



第三节 走向繁荣阶段
一、考利斯委员会(Cowles Commission)
20世纪30年代初“经济计量学会”成立以后,经济计量学研究以及宏观经济模型理论和应用的研究开始走向繁荣发展的阶段。对经济计量学和宏观经济模型的继续发展做出重要贡献的是考利斯委员会的一批经济计量学家。
考利斯委员会作为一个非营利组织由考利斯Ⅲ(Afred CowlesⅢ)资助,于1932年在美国科罗拉多(Colorado)成立。考利斯第三资助成立这一组织的本意是希望用数学方法对股票市场行为做出更好的预测,但是该组织很快在两三年内就成了一个专门的学术组织。它的早期成员包括著名的经济学家和统计学家,如费希尔(F.Fisher)、霍特林(H.Hotelling)、弗瑞希(R.Frisch)等人。考利斯委员会在1935~1940年期间每年都举行一次夏季研讨会,吸引了世界各地的经济学家和统计学家们参加。这一活动有力地促进了经济学研究中数量分析方法的推广和普及。然而,第二次世界大战的爆发严重地影响了考利斯委员会的活动,影响了经济计量学和宏观经济模型的发展进程。考利斯委员会的许多学者离开了学术研究岗位,进入了各种战时机构。在欧洲,甚至弗瑞希本人都成了德国法西斯的阶下囚。
第二次世界大战期间,美国各州政府不同程度地增加了税收,财政困境迫使考利斯委员会颠沛流离,从科罗拉多迁到耶鲁,又迁到芝加哥,一直到1943年马尔夏克(J.Marschak)出任该委员会主任才稳定下来。马尔夏克制定了委员会的研究方针和计划——继续由丁伯根以及哈维尔漠(T.Haavelmo)、曼(H.Mann)和瓦尔德(A.Wald)开始的研究工作。第二次世界大战后,一批年轻有为、朝气蓬勃的经济计量学家先后加入考利斯委员会,例如,赫维茨(L.Hurwicz)于1942年;科普曼斯(T.Koopmans),芦宾(H.Rubin)于1944年6月;克莱因(L.Klein)于1944年11月;安德森(T.Anderson)于1945年11月;阿罗(K.Arrow)于1947年先后来到芝加哥。他们当时都是二三十岁的年轻人。他们的工作推动了经济计量理论和应用的繁荣发展。考利斯委员会在40年代末、50年代初出版了一系列论文集(Cowles Commission Monograph),其中最有影响的、主要论述经济计量理论和方法的是第10辑《动态经济学中的统计推论》,[16]第14辑《经济计量方法研究》,[17]以及克莱因于1949年发表的《凯恩斯革命》(第一版),[18]1950年发表的《1921~1941年美国经济波动》。[19]这些著作是考利斯委员会的重要研究成果,它们不仅解决了经济计量学的一些基本理论问题,为经济计量学家们提供了专门有效的实用宏观模型手段,而且在丁伯根模型的基础上,以美国经济为背景,建立了美国宏观经济模型,为以后宏观经济模型的发展开辟了道路。
二、经济计量理论的发展
考利斯委员会的主要工作成果是在经济计量理论方面取得的。考利斯委员会的经济计量学家以及考利斯委员会之后的经济计量学家奠定的经济计量理论基础,为宏观经济模型的广泛应用开辟了道路。到20世纪60年代,可以说已经形成了较为完整的经典经济计量理论体系。60年代以来的经济计量学教科书已经基本形成固定的格式,就像目前所使用的微积分教科书一样。当然,就理论研究来说,经济计量理论中的问题远没有彻底解决。然而,70年代以来,对经典的经济计量学理论的研究或者仅局限于取得某些不影响大局的改进,或者已经离开了“经典”经济计量学,试图形成其独自的、对“经典”理论具有批判特点的理论体系。
“经典”经济计量理论在这一阶段取得的成果是相当丰富的。这里主要谈谈设定、估计和识别问题。
(一)模型设定理论
在模型的设定问题中,要考虑经济变量本身的性质和经济结构两个方面。如果经济变量全部是确定性的,并且经济结构是固定不变的,那么宏观经济模型将成为非常简单的事情,甚至只要知道一年的经济情况,就可以轻而易举地了解过去和推测未来。然而,经济运动的实际情况并非如此。首先,经济变量,至少大多数经济变量是非确定性的,是随机性的,而这种随机性在一定条件下是有一定的概率分布性质可循的。其次,经济结构是非固定的,是变动的,这主要是由于经济变量之间的相互影响以及所考虑的经济系统之外的因素影响的结果。这种相互影响也表现为某种随机性,但在一定条件下,它们也是有一定的概率分布性质可循的。经济计量学家把个别经济变量的随机性影响的结果称为“误差”(error),把变量间的随机性相互影响的结果称为“冲击”(shock)。最后,个别变量的随机性可能表现为变量某个时期的状态受其以前状态的影响,经济变量之间的相互影响也可能表现为非同期状态的相互影响,这就是结构问题的动态性。因此,宏观经济模型诞生之初,经济计量学家们所面对的关于模型设定的问题是随机性、相互关系和动态性问题。[20]这些问题被称为“供求分析的陷阱”、“经济时间序列独立性的匮乏”。
