



17.2.3 价值迭代的收敛
前面我们提到价值迭代最终会收敛在贝尔曼方程组的唯一解上。在这一节中,我们解释为什么会发生这种情况。我们会引入一些有用的数学思想,并得到一些方法,用来在提前终止算法时评估所返回的效用函数误差;这是很有用的,因为它意味着我们不需要永久地运行算法。本节内容相当有技术性。
在证明价值迭代法的收敛时用到的基本概念是收缩(contraction)。粗略地说,收缩就是指一个单参数的函数,当依次用于两个不同的输入时,产生的两个输出值相对于原始参数“彼此更接近”,接近的程度至少是某个常数的量级。例如“除以2”函数是收缩的,因为在把两个数都除以2以后,它们的差值也缩小了一半。注意“除以2”函数有一个不动点,也就是0,它的值是不因函数的应用而改变的。从这个例子,我们可以认识到收缩函数的两个重要属性:
• 一个收缩函数只有一个不动点;如果有两个不动点,对它们应用这个函数就不会得到更近的值了,因而不是收缩。
• 当把函数应用于任意参数时,值一定更接近于不动点(因为不动点不会移动),于是反复使用收缩函数总是以不动点为极限。
现在,设想我们把贝尔曼更新(公式(17.6))视为一个算子B,用于同时更新每个状态的效用值。令Ui表示在第i次迭代时所有状态的效用向量。那么贝尔曼更新公式可以写成
Ui+1=B Ui
下一步,我们需要一种度量效用向量之间的距离的方法。我们使用最大值范数(max norm),用向量的最大分量的长度来衡量量的长度。
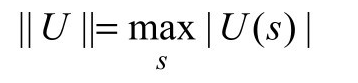
使用这个定义,两个向量间的“距离”||U − U '||是任意两个对应元素之间的最大差值。本节的主要结果就是:令Ui和Ui'为任意两个效用向量,那么

也就是说,贝尔曼更新是在效用向量空间中因子为γ的一个收缩。因此,价值迭代法总是收敛到贝尔曼方程组的唯一解上。
实际上,我们可以用真实效用值U来替换公式(17.7)中的Ui',满足BU=U。那么我们得到不等式
||BUi–U||≤ γ||Ui–U||
如果我们把||Ui− U||视为估计值Ui的误差,那么每一次迭代该误差就以因子γ 减小。这意味着价值迭代的收敛速度是指数级的。我们可以计算出到达某个特定误差界限ε 所需要的迭代次数,方法如下:首先,根据公式(17.1)知道所有状态的效用值有界限±Rmax/ (1–γ )。这意味着最大的初始误差||U0–U||≤ 2Rmax/ (1–γ )。假设我们运行N次迭代达到的误差不超过ε 。那么因为误差每一次至少减少γ倍,我们要求γN⋅2 Rmax/(1–γ)≤ ε。两边取对数,发现
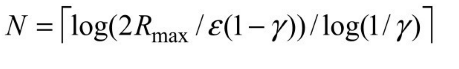
图17.5(b)显示了对于不同的比例ε /Rmax迭代次数N随着γ 如何变化。好消息是由于收敛速度是指数级的,N对于比例ε /Rmax的依赖不大。坏消息是当γ 接近于1时,N增长得很快。我们通过减小γ 来加速收敛,不过这样使得智能体只有短期视野,可能会错过智能体行动的长期效果。
上面一段中的误差界限给了我们关于某些对算法运行时间有影响的因素的概念,不过用它作为决定何时停止迭代的方法有时候会过于保守。出于决定何时停止迭代的考虑,我们可以使用一个在给定迭代中把误差和贝尔曼更新的大小联系起来的界限。根据收缩性质(公式(17.7)),可以证明如果更新很小(即,没有状态的效用值发生很大变化),那么误差和真实效用函数相比也很小。更准确地说,

这就是图17.4中VALUE-ITERATION算法使用的终止条件。
迄今为止,我们已经分析了价值迭代算法返回的效用函数误差。然而,智能体真正关心的是如果在这种效用函数的基础上制定决策,可行性有多高。假设在价值叠代的第i次迭代以后,智能体对于真实效用值U的估计为Ui,并且基于通过Ui向前看一步的方法(如公式(17.4))得到MEU策略πi。是否这样导致的行为近似于和最优行为一样好呢?这对于任何真实智能体都是至关重要的问题,而看来答案是肯定的。如果从状态s开始执行πi,Uπ i(s)是得到的效用值,那么策略损失||Uπ i–U||是智能体用执行πi替代最优策略π*可能遭受的最大损失。πi的策略损失通过下面的不等式与Ui的误差联系起来:
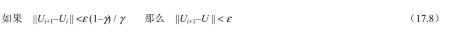
实际上,经常出现的情况是早在Ui收敛以前,πi就已经成为最优的了。图17.6显示出对于4 × 3环境且γ = 0.9时,随着迭代进程的进行,Ui的最大误差和策略损失是如何接近0的。当i = 4时,策略πi是最优的,尽管Ui的最大误差仍然有0.46。

图17.6 估计效用值的最大误差||Ui–U||和与最优策略相比较的策略损失||Uπ i–U||,显示为价值迭代法中的迭代次数的函数
现在我们已经有了实际应用价值迭代法所需要的全部技术。我们知道它会收敛到正确的效用值,并且如果我们在有限次数的迭代之后停止,可以把效用估计的误差限制在一定界限内,另外作为执行对应的 MEU 策略的结果,我们还可以限制决策损失。最后强调一点,本节中的所有结果都基于折扣因子γ<1的假设。如果γ =1并且环境包含终止状态,那么只要一定技术条件得到满足,可以得到类似的收敛结果和误差界限。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。









