



12.3 CDSS的方法——规则推理
12.3.1 规则和逻辑
基于规则的医学推理使用了形如“IF…THEN A;ELSE B”的简单推理模式,根据此推理机制搜索与之匹配的数据模式。“IF”判断条件是否为真,如果为真,执行A方案,如果不为真,就执行B方案。
举例说明:规则“如果(IF)患者患有哮喘,那么(THEN)每到秋天都需要接种流感疫苗”。按照充分条件假言推理,规则有两条:肯定前件就要肯定后件,否定后件就要否定前件;否定前件不能否定后件,肯定后件不能肯定前件。因此推理得到,如果没有为患者注射流感疫苗,那么患者就没有哮喘病;如果为患者注射了流感疫苗,也不能确认患者患有哮喘,因为可能有其他致病因素。在此规则之下,当医生提出关于何种情况下需要注射流感疫苗问题的时候,系统可以根据相应规则对医生进行提示逻辑帮助。
再如下例所示:如果(IF)患者性别为男,患有心血管疾病,甘油三酯检测值≥150mg/dl,高密度蛋白值≤40mg/dl,那么(THEN)可以采取Fibrate治疗。如果数据收集准确,此类规则可以帮助临床医生在遇到相同情况时,提供决策支持并避免医疗差错。类似的规则推理工具还有很多,比如测定酒精成瘾症的测试方法CAGE、AUDIT以及DSM等。
在以上的规则推理逻辑中,经常直接或间接使用一组符号来表达逻辑结构,加之简单的规则内容,可以解决许多非常复杂的问题。
表12-3 逻辑运算中常见的运算符号及其意义

在查询中使用的变量是存在量词。例如在SQL中,select语句的目标就是返回一个符合查询条件的数据库条目列表。而在规则中使用的变量都是全称量词,如“所有的女儿都是女生”。规则“IF…,THEN…”可以简单归纳为以下几类(如表12-4):
表12-4 IF…THEN规则

举例说明,如在上文提过的MYCIN决策支持系统中包含的一个规则:
IF ①感染属于原发性菌血症。
②菌体的培养点是无菌点。
③细菌的侵入门户是胃肠。
THEN以0.7的置信度判定菌体是一种拟杆菌。
12.3.2 基于规则的推理引擎
目前绝大部分的软件作为有限状态的系统都使用“存在—与”(EC)逻辑。EC逻辑只包括E表示存在,以及∧表示与逻辑。通过E和∧两个操作符,EC逻辑能够表达任何物件的相关属性和关联。举例来说,在关系型和面向对象型的数据库中,信息的表达全部借助EC逻辑实现,如物件数量、属性关联、患者的相关数据内容等等。但是EC逻辑无法表达不存在的逻辑,例如“目前医院中没有患有嗜铬细胞瘤的患者”这类问题。
EC逻辑最根本的限制在于无法表达:
(1)非逻辑;
(2)或逻辑;
(3)蕴含关系;
(4)全称量词。
因此也意味着无法表达类似下列问题:
(1)哪些患者没有感染炭疽病?
(2)有没有为女性患者或单身患者准备的专门房间?
(3)每位患者都有主管医生?
(4)有没有疾病感染了所有人?