弗瑞希首先对宏观模型的设定问题进行了开创性的工作,提出了经济计量方程中存在随机性因素影响的概念,例如合流分析问题。[21]这些问题的研究为以后的识别问题与多重共线性问题的研究奠定了基础。但是,弗瑞希的研究没有充分考虑经济关系中的随机扰动问题,即没有分析经济变量之间相互作用的随机影响。他的研究一般是对单一方程而言的,没有考虑反映变量相互作用的联立方程组的随机性问题。同时,弗瑞希对计量方程的随机性假设没有利用概率分布形式进行分析,这种形式上的限制也妨碍了关于设定问题理论的继续发展。
在模型设定问题的研究中,取得突破性进展的是哈维尔漠。[22]他的主要贡献在于,他不仅认为可观测的经济变量本身有随机误差,而且认为模型中每一个非定义方程也有随机误差项,以反映经济关系中随机因素的影响。更主要的是他将经济变量、经济关系中的这些随机因素的影响用概率形式来表现,这就使随机影响的不确定性取代了确定性,使它们成为易于研究和可掌握的了。在此基础上,哈维尔漠将宏观经济模型的联立方程组作为一种统计假设来设定。这一思想建立了宏观模型设定理论的基础。后来的各种设定理论的发展,无一例外地接受了这种概率统计假设的思想,因此,人们称哈维尔漠的工作是一场“革命”,是经济计量学理论发展的“里程碑”。
本小节提到的弗瑞希和哈维尔漠等人的经济计量设定思想是设定理论的基础。各种具体的设定问题或模型选择问题,将在下面有关的章节中进行讨论。
(二)估计理论
宏观经济模型中的估计方法主要有两类:极大似然法和最小二乘法。虽然从理论上可以证明最小二乘法实际上是极大似然法的一个特例,[23]但是对这两类估计理论的完善和发展却是基本上独立完成的。极大似然法具有广泛的适用性,例如它可以解决非线性模型的估计问题,但它要求比最小二乘法更严格的假设条件,其主要缺点在于计算的复杂性和要求较长的数据样本。最小二乘法的最大优点在于计算的简单性,但它基本上不能在一般条件下解决线性模型之外的估计问题。由于它要求的假设条件比极大似然法弱,因而它的估计量的性质就不如极大似然法估计量那样完善。
在数理统计学中,由于高斯—马尔科夫定理的提出,最小二乘原理在其他学科的参数估计问题中早已发挥了重要作用,但是在经济计量学中,在模型设定问题尚未解决之前,以及人们对模型的概率假设检验概念尚未全部接受之前,直接使用最小二乘法原理估计参数还存在着障碍。因此,在经济计量理论发展的初期,人们把估计理论研究的重点放在对极大似然法的研究上。最早完整地提出似然性估计理论的是曼和瓦尔德在1943年做的工作。[24]他们的研究限定在线性和大样本条件下,并且不考虑观测误差问题。在似然法应用中考虑全部变量和变量之间的随机因素影响的工作是由安德森和赫维茨在1948年完成的。[25]契诺夫(H. Chernoff)和德文斯基(N.Divisky)在1953年解决了一般条件下的似然法估计计算问题。[26]
有趣的是,极大似然法研究的发展走的是一条由全体到局部的道路。首先提出来的是充分信息极大似然法(FIML)——利用全部样本数据一次解决模型联立方程组所有参数的估计问题,然后提出来的是有限信息极大似然法(LIML)——利用部分有关变量的样本数据分别估计方程组中单个方程的参数。后一种方法是安德森和芦宾在1949年提出的。[27]克莱因最后给出了这种估计方法的最简单最实用的估计计算方法。[28]之所以出现这种从全体到局部的发展过程,是因为在数理统计理论中,极大似然法是作为一种系统估计方法出现的,因此在经济计量学的估计理论中首先也将其作为系统方法而使用。另外,在早期,一个模型系统也往往只有一个方程。随着模型系统的大型化,亟须计算上的简化,迫使经济计量学家独立研究出了专门用于经济计量模型的不同于系统估计的有限信息估计技术。
最小二乘估计方法只有在解决了模型的设定理论后,才得以发展。由于其简单性和实用性,它的发展是相当迅速的。进入20世纪50年代以后,对最小二乘法的理论研究和应用技术开发都大大超过了极大似然法。合流分析所提出来的一些问题,陆续由经济计量理论的一些专门研究成果得到了部分解决,如对多重共线性、序列相关、异方差性等问题都提出了较系统的判识和解决方法。
最小二乘法作为经济计量学估计理论的主要内容,它的发展走的是一条由简单到复杂的道路。高斯—马尔科夫定理解决的是仅有一个方程的模型的估计问题,之后提出的二阶段和三阶段最小二乘估计方法是建立在将最小二乘原理一般化基础上的。最小二乘原理的一般化是由贝斯曼(R.Basmann)总结完成的,[29]其主要思想是通过矩阵形式把联立方程组一般化为单一方程,并研究在这种形式下的估计量的表达式和性质,特别是它的大样本渐近性质。这一工作为二阶段和三阶段最小二乘法的提出打下了基础。
