



第三节 区间估计
对于总体的估计有点估计和区间估计两大类,估计的类别也分平均数估计、成数估计和方差估计等多种。下面分别论述如下。
一、总体平均数的区间估计
总体平均数的区间估计具体根据如下四种情况,分别进行处理。
1.总体正态分布、总体方差σ2已知的情况
样本取自总体方差σ2已知的正态分布,总体平均数区间估计μ:
![]()
[例6.2]某城市每户电费支出服从正态分布,2011年调查了该市400户居民家庭的户均年电费支出均值为2300元,标准差为980元。试以95%的置信度估计该市2011年居民家庭年户均电费支出区间。
解:由题意,虽然总体未知,但n=400属于大样本,可用z统计量进行区间估计,即
![]()
故我们有95%的把握保证,该市2011年居民家庭户均电量支出为2202到2398元。
2.总体非正态分布、总体方差σ2已知的情况
样本取自总体方差σ2已知的非正态分布,在不重复抽样的情况下,总体平均数区间估计μ:
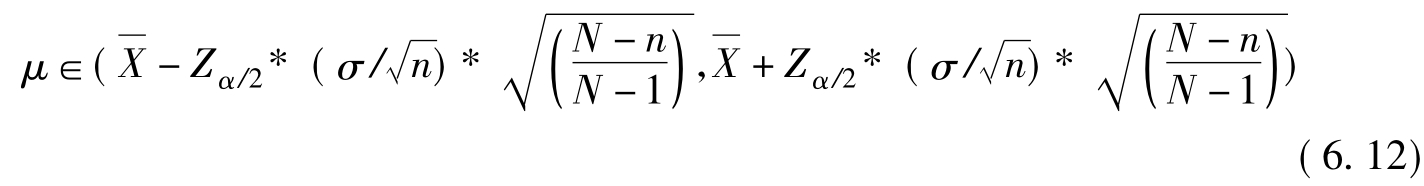
[例6.3]在例6.1中,总体是非正态分布的,总体方差σ2(=100000)已知,若每次不重复(无退回)抽2个样本,在95%的把握下,总体平均数区间μ为:
![]()
即(742.1,1457.9),这个结论和前文的分析结论是一致的。
3.总体方差未知,小样本的情况
总体方差未知,小样本的总体平均数μ的置信区间为:
![]()
其中: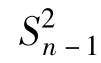 是样本的方差,tn-1,α/2是自由度为n-1时,显著性水平为α/2的t分布的表载值。
是样本的方差,tn-1,α/2是自由度为n-1时,显著性水平为α/2的t分布的表载值。
[例6.4]某校大学生四级英语考试成绩分布未知,总体方差未知,现从中任意抽取10人,成绩分别为68,46,56,64,74,58,65,48,70,61,在95%的把握下问考试成绩在60~65分之间的学生占多少?tα/2为2.262。
解:根据10个数据可以计算出平均数为61分,样本标准差Sn-1为9.141分。
![]()
61-2.262*(9.141/3)≤μ≤61+2.262*(9.141/3)
