



基于作者学术关系的科学交流 研究综述[1]
邱均平 马瑞敏
(武汉大学科学评价研究中心)
【摘 要】 科学交流的本质是知识的交流,如何使得知识的交流有序化和规范化是摆在我们面前非常重要的课题。研究科学交流的视角有多种,本文主要是从“作者学术关系”这一视角出发来研究科学交流。本文首先探讨了作者学术关系的基本理论问题,包括作者学术关系的类型以及其在科学交流的应用方面等;然后着重总结和介绍了基于作者学术关系的科学交流研究的国内外进展情况;最后指出了以后研究的发展方向。
【关键词】 作者学术关系 科学交流 研究进展
The research progress on the scientific communication on the basis of author academic relationship
Qiu Junping Ma Ruimin
(Research Center for Chinese Science Evaluation,Wuhan University)
【Abstract】 The essence of scientific communication is knowledge communication.How to order and regulate the communication of knowledge is an important research task.There are many research perspectives about scientific communication,but this paper does related research on the perspective of author academic relationship.This paper firstly discusses the basic theory of author academic relationship,including its types and the applications in scientific communication. Then,it introduces the research progress of scientific communication on the basis of author academic relationship.Meanwhile,it points out the future research directions in this field in the end.
【Keywords】 author academic relationship scientific communication research progress
科学交流的主体是科学工作者,而作者无疑是科学工作者中的重要组成部分,是知识创新的源泉。但是,科学并不是个人的产物。正如著名哲学家T.S.Kuhn所说:“科学研究尽管是由个人进行的,而科学知识本质上却是集团的产物,如不考虑创造这种知识的集团特殊性,那就无法理解知识的特有效能,也无法理解它的发展方式[1]”。如果科学家蒙头做实验和研究,不和他人交流就很难有重要的突破。并且我们注意到,很多学者都把“我是站在巨人的肩膀上”作为自己的座右铭。这告诉我们,没有前人成果的启迪就很难产生新的思想火花。科学交流深深地影响着科学的进程,整个科学的进程无不是学者间(不论是否跨时空)不断进行科学交流的过程。由此可见,科学交流促进了科学发展,是科技进步的关键环节。在科学交流系统中,作者和作者必然存在着各种学术关系并构成巨大的知识网络。通过对这些关系的研究,可以从中发现科学交流的模式和规律,也可以探测科学交流的知识结构,从而有利于科学交流的有序化和科学化,并且在促进新思想产生、提高创新能力和保障创新型国家建设方面都有着积极意义。
1 作者学术关系概述
1.1 作者学术关系的定义、类型与构建
1.1.1 作者学术关系的定义
要对作者学术关系加以定义,需要对该短语进行分拆,然后再进行组合,即首先要对“什么是关系”做一个清楚的了解,然后对“学术关系”进行科学界定,最后将主体——“作者”加入即可构成完整的“作者学术关系”定义。
“关系”在《现代汉语词典》中有5种含义,分别如下[2]:①事物之间相互作用、相互影响的状态。②人和人或人和事物之间的某种性质的联系。③对有关事物的影响或重要性;值得注意的地方(常与“没有、有”连用)。④泛指原因、条件等。⑤表明有某种组织关系的证件。⑥关联;牵涉,比如棉花是关系到国计民生的重要物资。很显然,考虑到研究主体——“作者”,我们这里的“关系”主要是指第②点,即人和人之间的某种性质的联系。
“学术关系”,如果从上面“关系”的定义来看,是指人和人之间的学术方面的联系,但是这一定义仍然不清晰,“学术”是一个非常宽泛的概念,“学术”在《现代汉语词典》中定义为“有系统的、专门的学问”。人和人学术方面的联系包含的类型和种类也比较多,比如学术座谈会、信件的交流、联合主持学术会议、合作出书和撰写文章等。需要强调的是,这里的“人”主要是指学者,但是即使限定为学者,仍然无法有效理清楚他们之间“学术关系”的类型。所以本文将学者的属性限定在“作者”范畴,即强调学者作为“论文发表者”的这一属性,而一个作者的论文也可以作为其他论文的参考文献,所以论文又可以从发文和引文两个角度来衡量。这样,作者即充当了知识的生产者和知识的接收者的双重角色。
基于以上的考虑,我们可以对“作者学术关系”作如下的定义,即:从论文的角度(包括发文和引文)出发,作者和作者之间表现出的某种学术联系。
1.1.2 作者学术关系的类型
从论文的角度出发,作者和作者之间的学术关系主要表现在四个方面:
(1)作者合作关系:这里的合作和广义的合作(比如项目合作、共同主持会议等)是不同的,仍然严格限定在“论文”范围之内。它是指两个作者或者多个作者共同撰写一篇文章,即这些作者同时出现在某篇论文的署名中。这是两个作者间主动、直接的知识交流关系。两个作者合著的文章越多,说明两人的研究兴趣越一致。两个作者合著论文的篇次被称为他们的“合作频次”或者是“合作强度”。
(2)作者引用关系:合作是完全从发文的角度来构建作者之间的学术关系,而引文则从发文和参考文献两个方面进行构建。发文和参考文献构建起庞大的引文网络,如果我们把文献替换为作者,则构成了作者引用网络。与合作网络不同的是,引用网络是有向的,情况更加复杂。对于两个作者之间的引用关系,既有单项的(如图1所示),也有双向的(如图2所示)。单向引用表示的是知识的单方向流动,一方是知识的生产者(箭头的初端),另一方是知识的接收者(箭头的末端),知识交流有一方处于被动;双向引用表示的是知识的双向流动,知识交流最为充分,互动性良好。如果考虑多个作者,则构成了作者引用网络,通过该网络我们就可以深入发掘作者引用关系背后深藏的科学交流模式和规律。图3给出的是一个简单的作者引用关系网络。在该图中可以很直观地看出有些作者完全是知识的吸收者(比如A);有些作者则互动良好,并且形成了该网络的“明星”(比如D)[2]。
![]()
图1 单向引用
![]()
图2 双向引用

图3 作者引用关系网络示意图