二阶段最小二乘法(2SLS)的基本思想最早是由赛尔(H.Theil)在1953年提出的。[30]当最小二乘原理一般化研究完成后,由戈尔登博格(A.Goldberger)在1964年总结出完整的表述。[31]2SLS利用模型全部前定变量信息,两次使用最小二乘法得到单一方程所具有较好渐近性质的估计值。
三阶段最小二乘法(3SLS)是由采尔纳(A.Zellner)和赛尔在1962年提出的。[32]从2SLS到3SLS的发展,实际上是通过代数方法而不是统计方法实现的(当然,这样的代数扩展形式具有统计解释),是一个从具体到一般的过渡。3SLS利用模型全部变量的样本数据信息,一次估计得到模型所有方程的全部参数估计值。这种方法的估计量比2SLS估计量具有更加渐进有效的性质。但是由于其对计算机容量的要求较高,一些较大的模型也遇到实际计算的困难。
从20世纪60年代末到70年代初,最小二乘法的理论和应用研究已经推广到非线性模型。例如乔根森(D.Jorgenson)等人在1974年已经研究了用三阶段最小二乘法概念估计非线性模型的参数问题。[33]
(三)识别理论
宏观经济模型中的识别问题,在20世纪初期的初步发展阶段就已经被提出来了。人们针对每一个具体模型的具体识别问题曾做过许多研究,试图加以解决。弗瑞希和哈维尔漠等人也曾试图把识别问题抽象成一个理论问题加以研究,并取得了一定的成果。然而,真正把识别问题系统化、理论化,并形成一套行之有效的识别方法的工作是在第二次世界大战后的走向繁荣阶段完成的。其代表成果是科普曼斯、芦宾和雷普尼克(R.Leipnik)的文章,[34]瓦尔德的文章,[35]以及赫维茨的文章。[36]在这些文章中,他们建立了一整套实用的关于线性随机方程组的识别条件,这些条件主要取决于先验信息的种类与数量。他们还从概念上、逻辑上及数学形式上阐明了识别问题的本质及一般解决方法。他们提出了用于判别模型是否可识别的阶条件和秩条件,并确定了模型的三种识别类型——唯一识别、过度识别和不完全识别。这些概念和内容是迄今为止经济计量学教科书中关于识别理论的基本内容,也是识别理论进一步发展,解决更加复杂的模型识别问题的基础。
费希尔在60年代提出了关于递推结构模型中模块的识别概念,这对于大型模型的建立很有益处。[37] 60年代以来,非线性模型中的识别问题得到了研究。[38] 维吉(Wegge)将识别问题推广到了任意非线性系统,[39] 但这一研究已变得极其深奥晦涩,难以引起多数人的兴趣。一段时期中,识别问题不再是很紧要的问题,直至70年代合理预期模型大量出现以后,识别问题才又引起人们的注意。
三、考利斯委员会之外的经济计量模型的理论和应用研究的发展
(一)概述
在宏观经济模型走向繁荣的阶段中,考利斯委员会是一支重要的力量,在某种意义上可以说是主流派。他们或者是对经济计量学基础理论具有浓厚的兴趣,如3.2节中所提到的,或者是致力于宏观总量的经济模型的探讨和研制,这以克莱因为主要代表,将在3.4节中讨论。然而,在考利斯委员会之外还存在着其他不容忽视的力量,他们以其独特的研究方式也为宏观经济模型理论和应用的发展做出了重要的贡献。
以考利斯委员会为代表的主流派,以及以克莱因为代表的总量宏观模型派之外的其他学派主要有:英国学派,以剑桥大学应用经济系为核心,代表人物有希克斯(Hicks)、斯通(Stone)等人;荷兰学派,代表人物有丁伯根、赛尔等人;美国的货币学派,代表人物有弗里德曼(Friedman)等人。这些不同学派与主流派相比有其鲜明的特点:第一,他们不是主要研究纯经济计量理论,而是针对某一具体的经济问题进行研究,例如英国学派对需求问题的研究,荷兰学派对政策问题的研究,因而对经济理论的依赖性表现得十分强烈,往往都是先对所研究的问题进行充分的数理分析。第二,他们的研究方法不完全是纯理论演绎性的,而是以大量实际数据为基础的归纳方法。研究者往往需要将大量时间用于收集、整理、转换数据的工作,因而他们的研究从选题到研究,直至最后形成结果,都紧密地与实际经济问题相联系。第三,他们的应用研究都离不开经济计量学的基本理论,特别是表现在获取重要的经济参数估值方面。他们在实际应用问题过程中,不仅被动地使用了经济计量方法,同时也主动地促进了经济计量学理论和方法的发展。
