



5.2.4 VisDLKC的算法选择
算法选择是VisDLKC的关键,主要包括由题录TXT文档生成符合索引文档XML Schema定义的实例文档、根据Lucene返回的Hits检索结果生成满足树形结构和网状结构XML Schema定义的实例文档、根据关系矩阵生成符合网状结构XML Schema定义的实例文档以及树形结构、网状结构的可视化展示算法等。
5.2.4.1 由题录TXT文档生成索引XML文档
题录功能保存下的文档格式为TXT文档,例如:
RT Journal
A1 王晰巍;靖继鹏;赵晋;
T1 知识构建对知识管理的优化研究
JF 情报科学
JO QBKX
YR 2007
IS 07
K1 知识构建;;知识获取;;知识表示;;知识存储;;知识共享
AB 本文在对知识管理的体系模型和应用中存在的问题进行分析的基础上,结合知识构建的特点及核心要素,提出了知识构建对知识管理体系中的知识获取、知识表示、知识存储和知识共享的优化思路。
SN 1007-7634
CN 22-1264/G2
DB CJFD
RT Journal
A1 刘玉照;李静;
T1 论ERP系统与企业知识管理
…
为了将题录TXT格式转换为索引XML文档格式,需要逐行读取题录TXT文档,然后提取需要的创建者、标题、来源、年期及摘要等信息,并将其写入XML文档。其中,读取TXT文档以“A1”作为标志识别一篇新文献的开始,然后根据引文格式提取相应信息,具体算法如下:
步骤1:创建根元素“documentset”;
步骤2:逐行读取题录TXT文档,判断当前行是否以“A1”开始;
步骤3:步骤2判断结果为True,从当前行获取当前文献的作者信息,依次读取后面的7行,获取当前文献的标题、来源期刊、发表时间、关键词及摘要等信息;
步骤4:根据步骤3获取的信息,创建一个元素“document”以及相应的子元素“title”“creator”“date”“source”“subject”“description”以及“fulltext”;
步骤5:判断当前行是否为空,判断结果为False转入步骤2,为True,创建写入流并生成相应的XML文档。
5.2.4.2 由检索结果Hits生成关键词网络XML
Lucene返回的检索结果Hits中包含了每篇文献的关键词,两个关键词同时作为一篇文献的关键词表明二者之间关联较强。关键词网络中的节点是返回结果中全部文献的所有关键词,两个节点之间是否存在连接取决于相应的两个关键词是否同时作为同一文献的关键词。从检索结果Hits中,可以计算得到以下字符串数组kwList={“知识管理;知识门户;企业信息门户”,“知识管理系统;智能代理;XML;UML”,“知识地图;工作流;知识管理;知识管理系统”,…},数组每个元素是一篇文献的关键词列表。由该字符串数组生成网状结构XML文档的算法如下:
步骤1:创建根元素“graph”,初始化关键词向量kwVector;
步骤2:依次读取kwList的每个元素,针对每个元素先以“;”标准切分为每篇文献的关键词组成的字符串数组docKw,针对docKw的每个元素判断是否已经出现在kwVector中,没有出现时将其添加到kwVector中并根据该关键词创建相应的“node”元素;
步骤3:判断kwVector[1]与kwVector[2]、kwVector[3]…kwVector[n]是否同时出现在同一文献中,如果出现生成相应的边元素“edge”,再判断kwVector[2]与kwVector[3]…kwVector[n]是否同时出现,直至判断kwVector[n-1]与kwVector[n]是否同时出现,n为关键词总数;
步骤4:创建写入流生成相应的XML文档。
5.2.4.3 由检索结果Hits生成关键词分布XML
关键词分布是为了揭示关键词在各个文献中的分布情况,即针对某一关键词,它都出现在哪些文献之中。从Lucene检索结果Hits中,可以计算得到以下字符串数组docList={“企业知识管理中的信息门户建设;知识管理;知识门户;企业信息门户”“当前知识管理系统模型问题与对策分析;知识管理系统;智能代理;XML;UML”“基于工作流的知识地图及其在企业知识管理中的应用;知识地图;工作流;知识管理;知识管理系统”,…},数组每个元素由每篇文献的标题和关键词列表组成。由该字符串数组生成树形结构XML文档的算法如下:
步骤1:初始化哈西映射HashMap实例kwHm,每个键值对分别保存一个关键词及含有该关键词的文献标题;
步骤2:遍历docList,针对每个元素docList[i]先以“;”为标识切分得到字符串数组str,依次判断str的每个元素str[j]是否出现在kwHm中,没有出现则以(str[j],str[0])为参数添加到kwHm中,已经出现则在str[j]键对应的字符串值后面添加“;”+str[0];
步骤3:创建根元素“tree”;
步骤4:遍历kwHm,针对每个键创建“branch”元素,根据每个值创建“leaf”元素;