另外需要指出的是,在作者引用关系网络中,还隐藏着两种特殊的关系,即作者同被引关系和作者耦合关系(如图4所示)。作者同被引关系:即两个作者同时出现在一篇文章的参考文献中。如果两个作者同时频繁出现在一些文献(数量为N)的参考文献中,说明两人的研究兴趣比较一致。数量N则被称为他们的“同被引频次”或者是“同被引强度”。这是两个作者之间一种被动、间接的知识交流关系,即他们的关系不是凭自身主观意愿建立的,且并不直接发生关系,他们的关系纽带建立在引用他们的第三方文献基础上。作者耦合关系:即两个作者发表的文章引用了一些相同文献。这些相同文献数量越大(数量为N),说明两者的研究兴趣越相似。数量N则被称为他们的“耦合频次”或者是“耦合强度”。这是两个作者之间一种主动、间接的知识交流关系,即他们关系的建立是源于自身意愿但是通过第三方即共同引用的参考文献这一中介表现出来的。
从图4来看,左边是作者同被引关系,作者A和作者B出现在某论文的参考文献中,同被引强度为1。右边是作者耦合关系,作者A的一篇论文和作者B的一篇论文共同参考了文献1,他们的耦合强度为1。
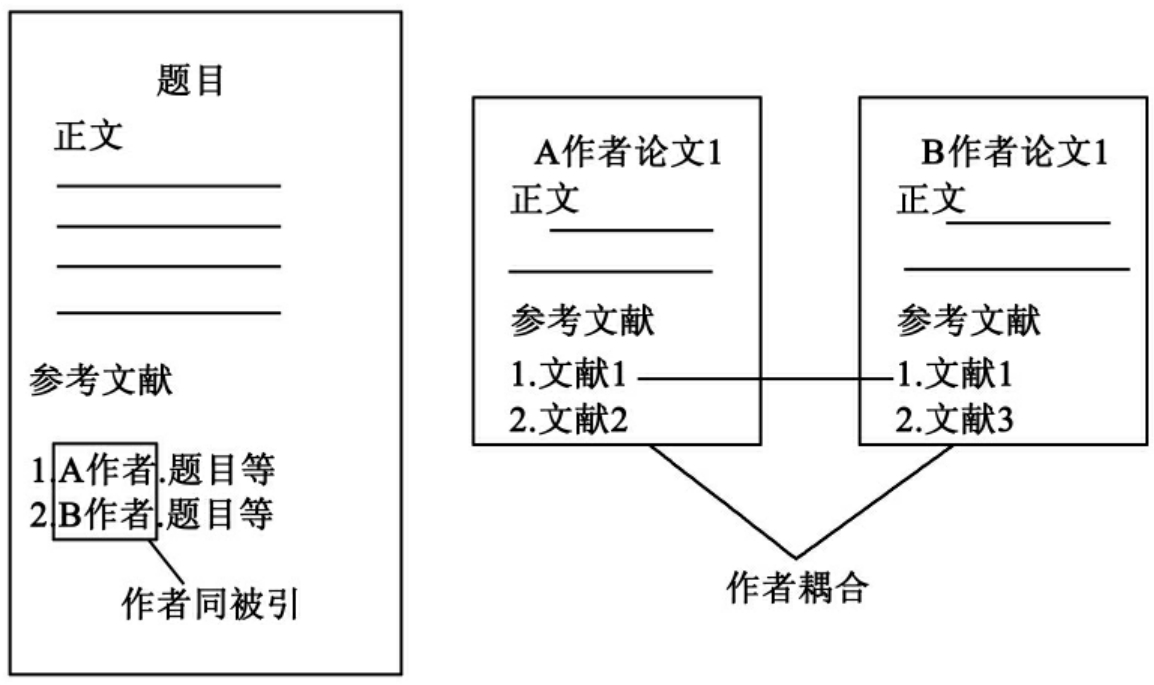
图4 作者同被引和作者耦合示意图
(3)作者链接关系:作者链接关系基本和作者引用关系是一样的,在此不再详述。这里主要阐述两者的不同之处。作者链接是通过超链接而建立起来的作者之间的学术关系,而很明显,“链接”范围比“引用”范围要宽广一些,后者一般都是局限在某个学术数据库内,而前者则不受此限制,它对所有网上的相关资源都可以索引。所以,作者链接将有可能使作者之间的学术关系网扩大,并使得作者之间的学术关系加强。这是作者链接与作者引用最大的区别。
1.1.3 作者学术关系的构建
由于在实际研究中我们并不只是研究某两个作者的关系,那么必然涉及多人关系,要想深入地分析作者之间的学术关系,首先要将这种关系用计算机能识别的方式表示出来。一般来讲,从数据的形式角度来看,关系数据主要有两类:一是行动者和行动者数据;二是行动者和事件数据[3]。显然,作者和作者的关系数据属于行动者和行动者数据,这种数据的格式一般都是方正数据,即行和列是相同的。
方正数据又可以分为对称数据和非对称数据,对于作者合作、同被引和耦合数据是对称数据(如表1所示),而作者引用则是非对称数据(如表2所示)。对角线则根据实际情况填写,表1和表2中先暂时设置为空值。
表1 对称性关系数据

表2 非对称性关系数据
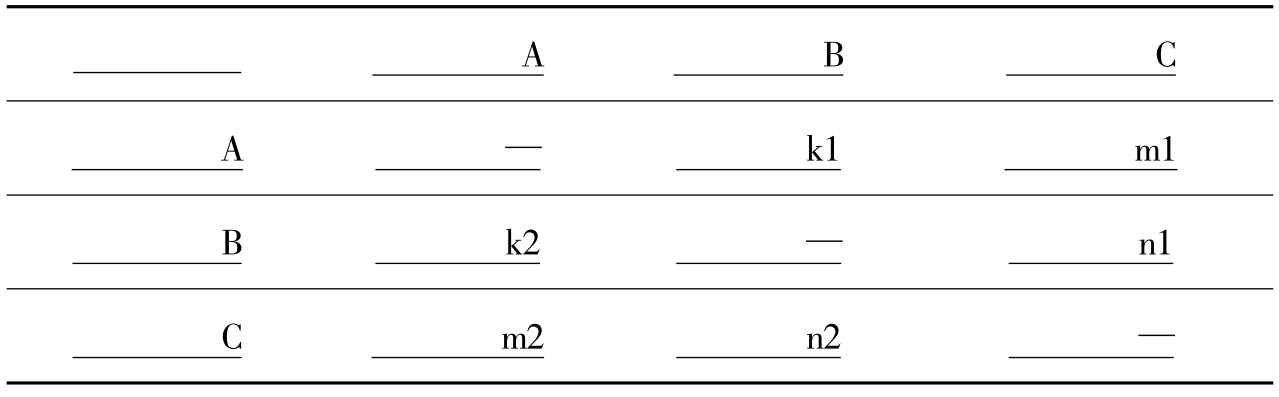
另外,对于作者关系的相似性,一般情况可以从两个角度来考察:一是绝对相似性,二是相对相似性[3]。所谓绝对相似性就是指两个作者的直接关系。比如A和B同时被引用3次,B和C同时被引用5次,那么我们说B与C较A有着更大的相似性,这种相似性的判断是从两个作者之间的关系强度出发的。所谓相对相似性是指全面考虑每个作者和除自己以外其他作者的关系,然后再比较两个作者之间的相似性。比如研究对象总共有4个(矩阵如表3),其中A和B的关系强度为10,A和C也为10,B和C也为10,那么从绝对相似性来看,A和B和C之间都具有最大的相似性,但是如果考虑到D的存在则需要重新考虑他们三者之间的关系,发现A和B还是等同的,而C则由于和D的关系相对不紧密,导致C和A和B有着一定的差别。在统计学中,这种相似性可以通过皮尔逊相关系数法、Cosine法和欧几里德距离等来测度。
表3 假想四人对称矩阵

1.2 作者学术关系在科学交流中的应用
科学交流是一个比较抽象的科学名词,而在实际研究科学交流时,往往是从学者之间的关系网络出发来研究。那么,作者学术关系在科学交流研究中可以有哪些方面的应用呢?由于作者学术关系的研究仍然主要属于文献计量的范畴,在此首先回顾Borgman在《科学交流与文献计量》一书中的相关研究,她指出文献计量尤其是引文分析在科学交流研究上有几个方面的应用:(1)识别和描述科学共同体(Characterizing scholarly communities):即回答这样几个问题,一是“一个领域由哪些科学共同体构成”,二是“每个科学共同体到底在研究什么”,三是“每个科学共同体的作者的特点是什么”。实质上,这一方面的应用就是如何发现一个研究领域的知识结构,知识结构正是由不同研究主题构成的有机整体。而研究对象既可以是文献(比如文献同被引,documentation co-citaion和文献耦合,Bibliographic coupling),也可以是词汇(比如共词,co-word),还可以是作者(比如作者同被引,author co-citation)。(2)揭示科学共同体的演变(Evolution of scholarly communities):很多研究已经表明一个学科或者领域的科学共同体的构成并不是一成不变的,而是随着时间的推移而有所改变的。并且,即使是一个科学共同体内部也会随着时间在人员组成和数量方面有所改变。而这种改变对于我们了解一个学科或者领域的变化、把握研究重点和前沿领域都有非常重要的意义。(3)评价学术贡献:文献计量已经非常广泛地应用在评价作者、论文和期刊等的影响力方面。很多研究进行了该方面的研究。比如被引次数、高被引论文、热门论文、影响因子、h指数等都是被大家熟知的评价指标。可以说,利用文献进行科学评价越来越受到关注,这种关注不仅限于国外,而且在国内也进行得如火如荼,并且日趋规范化和科学化。(4)思想演变轨迹的发现(Diffusion study):这一应用影响很大,比如对于双螺旋基因研究的历史轨迹及香农的信息理论发展历程等。这一点通过引文的时序网络可以进行清晰的描绘,加菲尔德博士及其团队已经开发了Histcite软件来实现这一研究目的。
对Borgman的研究进行总结,可以发现作者学术关系至少能在如下两个方面应用:一是学科或者领域科学交流知识结构及其演变研究中的应用;二是作者学术水平评价方面的应用。另外需要指出的是,Borgman的总结主要集中在较为微观的层面上,而对于引文分析在科学交流模式尤其是科学交流规律发现方面的总结仍然有所欠缺。而随着复杂网络研究的逐渐兴起,对于小世界效应和无标度特征(幂律分布)等规律性的研究引起了学者的极大关注。而正如前文所指出的,复杂网络中包含着合作网络和引文网络,所以作者学术关系在科学交流模式与规律方面也有着应用,是更加宏观方面且具有指导意义的应用。
1.2.1 科学交流模式与规律验证或发现
科学交流模式的定义根据不同的研究出发点有着不同的定义。比如按照载体来定义,则可以定义为正式交流模式和非正式交流模式,如果按照流程来定义,则又有诸如Garvey-Griffith模式、Murd模式等。可见,模式的研究需要一个合适的切入点,从该切入点出发来发现科学交流的模式。