这些不同学派与以克莱因为代表的总量宏观模型派相比,有如下不同特点:第一,他们的模型不像克莱因的模型那样采用总量和高度宏观,以致在总量水平上几乎包括了社会经济运动的所有方面,而是针对某一具体问题(如需求),并试图将研究对象进行分解(如对不同消费品的需求)。第二,由于他们的研究对象的范围相对较小,因而他们对模型方程的设定就细致得多,对于方程形式的推导也严格得多,更明显地依赖于数理经济学的研究成果,甚至行为方程的函数形式都具有确定的经济意义。相比之下,由于克莱因的总量宏观模型要兼顾各个方面,在方程设定方面与他们相比就显得略微粗糙了。第三,他们研究模型的目的比较单一,例如,英国学派在斯通之后对需求的研究,主要是为了研究第二次世界大战后英国由于物资匮乏而实行配给制度的问题;丁伯根等人研究政策变动问题,主要是因为战后他身为荷兰政府中央计划局局长的工作需要。他们的这种具有相对专一性的研究,不仅更具应用色彩,同时也为奠定特定经济问题研究的理论基础作出了贡献。第四,更重要的是,他们研究的理论基础不同程度地有别于克莱因的凯恩斯主义宏观模型,最突出的代表是弗里德曼的货币主义模型。这种模型所依赖的经济理论基础的不同,可以说是克莱因模型与弗里德曼模型的根本区别,这恐怕也是弗里德曼作为宏观经济模型的长期批评者之一的主要原因。弗里德曼早期虽然经常参加考利斯委员会的讨论会,却始终没有完全赞同考利斯委员会的主流派观点。然而,他的工作确实也为经济计量学理论和应用的研究作出了贡献。
我们介绍其他学派与主流派的不同,并不是要抹杀他们之间的一致性。例如,英国学派与主流派都以凯恩斯经济理论为基础;荷兰学派与主流派在模型方法上则承先启后;货币学派与主流派在经济计量方法上具有相似性。正是由于第二次世界大战后经济学、经济计量学各派的百家争鸣,互相渗透,才造成了宏观经济模型的理论研究和实际应用蓬勃发展的局面。
下面分别讨论三项取得较重要成果的研究,它们是:需求分析研究(斯通),消费函数理论研究(弗里德曼),经济预测和政策分析研究(丁伯根和赛尔)。
(二)需求分析研究
在需求分析研究方面作出突出贡献的是英国著名经济学家斯通,其代表作是1954年出版的《1920~1938年英国消费者支出和行为的度量》。[40]在这本书中,作者通过对几十种消费品的居民消费支出情况的综合分析,得出了对若干种主要消费品的市场需求关系的重要结论。斯通分析的是半个多世纪以前英国的情况,他的具体结论对我们来说可能已不是十分重要了,但是斯通的这一工作的意义在于他提出了一套完整而科学的经济学的数量分析研究方法。斯通在这部著作中,不仅针对具体问题进行了深入研究,得出了重要结论,而且他还论述了数量分析在经济学研究中的意义和基本原则。这也许是我们从其著作中的主要受益之处。
关于经济问题研究中的数量分析方法,斯通指出,消费和需求的情况主要反映在消费的数量、消费品市场价格和消费价值量的数字上。然而通过调查取得这些数字,为研究提供有用的信息,并不是唯一的目的。另一个主要目的是说明经济现象在多大程度上能够与经济理论联系起来,或由经济理论加以解释。作为科学的经济学的发展依赖于事实(数字)与理论的结合,是归纳和演绎的结合。正如列昂节夫所指出的,必须改变有太多的理论而没有或仅有极少事实支持的,或有太多的事实而没有与理论相联系的状况。因此,数量分析方法的主要目的是分析理论与事实之间的关系,其条件是成熟的理论和可供使用的观测数据。在数据信息比较丰富的时代,经济学家应该学习怎样利用这些数据,而不是仅依据很少的事实,创造宏大的理论。
斯通深入分析了在经济方程中引入随机误差项的原因。他指出,通过检验总会发现理论的不完全性,在理论研究中,某些经济关系的变化总是被假设为不变的(例如消费者的偏好和习惯)。为了弥补这种理论的不完全性,除了表示确定关系的恒等式之外,在经济行为方程中需要加入随机误差项。斯通从经济理论的相对不完全性的考虑出发所提出的在经济计量模型中加入误差项的观点是十分重要的,但却往往被人们所忽视。因此,在模型中加入误差项并不是一种简单的数学技术形式,而是表示经济变量之间的关系由于受其他变量的影响,在不同时期发生了变化。误差项的设定的根本原因在于经济,而不在于统计。斯通还指出,由于经济变量之间的相互关系的表现形式可能是多种多样的,理论对于模型的作用就在于极大地减少这种可能性的数目,使模型的方程的可能形式减少到最小限度,再用统计推论手段加以确定。
在需求分析中,斯通把研究分为两方面:短期和长期。短期研究主要是根据已知的情况,通过数量分析得出结论,供管理人员决策时参考。长期研究是对短期研究范围的扩大。短期研究很难提出解决问题的办法,而长期研究则是要发现以前未能得到的信息,并将这些信息与可观测的现象或现象之间的关系联系起来,为制定政策服务,提出解决问题的办法。因此,长期研究的主要内容是市场需求分析。
斯通在消费者对各种商品的支出分析中,始终贯穿了同一叙述方法,即一般分析—估计方法—估计的可靠性分析—结论,并提出了数据的内插和外推方法。这是数量分析的一般思路。他在需求分析中用专门章节论述了经济计量学的基本要素,说明了经济计量方法的一般过程——显著性检验、识别问题、参数估计、预测——在需求分析中的重要作用,并提出了建立季度、月度模型的可能性,以及联立估计的重要性。这些研究对经济计量学本身也是一个重要的贡献。
