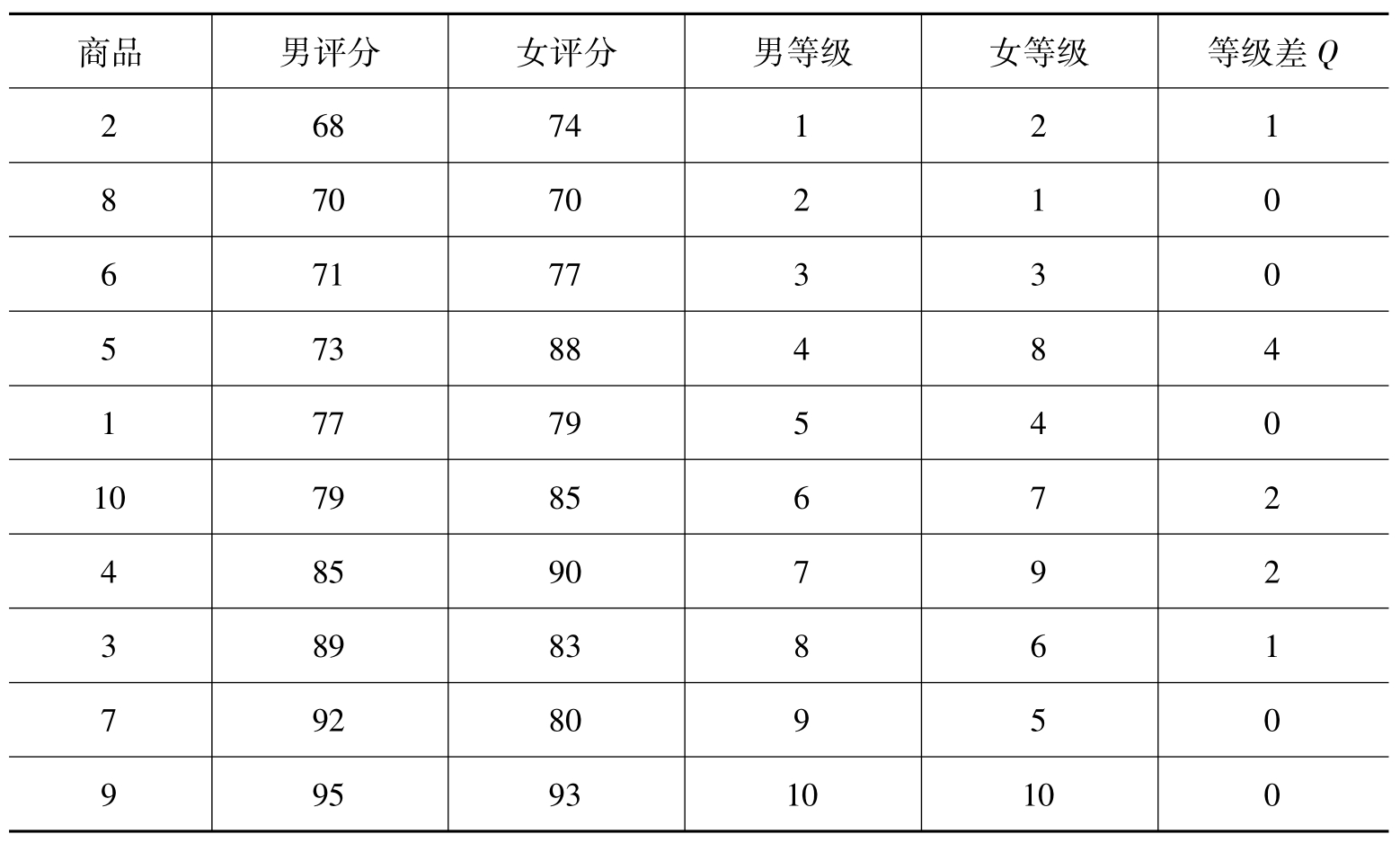
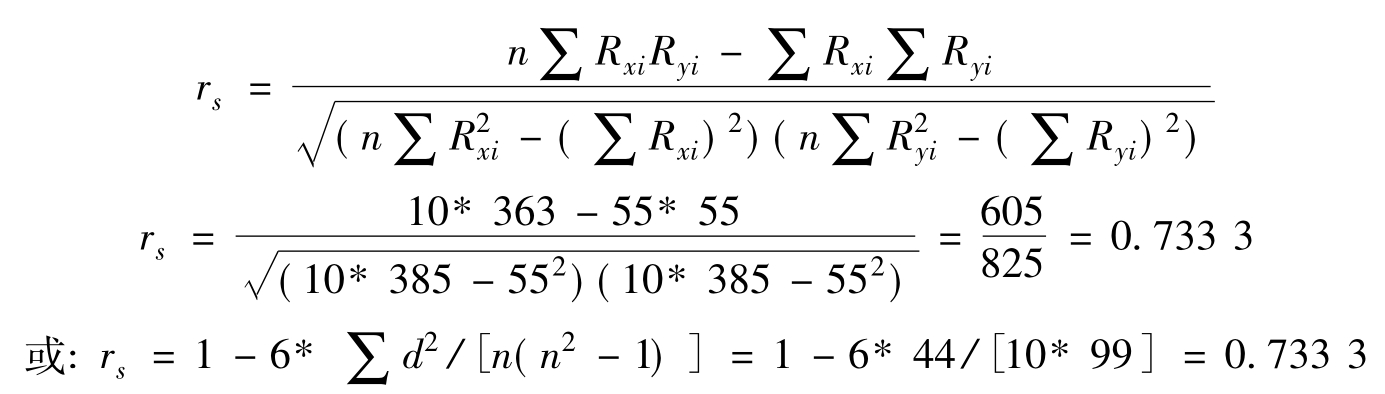
显然,计算结果一致,但后者比前者计算容易多了。该相关系数的临界值可以通过附表10进行检验。对本例而言,显著性水平(α)取0.05,n=10,则rα=0.5515<rs=0.7333,总体相关系数异于零,样本相关显著。应该说明的是,随着计算机的普及和计算条件的改善,该方法的应用得到一定的限制。但对于非正态分布的定序资料,或定序统计资料的分析,该方法使用是有很大潜力的。
2.Kendall秩相关模型
Kendall秩相关模型也是一种比较直观的模型。其思想是先按某一变量X进行排序,再检查另一变量Y与变量X的排序差异,若无差异则变量Y与X完全相关,若差异大则变量Y与X为低度相关或无相关。
[例10.8]假设男女两个消费者对某10件商品的质量进行评价,其评分状态如表10.7,问男女性的评价是否一致?
先将某一消费者(男性)的等级进行排序,以此锁定同一商品另一消费者(女性)的等级,如果男女消费者等级相同,说明认识一致,秩相关系数R为1,但实际情况并不是如此。如果等级不一,则记下每一个后面在秩次上比自己小的个数,并将这些个数累加起来。例如第5号商品,女性评出的秩为8,其后比8小的个数有4个(4,7,6,5),故等级差为4,最后累计等级差的总和Q为10,N为样本总数10。Kendall秩相关系数R为:
R=1-4*Q/[N*(N-1)]=1-4*10/(10*9)=1-4/9=0.55556
Kendall秩相关模型没有给出临界相关系数值,虽临界值R应该与样本容量有关,但一般认为,计算值R大于0.8为非常一致(高度相关),R值小于0.5为基本不一致(不相关)。本例说明男女性对该商品看法基本一致(中度相关)。
三、交叉表Gamma系数的测定
交互分类主要处理的是定类变量与定序变量,或者是定类变量与定序变量之间的相关问题。如果两个变量都是定序变量,可以用Gamma系数来测量它们之间的相关关系。Gamma系数通常用G表示,其取值范围是[-1,+1],适用于分析对称关系,其表示相关的方向和相关的程度。Gamma系数与λ系数一样,也具有消减误差比例的意义。Gamma系数的计算公式是:
G=(Ns-Nd)/(Ns+Nd) (10.15)
其中,Ns表示同序对数目,Nd表示异序对数目。所谓同序对指的是变量大小顺序相同的两个样本点,即其在变量X上的等级高低顺序与在变量y上的等级高低顺序相同(xi>xj且yi>yj);否则就叫做异序对(xi<xj且yi<yj)。下面举例说明Ns和Nd的计算方法。
[例10.9]某地3岁以下婴幼儿身体发育状态与母奶喂养、母亲身体素质、副食品供给和个人吸收消化情况等有关。调查180个婴幼儿身体发育状态与副食品供给资料见表10.8,问婴幼儿身体发育状态是否与家庭副食品供给有关?