文献发表后便进入了正式交流渠道,如果它的表现是杂乱无章的,那么我们就不会对其有一个清晰的认识,也不会利用其来进行相关的理论与应用研究。早在20世纪初文献计量学诞生的时候,就有许多关于科学交流规律的研究。比如文献计量学中的三大经典定律,其实质都是对文献(包括其作者和载体——期刊)在科学交流系统中的分布进行研究。布拉德福定律是对文献信息集中于离散分布规律的研究;齐普夫定律是对文献信息词频分布规律的研究;洛特卡定律是对文献信息作者分布规律的研究。随着科研条件和环境的改变,学者们对于这三大定律进行了不断的验证(包括修正)和扩展(新发现)。尤其是为了适应网络环境的变化,许多研究有了“网络”的烙印。比如早在1997年,R.Rousseau就对纯网络环境下网站的分布进行了研究,他发现网站被链接数量的分布也符合洛特卡定律[4]。在国内,张洋也以网络环境下的布拉德福定律研究作为其博士论文的重要内容进行了实证研究,着重研究了Web下载总频次的布拉德福分布研究[5]。虽然这些传统的文献计量规律和作者学术关系的关联性并不是很直接、很紧密,但是这些规律可以为作者学术关系的相关研究带来很多启示。
作者学术关系中包含规律的研究是随着复杂网络的研究逐步深入的。正如前文所述,在过去的研究中已经证实很多学科的作者合作网络都是复杂网络。在复杂网络中,作者合作网络有着小世界效应特征,即在较短的路径内作者之间就可以认识,并且合作作者之间合作的概率也是比较高的(高集聚系数);同时,作者度的分布满足幂律分布,而幂律分布是信息计量学中普遍存在的分布规律(三大定律的实质都是幂律分布,即布-齐-洛的统一)。最近的一些研究也发现作者合作子网的分布也满足幂律分布(比如,G.Palla等,2005[6];王福生和杨洪勇,2007[7];等等)。但是,当前的研究还主要集中在外文作者合作的研究上,对于中文作者的合作研究还是非常欠缺的。对于引用网络,普赖斯无疑是该方面研究的先驱,他早在1965年的一篇发表在Science上的论文中就发现了在引用网络中论文的度分布满足幂律分布[8]。当然,受到当时实验条件的限制,他还不可能进行太大规模的研究。那个时代的他也没有明确提出“幂律分布”这样如今被广泛认知的概念。直到1998年,Redner利用大量数据对引文网络再次进行了相关研究,他再次证实了论文引用网络中论文度的分布符合幂律分布[9]。但是,我们可以发现,从作者引用关系这一角度出发来发现其背后隐藏的交流规律的研究还没有,对其研究是非常迫切的。
1.2.2 科学交流知识结构的发现及其演变分析
科学交流结构包括拓扑结构、社会结构和知识结构三种结构[4]。这里主要研究科学交流的知识结构的发现及其演变。通过作者关系的分析来研究科学交流知识结构已经有近30年的历史。早在1981年,White和Griffith[10]就明确提出了利用作者同被引关系来进行一个学科或者领域知识结构的发现和分析[5]。最近几年对于它的研究更是如火如荼。我们可以看到不仅在国外最近几年发表了大量关于作者同被引的论文,国内也有许多相关论文(详见下文“国内外研究现状”)。由此可见,作者同被引分析已经是当前信息计量学界的一个研究热点。在前文中已经提到,作者同被引的研究热点集中在如下两个方面:一是对于传统同被引方法的修正;二是结果可视化。现在对于作者同被引的研究吸引了许多不同学科的学者,并且在许多学科知识结构的发现中都得以应用。
该方面的研究,对当前研究影响最大且极具参考价值的是White和McCain于1998年发表的关于《信息科学研究可视化》一文(曾获得美国科学技术情报学会最佳论文奖)[11]。在这篇长达19页的论文中,他们分时段(1972—1995年,1972—1979年,1980—1987年,1988—1995年)地分析了国外信息科学的知识结构。他们指出信息科学主要由“文献计量”和“信息检索”这两个部分构成,虽然随着时间的推移,由原来信息检索比例较大转为文献计量专家比例较大。他们用图形表现了这种变化,如图5和图6所示。我们可以清楚地看到,文献计量学的研究学者(图5左侧)在1980—1987年这一时段所占比例相对信息检索的研究学者是比较少的,而在随后的8年(如图6所示)则有了翻转——文献计量的研究占据了主要地位。
图5 1980—1987年图书情报学知识结构
1.2.3 作者学术贡献的评价
通过作者合作网络和引用网络的构建可以衡量作者的学术贡献,并且随着社会网络的一些概念和方法的引入,使得对于作者学术贡献的研究更加多样且科学。
首先来看作者合作网络中,一个作者的度代表一个作者的学术地位。如果一个作者的度较大,那么说明和他合作的人多,其学术辐射范围广,是某个方面比较有学术地位的学者。另外,我们引入社会网络中的中间中心性来考察作者控制信息的能力。中间中心性(betweenness centrality)[6]是指一个节点处于许多网络路径上,可以认为此点居于重要地位,因为该点具有控制其他两人之间的交往的能力,它测量的是行动者对资源控制的程度。结构洞(structural holes)的概念也基于此,指两个点以距离[7]2相连而不是以距离1相连,那么两点之间就存在一个结构洞[8]。其测度可以用“中间性比例”来衡量,具体为:经过点X并且连接这两点的测地线[9]占这两点之间的测地线总数之比。一个点的中间中心度测量的是该点在多大程度上控制他人之间的交往,是一个很有用的指数。但是需要指出的是该指数只能用于二值数据。我们可以利用该指数测度作者研究方向的交叉性,如果一个作者处在两个研究方向群体的中间(或者说两个群体通过这个作者连接起来),那么该作者知识交流起着重要的“桥梁”作用。

图6 1988—1995年图书情报学知识结构
引文网络在评价学者学术贡献方面的应用则更广泛,也更受大家关注。首先,引文网络中一个作者的加权度数[10]就是一个作者的被引次数,而一般来讲,一个作者被引次数的高低往往代表着其学术的影响力。当然,从引文网络中还可以按照年代来考察一个作者在“高被引论文数、热门论文数、平均被引次数等”指标方面的表现。特别值得关注的是,h指数的提出无疑给作者学术贡献的评价带来了全新的理念和方法支撑,这也是近几年在作者评价方面的突破。而h指数的确定正是基于引文网络。h指数是由美国加州大学圣地亚哥分校的物理学家赫希(J.H.Hirsch)教授于2005年提出的[12]。h指数(h-index)的定义文字表述如下:一个学者的h指数就是指他发表的所有论文中,有h篇论文分别被引用了至少h次。h确定的方法如下:按照论文被引次数降序排列,当TCr<r时,则h=r-1,其中r为按论文被引次数降序排列的论文序号,TCr表示排名第r的论文的被引次数。这种方法非常简单,可操作性强。用赫希的话说,只需要“花30秒钟”。下面给出科学计量学界最高奖普赖斯奖获得者的h指数。由于武汉大学数据库订购时间从1999年开始,所以不能够反映这些学者真实的h指数。在此引用比利时科学计量学家Leo Egghe的论文数据[13],具体如表4所示。
表4 普赖斯奖获得者的h指数(按h指数降序排列)

从表4可以一目了然地看出当前科学计量学界的精英都有些什么人,大致排序是怎样一种情况。随着h指数的提出,很多学者都对其进行了改进,形成了庞大的h指数家族(比如g指数、AR指数等)[11]。但是,h指数的影响力是广泛的,更为广泛地被人们接受虽然它并不完美[12]。
最后需要强调的是从作者引用关系来评价作者的学术影响力是一种比较客观的方法,但是其中仍然存在着一些问题,比如作者之间的虚引甚至是故意自引等。然而,对于大数据样本来说,这些负面影响还是比较弱的。当然,在遴选核心作者或者特定研究对象时,在结合引用的情况下,还要结合专家意见和自己对于该学科领域学者的了解等情况,只有这样才能较全面地把握一个学科的核心作者群体。