在对英国的消费者支出和市场需求进行深入研究的基础上,斯通首次从理论上提出了线性支出系统的研究方法。[41]这是一个具有基础理论性质的关于需求方程的实用系统,对后来的需求研究的发展起着重要作用。其基本表述式为:
![]()
除斯通之外,沃尔德(H.Wold)用经济计量方法对瑞典的消费需求所做的研究也堪称另一个范例,[42]这里不再赘述。
(三)消费函数理论研究
按照凯恩斯的理论,总量消费函数主要由总量消费、总量收入和总量储蓄构成。凯恩斯本人就认为,[43]即期消费支出是依赖于即期收入的稳定的函数,当收入增加某一个量时,消费并不是绝对增加相同的量,而是新增收入的相当部分被用于储蓄。人们按照凯恩斯的这一理论,利用实际数据,做了许多经验估算工作。不论使用有关经济变量的总量时间序列数据,还是使用抽样调查的家庭或个人的预算数据,得到的估计结果基本上支持了凯恩斯的理论,即消费与收入相关,边际消费倾向小于1,且边际消费倾向小于收入的平均消费倾向,因而用于储蓄的收入的比例随收入的增加而增加。
但是,有人发现,例如库兹涅茨(S.Kyznets)对美国1899年以来的储蓄情况进行估算后发现,收入增加时,储蓄在全部收入中所占份额不断增大,然而多年度的长期资料则表明,即使总收入逐年增加,总储蓄在总收入中占的份额也是相当稳定的。这一结果说明,仅将消费或储蓄与即期收入相联系是不够的。为了解释实际数据估算中出现的这些现象,人们提出了一些假说,试图说明消费者行为规律。其中最主要的是由布拉弟(D.Brady)、杜森布利(R.Duesenberry)等人提出的“相对收入假设”理论。这种假设认为,在任何规定时间,消费对即期收入的反应并不特别敏感,人们怎样消费是和他们的相对收入的地位相称的。当收入在几年中增加或减少时,如果他们的相对地位发生了变化,他们的消费模式也会改变。之后,托宾(Tobin)等人又证明,其他因素也能引起相对收入假设所解释的那些效果。此外,许多学者对消费函数理论研究的发展也做出了各自的贡献,这些工作对消费函数理论的发展都有着重要作用。
然而,上述这些工作,单独看来都不够全面,都不能作为消费理论的一般表述。完成消费函数理论一般化工作的是美国经济学家弗里德曼。他于1957年提出了“长期收入假设”理论,比较圆满地解决了消费函数的理论问题,使以往的一些有科学性的假说与一般经济理论统一起来,并能较好地用于解释实际数据估算中所发生的在总收入中储蓄份额相对稳定的现象。[44]他指出,在研究所度量到的收入和消费时,首先要对收入和消费有个确切的概念。他首先区分了两种不同的收入——长期收入和临时收入,并由此引出了长期消费和长期储蓄的概念。长期收入是消费单位预期将在长期内得到的收入,并据以调整其长期消费。长期消费是长期收入的一部分,它不决定于长期收入水平,而决定于那些影响消费单位是进行消费还是积累资产的因素,例如利息率。临时收入是消费单位意外得到的收入。当临时收入与长期收入有差异时,消费单位就将两种收入之间的差额储蓄起来,或动用储蓄。这样,计划的储蓄或长期储蓄就与所度量到的储蓄有了差异,而临时消费的增减也使长期消费不同于所度量到的消费了。由此弗里德曼得出结论:年度资料反映的是已被歪曲了的消费者行为,因而,在分析消费者行为时,影响长期消费对长期收入比率的因素要比收入水平重要得多。
弗里德曼对于消费函数的研究,不是一种纯理论的演绎研究,其长期收入假设的提出,是以利用大量实际数据进行估算的结果为基础的。更重要的是,他将长期收入假设概括为一个简洁的经济模型,当对这个模型进行了具体的设定之后,就能够用经济计量方法对消费函数进行充分的研究。这个模型包括三个主要方程:

第一个方程说明,计划或长期消费(Cp)是计划的或长期收入(yp)的一部分(K),而比例系数K并不依赖于长期收入的多少,而是依赖于其他一些变量,特别是利率(i)、人们积累的财富与收入的比率(w),以及其他影响消费单位当前消费与积累财产的嗜好的因素(u)。第二、第三个方程说明,被度量的收入(y)和消费(C)分别是由长期收入(yp)和长期消费(Cp),以及临时收入(yt)和临时消费(Ct)构成的。临时性收入和消费包括消费单位的随机变化因素的影响,以及度量的误差。这个简单的模型仅是一个理论框架,把它变为一个具体的经济计量模型还需要做详细的模型设定工作,例如第二、第三个方程中长期收入和消费与临时收入和消费的设定式,以及数据整理。这样的工作也许是很艰巨的。但弗里德曼的工作毕竟为用经济计量方法深入研究消费函数理论奠定了基础。