即:54.11≤μ≤67.89
若以95%的概率进行估计,则这些学生的平均成绩为54.1~67.9分。
4.总体方差未知,大样本抽样的情况
总体方差未知,大样本的总体平均数的置信区间。平均数区间估计:
![]()
若抽样比例大于5%,样本估计量则加一订正因子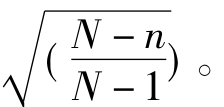
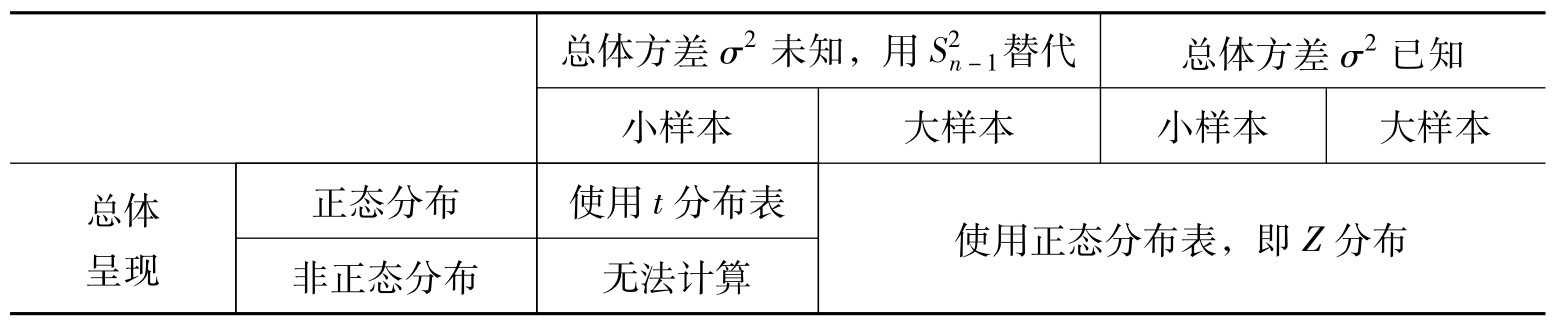
5.小结与讨论
表6.3 总体分布、总体方差、样本量与统计检验的分布表
二、区间概率度的估计
1.区间概率度估计基本原理
由于总体参数是一个确定值。显著性水平、置信水平和概率度之间存在着密切关系(如图6.2所示),如果知道了置信区间以后,也可以知道具体的概率度。比如:
当x=(-1,1)时,占总面积的(概率度)p=2*F(1)=0.6826
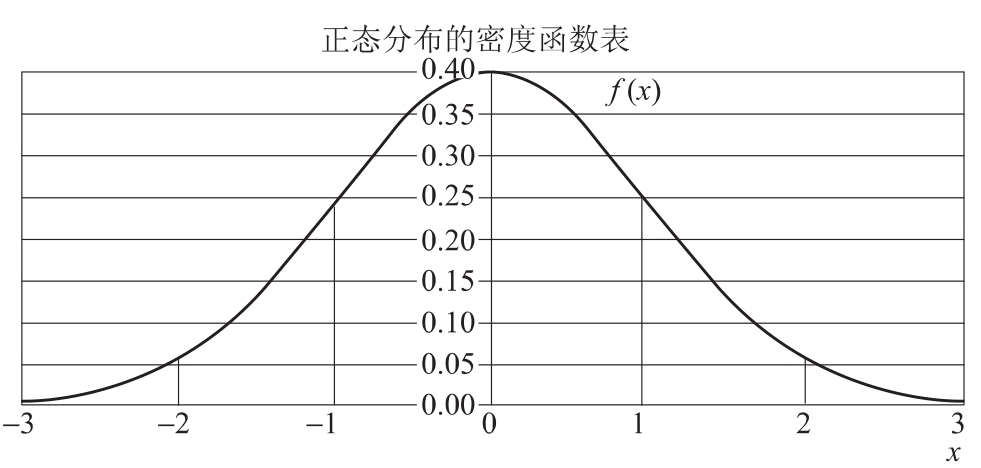
图6.2 标准正态分布密度函数表
当x=(-2,2)时,占总面积的(概率度)p=2*F(2)=0.9545
当x=(-3,3)时,占总面积的(概率度)p=2*F(3)=0.9745
进行区间估计,置信水平总是预先给定的,否则z值将无法确定,置信区间也无从建立。因为置信水平表明了区间估计的可靠性,所以z可以认为是决定区间估计可靠性的关键因素。注意横坐标,一般用x坐标,但若进行标准化以后,平均值为0、标准差为1时,将转化为z坐标。其实质都是一样的。
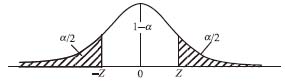
图6.3 显著性水平、置信水平和概率度之间关系图
当α=0.10时,1-α=0.90,即Z=1.65
当α=0.05时,1-α=0.95,即Z=1.96
当α=0.01时,1-α=0.99,即Z=2.58
2.大样本概率度的估计
[例6.5]男性高中生身高服从正态分布,现抽取若干样本,发现平均身高为170cm,标准差(均方差)为4cm,现准备做1000套校服,问身高166~174cm的准备裁制多少套?165~172cm的准备裁制多少套?176cm以上的准备裁制多少套?
