



第一节 结构方程模型适配检验结果
为了量化验证、精确说明微博客涵化作用机制以及影响关系的理论模型,经过第四章介绍的研究数据收集过程、数据分析过程,本研究实现了对于微博客公益行为相关信息涵化作用结构方程的拟合。实际样本数据对于整体结构方程的拟合结果如下。
一、不违规估计检查结果[1]
不存在违规估计(offending estimated)的情况,参数的估计结果都在可以接受的范围。
(一)各个路径系数都具有显著性
Regression Weights:Group number 1-Default model
表4-1 微博客公益行为相关信息涵化作用结构方程模型未标准化路径系数[2]
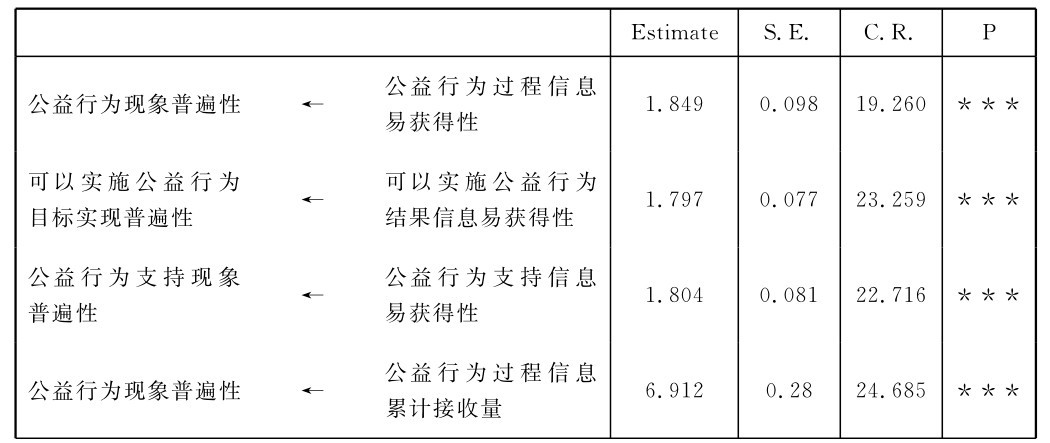
续表

续表
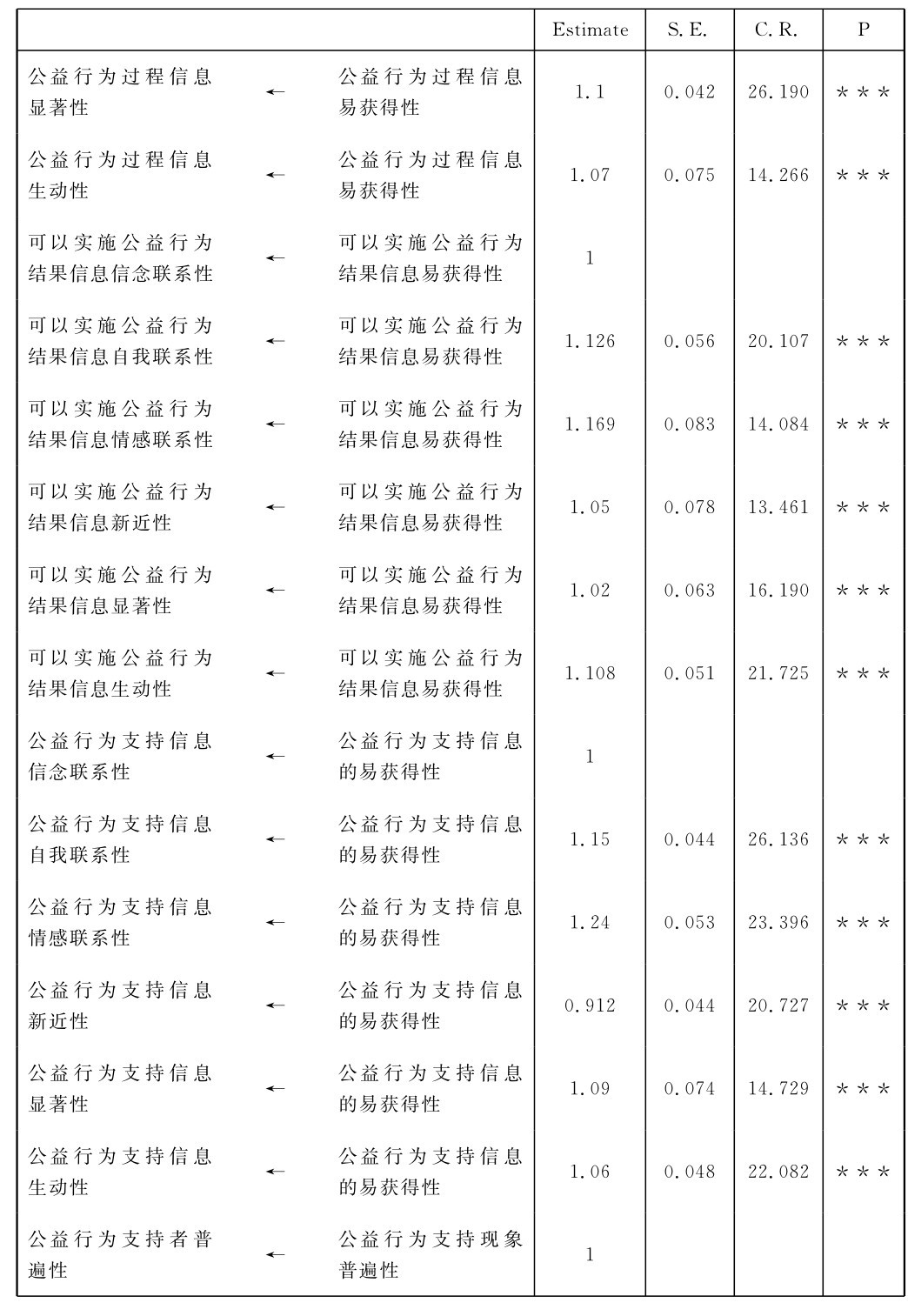
续表
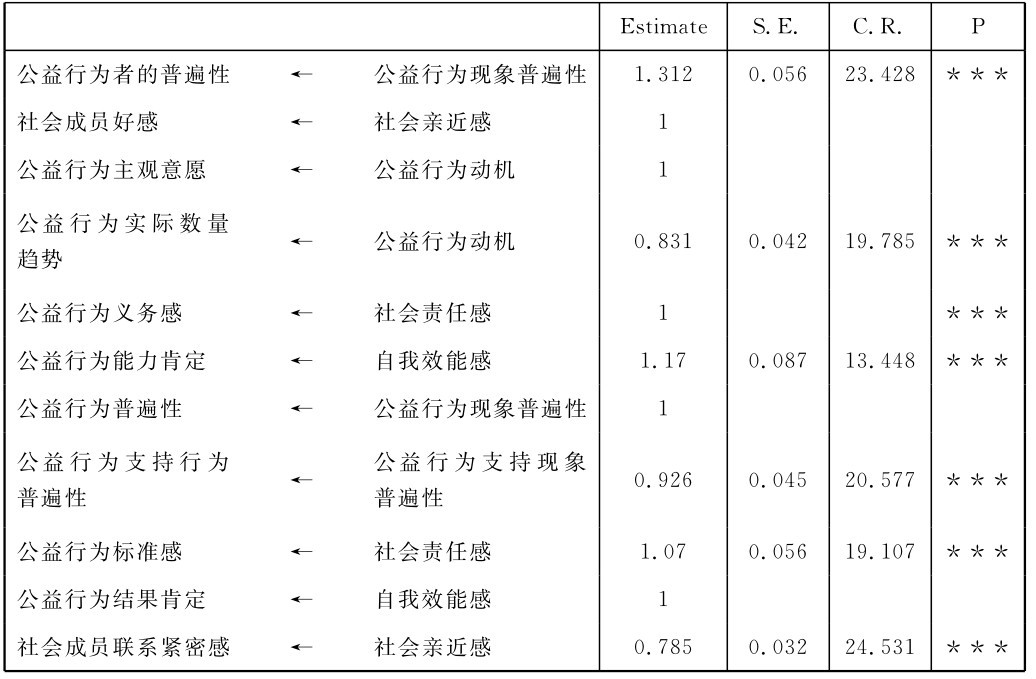
说明:***表示显著性检验水平<0.001,即P<0.001
从表4-1可以看出,在C.R即critical ration(临界比率值)方面,所有未标准化路径系数的C.R值的区间为(12,28),最小值为12.608,最大值为28.704。而C.R值相当于显著性检验中的t值,当t值,这里即C.R值>2.58时,该未标准化路径系数的显著性水平就相当于P<0.01,这就说明了结构方程模型中的各个变量间的回归系数都具有很高的显著性水平,这些未标准化路径系数所代表的变量之间的影响关系有99%的把握是存在的,这些对变量间的影响关系具有数理统计意义上的存在显著性(吴明隆,2009)。