2 国内外研究现状
2.1 国外研究现状
科学交流的研究在国外有着悠久的历史,并且不同学科背景的学者都参与其中。比如科学社会学奠基人R.K.Merton就提出了论著的优先权问题[14],从而从根本上解决了学者为什么不断创作这一问题,他开创了研究科学交流社会结构与过程(social process and structure)的先河;著名哲学家T.S.Kuhn则在其著作《科学革命的结构》[15]中给出了科学如何发展、演变及影响因素等哲学层面的解释,他开创了研究科学交流的认知变革和结构(cognitive change and structure)的先河;而科学计量学之父D.J.Price则利用科学计量学方法对科学增长、无形学院中的合作等进行了计量研究[16],从另一个更加细致且更具说服力的方面来研究科学交流,他开创了利用数据来研究科学交流的结构和过程之先河。他们三人的众多传世论著都集中在20世纪60年代,可以说,关于科学交流的研究发端于20世纪60年代。遵循着这些奠基人的科学足迹,国外关于科学交流的研究不断涌现并逐步兴盛。国外关于基于作者学术关系的科学交流研究主要集中在以下三个方面:
(1)关于作者合作的研究。作者合作关系的研究历史也非常悠久,早在20世纪60年代科学计量学之父D.J.Price和著名科学计量学者D.Beaver就曾研究了“无形学院”中作者合作的关系,他们发现了高产作者在科学交流中的特殊作用:在群体内起领导作用,在群间起桥梁作用[17]。很明显,那个时候的合作还属于非正规交流,主要还是通过社会调查等方法进行相关研究。但从那以后,研究作者合作的论文便多起来,但是在科学计量学界主要集中在国家宏观层面和组织(单位)中观层面[13],对于个人微观层面的分析不够深入(主要集中在合作度和合作率等的研究上)[18]。著名科学计量学家H.Kretshmer也在2004年明确呼吁:以后的研究应该多关注微观层面的作者合作关系。可以说,科学计量学界对于作者合作微观层面的研究在很长一段时间内并没有什么实质性突破,之所以没有较大突破是因为科学计量学方法的局限,传统的科学计量方法并不利于大规模、深入地分析作者合作模式。但是最近几年社会网络分析和复杂网络分析方法的兴起给微观层面的作者合作研究提供了契机,许多学者都投身到这一极具挑战性的研究中。当前的研究主要集中在以下三个方面:
一是关于复杂网络下的作者合作关系的宏观计量分析。这方面的研究发端于20世纪末,首先是学者D.J.Watts和S.H.Strogatz研究了复杂网络的小世界效应[19];紧接着是A.L.Barabási和R.Albert研究了复杂网络中的幂律分布规律(即无标度统计特征)[20]。他们的研究立即引起了学界的广泛关注,产生了许多相关的研究成果,其中以物理学家M.E.J.Newman[21]的研究成果最有代表性[14]。他于2001年系统地研究了复杂网络环境下作者合作者数量以及作者所写论文数量的分布,发现这些分布都符合幂律分布;同时发现作者合作网络符合小世界原理,即作者之间的路径短且集聚系数高;他还指出不同学科的作者合作分布的参数等是不一样的。值得注意的是,他也明确指出:“文献计量方法还没有构建出真正的作者合作关系。”这一探索性的研究掀起了研究科学合作网络的热潮,许多不同学科的学者都投身到该方面的研究,他们研究了包括生物医药、高能物理和数学等学科领域的合作网络,发现Newman的结论在这些学科的验证中也有显著体现[22]。还需要指出的是,由于幂律分布拟合方法也存在争议,所以很多学者单独就此问题进行了系统研究。Rousseau等[23][24]提出n值拟合的方法使用的不是最小二乘法,而是最大似然估计(maximum likelihood estimate),他们通过较为严密的数学推理,认为最大似然估计更加适用于洛特卡定律,即更适用于频次—规模分布,并且他们认为利用最大似然估计方法不需要对高产作者进行删除[25]。M.L.Goldstein、S.A.Morris等人的论文中认为最大似然估计比最小二乘法更加稳健,K-S也非常适用于幂律分布的检验[26],这一点和Rousseau等的观点是完全一致的。而在Clauset、Shalizi和Newman最新论文中也指出最小二乘法和K-S结合可以很好的进行幂律分布研究[27]。同样的结论在H.Bauke的论文中也有证实[28]。Clauset等在自己研究的基础上,借鉴信息计量学学者的研究方法[15],通过严格的数学推理,给出了更加普遍的参数估算公式,这为以后的研究提供了理论和方法支撑[16]。
二是基于作者合作关系的社团发现算法的研究。要想知道作者合作的内在结构,必然涉及作者合作网络分解这一问题。社区发现算法一直是当前研究的热点,主要集中在物理学、数学和计算机科学领域。早在2002年,M.Girvan和M.E.J.Newman[29]便提出在社会网络中还有一个属性,即存在着社团结构,社团内部联系紧密而与其他社团联系疏松,并提出了社团发现算法,即现在广为流行的GN算法。后来,Newman对这一算法进行了改进,提出了Newman快速算法,从而解决了GN算法运算速度过慢的缺陷[30]。很多学者沿着这一思路进行研究,产生了丰硕成果。2005年G.palla[6]等人提出了派系过滤算法(Clique Percolation Method,CPM),解决了个人属于多个社团的重叠性问题,并研发了CFinder软件,大大方便了其他学者的研究。
三是基于社会网络分析方法的作者关系研究。主要是应用社会网络中的度、中间中心性等方法进行作者合作关系的研究。E.Otte和R.Rousseau[31]在2002年就曾呼吁将社会网络方法引入信息科学的研究,他们也研究了133位研究社会网络主题的作者之间的合作网络,用密度、接近中心性等方法测度了网络的整体属性以及作者的个体表现。F.J.Adedo[32]等研究了管理学作者的合作关系(基于7种期刊),着重研究了作者合作的原因和作者合作的网络结构。Kretshmer[33]的研究(基于385位作者)发现高产作者和低产作者在作者合作中地位的不同:高产作者一般都在大的类群中,而低产作者一般都在小的类群中;高产作者的平均距离较短,而低产作者的平均距离较短。H.Y.Hou和H.Kretshmer等[34]利用社会网络研究了《科学计量学》杂志1978—2004年的作者合作关系,并分析了科学计量学当前的研究分支方向。
通过上面的文献综述来看,国外图情学关于作者合作的研究逐渐深入,社会网络分析已经在相关研究中应用,但是基于复杂网络的研究却比较缺乏,即使有一些研究也主要是移植其他学科的方法,但对方法的原理和步骤思考不透彻,并最终导致结论的偏差和不可靠。由此可见,作者合作的研究在图书情报学研究中仍然有扩展的空间。