(1)P{166<x<174}=P{(166-170)/4<(x-170)/4<(174-170)/4}
=P{-1<Z<1}=F(1)-F(-1)=2*F(1)-1
=0.6826
因为:P(-X)=P(X),实际上: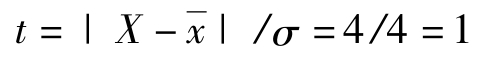
P{166<x<174}=F(1)-F(-1)=0.6826
需做1000*0.6826=683套。
(2)P{165<x<172}=P{(165-170)/4<(x-170)/4<(172-170)/4}
=P{-1.25<Z<0.5}
=F(0.5)-F(-1.25)=F(0.5)+F(1.25)
=0.1915+0.3944=0.5859
需做586套。
(3)P{x>176}=P{(x-170)/4>(176-170)/4}
=P{Z>1.5}=0.5-P{Z<1.5}
=0.5-F(1.5)=0.5-F(1.5)
=0.5-0.4332=0.0668
需做67套。
由此可见,身高166~174cm的需要裁制683套,165~172cm的裁制586套,176cm以上的需要裁制67套。
3.小样本区间概率度计算
很多总体标准差(均方差)未知的情况下,须用样本标准差(均方差)代替总体标准差(均方差)。下面举一个例子。
[例6.6]某大学生四级英语考试成绩服从正态分布,已知全校学生考试成绩为64分,现从中任意抽取10人,成绩分别为68,46,56,64,74,58,65,48,70,61,平均数为61分,样本标准差Sn-1为9.141分。问考试成绩在60~65分之间的学生占多少?
分析:X~N(μ,σ2),即(X-μ)/σ(x)~N(0,1)
![]()
解:已知: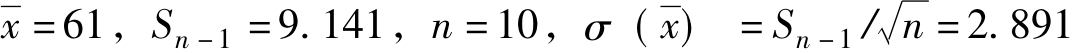