而表中,各个未标准化路径系数对应的P值一列上,A-MOS(18.0)检验计算后给出的P值结果皆为***(<0.01),也说明了该未标准化路径系数,即变量之间的线性影响关系水平具有较高的显著性,表明这些系数参数均显著不等于零。这也就说明了该结构方程模型的回归系数拟合结果不存在违规估计,都在可以接受的范围内。
(二)估计参数中不存在负的误差方差
这一点从表4-2《微博客公益行为相关信息涵化作用结构方程模型[3]误差方差分析表》中直观可见。
如下表呈现的误差方差(列S.E.)所显示,微博客涵化作用结构方程模型的误差方差的测量误差值最小值为0.298,没有负的误差方差存在。
表4-2 微博客公益行为相关信息涵化作用结构方程模型误差方差分析表
Variances:(Group number 1-Default model)
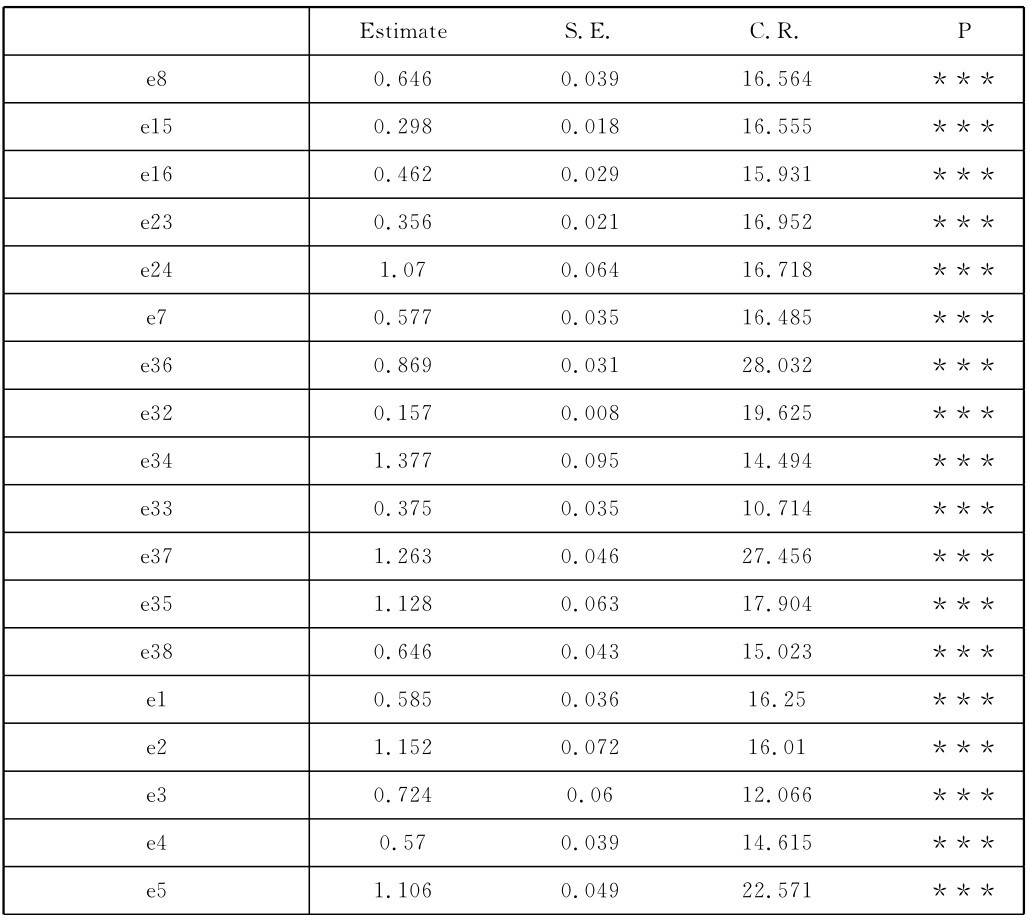
续表
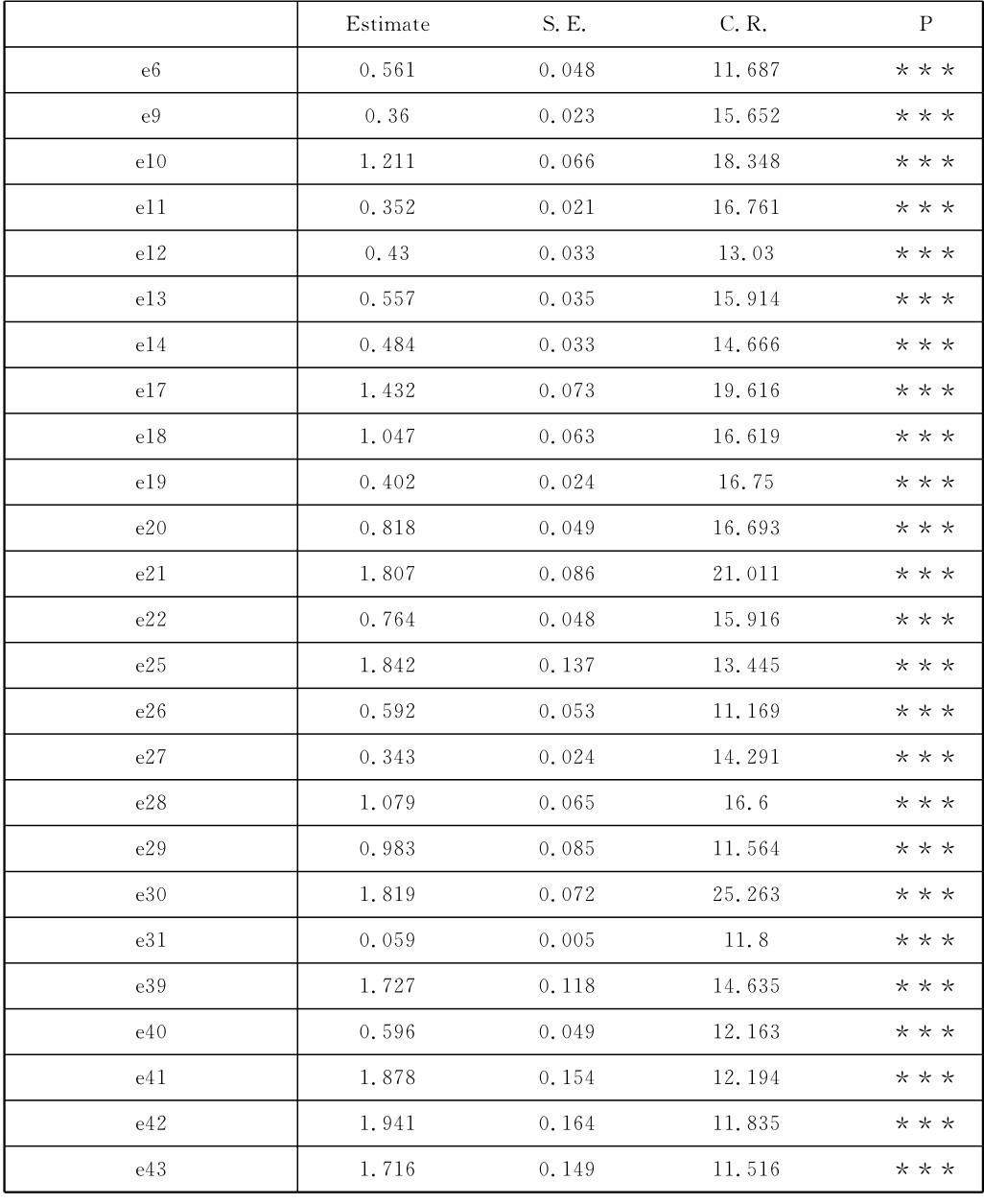
(三)所有误差方差都达到显著水平
这一点从表4-2中直观可见。表4-2中显示所有误差方差的C.R值,也就是t值的数值区间为10.404至28.032之间,都大于2.58,p值列也都显示***,表示这些误差变异均达到了p<0.01的较高显著水平。
而且,模型估计的标准化残差的数值区间为[0.42,0.85],所有标准化残差的绝对值都小于2.5。表示测量模型与样本数据能够适配(吴明隆,2013)。
以上两点说明模型参数估计的误差部分没有出现违规估计,误差估计结果均在可以接受的范围。
(四)潜在变量之间标准化路径系数的绝对值均未超过0.95,不接近1
如表4-3所示,结构模型部分估计的显潜变量间、潜变量间的标准化系数值的区间为0.712到0.85,大于0.7,小于0.95。