也许在绝大部分的编程语言中都可以找到“非”逻辑或其等价物。但是这些“非”逻辑的实现是通过间接的技术手段,用不成功的操作状态替代“非”的逻辑。例如查询语句没能在数据库或计算机系统内存的数据中找到目标数据,即返回false状态,进而用false状态表示“没有”此类数据的状态。通过此种集合,在EC逻辑中使用false概念的方式达到了增加规则的效果,解决了上文无法表达的查询问题。转化结果如下:
(1)列出查询“患有炭疽病”时语句状态返回false的患者。
(2)首先得出“女患者单间”查询返回false的结果与“单身患者单间”查询结果返回为false的结果取交集,再列出对此交集进行查询返回false状态的条目就是要得出的结果。
(3)对患者“拥有主管医生”查询得到false的结果进行查询得到false条目。
(4)先得到查询患者“患有此类疾病”为false的数据,意为未患有此类疾病,然后得到“未患有此类疾病患者”查询结果为false的结果,意为全部患者均患有此类疾病。
而在整个推理过程中,推理引擎作为一个有限状态机,不断重复执行以下三种动作:
(1)把数据对应到规则中,且通过这些规则产生一个执行规则的冲突集,用以识别规则之间的冲突情况;
(2)在冲突集中选择执行规则;
(3)执行规则。
其中匹配数据,产生规则的冲突集是最消耗计算成本的工作,目前的三种主要算法为:brute force算法,indexing算法和rete算法。
12.3.3 前向链推理(数据驱动)
通常用于处理知识数据的搜索策略,从已知的事实出发推出结论或建议,符合蕴含逻辑的推导顺序。我们通常把前向链推理系统称之为“production”系统。系统中的每个规则都是一个微型小程序,被称为production。每个production都由两部分组成:左边的条件模板和右边的操作。当左边的模板和工作空间中的元素匹配的时候,就运行右边的操作。
推理规则的形式为:左边部分<右边部分。左边部分是此规则运行的条件,也就是说当工作空间中的数据满足左边部分的条件的时候,此规则将被运行。而右边部分则是实际的运行程序。整个系统的工作流程如下:①选择一个左边部分符合工作空间的数据的规则;②运行此规则的右边部分;③重复上面的步骤,直到没有规则能被使用为止。当有多个规则同时符合工作空间的数据的时候,不同的production系统使用不同的选择规则的算法,例如选择第一个符合条件的规则。
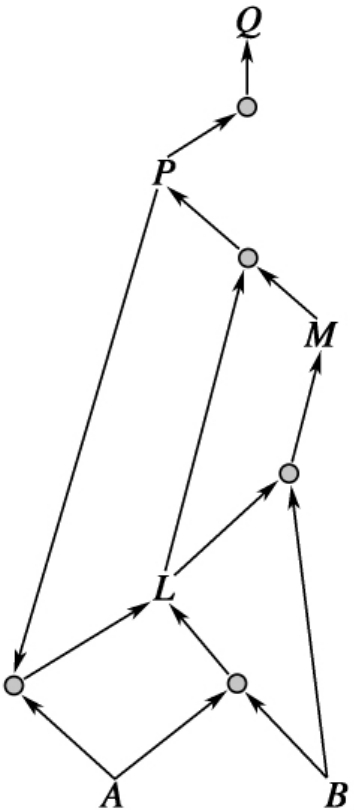
图12-5 前向链推理顺序图
解释性编程语言的编译器使用前向链推理的方法进行变量类型检查,如强类型语言C。一旦声明变量(满足规则左侧条件),编译器将会检查在程序中所有同名变量是否符合类型规定(执行右侧操作)。
举例说明:
规则:P<Q,L∧M<P,B∧L<M,A∧P<L,A∧B<L
事实:A,B
目标:是否可以通过此知识库推出Q?
