



22.3 句法分析(Parsing)
我们已经将句法分析定义为一个为给定的输入字符串找到句法分析树的过程。也就是说,是一个调用句法分析函数PARSE的过程,比如:
PARSE( “the wumpus is dead”, E0, S)
应该返回一棵句法分析树,该树以S为根节点,“the wumpus is dead”为叶节点,内部节点是来自E0语法的非终结符。你可以在图22.1中看到这样的一棵句法分析树。在线性表示的文本中,我们将该树写为:
[S:[NP:[Article:the][Noun:wumpus]]
[VP:[Verb:is][Adjective:dead]]]
句法分析可以被看作搜索句法分析树的过程。这里有两种指定搜索空间的极端方法(二者之间有很多变种)。其一,我们可以从符号S开始,搜索一棵以词语为其叶节点的树。这被称为自顶向下的句法分析(因为S处于树的顶端)。其二,我们从词语开始,寻找一棵以S作为根节点的树。这被称为自底向上的句法分析[2]。自顶向下的句法分析可以被精确地定义为一个搜索问题,如下所示:
• 初始状态是一棵句法分析树,由根节点S和未知子节点[S: ?]组成。一般来说,搜索空间中的每个状态都是一棵句法分析树。
• 后继函数选择树中具有未知子节点的最靠左的节点。然后在语法中寻找该节点的根标记出现在规则左侧的那些规则。对每条符合要求的规则,该函数都在“?”的位置上产生后继状态,其中“?”被一个对应于规则右件的列表所代替。例如,在E0中对S有两条规则,所以树[S: ?]会被如下的两个后继所代替:
[S: [S: ?][Conjunction: ?][S: ?]]
[S: [NP: ?][VP: ?]]
其中第二个将会有7个后继,每条NP的重写规则产生一个。
• 目标测试检验句法分析树的叶节点完全符合输入的字符串,而且没有未知的和未遇到的输入。处理所谓的左递归规则——也就是,形如 X → X … 的规则——是自顶向下的句法分析的一个大问题。如果采用深度优先搜索,这样的规则会使我们在一个无限循环中不停地以[X: X …]代替X。而如果采用广度优先搜索,我们能够成功地为合法的语句找到句法分析结果,但是当给定的是非法语句时,我们将在一个无限的搜索空间中陷入进退维谷的境地。
作为搜索过程的自底向上句法分析的形式化表示如下所示:
• 初始状态是输入字符串中所有词语的列表,每个词语被看作是一棵仅有唯一叶节点的句法分析树——例如:[the, wumpus, is, dead]。一般说来,搜索空间的每个状态都是一个句法分析树的列表。
• 后继函数考虑树列表中的每个位置i,以及语法中每个规则右件。如果树列表中起始于位置i的子序列与规则右件相匹配,那么这个子序列将被一棵新的树代替,这棵树的范畴是规则的左件,它的子节点则是该子序列。我们用“匹配”表示节点的范畴与规则右件中的元素相同。
例如,规则Article→the与由列表[the,wumpus,is,dead]中第一个节点组成的子序列是相匹配的,所以一个后继状态为[[Article:the],wumpus,is,dead]。
• 目标测试检查某个状态是否包含一棵以S为根节点的树。
参见图22.5,一个自底向上句法分析的例子。

图22.5 应用于字符串“The wumpus is dead”的自底向上句法分析过程。我们以一个由词语组成的结点列表作为开始。然后我们以新节点替换能够与规则的右件相匹配的子序列,其中新节点的根节点是规则的左件。例如,在第三行中,Article和Noun节点被一个以这两个节点为子节点的NP节点所替换。自顶向下句法分析则产生一个相似的过程,但是方向相反
由于对不同短语的多种句法分析可以进行组合的方式的多样性,自顶向下和自底向上的句法分析效率可能都比较低。二者都将对搜索空间中不相关的部分进行搜索而浪费时间,并且自底向上的句法分析还可能生成不会出现在语句S中的词语的不完全句法分析。
即使我们已经拥有一个启发式函数,允许我们进行搜索而不会有任何不相关的偏离,这些算法仍然可能是效率不高的,因为某些语名具有指数量级那么多的句法分析树。下一小节将说明关于此种情况可以做什么。
高效的句法分析
考虑如下的两个语句:
Have the students in section 2 of Computer Science 101 take the exam.
Have the students in section 2 of Computer Science 101 taken the exam?
尽管它们的前10个词语是相同的,但是这两个语句却有截然不同的句法分析结果,这是因为第一个语句是一个命令句,而第二个是一个问句。从左至右的句法分析算法将不得不猜测第一个词语是否为某个命令句或是问句的组成部分,并且至少要分析到第11个词语的时候——即take或者taken——才能知道这个猜测结果是否正确。当算法猜测错误时,它必须一直回溯到第一个词语。这种回溯是不可避免的,但是如果要想使我们的句法分析算法效率足够高,那么它必须避免在每次回溯后都将“the students in section 2 of Computer Science 101”重新分析为一个NP。
在本节中,我们将发展一种能够避免这类低效率的来源的句法分析算法。基本思想是动态规划的一个实例:我们每次分析一个子串,并保存结果,这样我们以后不必再重新分析该子串。例如,我们一旦发现“the students in section 2 of Computer Science 101”是一个NP,那么我们将这个结果记录在一个被称为图的数据结构中。完成这项工作的算法被称为图句法分析器。由于我们处理的是上下文无关语法,因此在搜索空间某个分支的上下文中发现的任何短语在状态空间的其它分支中一样可用。
有n个词语的语句的图由n+1个顶点和多条连接这些顶点的边组成。图22.6显示了一个有6个顶点(圆圈)和3条边(直线)的图。例如,以
[0, 5, S → NP VP •]
标记的边表示一个NP后面跟一个VP可以组合成一个S,从节点0到5横跨该字符串。每条边中的符号 • 把迄今为止已经找到的与尚待寻找的分隔开[3]。结尾处出现 • 的边被称为完全边。边
[0, 2, S→NP • VP]
则表示一个 NP 能够从节点 0到2(最初两个词语)横跨该字符串,而且如果我们能够在它的后面找到一个紧接着的 VP,那么我们就能得到一个 S。像这类在结尾之前包含 • 的边被称为不完全边,我们称这样的边是在寻找一个VP。