表4-3 微博客公益行为相关信息涵化作用结构方程模型标准化路径系数表 Standardized Regression Weights:(Group number 1-Default model)

续表

续表

(五)潜在变量与其测量指标间的因子载荷量,介于0.50至0.95之间
这一点从表4-3直观可见。测量模型部分,潜在变量与其测量指标间的标准化系数的数值区间为0.712到0.912,大于0.7,小于0.95,处于模型拟合适配要求的(-1,1)区间之内。
以上两点说明模型参数估计的变量间标准化路径系数部分没有出现违规估计,标准化路径系数估计结果均在可以接受的范围。
二、整体模型适配度
(一)整体模型适配度各指标水平
用于结构方程模型适配度评判的指标以及判断标准复杂多样,且各有侧重,也各有针对性。但是基本上,对于结构方程模型绝对适配度[4]的指标以及指标标准界值的选择都是依据以下的三条原则,第一,不受到样本容量的影响;第二,能够惩罚复杂的模型[5];第三,对于设计错误的模型具有敏感性。那么以这三条原则为依据,结合Hu、Bentler(1999)温忠麟、侯杰泰、Mashibert(2004)和吴明隆(2009)等多位统计学者的意见,本研究选择了以下几个模型适配度指标作为检验本研究模型绝对适配度的指标,并按照这些指标对应的评判标准对本研究模型的绝对适配程度(适配界值)进行了检验,得到的结果如下。
1.卡方值(CMIN)
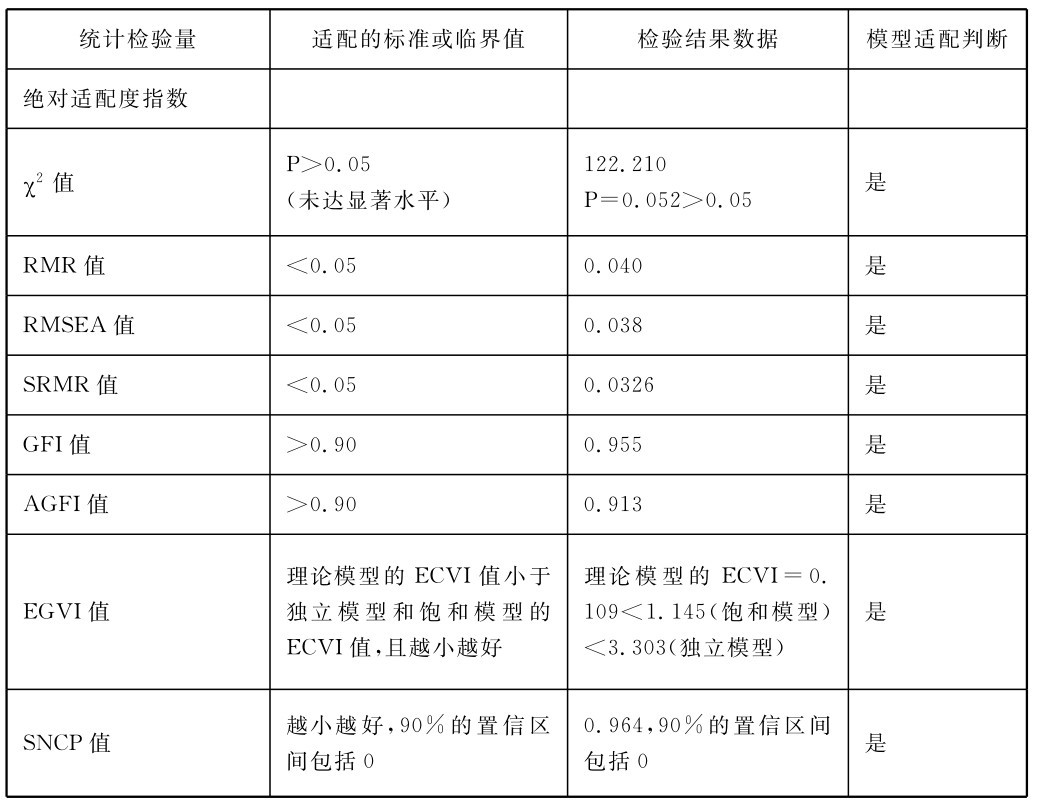