表10.7 婴幼儿身体发育状态与副食品供给情况表
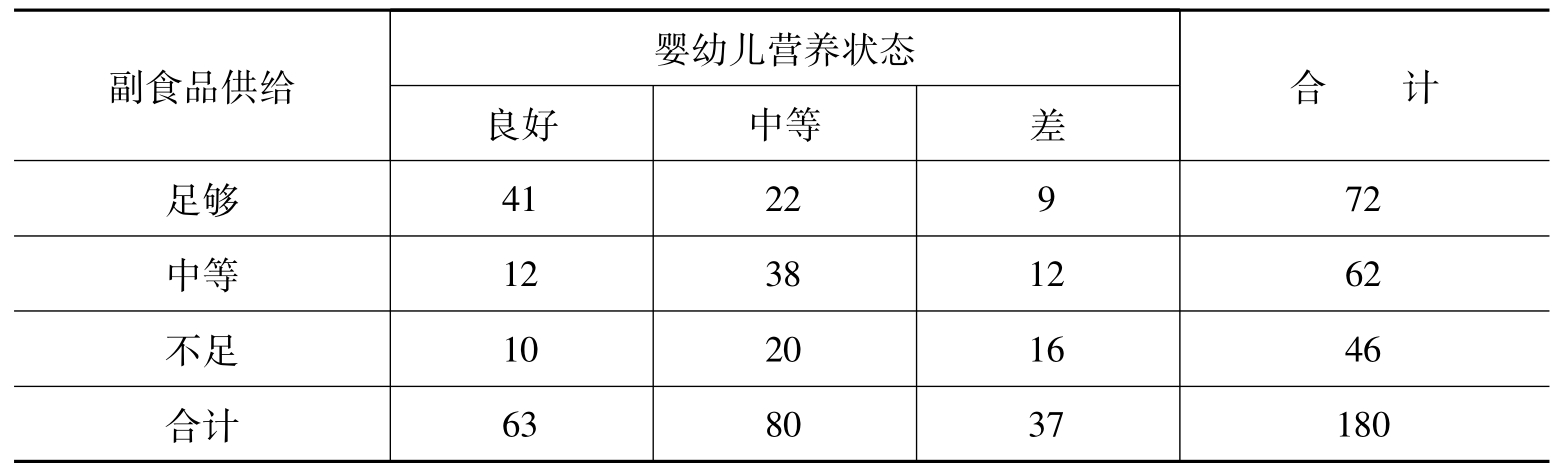
首先将资料按顺序排列,先看第一行第一列格中的41个个案(f11=41),满足同序标准(xi>xj且yi>yj)的有4个格子,分别为f22=38、f23=12、f32=20和f33=16。再看第一行第二列格中的22个个案(f12=22),满足同序标准(xi>xj且yi>yj)的有2个格子,分别为f23=12和f33=16。再看第二行第一列格中的12个个案(f21=12),满足同序标准(xi>xj且yi>yj)的有2个格子,分别为f32=20和f33=16。最后看第二行第二列格中的38个个案(f22=38),满足同序标准(xi>xj且yi>yj)的有1个格子,为f33=16。这样,表中所有的同序对数量Ns为:
Ns=41(38+12+20+16)+22(12+16)+12(20+16)+38(16)=5182
而异序对的求法类似,一般是从右上角的“高—低”9人开始,个案(f13= 9),满足异序标准(xi>xj且yi<yj)的有4个格子,分别为f21=12、f22=38、f31=10和f32=20。再看第一行第二列格中的22个个案(f12=22),满足异序标准(xi>xj且yi<yj)的有2个格子,分别为f21=12和f31=10。再看第二行第三列格中的12个个案(f21=12),满足异序标准(xi<xj且yi>yj)的有2个格子,分别为f32=20和f31=10。最后看第二行第二列格中的38个个案(f22= 38),满足同序标准(xi>xj且yi>yj)的有1个格子,为f31=10。这样,表中所有的异序对数量Nd为:
Nd=9(38+12+20+10)+12(10+20)+22(12+10)+38(10)=1944
因此,代入公式可求得
G=(Ns-Nd)/(Ns+Nd)=(5182-1944)/(5182+1944)=0.4544
即文化程度与收入水平的相关程度为G=0.454。其说明,用文化程度去预测收入水平,可以消减45.4%的误差。
当然,在SPSS统计分析软件中,都可直接给出Gamma系数的值,而不用具体计算。