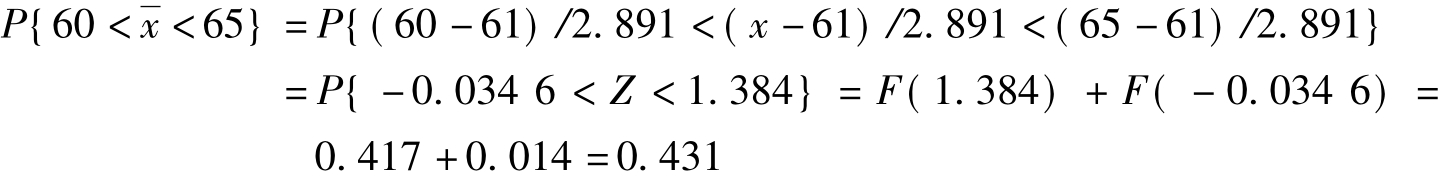
即考试成绩在60~65分的比例应该为43.1%。
三、总体比率的区间估计
1.成数抽样误差
成数的抽样误差的计算方法与均值的抽样误差的计算方法是基本相同的,只不过因为成数的方差和均值的方差不同。在抽样平均误差的公式中,将σ2换成p(1-p)就行了。
在回置(重复)抽样条件下: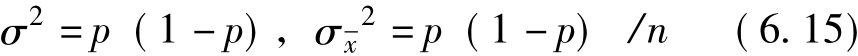
在不回置抽样条件下:
![]()
在总体成数p未知的情况下,可用样本成数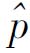 替代之。
替代之。
2.总体比率的区间估计
如果总体成数为P,样本成数为p,则总体成数的估计区间为
大样本: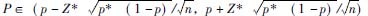
[例6.7]某社区的5000名居民中,以随机方法(一般为不回置)抽出200名居民,发现其中女性人口有80人。试求该社区女性成数之95%置信区间。
解:据题意,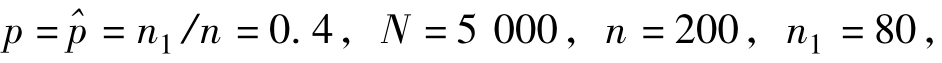 所以该社区女性人口成数之95%置信区间为:
所以该社区女性人口成数之95%置信区间为:
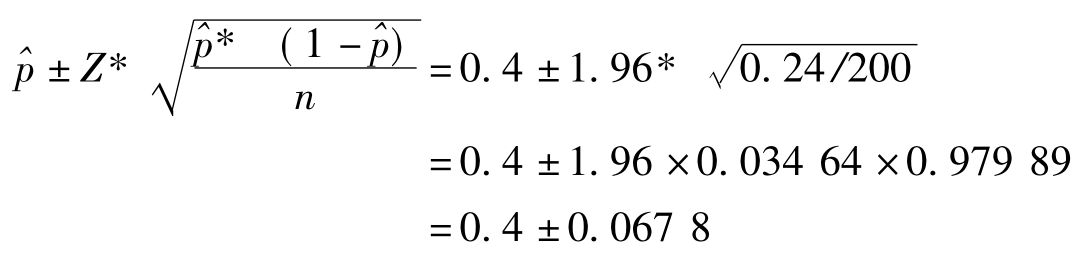
即P(0.3322<P<0.4678)=95%
可以95%的把握说,该社区女性人口占33.22%~46.78%,大约为1661~2339人。
[例6.8]估计某市居民住户拥有计算机的普及率,随机抽取900居民户,发现其中有360户居民有计算机。要求极限抽样误差范围不超过3.2%,试对该市居民住户计算机普及率进行区间估计。
第一步,抽取样本,计算样本成数、标准差,并推算抽样平均误差。
p=360/900=40%