卡方值越大,卡方值显著性水平越小,说明理论模型与实际数据越适配。一般来说,当卡方显著度检验水平P>0.05时,说明结构方程模型拟合的程度越好。但是实际上卡方值的大小不仅与自由度多少相关,也与被试样本数量密切相关。样本数量越大,其卡方值就越大,这样就导致很多本来是拟合良好的模型,由于样本量过大,而卡方值较高,进而卡方检验都被拒绝。所以,对于这一模型适配度指标,其评判标准要根据样本量进行具体分析判断。根据温忠麟、侯杰泰、马什赫伯特(2004)的相关研究显示,“卡方准则可以被列入优秀的指数准则之一。更明确一些,卡方准则的显著性水平是:N≤150时,α=0.01;N=200时,α=0.001;N=250时,α=0.0005;N≥500时,α=0.0001。[6]但是对于N≥1000的大样本, α=0.0001还是不够小,其结果就是卡方值往往很大而导致拟合得不错的模型都被拒绝。因此我们建议在N<1000时才使用卡方准则”[7]。所以根据这一标准,在样本量N≥500的情况下,只要卡方检验的显著水平即P值>0.0001,那么卡方检验就不会被拒绝,就可以说明该模型具有良好的适配度。而本模型的样本量是543人,如表5-4所示,卡方值CMIN的显著程度P为0.056,远大于0.0001,所以本模型在卡方值这一主要的绝对适配度指标上具有较好的拟合表现。
表4-4 微博客公益行为相关信息涵化作用结构方程模型CMIN检验表

说明:default model(预设模型):即我们所建立的模型,也就是本研究按照理论概念模型而建立的结构方程模型。
饱和模型(Saturated model):对观测变量的方差及变量之间的所有相关进行估计的模型(对数据适合最佳的模型)
独立模型(Independence model):只顾及观测变量方差的模型(对数据适合最不佳的模型)[8]
在此,本研究将在呈现预设模型的数据之外,也将其他两个模型对应的拟合指标数据一并呈现,作为参照对比之用,以更加明确地显示本研究构建的理论模型与实际数据的相对拟合程度,更加全面地说明本理论模型与实际数据的契合程度。