事实A和B将驱动条件得到满足的规则进行运转,得到的结果又成为其他规则的前提条件。这个过程将持续进行直到规则运转的最终停止,同时得到Q被推导出来与否。在这个过程中,不断产生新事实数据驱动推导过程。也正是因为这个原因,前向链推理也被称为数据驱动推理(见图12-5)。
12.3.4 后向链推理(目标驱动)
对应于前向链推理的后向链推理搜索策略,依照蕴含逻辑的逆向推导顺序,从结论的否命题出发推出前提条件的命题为否。值得注意的是,根据此推理方法是不能根据结论命题为真而推出事实条件为真。
后向链推理的基本思想是从诊断等目标内容出发,在知识库中匹配有相同结论的规则内容,假定推理目标存在并推出规则中左侧事实条件的逻辑状态,进而寻找事实数据对条件的真假性进行证明。当用户提供的数据与系统所需要的事实证据完全匹配成功时,则推理成功,所做的假设也就得到了判断。这种推理方式又称为目标驱动方式,与前向链推理相比,后向链推理具有很强的目的性。
我们可以用一个网络表达后向链推理的方法,见图12-6:
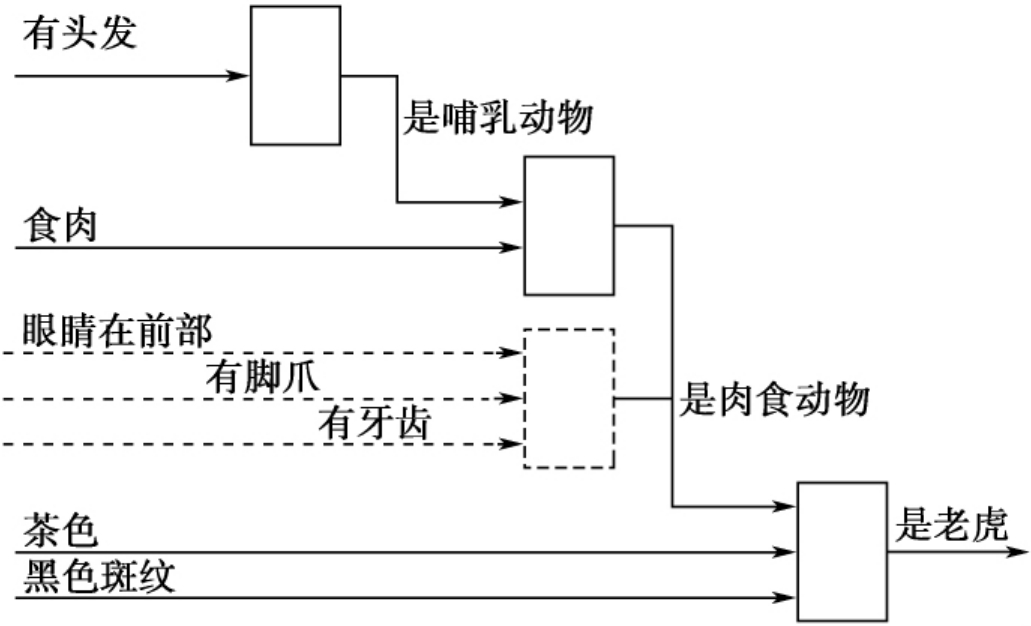
图12-6 后向链推理方法示意图
再以上文提供的示例数据为已知条件进行后向链推导,得出Q的过程为:从向后推导要求首先检视Q是否已知真假。若非,则顺序检查包含Q的所有规则中的前提条件。为了避免形成推导的无限循环状态,需要确定目标内容不能彼此嵌套存在,且次级目标的真假不能处于未知状态。
此例中,假定Q为假->P为假;再由P为假->L或M为假;此时如果L为假->A或B为假,同时P或A为假;其中L的次级目标为已经参加运算的P,故此规则略过,另一规则中A,B已知作为事实为真,推导出L不可能为假;另一方面M可能为假,但有A,L都为真可证得M也为真;进而由此证得P为真,Q为真。
12.3.5 前后向链推理的比较与联合
前向链数据驱动推理和后向链目标驱动推理有很大的不同。目标驱动适用于最终的可能解答较少的情况,例如简单诊断或识别系统。这样的系统通过从用户那里获得有用的信息,从而有效地证明或者推翻一系列的可能的解答。最终给出正确的答案。而有些系统由于组合爆炸的原因,最终的可能解答数量大得惊人,以至于无法对其一一进行测试,这个时候就需要使用数据驱动了。例如配置一台机器,假设某台机器由10个部件组成,而每个部件又有10种可选的方案,那么一共就有10的10次方种最终配置方法,显然对每种方法进行测试是不可能的。
于是,一些推理机制联合了前向链和后向链两种推理方法。当数据对象较少时,倾向于以数据驱动的前向链方法,因为这些数据可以有选择性地对知识库中的对应规则进行触发。当数据事实过多难以触发数量巨大的production程序规则时,会使用目标驱动的后向链推理方法以便提高效率。
在医疗系统中检验结果解释程序、预前预后程序、医疗计划、检测程序以及设备管理程序通常使用前向链推理的方法;而诊断程序、系统调试修复、通常使用后向链推理的方法。前后向链混合的方法通常用在临床说明系统中。