σ2=p(1-p)=0.40×0.60=0.24σ=0.490
μ2=p(1-p)/n=0.24/900=0.0002666,μ=1.6%
第二步,根据给定的Δ=3.2%,计算总体成数估计区间的下限和上限。
估计区间下限=p-Δ=40%-3.2%=36.8%
估计区间上限=p+Δ=40%+3.2%=43.2%
第三步,根据Z=Δ/μ=3.2=2。查概率表得F(2)=95.45%。
点估计:估计该市居民计算机普及率为40%;区间估计:以概率95.45%的保证程度,估计该市居民电视机普及率在36.8%~43.2%之间。
[例6.9]某企业1500个职工,用随机重复抽样方法抽50人进行调查,其工资水平如表6.4所示:
表6.4 某企业职工工资的抽样分布

要求:计算样本平均工资和平均工资的标准差。
以95.45%的可靠性估计该工厂工人的月平均收入区间。
以95.45%的可靠性估计该工厂工人月平均收入超过2000元的比例区间。
解:样本平均工资为1810元,平均工资的标准差42.54元,月平均工资超过2000元的比例为36%。
这是属于总体方差未知,大样本的总体平均数的置信区间问题。
平均数区间估计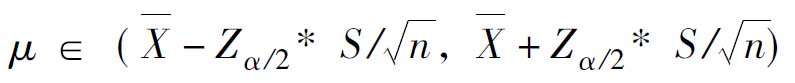
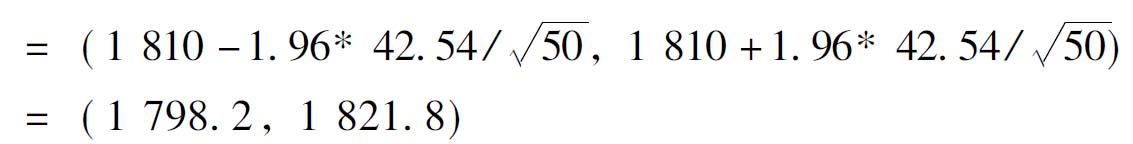
比例区间估计: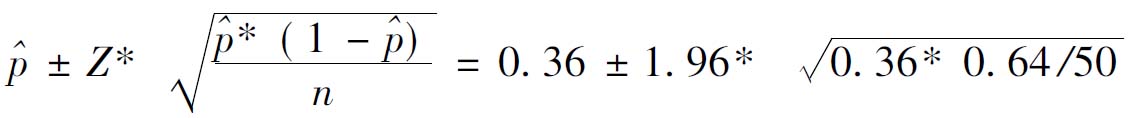
=0.36±0.13=(0.23,0.49)
即若以95.45%的可靠性估计该工厂工人的月平均收入区间为1798~1822元,该厂工人月平均收入超过2000元的比例为23%~49%,或者为345~735人。
四、双总体均值(成数)之差的区间估计
双总体区间估计可以分为双总体均值之差(μ1-μ2)的区间估计和双总体成数之差(P1-P2)的区间估计两类,均值之差区间估计又可分为大样本正态分布方差未知、大样本正态分布方差已知等多种情况,具体可参考表6.3。下面以几个例子说明具体用法。