以上对于模型名称的说明同样适用于以下各个表格中的相同名称,其含义皆参照此说明,不再赘述。
2.卡方自由度比(CMIN/DF)
作为衡量模型的协方差矩阵与样本数据适配程度的另一指标,卡方自由度的比值,其值介于1至2之间时,表示模型适配良好。当得值小于1时,模型是过度适配,表示该模型适用于特殊的样本,具有样本独特性;“当其值大于2.0(最高不能超过5.0)时,则假设模型尚无法反映真实观察数据,即模型契合度不佳,模型需要改进”[9]。而如表4-4所示,本模型CMIN/DF值为0.193,说明本研究模型与样本数据的契合度可以接受,假设模型关系符合实际观察情况。
3.GFI(goodness of fit index)拟合优度指数
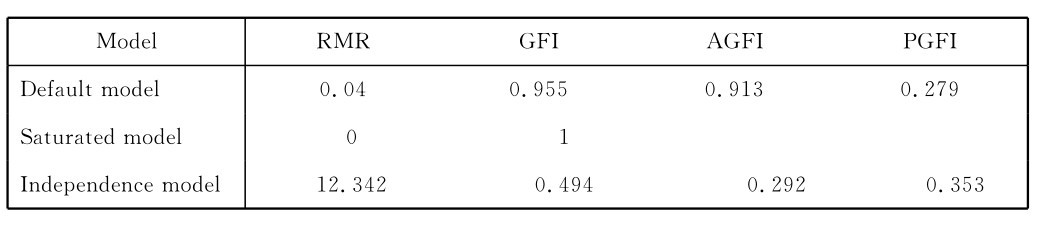
此指标指数得值越接近1,表示模型绝对适配程度越高,通常采用GFI>0.9这一界值标准,而如表4-5所示,本模型的GIF值为0.955,表示模型拟合良好。
表4-5 微博客公益行为相关信息涵化作用结构方程模型RMR,GFI检验表
4.AGFI:(adjusted goodness-of-fit index)调整后适配度指数
作为对于GFI指数的调整,AGFI指标不再受到计量单位的影响,其估计公式中,同时考虑到要估计参数的数目与观察变量的数量,它主要是利用假设模型中的自由度与模型变量个数的比率对GFI指标进行修正。所以该指标在反映模型与样本数据的拟合程度上,更具有标准化和稳定性。一般认为AGFI值大于0.90,就表示该模型变量间的路径关系与实际观察数据有着良好的适配程度。
而本模型的AGFI值如表4-5所示,为0.913,超过判断合格的界值0.90,所以这一指标上的得值也说明了本研究架构的模型得到了样本数据较好的支持。