12.3.6 基于规则推理的专家系统案例推理
通常,一个以规则为基础,以问题求解为中心的专家系统,通过借助人类专业知识实现其在特定领域辅助决策的能力,例如在医学诊断方面。如图12-7所示,它主要由下述五个部分组成:知识库(knowledge Base)、推理引擎(infer engine)、数据库(database)或工作空间(working memory)、解释工具(explanatory facilitates)和用户界面(user interface)。各部分之间的相互关系一般可形式化地表达为下图,
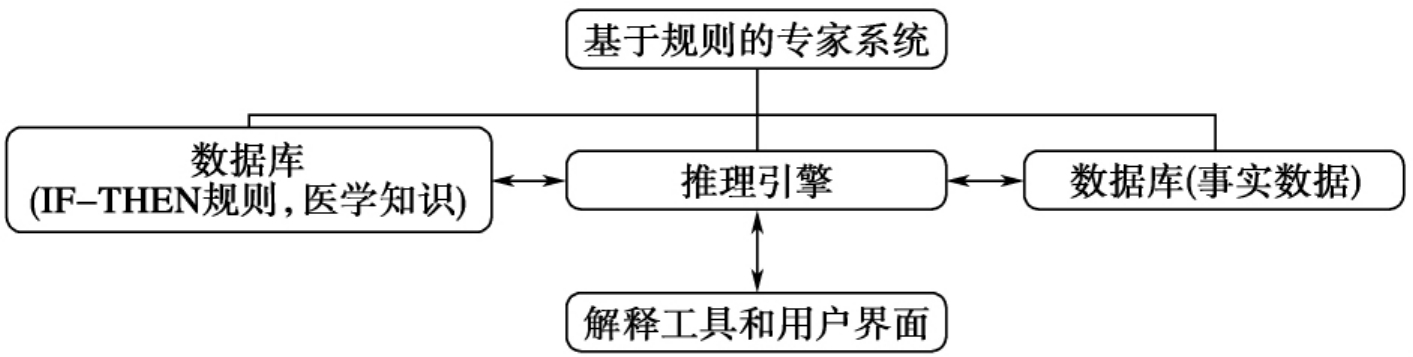
图12-7 基于规则的专家系统的结构
其中,知识库包含一组由标准语言表达的事实集合,而推论引擎产生用于推导新事实的规则。典型的规则推理专家系统以上文提到的MYCIN决策支持系统为代表。
MYCIN是一个通过提供决策支持来帮助医生诊治细菌感染性疾病的专家系统。于1972年开始研制,到1974年基本完成。MYCIN的取名来自多种治疗药物的公共后缀,如氯洁霉素(clindamycin)、红霉素(erythromycin)等。许多早期的医学专家系统,都参照了MYCIN系统的技术,如知识表现、不确定推理、推理解释、知识获取等。
MYCIN由规则库、数据库和控制系统三个部分组成,使用后向链推理,从问题求解的目标出发,搜寻原始证据支持目标成立。规则库是MYCIN的知识库,数据库和控制系统联合形成推理机。其中,数据库用以保存问题求解的原始证据(初始状态)和中间结果。由于当时尚未出现视窗技术,用户界面只提供基于文本的问答过程和结果显示。
MYCIN的知识库以前提条件——产生式规则来表示诊断和治疗细菌感染性疾病的专家级医学知识,以实现专家级诊断和治疗能力。MYCIN系统建立的初期按照下述格式在知识库中收集了200多条规则,其中047号规则表示为:
[规则047]
如果:(1)培养物取自血液,且
(2)病原体的身份未鉴别,且
(3)病原体的染色是革兰氏阴性,且
(4)病原体的形态为杆状,且
(5)患者被烧伤。
那么:该病原体的身份应鉴别为假单胞细菌,且可信度为0.4。
12.3.7 规则推理的优缺点
规则推理的优点在于:
(1)与临床专家进行推理的过程相似。
(2)规则推理可以用于临床指导。
(3)将知识和工作流程分离。
另一方面,规则推理的局限包括:
(1)在一个较大的知识库中,难以避免规则之间的冲突。
(2)系统难以进行更新和维护,向大型的规则库中加入新规则会导致许多无法预见的结果,从而直接导致系统难以进行调试。
(3)许多类型的知识都难以通过规则的形式表达出来,如存在非确定性的知识以及随时间信息不断变化的知识内容。
(4)操作呆板,对于专业领域外的信息束手无策。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。