(一)总体方差已知、两总体均值之差(μ1-μ2)的区间估计
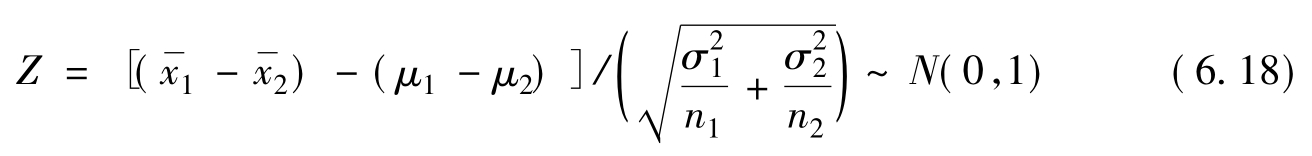
并且,可以得到两均值之差(μ1-μ2)的区间估计:
![]()
两总体均值之差值,可由两样本均值之差进行推断。为此,需要计算两样本的均值,再按区间估计方法推断它们的总体均值差异情况。当两样本均为大样本时,样本标准差可以替代总体标准差。
[例6.10]在甲乙两地抽样调查,比较两地居民受教育年限的差异情况。在甲地成年居民中随机抽取120人,算得平均受教育年限13年,标准差2.8年;在乙地随机抽取100人,算得平均受教育年限12年,标准差3.2年,现以95%的概率保证程度推断甲乙两地全部成年居民平均受教育年限差异的置信区间。
根据题中资料已知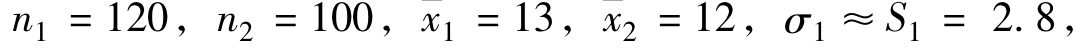 σ2≈S2=3.2,F(t)=95%,查正态分布概率表得Zα/2=1.96。得:
σ2≈S2=3.2,F(t)=95%,查正态分布概率表得Zα/2=1.96。得:
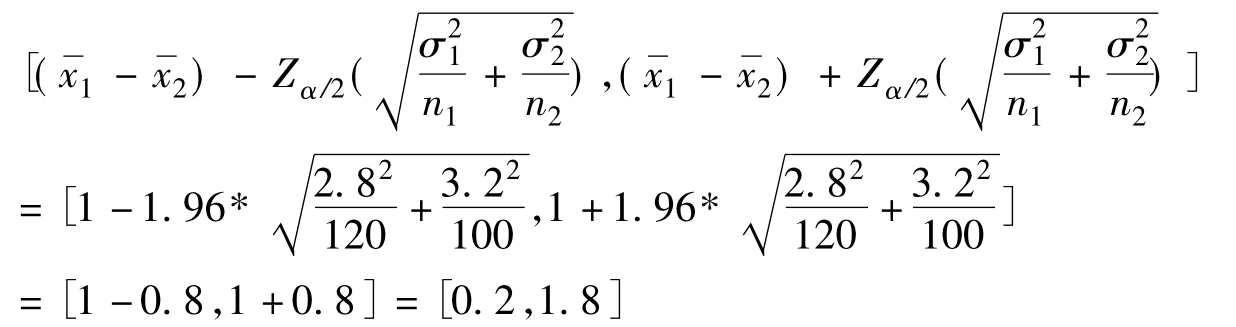
计算结果表明,甲地区全部成年居民平均受教育年限差异(μ1-μ2)可能比乙地居民高0.2年至1.8年之间,其可信程度为95%。
(二)总体方差(σ1、σ2)未知、两均值之差的区间估计
对大样本可以用样本方差S1、S2替代总体方差σ1、σ2,代入上述公式计算。
对于小样本,且两总体的标准差均不知道,两样本均值的抽样平均误差应按下列公式计算: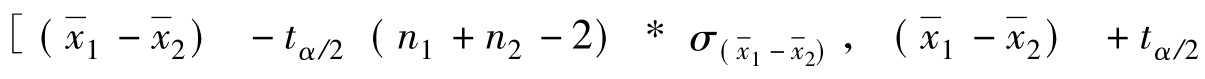
![]()