弗里德曼是1976年诺贝尔经济学奖金的获得者,他得到这一荣誉的原因之一就是“他根据一个假设,在估计总消费支出时,‘长期收入’而非各年度收入是决定性因素,改造了消费理论,这有头等重要的意义”。[45]
(四)经济预测和政策分析研究
宏观经济模型从出现之日起,其主要目的之一就是进行经济预测,并为经济政策的决策服务。宏观经济模型为经济预测提供了一种科学有效的手段,当今任何能推动经济发展的经济政策的制定都离不开经济模型所提供的信息。此外,一个经济模型预测效果的优劣已经成为检验模型水平的重要标准。宏观经济模型方法的创始人之一丁伯根,在其著作中十分强调模型对于政策分析的作用,并有专著论述这方面的问题。[46]可以说,丁伯根同时也是将模型方法与政策分析、政策决策联系起来的创始人。以丁伯根为代表的早期的关于模型对政策决策作用的研究尚存在某些不足,主要表现在两方面:第一,对模型与实际之间的偏差考虑得不够,因而对决策可能出现的错误没有有效的分析方法。第二,对怎样通过模型得到最优决策没有提出方法,早期这方面的模型都要求可调控的决策变量数要大于或等于模型中内生变量数,当出现相反情况时,就显得无能为力了。
宏观模型用于政策分析、政策决策的理论是与模型的预测理论密切联系着的,只有解决了预测理论问题以及预测与政策决策的关系问题,模型对于政策决策的作用才能有坚实的基础。这方面的研究也是宏观经济模型在走向繁荣阶段中在应用领域取得重要成果的一个方面。其代表作是赛尔在1958年发表的《经济预测和政策》一书。[47]为了纪念丁伯根在这方面的奠基性工作,赛尔在此书的扉页写道:“献给J.丁伯根,预测家和政策制定家。”
赛尔在他的著作中将预测科学地划分为条件预测和非条件预测、点预测和区间预测、单项预测和多元预测等概念。他的预测理论主要是三个方面的分析,即:可验证性分析及准确性分析;预测的产生过程分析;预测在政策制定中的应用分析。其重点是可验证性分析及准确性分析。所谓可验证性是指无论预测结果对或错,都必须说明得出预测结论的方法,正如物理和化学试验一样,是他人可以重复并得到相同结果的。因此,所使用的经济变量的定义必须清楚,预测时间必须清楚,同时在多元预测中必须保持所有被预测变量的“内部一致性”。预测所依据的是有关的经济理论和变量数据,由于理论的概率性质和数据生成的概率性质,宏观经济模型的预测结果必然具有概率意义。例如,从概率术语出发,可以引出诸如中值预测、无偏预测等概念。预测的概率性质是一个很重要的概念,赛尔在此基础上给出了不同条件下的预测误差计算公式。他指出,由于预测存在误差,据此做出的决策措施就可能不是最优的。因此在进行决策之前,必须对预测,特别是对预测误差做事前分析。此外如果能找出“系统性”预测误差,则将有助于避免决策中的“系统性”失败。
关于决策以及决策与预测的关系的理论,赛尔指出,决策实际上是不确定条件下的决策,由于这种不确定性的存在,才需要预测,特别是在动态决策过程中更需要预测。决策的目的是使政策制定符合经济运动的客观规律,使决策和预测二者一致起来。因此,预测是政策制定的基础,合理的政策制定(或决策)是使政策制定者通过采取适当的手段使社会经济运动达到较好或最优状态。预测对决策行为的影响主要表现在:①预测社会经济环境会发生什么变化。②预测决策者的行为会发生什么影响。③分析决策者应采取什么措施。赛尔还指出,预测和决策之间有如此密切关系的基础是:第一,对政策制定者来说,一些变量是可控的,而另一些是不可控的。第二,可控变量与不可控变量之间的相互关系可以在一定程度上被认识。第三,政策制定者所欲达到的目标是确定的。当他们的最优标准确定后,怎样达到这个最优标准,即使可控变量达到怎样的值,以实现这个最优,也是问题的一个重要方面。丁伯根等人的早期工作解决了可控变量个数大于或等于不可控变量个数的问题,然而在实际当中这种情况是比较罕见的。赛尔进一步发展了这方面的研究,提出了解决这一问题的一般化方法——二次函数的极大化过程方法。他提出了必要的概念,并建立了较完整的数学处理体系。在此基础上,克莱因又对其进一步完善、简化,并对许多实际问题进行了研究,使宏观经济模型的预测与政策制定更有效地结合起来。[48]
四、宏观经济模型的发展
(一)概述
克莱因在考利斯委员会内独树一帜,从考利斯委员会后期以来,特别是在20世纪50年代末至60年代,以克莱因为代表的宏观经济模型学派迅速蓬勃发展起来。在丁伯根开创性工作的基础上,以美国为主,西方一些主要资本主义国家(包括日本)都相继建立起各国的宏观经济计量模型。这个时期宏观经济模型的发展不仅迅速,而且扎实、稳健,实际上,是一个宏观模型理论和方法在主要工业化国家的普及过程。