(2)关于作者引用关系的研究。国外对于作者引用的研究相对较少,而对引文的研究则很多。也就是说,当前非常流行的引文分析单元主要是“文献”(比如引文分布的统计特征、网页分布的统计特征),即使是分析作者,也主要是单个作者,从作者之间的相互引用来进行研究的论文非常少(需要强调的是,这里只讲作者,对于Web 2.0下的博客主的分析不进行单独讨论,但是当前对于博客等的研究也是非常有必要的),当前只发现White等[35]在2003年中研究了“Globenet”组织中(共16个成员)各成员之间的引用[17],并且进行了可视化,他们发现发生互引的作者比没有发生互引的作者在现实中交流更多。很显然,他们使用的是文献计量与实际访谈相结合的方法,具有科学社会学研究的显著特点。C.L.Borgman在《科学交流与文献计量》一书中写道:“从作者之间的引用关系出发,可以研究作者在科学交流系统中的贡献和表现,并可以研究一个学科或者领域的科学交流的结构。”[36]这两个方面都是当前研究的热点。
如何评价学者在科学交流中的贡献无疑是大家普遍关注的问题之一。关于作者在科学交流中的表现,现在已经用很多指标可以来度量,比如被引次数、热门论文数[18]、高被引论文数[19]等。当然,当前最引人注目的是h指数的提出,该方法自2005年由J.H.Hirsch提出以来得到了广泛的关注,随后很多学者都对其进行了修正,比如提出了g指数、AR指数等一系列指数。但毫无疑问的是,h指数的影响力是广泛的,不局限于科学计量学界,在各个学科的学者中以及科研管理人员中影响重大。在ISI的Web of Science平台中,已经提供了利用h指数进行科研人员评价的相关功能。可以说,h指数的提出使得科研工作者成果评价的研究有了一个新的突破。
关于基于作者同被引关系的科学交流知识结构研究起源于1981年,当时,H.D.White和B.C.Griffith提出了作者同被引这一概念,自那以后这一方法便引起了广泛关注,不局限于信息科学领域,它已经渗透到其他的学科领域。对于作者同被引关系的研究主要集中在三个方面:一是关于作者同被引基本问题的探讨和争论。这场激烈的争论始于2003年P.Ahlgren等人[37]对作者同被引矩阵转化方法——“皮尔逊相关系数”的质疑,他们认为皮尔逊相关系数不适合作为同被引矩阵转化的方法,因为它对0模块敏感,且不符合相似性测度的两个基本条件,并建议使用Cosine等方法取代皮尔逊相关系数。皮尔逊相关系数自1981年就一直被广泛使用,所以Ahlgren的质疑一石激起千层浪,吸引了众多科学计量学家的相互争论,并且引发了诸如“对角线如何设置”和“矩阵是否需要转化”等其他问题的讨论,至今这场争论还没有结束。对于对角线如何取值的问题,McCain在1990年的一篇关于作者同被引技术回顾与总结的文章中明确提道:“决定将怎样的数值置于对角线上是一个重要问题。”[38]White和Griffith在1981年的文章中最初使用的是用一个作者的总被引,但是由于受到同名作者的影响,结果并不理想,最终他们将对角线值定义为:排序前三的同被引频次之和除以2[10]。A.E.Mayer以及White等将其定义为:该作者与其他作者同被引强度的最大值[39][40]。McCain将其定义为:系统默认值(即缺失值),这也是影响最广泛的一种对角线确定方法[38]。Ahlgren等认为,应该使用自己与自己实际同被引次数(排除自引)[37]。而对于矩阵是否转化以及转化的方法无疑更是当前讨论的热点:Leydesdorff发表了《共现分析及在信息科学中的应用》一文,在该文中他提出原始共现对称矩阵根本不应该进行任何转化,需要转化的是非对称共现矩阵。如果进行了转化,则破坏了数据的属性[41]。但是,这一说法很快被Waltman和Van Eck否定,他们首先认为矩阵转化是必要的,其次还指出低版本SPSS中PROXSCAL程序的错误,错误的程序导致了错误的多维尺度分析结果[42]。Leydesdorff继而对该文进行了反驳,他利用Pajek可视化软件重新对Ahlgren等人论文中的数据进行了实证研究,发现基于原始数据的可视化结果要好于基于皮尔逊相关系数的可视化结果[43]。但是争论并没有就此结束,Leydesdorff又发表了题为On the Normalization and Visualization of Author Co-Citation Data:Salton's Cosine versus the Jaccard Index一文,他认为Jaccard指数更加适用于共引数据,比Cosine有着优越性[44]。此后不久,Van Eck和Waltman提出用Jensen-Shannon离散量和Bhattacharyya距离方法来测定作者之间的相似度[45]。二是作者同被引关系的可视化研究。如何展示作者同被引关系是当前研究的热点和难点。传统方法利用多维尺度分析(MDS)进行可视化[38],后来L.Leydesdorff又使用Pajek进行了作者同被引关系的可视化[20]。C.Chen[46][21]和White[47]等则利用Pathfinder对作者同被引进行了可视化,并发表了一系列相关论文。White还指出作者同被引应该使用原始数据作为输入数据,他发现转化为皮尔逊相关系的数据并不能很好地揭示作者的关系。C.Chen还研发了应用广泛的CiteSpace开放软件,将作者同被引关系的可视化更加科学生动,极大地促进了该方面的研究。最近D.Zhao[48]也提出了利用因子分析结果进行作者同被引关系可视化的尝试。三是积极探索纯网络环境下作者同被引的适用性。Leydesdorff等研究了Goolge Scholar环境下的作者同被引关系,他发现作者同被引在纯网络环境也有较好的适应性。Ma[49]也研究了中文Google Scholar下的中文作者同被引,选择了国内有影响力的32位作者进行了研究,发现得到的结果和实际情况基本相符,再次证明了作者同被引在纯网络环境下的适用性。
通过上面的分析,我们可以看出作者同被引研究历来备受关注,且在方法上一直有所创新,具有旺盛的生命力。但是,我们也看到在相关研究中,一些基本的理论问题还没有很好地解决。同时,在作者关系的可视化方面仍然存在一定的探索空间。
在文献计量学中,作者同被引起源于文献同被引(document co-citation),而与文献同被引紧密相关的一个概念是文献耦合(Bibliographic Coupling)。在文献同被引的基础上发展出作者同被引,而在文献耦合的基础上发展出作者耦合。但令我们惊讶的是,作者耦合的研究一直是一个空白。最早进行作者耦合研究尝试的应该是L.Leydesdorff,在他个人学术网站上提供了一个进行作者耦合分析的应用软件(Dos命令下的软件),但是,没有看到Leydesdorff利用该软件进行任何实证研究的论文,我们在利用该软件进行反复试验时,发现作者耦合包含的情况比较复杂,需要进一步梳理。不过值得一提的是,作者耦合的研究在国外也已开始了,只是刚刚起步而已,即最近D.Zhao[50]提出并实证了作者耦合,他发现作者耦合也可以用来研究作者之间的研究兴趣并窥探当前某学科的知识结构,是作者同被引的有益补充。与作者同被引如火如荼的研究相比,作者耦合研究则显得比较冷清。究其原因,可能与文献耦合历来不受信息计量学界学者重视和应用有着直接关系[51],也是直到最近才有少数几篇文章应用了文献耦合来探讨某个具体学科的前沿研究内容[52][53]。
我们可以发现作者耦合的研究才刚刚起步,需要做的工作还有很多,包括基本方法的阐明、方法是否可行、结果如何以及存在的问题等都是亟待解决的问题,可以说这是一项具有探索性的研究,充满了挑战意义。