要将随机样本中有关两定序变量间关系的结果推论到总体,同样必须对其进行统计检验。Gamma系数的抽样分布在随机抽样和样本规模较大的前提下,近似于正态分布。因而其检验通常采用Z检验的方法进行。
为了进行Z检验,必须先将G值转化为Z值。以表10.8中的资料和计算结果为例,将G=0.4544,Ns=5182,Nd=1944,n=180代人公式得:
![]()
根据不同的显著度要求,通过查书后附录的Z检验表可以判定样本中的结果能否在该置信水平下(1-p)推论到总体。比如,要求的显著度为0.05时(即P<0.05),查表可得Z的临界值为1.96。由于本例所计算的Z=3.21>Z0.05= 1.96,故拒绝“相关系数为零”的原假设,认为,在总体中文化程度与收入水平之间存在较强的相关。
四、定类(或定序)与定距变量的强度测定
当两个分析变量一个为定类(或定序)变量,另一个为定距(以上)变量时,我们用相关比率(Correlation Ratio)或eta系数来测量二者间的相关程度。相关比率又称为eta平方系数,记为E2,其数值范围由0到1,也具有消减误差比例的意义。其计算公式为
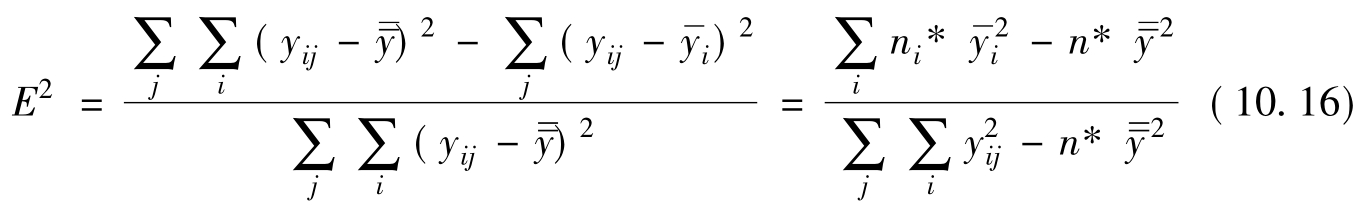
[例10.10]以[例9.3]为例,研究某灯泡厂用四种不同配料材料制成的灯丝,生产四批灯泡。在每批产品中随机地抽取5~8个灯泡测其使用寿命(表9.5)。现在想知道,对于这四种灯丝生产的灯泡,其使用寿命有无显著差异。说明E2的计算方法,求不同灯丝与灯泡使用时间之间的关系。由原资料得:A1配料制成的灯泡进行7次试验,平均使用时间为1674.3小时;A2配料制成的灯泡进行5次试验,平均使用时间为1598.0小时;A3配料制成的灯泡进行8次试验,平均使用时间为1648.8小时;A4配料制成的灯泡进行6次试验,平均使用时间为1575.0小时;合计进行26次试验,平均使用时间为1628.8小时。代入公式

E=0.4273
可见,用不同灯丝来预测或估计灯泡使用时间,可以消减18%的误差。