上述资本主义国家的宏观经济计量模型,注意了在宏观总量水平上把握和反映一国经济运动的较全面的动态特点,基本上是以凯恩斯的宏观经济理论为理论基础,并使用了时间序列数据。1966年,纳拉夫(Nerlove)把从50年代初到60年代中期的西方八国及印度的较有影响的25个宏观经济计量模型用列表法进行了总结对比,[49]其中包括10个美国模型,2个英国模型,3个日本模型,以及澳大利亚、德国、意大利、印度各一个模型。关于这些模型的特点,纳拉夫都作了简要的评介。当然,这25个模型的选取带有纳拉夫的认识,但它们基本上反映了那一时期宏观经济计量模型的发展状况。
由于美国的经济数据统计的系列化、规范化程度相对较高,丁伯根在1939年建立了第一个美国商业周期模型,这也是最早的一个比较完整的宏观经济模型。之后,宏观经济模型的研制似乎沉寂了一个年代。直至1950年,克莱因建立了1921~1941年美国模型(Interwar Model),并接着于1955年与其他人合作建立了克莱因—戈尔登博格(Koein-Goldberger)模型,奏起了宏观经济模型大规模兴起的序曲。这几个模型作为现代宏观经济模型的样板,对以后的许多宏观经济模型产生了重要的影响。
研究宏观经济模型不能不着重研究关于美国的宏观经济模型,因为美国学者所研制的宏观经济模型的确在宏观经济模型史上占有重要的位置。下面分析走向繁荣阶段美国宏观经济模型的发展情况。
(二)几个主要的美国宏观经济模型
1.克莱因的1921~1941年美国经济模型。
这个模型是为了分析两次世界大战之间1921~1941年的美国经济,并为了推广普及当时还不为人们所熟悉的经济计量模型知识而建立的。克莱因在论述该模型的著作中,[50]首先提纲挈领地介绍了经济计量方法的基本概念和内容,以及模型方法与经济理论的关系,然后从简到繁建立了三个模型。第一个模型仅有6个方程;第二个模型是第一个模型的简化型,用于分析有关的经济结构参数和弹性;第三个模型是由第一个模型引出的、由16个方程组成的实际应用模型。6个方程的模型为:
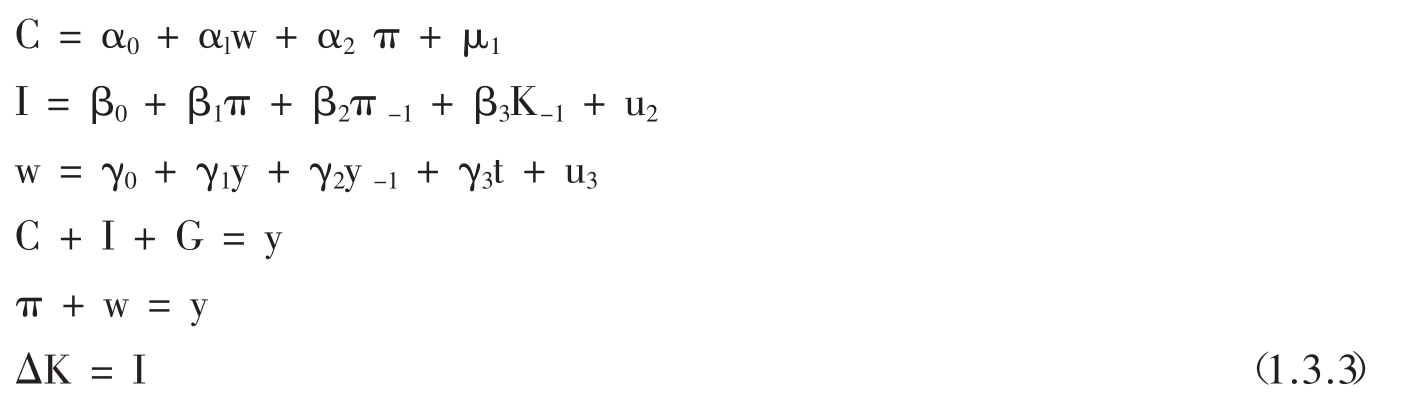
仅此6个方程已包括了消费(C),收入(y),投资(I),工资(w),固定资产(K),政府支出(G),利润(π)这些总量的宏观经济变量内容。该模型的外生变量,除时间t外,都是政府政策变量,因而适用于政策分析。模型参数用OLS法估计。这个模型可以说是凯恩斯主义的宏观经济模型的典范,它经常被后来的宏观经济模型理论书籍作为样板提及。当然,这个模型过于“总量”了,并且没有考虑国民经济中的其他因素,如生产、金融的影响。
2.克莱因—戈尔登博格模型。
这是一个中等规模的模型,样本为不包括1942~1945年的从1929年到1952年的20组观测值。模型由20个方程组成,其中15个随机方程,5个定义式,共有34个变量,14个是外生变量。这个模型比上一个模型包括了更多的内容:首次引入了进口需求方程,并把农业生产函数作为独立的方程处理。同时还包括了价格、利率、流动偏好等金融内容。在技术方面,首次使用了先验方程(prior equation),为在数据缺乏或不稳定条件下解决行为方程的参数值问题提出了一种新的方法。模型使用了长达5年的滞后变量,并出现了一些非线性方程,使用LIML法估计参数。克莱因和戈尔登博格关于此模型的著作[51]按照模型设定讨论、模型系统性质、模型统计估计值和检验、外推及预测和预测检验的顺序一气呵成,亦成为后来有关的宏观经济模型专著的表率。
这个模型按凯恩斯理论是以消费需求为导向的,而忽略了对生产行为的处理,另外在货币金融方面,如对价格、利率的处理也不很合适,但其经验仍很值得后来的模型所借鉴。
3.沃顿模型。
沃顿模型也是一个中等规模的计量模型。它受克莱因—戈尔登博格模型的影响,但与该模型又有三点不同之处:第一,它使用的是季度数据,从1948.1~1964.1共68组样本;第二,它主要是用于经济预测,特别侧重于国民收入各要素和就业方面;第三,总量变量被划分得比较细,并且货币金融部分比较完善。这个模型有76个方程,其中47个随机方程,29个定义式,有118个变量,42个是外生变量。模型中出现了制造业和非制造业的柯布—道格拉斯型生产函数,最大滞后期为9个季度,用2SLS法估计参数。
沃顿模型的主要研制者埃文思(Evans)和克莱因指出[52]:“这个模型是能够进行季度预测的最简单的模型,并有足够的规模包括了在宏观经济水平上与一般商业和政府决策有关的大多数经济变量。”实际上,此模型与专家判断相结合,对以后8个季度的经济预测的效果是比较好的。
沃顿模型后来又发展出了几种变形,主要有,沃顿Ⅲ型模型,[53]以及沃顿年度和工业预测模型,[54]它们都在不同程度上扩大了沃顿模型的预测功能。
4.布鲁金斯模型。