5.RMR(root mean square residual)残差均方和平方根[10]
该指标越接近于0,表明该模型的拟合程度越好,通常的标准是要<0.05,而本模型的RMR值如上表4-5所示为0.04,满足该模型拟合判断标准。
6.RMSEA(root mean square error of approximation)渐进残差均方和平方根
该指标作为最重要的适配指标,其得值的大小直接指示了理论模型的适配程度。一般来说其得值小于0.05就表示该模型拟合良好,在0. 05与0.08之间则说明该模型拟合合理,可以接受。(吴明隆,2013)本研究模型的RMSEA得值如下表所示,为0.038,表示本假设模型与实际样本数据拟合良好,具有较高的契合度。
表4-6 微博客涵化作用结构方程模型RMSEA检验表

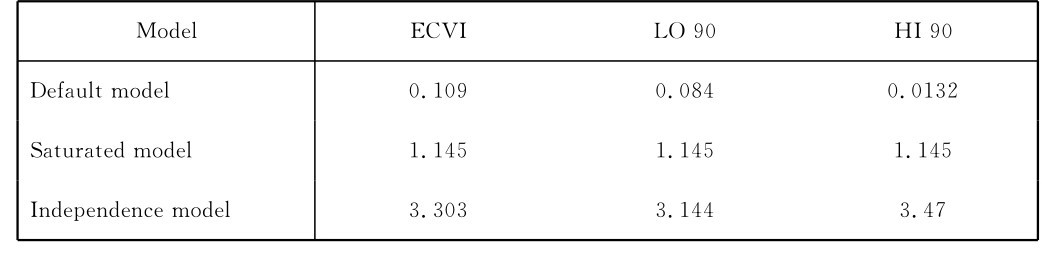
7.ECVI值(expected cross-validation)期望跨效度指数
ECVI值不像其他的模型整体拟合判断指标一样,可以参照一个固定的界值来判别模型是否与观察数据的适配程度,判断假设关系与实际数据之间的契合程度,该指标主要作为判断模型的复核效度使用。常用于预设模型与独立模型、饱和模型间的比较和模型选择。具体的判断标准就是预设模型(即研究构建的理论模型)Default model的ECVI值要小于独立模型Independence model的ECVI值,且小于饱和模型Saturated model的ECVI值(吴明隆,2013)。