其中:对于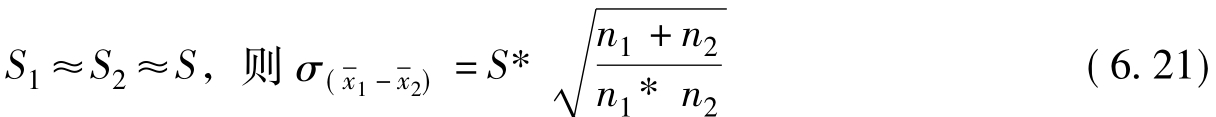
对于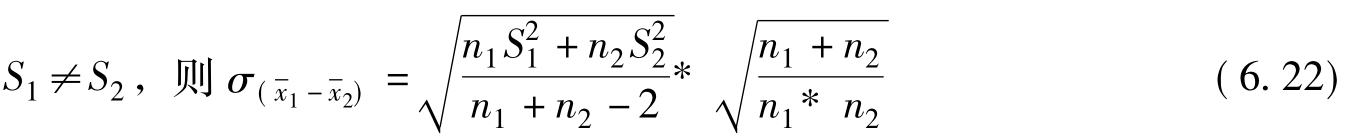
[例6.11]调查戒毒所戒毒患者的平均年龄,从甲强制戒毒所抽取18人,算得平均年龄26岁,年龄标准差4.7岁;从乙强制戒毒所抽取20人,算得平均年龄22岁,年龄标准差3.9岁。试以95%的概率估计甲乙强制戒毒所戒毒患者平均年龄的差异情况。
根据题中资料已知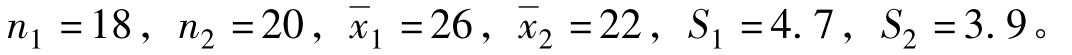
由1-α=95%,查t分布表得tα/2(n1+n2-2)=t0.025(18+20-2)=t0.025(36)=2.028。
注意:tα/2(n1+n2-2)可以通过Excel表格函数进行计算,具体为TINV(P(X<x)=1-α,自由度)=x,其中α为单尾概率。本例中,t0.025(36)= TINV(0.05,36)=2.028094。同样,有t值也可计算相应概率:TDIST(2.028094,36,1)=0.025,其中36为自由度,1为求单尾概率,若双尾则为2。
根据题中资料已知:
![]()
于是有:
![]()
即以95%的把握认为,甲强制戒毒所患者年龄比乙强制戒毒所患者年龄高1.1~6.9岁之间。
(三)两总体比例(比率)之差(P1-P2)的区间估计
根据中心极限定理的推论,根据抽样分布的有关定理,当n1p1,n2p2,n1
(1-p1),n2(1-p2)均大于5时,两个样本比例之差p1-p2近似地服从期望值为P1-P2、方差为P1(1-P1)/n1+P2(1-P2)/n2的正态分布。但由于两个总体比例均未知,故方差计算公式中的总体比例需用样本比例代替。其中q1= 1-p1,q2=1-p2,于是可构造统计量:
![]()
此时,两比例(成数)之差(P1-P2)的区间估计为:
![]()