布鲁金斯模型[55]是到20世纪60年代早期为止的关于美国经济的最大的经济计量模型,美国各大学和研究机构的30位经济学家参与了这一著名模型的研制工作。在这个“标准”型中,包括176个内生变量,89个外生变量,使用了1949~1960年的近60组季度数据。这个模型虽然较为庞大,但其结构有明显的模块递推形式,因而避免了使用联立估计方法估计参数的自由度不足问题。各主要模块分别使用2SLS和LIML方法得到具有一致性的参数估计值。这个模型包括了较详细的经济内容,并首次引入了7个主要产业部门的投入产出关系。模型的最大滞后期为8个季度。
布鲁金斯模型主要用于经济周期的结构分析、政策评价,以及经济增长的长期研究。这个模型被许多经济学家进行必要修改后用于他们各自感兴趣的经济问题的研究。布鲁金斯模型不仅对后来的模型产生了重要的影响,而且经济学家们共同努力建立一个大型模型的工作方式也为后来的大型模型研制工作树立了榜样。例如后来的LINK模型,有数十个国家的数百名经济学者参加了工作。
5. MPS模型。
MPS模型[56]也是许多经济学家合作的结果,它是由美国联邦储备局、麻省理工学院和宾夕法尼亚大学共同研制的。MPS模型也是一个大型季度经济计量模型,有6个主要模块,包括75个随机方程和96个非随机方程。它可以用于短期预测,但其主要目的是为联邦储备局做货币金融政策评价之用。
6. DRI模型。
DRI模型[57]是由数据资源公司研制的,也是一个大型模型,有7个主要模块,包括379个随机方程及339个非随机方程,并有170个外生变量。此模型具有明显的受沃顿模型和布鲁金斯模型影响的特点,其中包括一个51个产业部门的投入产出模块。DRI模型有以下特点:第一,具有与收入支出系统相应的资金流模块;第二,具有通货膨胀过程的过程阶段模块,可以对经济环境变化引起的各种价格变化的情况进行跟踪;第三,包括了人口,以及人口对长期潜在产出和就业状况的影响的内容;第四,包括了州政府和地方政府行为以及它们的预算内容。
DRI模型可用于结构分析、预测和政策评价各方面,它在使用中的一个重要特点是,一年一次使用最新数据进行重新估计。这是长期维护使用一个模型的必要条件。
(三)美国主要经济计量模型之间的关系
美国经济学家英特里利盖特(Intriligator)在他的著作《经济计量模型、技术和应用》一书中,曾用“树图”来表示美国主要经济计量模型之间的关系。[58]这个图很清晰地反映了从丁伯根模型开始,一直到70年代主要美国经济计量模型之间的“血缘”关系(见图1-1),图中有几个3.4.2节中未提及的模型,可参见英特里利盖特的著作。
(四)克莱因
在本节的结尾,有必要特别提及克莱因在宏观经济模型的理论和应用研究方面的杰出贡献。继丁伯根的工作之后,克莱因首次把宏观经济模型应用于宏观经济问题总量水平的全面研究中,开辟了进行经济预测和政策分析的新途径。
从20世纪50年代起一直到今天,克莱因一直是宏观经济计量模型理论和应用研究的一位先锋和主帅。在这一过程中,他的工作特点在于解决实际问题的色彩越来越鲜明。在50年代中期,他研制了1921~1941年美国经济模型和克莱因—戈尔登博格模型。从50年代后期开始,他参加了英国、加拿大、日本等国的模型编制工作。60年代初,他参加并领导了布鲁金斯模型与沃顿模型的研制工作,赢得了广泛的声誉。60年代末,他又倡议并促成了世界联接模型体系(Project Link)的建立。在这之后,许多美国或其他国家的宏观模型中都不难发现他的影响的存在。
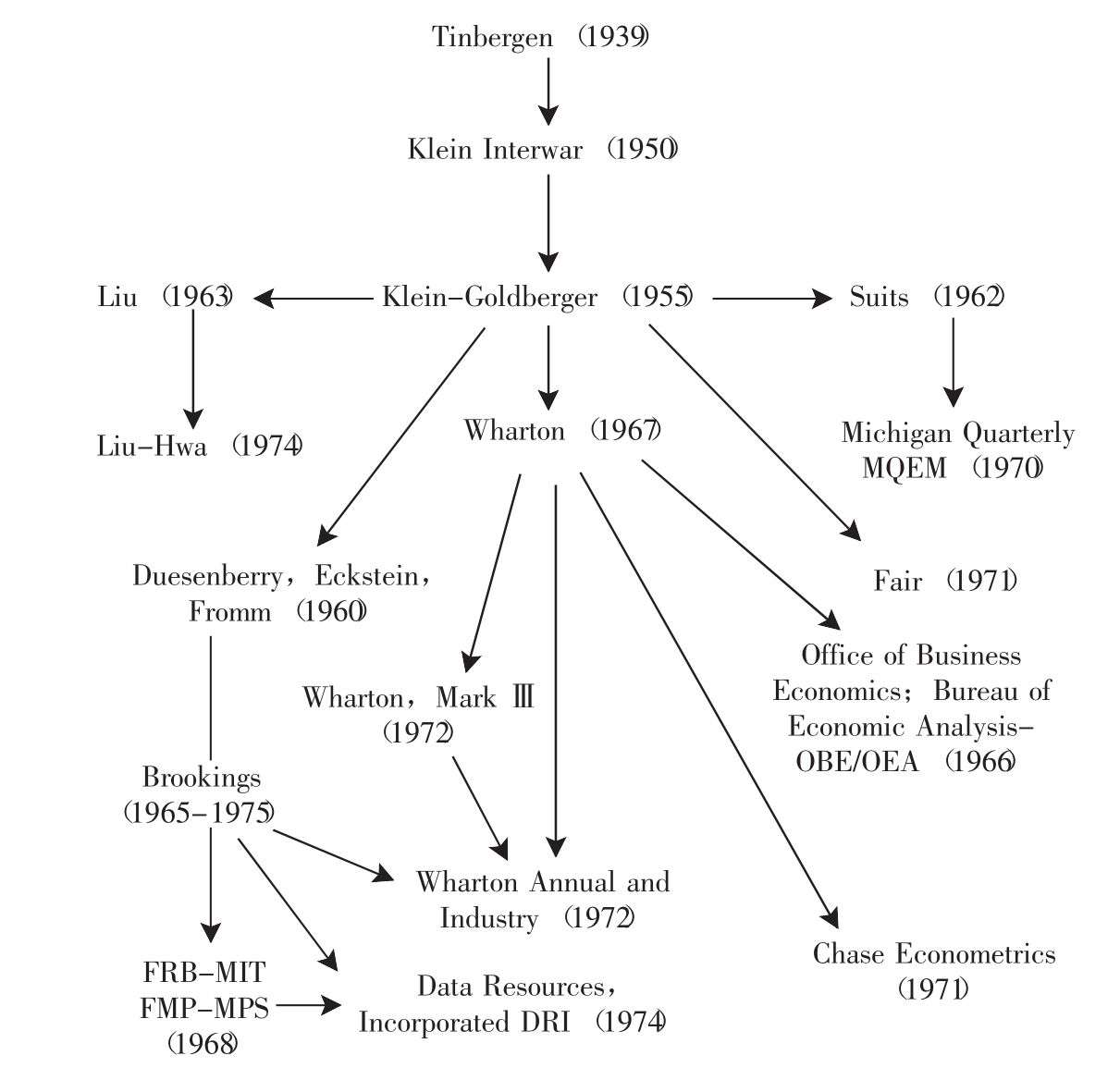
图1-1
由于克莱因在宏观经济模型的理论研究、实际应用以及推广普及方面所做出的重大贡献,他获得了1980年诺贝尔经济学奖金。乌家培同志曾将克莱因对发展经济计量分析的历史作用归纳为三点,现摘录如下:[59]
“①第一个把凯恩斯理论与经济计量方法结合起来,与荷兰的丁伯根有所不同,他开辟了宏观经济计量模型的领域,并把宏观经济计量模型提高到重要地位。他的特点在于不是一般地分析经济条件和价格运动,而是把它用于预测经济发展趋势、评价经济政策等方面。②他经过三十多年的努力,把经济计量模型从课堂带到实际部门,包括企业、政府和国际组织的应用。他不满足于教学模型而致力于工作模型,以适应实际决策者在经济工作中的需要。他强调‘走出去’ ,用我们的话来说,就是理论与实际相结合,理论为实际服务。③他把宏观经济计量模型从个别国家的范围扩展到世界的范围,发起和创立了连接许多国家经济计量模型的Project Link。……这种设想和行动要比其他西方经济学家企图一下子建立全球性的世界经济模型现实。同时它也为将来每个国家或地区建立一种标准的模型,然后把它们集中在一个模型内并用一定机制连接在一起逐步创造条件。”
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