而本研究构建的模型ECVI值如下表《微博客涵化作用结构方程模型ECVI检验表》所示,可见Default model的ECVI为0.109小于Independence model的ECVI值3.303,也小于Saturated model饱和模型的ECVI值1.145,所以在这一复核指标上,本研究结构方程模型的拟合程度也能够被接受。
表4-7 微博客涵化作用结构方程模型ECVI检验表
三、结构方程拟合结果分析
除以上详细说明的模型的绝对适配度指标外,本研究还对模型的增值适配度、简约适配度。以及模型的基本适配度、内在适配度进行了检验。具体结果如下表4-8、表4-9、表4-10所示。
表4-8 微博客涵化作用结构方程整体模型适配度的检验结果摘要表
续表
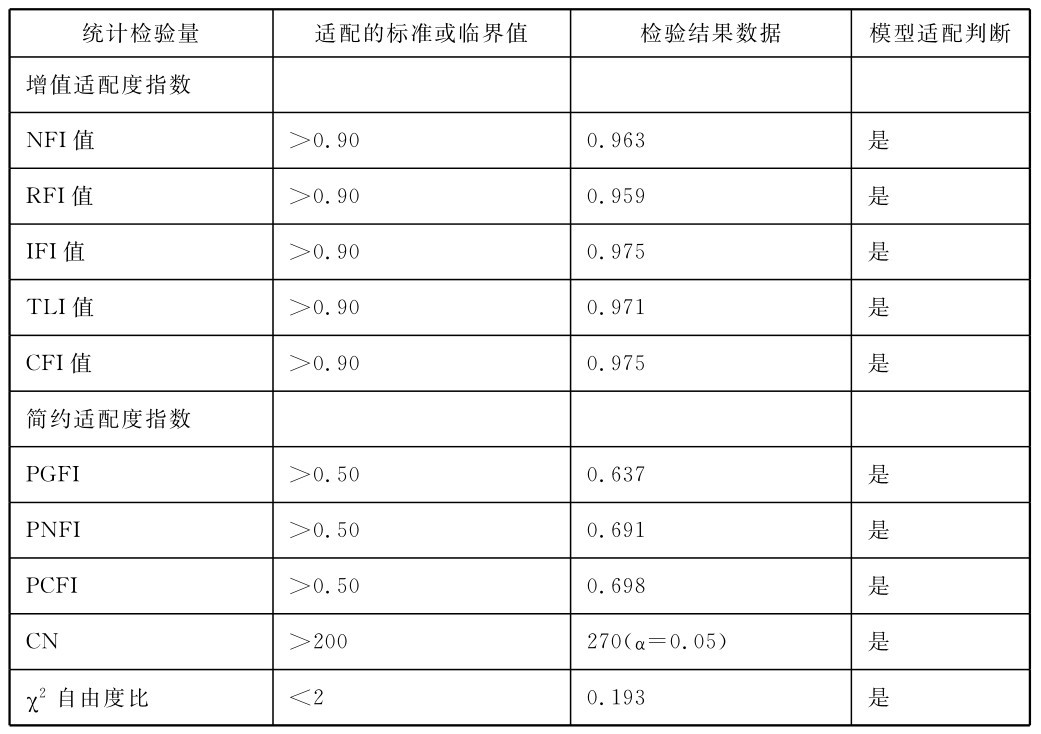
表4-9 微博客涵化作用结构方程模型基本适配度的检验结果摘要表
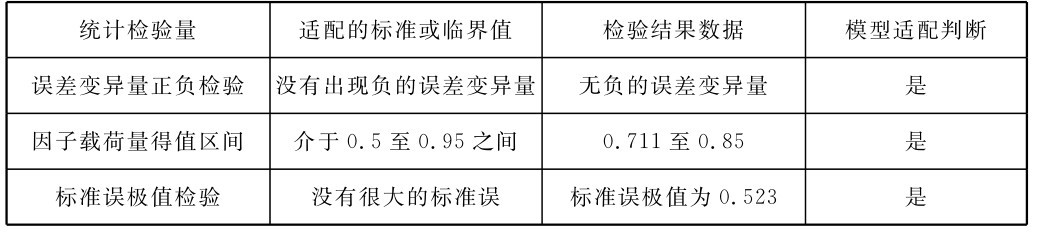
表4-10 微博客涵化作用结构方程模型内在适配度的检验结果摘要表
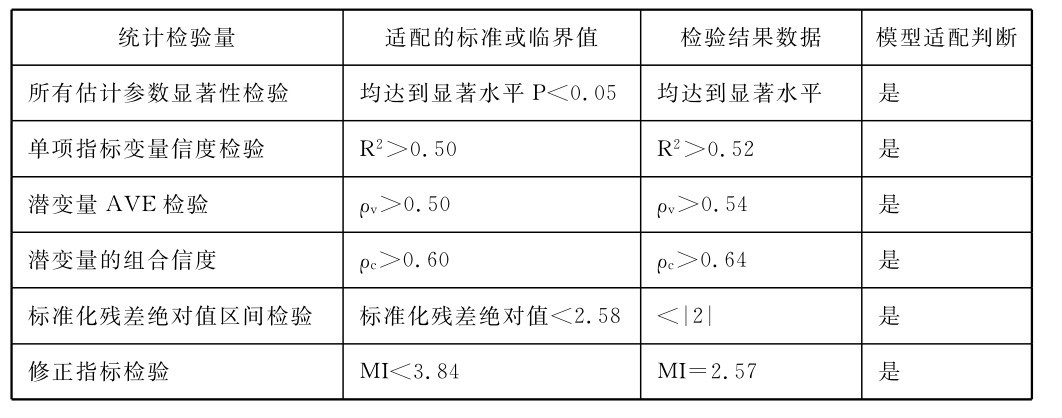
综合以上各个模型适配度指标的评鉴结果可见,本研究构建的微博客公益行为相关信息涵化作用模型的绝对适配度较好,该结构方程模型得到了样本数据的充分支持,其所显示的变量间的相关关系符合观察数据的实际情况,该理论关系模型与现实情况有着较好的拟合。也就是说,该结构方程模型的测量模型所揭示的潜变量操作化定义,以及结构模型所显示的涵化影响变量之间的作用关系和关系水平都被观察数据所验证。而该结构方程模型路径图展示的测量变量和潜变量之间,以及潜变量与潜变量之间的相关关系,都具有实证意义上的显著成立性。这样笔者在本书第三章通过理论演绎所得到的关于微博客公益行为信息涵化作用效果和机制的论断,包括相关影响变量、效果变量的具体内涵和操作化定义,以及变量关系背后的涵化作用机制得到了实际数据的支持验证。