[例6.12]某省劳动与社会保障厅对甲、乙两个地区的失业率的差异进行研究,随机从两个地区劳动力人口中分别抽取了500、600人,其中甲地区的500人中有25人失业;乙地区的600人中有60人失业。现要求对这两个地区失业率的差异进行区间估计,确定置信水平为95%。
根据题中资料已知:n1=500,n2=600,p1=25/500=0.05,p2=60/600= 0.10,F(t)=95%,查表得Zα/2=1.96。
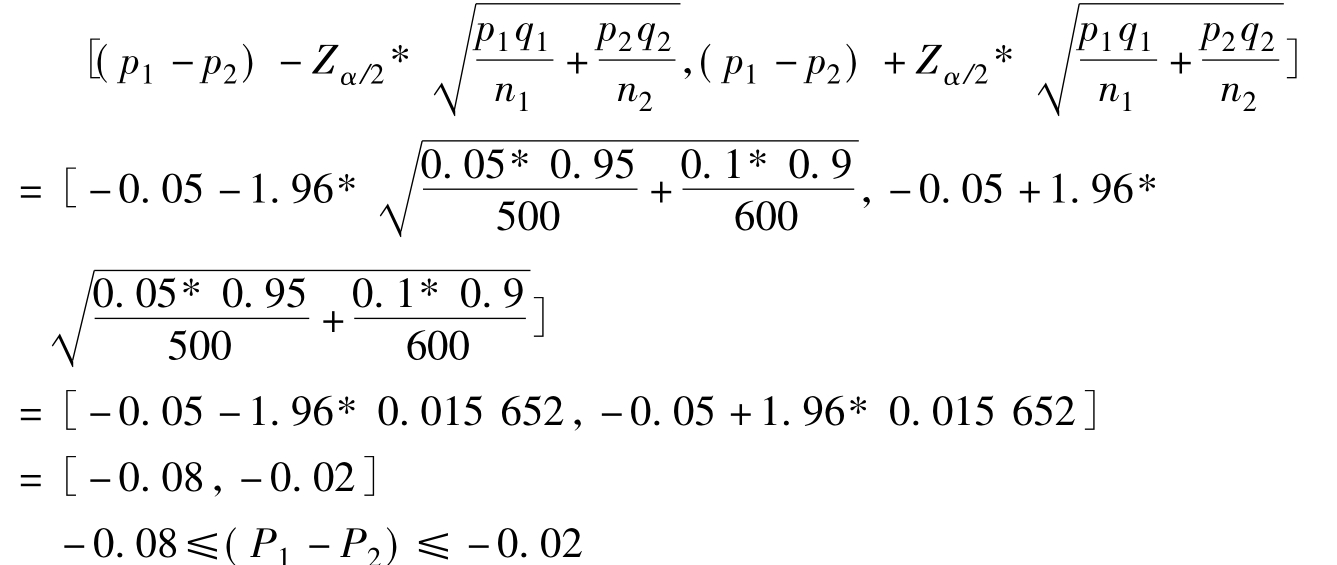
计算结果表明,甲地区失业率比乙地区失业率低2%到8%之间,概率保证程度为95%。
(四)配对样本均值差di的区间估计
配对样本x1i、x2i差di=x2i-x1i的均值区间估计,实质上是对单样本μd的区间估计。其服从如下t分布,其中:
![]()
均值分布区间为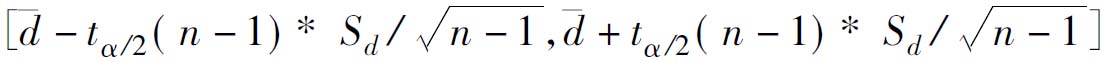
(6.26)
[例6.13]为提高学生外语水平,对学生进行强化学习,为了解强化班的效率,现从中任意抽取8个学生,调查其学习前后的成绩,现问强化训练以后,外语成绩能够提高多少(如表6.5所示)?
表6.5 8位学生强化训练后学习成绩对比表
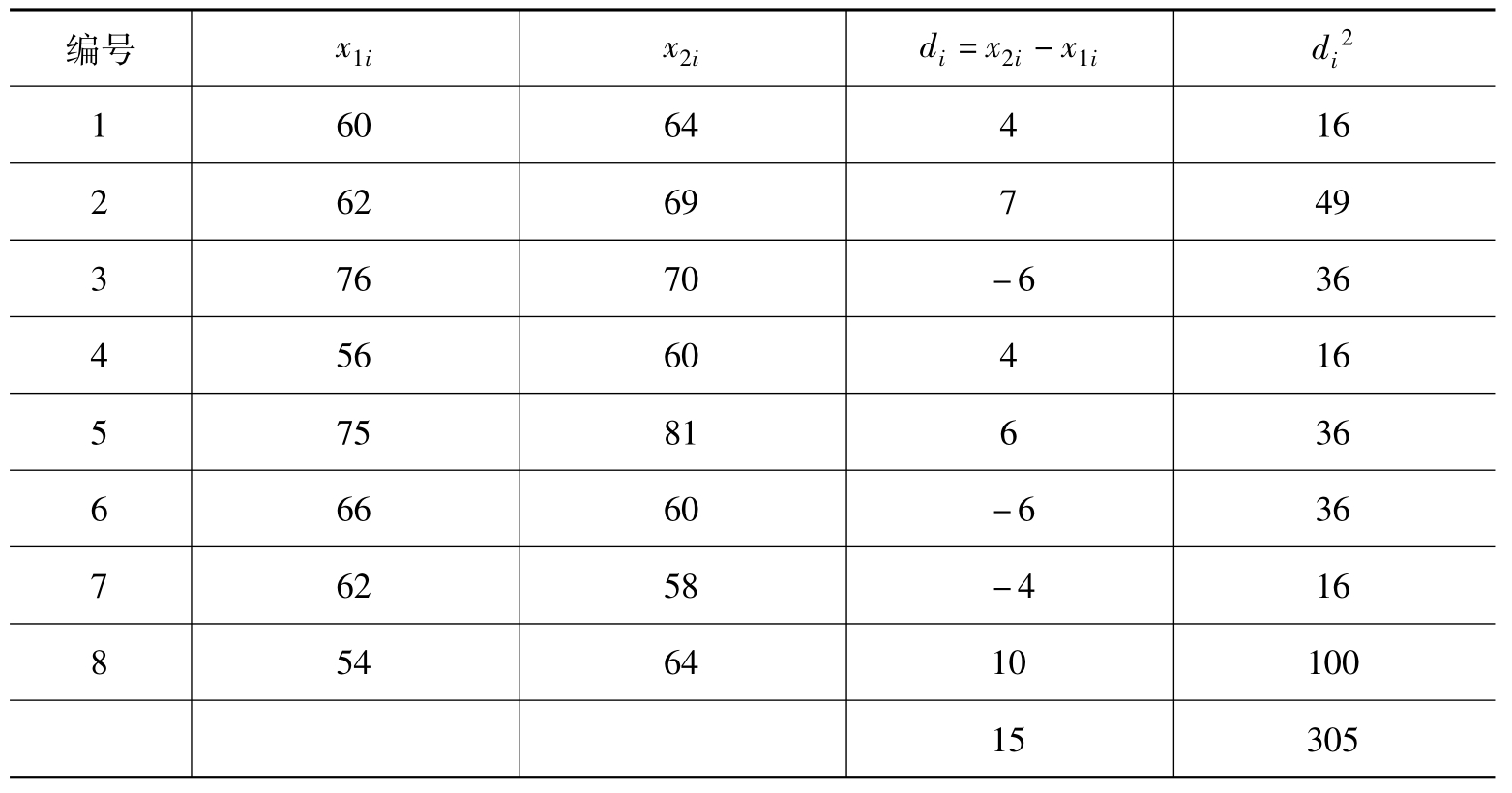
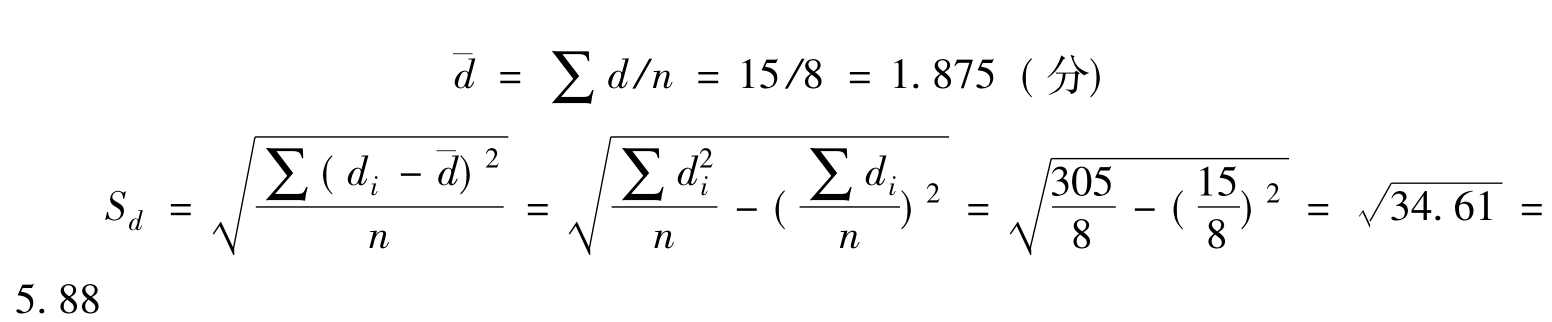
由1-α=95%,查t分布表得tα/2(n-1)=t0.025(7)=2.365,于是有:
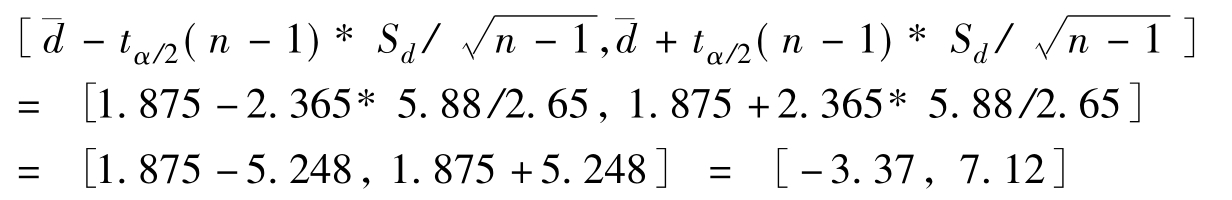
即有95%的把握说,通过强化培训以后,外语成绩提高-3.4分到7.1分。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