关于定序变量与定距变量的相关分析,有一点需略作说明。有些社会调查研究者在对资料进行统计分析时,常常将定序变量看作(并非实际等于)定距变量,采用后面将讲到的积矩相关系数来进行计算,甚至进行直线回归分析。比如,将文化程度高、中、低转化为高=3、中=2、低=1,然后将它们作为定距资料进行运算和统计。事实上,这些数字(3、2、1)只具有等级的含义,而不具备定距层次的数学特质,即不能进行加减乘除运算。严格意义上,这样做是不行的。一些研究者之所以这样做,一个主要的原因是当变量上升到定距层次后,可以用来进行各种多元统计分析。
相关比率的E2检验采用的是F检验法,其计算公式为
![]()
其中,k为分组数目,n为样本规模,k-1=df1,n-k=df2。
下面我们分别对前面所得出的相关比率进行F检验。
由于k=4,n=26,E2=0.18,故有F=(0.18/0.82)(22/3)=1.610。
假定所要求的显著度为P<0.05,由本书后所附F检验表可查得df1=3,df2= 22,F的临界值为3.05。由于计算的F=1.61<3.05=F0.05,故不能否定虚无假设。即得到下列结论:从总体上看,不同灯丝对于灯泡使用时间无关。由此可见,本结论和方差分析结论完全一致。
至此,本章已介绍了各种层次变量之间的相关测量与检验方法。这里,可对它们作一总结见表10.8。
表10.8 两变量间关系的测量与检验方法总结表
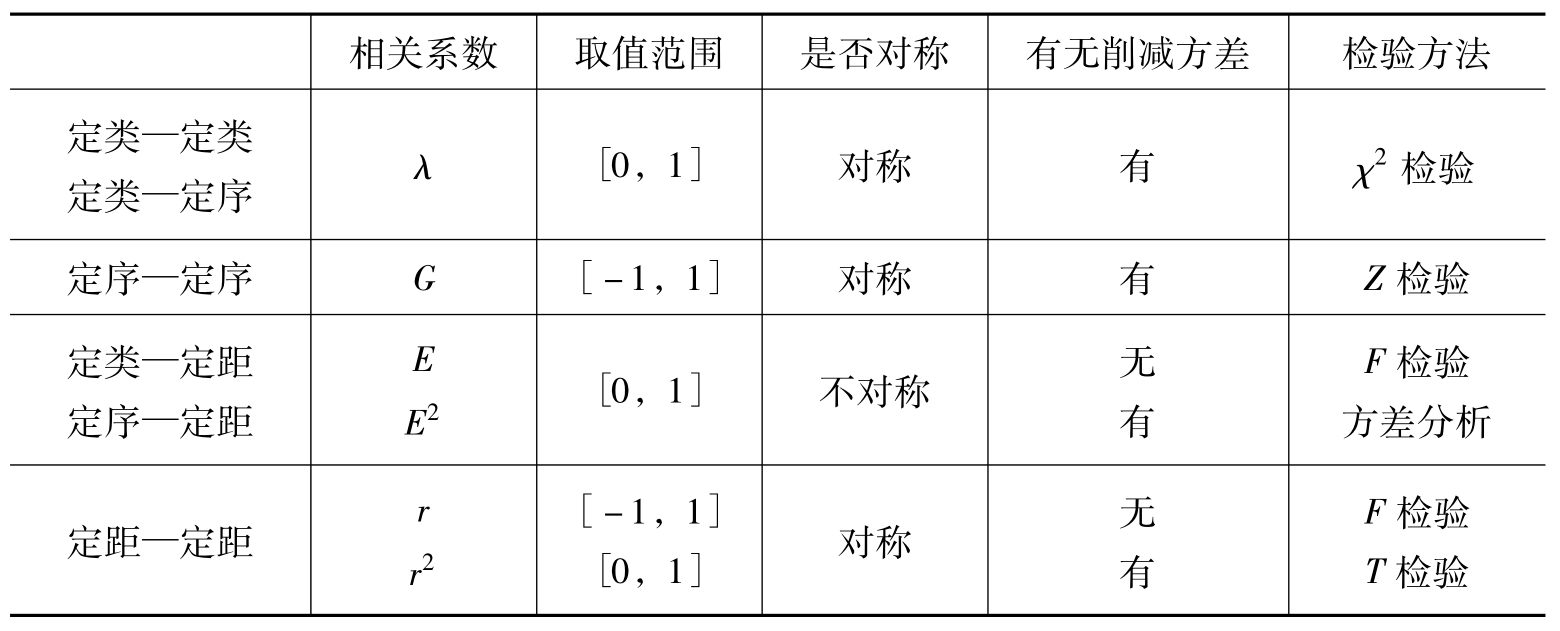
同时,必须强调如下几点。首先,各种相关测量的方法,目的是理解两个变量在“样本”中相关程度的强弱或大小。其次,对各种相关系数所进行的相应的检验,目的是根据随机样本的资料推论两个变量在“总体”中是否相关。它所关心的已不是样本中的结果,而是总体中的情形。并且,它所关心的也不是相关程度的强弱或大小,而只是“是否相关”。第三,选择何种相关测量方法和何种检验方法,主要看两变量的测量层次,要依据变量的测量层次来确定合适的相关测量和检验工具。
相关分析中,容易找到度量两变量的相互依存关系的强度指数,但如要确定两变量或多变量之间数量关系的联系形式,就需用一数学模型来表示这种形式,进行回归分析。下章将介绍线性回归模型、曲线回归模型、哑变量回归模型和通径分析。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