(3)关系之间关系的研究。作者合作和作者引用(包括作者同被引和作者耦合)之间并不是完全脱节的,它们之间可能存在着某种关联,那么如何测定关系之间的关系就是摆在我们面前的一个需要解决的问题。关于关系之间关系的研究始于社会网络研究,最近几年在情报学中也得到了应用,比如,White等[35]于2003年用QAP检验了Gobenet组织中16个作者间合著、共引、互引关系之间的关系。Zuccala[54]则在研究了可以使用QAP来检验奇点理论领域作者间共引与合著的关系,但是她并没有进行实证。J.W.Schneider等[55]则介绍了两种矩阵相关算法(Mantle test[22]和Procrustes analysis)在图书情报学中的应用,从方法论的角度为以后的研究奠定了基础。
从以上的介绍可以看出,当前关系之间的关系的研究还刚刚起步,并且对于检验矩阵相关的方法理解得还不够充分和深入,这些都是将来需要着重解决的问题。
2.2 国内研究现状述评
在我国,作者合作的研究并不少见,除了简单统计作者合作度、合作率之类的论文外,也出现了一些有深度的研究论文,并且最近几年利用社会网络分析和复杂网络进行相关研究的作者日益增多。汪冰[56]曾经对我国自然科学的9种重要期刊的作者合作情况进行了统计分析,指出我国自然科学的作者合作的模式主要有“同一单位同事间合作”、“跨地区、跨单位合作”、“国际间合作”、“师生合作”和“研究员与咨询机构、实验室合作”5种合作模式。刘蓓、袁毅等[57]则利用社会网络分析法对论文合作网络进行了研究。很显然,他们从另一个角度来研究合作交流的模式,即网络拓扑结构。他们通过情报学作者合作网络的分析,发现作者合作的模式主要有双核型、流线型和核心型3种,而核心型又分为核心发散型和核心蛛网型。党亚茹早在1996年就用递阶结构方程研究了《情报学报》1990—1995年作者合著网络的内部结构。但是从1997年一直到2005年,我国图书情报学界对作者合作的研究进入停滞期,没有产生特别吸引读者的文章。到了2005年后,相关研究才逐渐增多。比较引人注目的如:2005年刘俊婉和梁立明[58]考察了1989—1998年14953对师生合著的14125篇论文的时间分布,较深入地分析了师生合著这一普遍存在的合作模式的形成原因和演变过程;张秀梅和吴巍[59]则真正开创了我国基于复杂网络的作者合作研究的模式,他们的主要角度不是分析,而是对科研合著网络的可视化系统的构建,这是一个非常好的开端,但遗憾的是迄今还没有看到基于该系统的任何深入分析的论文发表;王福生和杨洪勇[7]则较全面地分析了《情报学报》2001—2006年的作者合作网络,挖掘了子网,并发现非连通网络的统计参数也呈现出无尺度特性(幂律分布)和小世界特性;刘蓓[60]等利用社会网络分析方法分析了2000—2006年情报学合作网络的整体结构和随时间变化的动态结构,数据量较大,分析角度较全面;以北京邮电大学智能通信软件与多媒体北京市重点实验室吴斌为代表的合作团队在复杂网络的科研合作中无疑作出了较引人注目的贡献,他们在《情报学报》[61]的文章和《数字图书馆论坛》关于“复杂网络”的专题[23]深入分析了生命科学领域的作者合作网络,利用社团发现算法进行了内部结构挖掘和可视化。他们的研究主要是从复杂网络角度来考察,但是我们认为忽略了一个问题,那就是一个学科的作者合作网络并不是全连通的,而是存在很多非连通的子网,社团发现算法要求很高,并不适合处理非连通的子网,甚至不适合单一地分析作者合作网络,需要同其他方法紧密结合。
关于作者引用的研究在我国也已经开始,刘蓓等人[60]最近尝试构建了作者之间的互引关系网,但是并没有深入分析其内部结构。作者同被引在我国无疑也是研究热点,发表了较多文章。主要集中在两个方面:一是利用作者同被引进行学科结构研究,比如刘林青[62]研究了战略管理研究领域的科学共同体,马费成和宋恩梅[63]研究了我国情报学的学科知识结构;二是基于同被引的可视化系统开发,在《情报学报》上发表了较多相关论文,比如最近朱学芳等人[64]设计的中文作者同被引系统,该系统利用最小生成树等算法较清晰地勾勒出作者之间的同被引关系。由此可见,作者同被引分析在我国的研究也是相对较多且较成熟,但仍然存在一些问题,即对作者同被引原理思考不够,主要是模仿和借鉴国外的研究套路,虽然邱均平等[65]探讨了该方面的问题,但是还没有引起大家的足够重视。另外邱均平等[66]也将作者同被引应用在了纯网络环境,这也是一个有益的探索。
作者耦合这一概念在我国的几部文献计量学著作中都有提及,但目前还找不到一篇相关的实证论文。另外,关于关系之间关系的研究在我国图书情报学界还没有出现,只有2007年刘军[67]在《社会》上发表的《QAP:测量“关系”之间关系的一种方法》一文介绍了社会网络分析中QAP方法如何使用并举例进行了实证分析,该论文对我们以后的研究有着重要的借鉴作用。
3 研究展望
通过国内外研究的述评,我们认为以后的研究可以在以下几个方面展开:
(1)对于作者学术关系的研究还没有成为一个系统,基本上都是分开进行分析研究,还没有从整体上把握作者的学术关系,这一点国内外的研究都是缺乏的。
(2)对于作者合作关系,将科学计量学方法、社会网络分析和复杂网络有机结合起来,全面深入地分析作者合作的网络,不仅归纳总结其存在的合作交流模式,而且对其内在交流规律(小世界效应和幂律分布)进行统计分析。
(3)对于作者引用关系是一项全新的探索性研究,不仅需要挖掘其引用交流模式,而且还需要发现其内在交流规律。
(4)对于作者同被引,首先要解决一些至关重要的基本问题,比如对角线如何设定、矩阵是否需要转化、如果需要如何转化、同被引强度计算方法等。其次,当前学科(或领域)科学交流的知识结构展现方式(即可视化方式)也值得重新进行审视和探索。
(5)对于作者耦合的实证研究也是一项探索性研究,比如如何选择样本、选择何种耦合强度等基本问题需要反复试验,并且基于作者耦合关系和基于作者同被引关系得到的科学交流的知识结构有何不同,两者关系是什么等问题也需要重点考虑。
(6)作者合作和作者引用之间并不是完全孤立的,它们之间的关系到底如何?是否符合“合作频繁,那么互引也频繁”这样的假设?这些都是需要探索的问题。
【参考文献】
[1]Kuhn,T.S.著.必要的张力[M].纪树生,等译.福州:福建人民出版社,1981:492.
[2]中国社会科学院语言研究所词典编辑室.现代汉语词典[M].北京:商务印书馆,2005.
[3]刘军.社会网络分析导论[M].北京:社会科学文献出版社,2004:23.
[4]Rousseau R.Sitations:An Exploratory Study[J/OL].International Journal of Scientometrics,Informatrics and Bibliometrics,1997,1:1-7[2009-05-30].http://www.cindoc.csic.es/cybermetrics/articles/v1i1p1.html.
[5]张洋.网络信息计量学的理论与应用研究[D].武汉:武汉大学信息管理学院,2005.