图22.6 语句“The agent feels a breeze”的部分图。该图显示了全部6个顶点,但是仅画出了能够组成完整句法分析的所有边中的3条
图22.7显示了一个图句法分析算法。其主要思想是将最好的自顶向下和自底向上的句法分析结合起来。其中 PREDICTOR(预测函数)过程是自顶向下的:该过程将各条目放入图中,说明何种符号期望出现于哪个位置。SCANNER(扫描函数)是一个自底向上的过程,该过程从词语开始,但是它仅用一个词语来扩展一个已有的图条目。类似的,EXTENDER(扩展函数)自底向上地建造成份,不过仅扩展一个已有的图条目。

图22.7 图句法分析算法。S是开始符,S'是一个新的非终结符。chart[j]是到顶点j的所有边的列表。希腊字母匹配包含零个或多个符号的字符串
我们用一个技巧启动整个算法:我们把边[0, 0, S ' → • S]加入图中,其中S是语法的起始符,S ' 是我们创造的一个新符号。对ADD-EDGE的调用使得PREDICTOR为能产生S的规则——即[S→NP VP] ——添加一条新边。然后,我们考虑该规则中的第一个成份——NP,并为每种可能产生NP的方式添加规则。最终,预测函数以自顶向下的方式将所有可能的边添加到图中,这些边可以为创建最后的S发挥作用。
当对S'的预测完成的时候,我们进入到一个被称为SCANNER的循环中,处理语句中的每个词语。如果位置j上的词语属于某条边正在j处寻找的B范畴,那么我们将扩展这条边,将当前位置上的词语标注为B范畴的一个实例。注意每次对SCANNER的调用都会以对PREDICTOR和EXTENDER的递归调用而告终,因此自顶向下和自底向上的过程是交叉进行的。
另外一个自底向上的组件是EXTENDER[4],它挑选一条左件为B的完全边来扩展图中任何以完全边的起始为终点的不完全规则,如果该不完全规则正在寻找B的话。

图22.8“0I1feel2 it3”的句法分析图。符号m:S的含义为边m的左件是S,而符号f:VP/Verb的含义为边f的左件是VP,但是在寻找Verb。顶点上方是5条完全边,下方是8条不完全边