同时根据实证数据对变量间关系水平的量化估算结果,可以更加详细、精确地描述微博客公益行为相关信息涵化作用因素对于各个层面上的认知心理效果影响强度、影响实现机制,进而更加切实精准地描述出微博客公益行为信息涵化作用的实际效果以及实现机制。与上述内容相关的研究成果将以第三章第二节提出的微博客公益行为相关信息涵化作用的影响关系假设为探寻线索,基于以上结构方程模型具体路径系数的详细解析,逐步呈现于以下的相关章节。
[1] 本研究所选择的违规估计判别标准主要参照Hair,Anderson、Tatham与Black(1998)的相关界定。
[2] 也就是结构方程各个变量间关系路径的未标准化路径系数。
[3] 为了行文方便,以下简称微博客涵化作用结构方程模型。
[4] 指评价结构方程模型与样本数据充分拟合,量化的概念关系模型被样本数据给予充分支持,实际证明。
[5] 估计参数过多,自由度较小的模型。
[6] N为样本量,α为显著性水平的标准,模型的卡方检验得值大于α值则表明该卡方检验结果显著,模型拟合良好。
[7] 《结构方程模型检验:拟合指数与卡方准则》,《心理学报》2004年第2期。其中N为样本量,α相当于P值。
[8] 引自荣泰生:《amos与研究方法》、重庆大学出版社2009年版,第123页。
[9] 吴明隆:《结构方程模型——amos的操作与应用》,重庆大学出版社2009年版,第43页。
[10] 吴庆隆:《结构方程模型-amos的操作与应用》,重庆大学出版社2009年版,第43页。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