[6]Palla G.,Derenyi I.,Farkas I.,et al.Uncovering the Overlapping Community Structure of Complex Networks in Nature and Society[J].Scinence,2005,435(7043):814-818.
[7]王福生,杨洪勇.《情报学报》作者科研合作网络及其分析[J].情报学报,2006,26(5):653-659.
[8]Price D.J.S.Networks of Scientific Papers[J].Science,1965,149(3683):510-515.
[9]Redner R.How Popular is Your Paper?An Empirical Study of the Citation Distribution[J].The European Physical Journal B,1998,4(2):131-134.
[10]White H.D.,Griffith B.C.Author Cocitation:A Literature Measure of Intellectual Structure[J].Journal of the American Society for Information Science,1980(May):163-171.
[11]White H.D.,McCain K.W.Visualizing a Discipline:An Author Co-citation Analysis of Information Science,1972-1995[J].Journal of the American Society for Information Science and Techology,1998,49(4):327-355.
[12]Hirsch,J.E..An Index to Quantify and Individual's Scientific Research Output[J].PNAS,102(46):16569-16572.
[13]Egghe L..Theory and Practise of the G-index[J].Scientometrics,2006,69(1):131-152.
[14]R.K.Merton著.科学社会学[M].鲁旭东,林聚任,译.北京:商务印书馆,2003.
[15]T.S.Kuhn著.科学革命的结构[M].金吾伦,胡新和,译.北京:北京大学出版社,2003.
[16]D.J.Price著.巴比伦以来的科学[M].王静,张风格,译.北京:中共中央党校出版社,1992.
[17]Crane D.著.无形学院—知识在科学共同体的扩散[M].刘珺珺,顾昕,等译.北京:华夏出版社,1998:4.
[18]Kretshmer H..Author Productivity and Geodesic Distance in Bibliographic Co-authorship Networks,and Visibility on the Web[J].Scientometrics,2004,60(3):410.
[19]Watts D.J.,Strogatz S.H..Collective Dynamics of“Small-world”Network[J].Nature,1998,393:440-442.
[20]Barabási A.L.,Albert R..Statistical Mechanics of Complex Networks[J].Science,1999,286:509-512.
[21]Newman M.E.J.The Structure of Scientific Collaboration Networks[J].Proceedings of the National Academy of Sciences,2001,98(2):404-409.
[22]刘则渊,尹丽春,徐大伟.试论复杂网络分析方法在合作研究中的应用[J].科技管理研究,2005(12):268.
[23]Egghe,L.,Rousseau,R.著.情报计量学引论[M].田苍林,葛赵青,译.北京:科学技术文献出版社,1991.
[24]Rousseau,R..A Table for Estimating the Exponent in Lotka's Law[J].Journal of Documentation,1993,49:409-412.
[25]Rousseau,R..Lotka:Aprogram to Fit a Power Law Distribution to Observed Frequency Data[J].Cybermetrics,2000,4(1):1-6.
[26]Goldstein,M.L.,Morris,S.A.,Yen,G.G..Problems with Fitting to the Power-law Distribution[J].The European Physical Journal B,2004,41:255-258.
[27]Clauset,A.,ShaliziC.R.,Newman M.E.J..Power-law Distributions in Empirical Data[J/OL][2009-05-03].http://arxiv.org/abs/0706.1062.
[28]Bauke,H..Parameter Estimation for Power-law Distributions by Maximum Likelihood Methods[J/OL][2009-05-04].http://arxiv.org/abs/0704.1867.
[29]Girvan,M.,Newman,M.E.J..Community Structure in Social and Biological Networks[J].Proceedings of the National Academy of Sciences,2002,99(12):7821-7826.
[30]Newman M E J.a Fast Lgorithm for Detecting Community Structure in Networks[J].Phys Rev E,2004,69(6):066133.
[31]Otte E.,Rousseau R..Social Network Analysis:A Powerful Strategy,also for the Information Sciences[J].Journal of Information Science,2002,28(6):441-453.
[32]Adedo F.J.,Barroso C.,Casanueva C.,et al..Co-authorship in Management and Organizational Studies:An Empirical and Network Analysis[J].Journal of Management Studies,2006,43(5):957-983.
[33]Kretshmer,H..Author Productivity and Geodesic Distance in Bibliographic Co-authorship Networks,and Visibility on the Web[J].Scientometrics,2004,60(3):409-420.
[34]Hou,H.Y.,Kretshmer H.,Liu Z.Y..The Structure of Scientific Collaboration Networks in Scientometrics[J].Scientometrics,2008,75(2):189-202.
[35]White H.D.,Wellman,B.,Nazer,N..Does Citation Reflect Social Structure?[J].Journal of the American Society for Information Science and Technology,2004,55(2):111-126.
[36]Borgman,C.L..Scholarly Communication and Bibliometrics[M].Newbury Park:SAGE Publications,1990.
[37]Ahlgren,P.,Jarneving,B.,Rousseau,R..Requirements for a Cocitation Similarity Measure,with Special Reference to Pearson's Correlation Coefficient[J].Journal of the American Society for Information Science and Technology,2003,54(6):550-560.
[38]McCain,K.W..Mapping Authors in Intellectual Space:A Technical Overview[J].Journal of the American Society for Information Science,1990,41(6):435.
[39]Bayer,A.E.,Smart,J.C.,McLaughlin G.W..Mapping Intellectual Structure of a Scientific Subfield Through Author Cocitations[J].Journal of the American Society for Information Science,1990,41(6):444-452.
[40]White,H.D..Author Cocitation Analysis and Pearson's[J].Journal of the American Society for Information Science and Technology,2003,54(13):1250-1259.
[41]Leydesdorff,L.,Vaughan,L..Co-occurrence Matrices and Their Applications in Information Science:Extending ACA to the Web Environment[J].Journal of the American Society for Information Science and Technology,2006,57(12):1616-1628.
[42]Waltman,L.,Van Eck N.J..Some Comments on the Question Whether Co-occurrence Data Should be Normalized[J].Journal of the American Society for Information Science and Technology,2007,58(11):1701-1703.
[43]Leydesdorff,L..Should Co-occurrence Data be Normalized?A Rejoinder[J].Journal of the American Society for Information Science and Technology,2008,58(14):2411-2413.
[44]Leydesdorff,L..On the Normalization and Visualization of AuthorCo-Citation Data:Salton's Cosine versus the Jaccard Index[J].Journal of the American Society for Information Science and Technology,2008,59(1):77-85.
[45]Van Eck N.J.,Waltman L..Appropriate Similarity Measures for Author Co-citation Ananlysis.
[46]Chen C.,Paul R.J.,Keefe B.O..Fitting the Jigsaw of Citation:Information Visualization in Domain Analysis[J].Journal of the American Society for Information Science and Technology,2001,52(4):315-330.
[47]White H.D..Pathfinder Networks and Author Cocitation Analysis:A Remapping of Paradigmatic Information Scientists[J].Journal of the American Society for Information Science and Technology,2003,54(5):423-434.
[48]Zhao D..Information Science During the First Decade of the Web:An Enriched Author Cocitation Anlysis[J].Journal of the American Society for Information Science and Technology,2008,59(6):916-937.
[49]Ma,R.M.,Ni,C.Q.,Dai,Q.B.,et al..An Author Co-citation Analysis of Information Science in China with Chinese Google Scholar Search Engine[J].Scientometrics,Forthcoming.
[50]Zhao,D.,Strotmann,A..Evolution of Research Activities and Intellectual Influences in Information Science 1996-2005:Introducing Author Bibliographic-Coupling Analysis[J].Journal of the American Society for Information Science and Technology,2008,59(13):2070-2086.
[51]Glanzel,W.,Czerwon,H.J..A New Methodological Approach to Bibliographic Coupling and its Application to Research-front and Other Core Documents[J].Scientometrics,1996,37(2):196.