图22.9 “0I1feel2it3”的句法分析过程。对a~m中的每条边,我们展示了从图中已有的边推导当前边的过程。另外为了简便,我们省略了一些边
图22.8和图22.9显示了一个图,以及算法对语句“I feel it”(是对问句“Do you feel a breeze?” 的回答)进行句法分析的过程。在图中一共记录了13条边(标记为a到m),其中包括5条完全边(处于顶点上方)以及8条不完全边(处于顶点下方)。注意预测函数、扫描函数以及扩展函数的行动循环。例如,预测函数利用边(a)在寻找S的事实,许可预测一个NP(边b),然后是一个Pronoun(边c)。接着扫描函数发现在合适的位置(边d)存在一个Pronoun,扩展函数则将不完全边b和完全边d合并产生一条新的边e。
图句法分析算法避免了建立一大类边,这些边本来需要用单个自底向上过程进行检查。考虑语句“The ride the horse gave was wild”。自底向上的句法分析会把“ride the horse”标记为NP,然后当发现在其不适合更大的S时,它将丢弃这棵句法分析树。不过E0不允许“the”的后面紧跟一个VP,所以图句法分析算法绝不会在那个点预测出VP,并因此将避免在那里浪费时间去建立VP成份。这些从左至右运行、能够避免建立不可能出现的成份的算法被称为左角句法分析器,因为它们建立了一棵以语法起始符开始的、始终对语句中最左边的词语(即左角)进行扩展的句法分析树。只有当某条边能够对扩展句法分析树起作用时,该边才被添加到图中。(参见图22.10中的例子。)
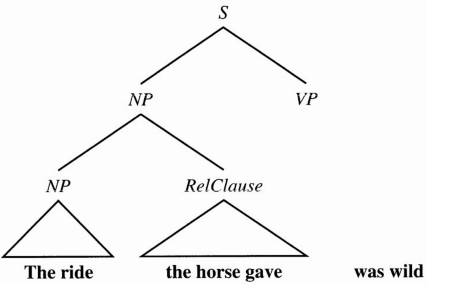
图22.10 左角句法分析算法避免了预测一个以“ride”开始的VP,但是却预测VP能够以“was”开始,因为该语法期望NP后面可以接一个VP。在“the horse gave”上方的三角形意味着这些词语有一个句法分析结果是RelClause,不过还有其它一些未显示出来的附加中间成份
图句法分析器仅仅使用多项式的时间和空间。它需要O(kn2)大小的空间存储所有的边,其中n是语句中词语的数量,k是一个依赖于语法的常数。当该分析器不能再构造新的边的时候,它就会停止,由此我们可以知道算法终止了(即使当存在左递归规则的时候)。事实上,该分析器在最坏的情况下需要O(n3)的时间,这对于上下文无关语法是能达到的最好结果。EXTENDER是CHART-PARSE(图句法分析)的瓶颈,对位置j的n+1个不同值中的每一个,它都必须尝试通过开始于j的O(n)条完全边中的每一条来扩展所有的以j结束的O(n)条不完全边。把上面的值乘在一起,我们得到O(n3)。这个结果给了我们某种矛盾的东西:复杂度是O(n3)的算法是如何能够返回一个也许包含指数级个数句法分析树的答案的?考虑一个例子:语句
“Fall leaves fall and spring leaves spring”
是有歧义的,因为语句中的每个词语(除了“and”)都可以既作名词又作动词,而“fall”和“spring”还可以作形容词。总而言之,这句话共有4种句法分析结果[5]:
[S:[S:[NP:Fall leaves]fall]and[S:[NP:spring leaves]spring]
[S:[S:[NP:Fall leaves]fall]and[S:spring[VP:leaves spring]]
[S:[S:Fall[VP:leaves fall]]and[S:[NP:spring leaves]spring]
[S:[S:Fall[VP:leaves fall]]and[S:spring[VP:leaves spring]]
如果我们有n 个有歧义的能够合并的子句,那么我们将会有2n种方式来选择子句的句法分析结果[6]。图分析器如何避免指数级的处理时间?这里实际上有两种答案。首先,CHART-PARSE 算法自身实际上是一个识别器,而不是句法分析器。如果在图中存在形如[0,n,S → α •]的完全边,那么我们识别出一个S。从这条边复原句法分析树被认为不是CHART-PARSE的部分任务,不过仍可以进行。注意,在EXTENDER的最后一行,我们建立了α 作为eB边的列表,而不仅仅是范畴名的列表。所以要将每条边转换成一棵句法分析树,只要递归地考虑组成的边,把每条形如[I,j,X → α •]的边转换为一棵形如[X:α]的树。这很直接,不过它只能够为我们提供一棵句法分析树。
第二个答案是如果你需要所有可能的句法分析结果,你将不得不更深入地对图进行挖掘。当我们将边[I,j,X → α •]转换成树[X:α]的同时,也会注意是否存在任何其它形如[I,j,X → β •]的边。如果存在,那么这些边将会产生另外一些句法分析结果。现在,对它们如何进行操作,我们有一个选择。我们可以枚举出所有的可能结果,这意味着上文中所提到的矛盾将会被解决,同时我们需要指数量级的时间来列出句法分析结果。或者我们可以把保持神秘的时间稍微延长一点,并用一种被称为密集森林的结构来表示分析结果,它看起来就像下面这样:

这种做法的思想是每个节点既可以是一个正规的句法分析树节点,也可以是树的节点集。这使得我们能够在多项式量级的时间和空间内返回一个指数级的句法分析结果的表示。当然,当n = 2的时候,2n和2n没有很大区别,但是对于n很大的情况,这样的表示方法提供了可观的节约。但是不幸的是,这种简单的密集森林方法不能处理所有在如何连接中出现的O(n!)量级的歧义性。Maxwell和Kaplan(1995)说明了一个基于真值维持系统的原理的更为复杂的表达方法是如何能够把树压缩得更紧密的。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