[52]Morris S.A.,Yen G.,Wu Z.,et al..Time Line Visualization of Research Fronts[J].Journal of the American Society for Information Science and Technology,2003,54(5):413-422.
[53]Jarneving,B..Bibliographic Coupling and Its Application to Research-front and Other Core Documents[J].Journal of Informetrics,2007(1):287-307.
[54]Zuccala,A..Modelng the Invisible College[J].Journal of the American Society for Information Science and Technology,2006,57(2):152-168.
[55]Schneider,J.W.,Borlund,P..Matrix Comparison,Part 2:Measuring the Resemblance Between Proximity Measures or Ordination Results by Use of the Mantel and Procrustes Statistics[J].Journal of the American Society for Information Science and Technology,2007,58(11):1596-1609.
[56]汪冰.我国自然科学期刊论文合著现象研究[J].情报学刊,1990,11(5):335-339.
[57]刘蓓,袁毅,Eric B.社会网络分析法在论文合作网中的应用研究[J].情报学报,2008,27(3):407-417.
[58]刘俊婉,梁立明.师生合作发表科技论文时间分布的研究与思考[J].情报学报,2005,24(2):169-180.
[59]张秀梅,吴巍.科研合作网络的可视化及其在文献检索服务中的应用[J].情报学报,2006,25(1):9-15.
[60]刘蓓,袁毅,Eric B.社会网络分析法在论文合作网中的应用研究[J].情报学报,2008,27(3):407-417.
[61]吴斌,杜楠,裴欣等.基于科技文献的科研组织网络分析方法研究[J].情报学报,2008,27(4):591-595.
[62]刘林青.范式可视化与共被引分析:以战略管理研究领域为例[J].情报学报,2005,24(1):20-25.
[63]马费成,宋恩梅.我国情报学研究分析:以ACA为方法[J].情报学报,2006,25(3):259-268.
[64]朱学芳,周挽澜,常艳丽.中文作者共被引分析系统可视化实现研究[J].情报学报,2008,27(4):572-577.
[65]邱均平,马瑞敏,李晔君.关于共被引分析方法的再认识和再思考[J].情报学报,2008,27(1):69-74.
[66]邱均平,马瑞敏.网络环境下ACA方法研究[J].图书情报工作,2008(2):85-87.
[67]刘军.QAP:测量“关系”之间关系的一种方法.社会,2007,27(4):164-174,209.
【作者简介】

邱均平,男,1947年出生,湖南涟源市人。1969年毕业于武汉大学化学系,1978年考入武汉大学科技情报专业学习,1981年毕业留校任教至今。1998年作为高级研究学者应邀访问了美国科学情报研究所(ISI)等14个著名图书情报机构。2000年应邀赴美国西东大学访问、研究,被吸收为“美国信息科学与技术学会”(ASIST)理事。现任武汉大学信息管理学院教授、博士生导师,中国科学评价研究中心主任,《图书情报知识》杂志副主编;兼任中国管理科学研究院、浙江大学等多个单位的研究员、教授或博导,中国索引学会副理事长,中国科学学与科技政策研究会常务理事兼科学计量学委员会副主任,中国科技情报学会常务理事,中国社科信息学会理事,中国竞争情报研究会常务理事,中国图书馆学会编译出版委员会委员,期刊委员会副主任,中国社会科学研究评价中心(南京大学)指导委员会委员以及《情报学报》、《情报科学》等15种杂志编委,并被评为湖北省有突出贡献的中青年专家,享受国务院政府特殊津贴。主持或参加了24个项目的研究工作,其中国家级16项,出版著作15部,在《中国软科学》、《情报学报》、《中国图书馆学报》等重要期刊发表论文260多篇,其中40余篇获奖或被人大报刊复印资料全文转载,获35项学术奖励。主持了多届科研评价与大学评价国际研讨会,其显著学术成就被载入《世界名人录》等21部大型权威辞书,在国内外学术界产生了广泛影响,被誉为“我国文献计量学和科学计量学的主要奠基人”。
马瑞敏,山西大学管理学院讲师。
【注释】
[1]本文系国家自然科学基金“基于作者学术关系的知识交流模式与规律研究(批准号:70973093)”成果之一。
[2]完全意义的知识传递者是不存在的,任何学者的成果都是在前人研究的基础上形成的。
[3]这两个名称是我们自己定义的,特此说明。
[4]拓扑结构一般是指一个网络的物理结构,即网络中各个站点相互连接的形式,是最为直观的一种表现网络节点关系的图形。社会结构在社会学中的定义是指一个群体或者一个社会中的各要素相互关联的方式。
[5]实际上,早在1968年就有学者提出了类似的概念,只不过没有得到足够的重视。
[6]点的中心度还有点度中心度(相当于度数),接近中心度等,这里主要介绍中间中心度。
[7]距离是指两点之间的测地线的长度。
[8]成为结构洞可能性的测度为总约束系数(Aggregate Constraint Index)。
[9]测地线是两点之间的长度最短的途径。途径是指没有重复点和线的线路。
[10]这里的加权度数是指引用强度之和,比如A作者被B作者引用了3次,被C作者引用了5次,那么A作者的加权度数为3+5=8。而如果不是加权度数,则只有2。
[11]可参考下列论文:Egghe L.Theory and practise of the g-index[J].Scientometrics,2006,69(1):131-152;Jin B.H.,Liang L.,Rousseau R,Egghe L.the R-and AR-indices:Complementing the h-index[J].Chinese Science Bulletin,2007,52(6):855-863。
[12]我们曾就h指数进行了相关研究,并就h指数的优劣性和C Baldock博士进行了辩论,详见Baldock C.Ruimin Ma,Orton C.G.The h-index is the best measure of a scientist's research productivity[J].Medical Physics,2009,36(4):1043-1045。
[13]对于这方面的研究,科学计量学界有着丰硕成果,发表了许多论文,在此不再赘述,可参见W.Glanzel等学者的论文。
[14]Newman本人发表了多篇关于作者合作的文章,并且一些论文的被引次数在短短几年内达到了近1000次。在此不一一罗列,其代表作有Newman M.E.J.Coauthorship networks and patterns of scientific collaboration.Proceedings of the National Academy of Sciences,2004,98,suppl.1:5200-5205,以及2001年在《物理评论E》上发表的关于《科学合作网络(Ⅰ和Ⅱ)》等。
[15]在他们的文章中,引用了齐普夫定律,并且Newman曾经对Rousseau的论文进行过评议,详见Rousseau B.,Rousseau R.LOTKA:A program to fit a power law distribution to observed frequency data[J/OL][2009-05-03].Cybermetrics,2003,4:1-6。
[16]具体数学含义和推理可参见他们的文章,或者参见相关的统计参考书籍,在此不进行详细介绍。另外,现在很多统计工具可以对Zeta进行计算。
[17]虽然White称为互引,但是实质上是引用,因为并不是每对作者都相互引用,有一些作者是单方面引用,甚至有的作者之间没有任何关系。
[18]热门论文是指某领域前两年的发文在最近两个月的被引次数排在前0.1%,条件非常严格,往往是时效性和创新性非常强的论文。
[19]高被引论文是指按照年代和领域划分,并且论文的被引次数迄今为止排序前1%的论文。
[20]Leydesdorff在很多论文中都使用Pajek进行了作者、期刊等之间关系的可视化,他著作颇丰,可参见其个人网站的文章列表:http://users.fmg.uva.nl/lleydesdorff/list.htm。
[21]Chen是华人,在领域可视化方面取得了卓越成绩。相关研究可参见其著作:Chen C.Mapping scientific frontiers:The quest for knowledge visualization[M].London:Springer,2003。
[22]Mantle test和QAP有着很大的相似性,但是要优于QAP,是QAP的改进。
[23]详见该杂志2008年第6期1~43页。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