步骤5:创建写入流生成相应的XML文档。
5.2.4.4 由关系矩阵挖掘关联矩阵并写入XML
根据词条之间的关联强度可以得到以下的关系矩阵:

其中,关系矩阵W的元素wij是词条i和词条j的关联强度,易知,W为对角线元素值为0的对称矩阵。而需要构建的概念图可用以下关联矩阵表示:
其中,关联矩阵C的元素cij揭示概念i和概念j之间的关系,若cij=1,表示概念i和概念j之间关系密切,它们之间应画一条连线;若cij=0,表示概念i和概念j之间关系不密切。而根据关联矩阵C可以直接生成相应的XML文档。
笔者根据内容比较接近的文献集合特点,发现它们揭示的概念之间关系紧密,而且常常自动呈现层次关系,采用直接选择最相关的一定元素作为子元素,而将关联强度大于平均值且未关联的概念对作为交叉关系,具体算法如下:
步骤1:根据W计算每个词条与其他词条的关联强度之和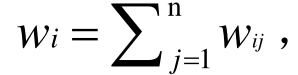 并根据iw值的大小重新生成关系矩阵W,将较大的值置于前面的列,即确保列元素之和依次递减;
并根据iw值的大小重新生成关系矩阵W,将较大的值置于前面的列,即确保列元素之和依次递减;
步骤2:将第一列元素作为根元素,并选择与其关联最强的k个元素作为其子元素,即从第一列元素中选择最大的k个值,并根据对应的行序号m,置c1,m=1;
步骤3:依次从每个子元素中选择与其关联最强的k个元素作为其子元素(若与其相关的少于k个,即关联强度大多为0,则仅选择大于0的),直至所有元素均被选成子元素;
步骤5:根据wij和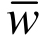 确定交叉关系,如果wij>且cij=0,则将cij置于1;
确定交叉关系,如果wij>且cij=0,则将cij置于1;
步骤6:根据矩阵C生成对应的网状结构XML文档。
5.2.4.5 利用力导向算法展示网状结构
概念图的展示采用力导向算法(Force Directed Algorithm)完成,力导向算法源于仿真物理力学,认为网状结构中的任意一个节点,都受有引力及斥力(Kamada和Kawai,1989)。引力主要是由每个与此节点有边相连接的邻居所提供的合力,其意义是为了让此节点与其邻居之间的距离不会太远;斥力则是由整个网状结构中除了本身以外的节点所提供,目的是为了让任意两节点不会因距离太近而产生重叠的现象,也因此整个网状结构不会太密集而影响视觉。通过对每个节点的计算,算出引力及斥力共同作用的合力,再由此合力来移动节点位置。整个算法维护一个能量值,此能量值可设为所有节点合力值的总和。每执行一个回合,根据节点新的位置计算出新的能量值。能量值愈小,表示整个网状结构配置愈趋于稳定。一般来说,能量值愈小,网状结构的配置显示会较清晰,因此当能量值到达最小值时,网状结构的状态就是理想结果。力导向算法的主要思想如下:
步骤1:初始化能量值Energy;
步骤2:针对每个节点v,计算引力Fa和斥力Fr,进而得到合力F;
步骤3:根据合力F更新v的位置,并计算新的能量值NewEnergy;
步骤4:比较Energy与NewEnergy的大小,后者较小,用后者更新前者;
步骤5:不断移动每个节点v,反复计算能量值Energy直至取得最小值。
5.2.4.6 利用Radial Graph展示网状结构
关键词网络的展示采用Radial Graph实现,该算法非常适合于动态交互要求高的情境。在Radial Graph中,算法以当前节点(一般是用户当前选中的节点)作为根节点,采用广度遍历算法,以当前节点为初始节点进行遍历,然后获取节点间的父子关系,生成一棵树,树中的节点对应图中的节点,树中的每个节点(根节点除外)都以它在图中的一个邻居作为父节点。各个节点被排列在以根节点为中心的多个圆环上,每个节点处于哪个圆环上取决于它在树中所处的深度;深度越深,则离根节点(当前节点)越远,越处于远离根的圆环上。Radial Graph以当前节点为中心,向外扩展的发散图可以划分为多个扇区(Sector),每个节点在圆环上所处的位置取决于该圆环分配给该节点的扇区。每个节点处于其父节点的扇区内,而扇区分开的角度与该节点的子树的角宽度(Angular Width)成比例。其中,所有的节点具有相同的大小,节点的角宽度的大小取决于该节点子树的后代中叶子节点的数目(Wills,1997)。
5.2.4.7 利用Treemap算法展示树形结构
关键词分布图的展示采用Treemap算法实现,该算法能够在有限的屏幕空间上展示复杂的树形结构并能直观揭示节点信息(Shneiderman,1992)。Treemap通过对屏幕空间的多次划分来实现,每一次划分表示树形结构的一个层次,每次划分产生的矩形区域数量由相应层次的节点数量决定,每个矩形区域的面积由该节点隐喻的某一特征值决定(例如,所有子节点数量)。另外,还可以为不同的矩形区域涂上不同的颜色来隐喻一定的数量特征。Treemap算法的主要思想如下:
步骤1:初始化矩形区面积隐喻的数量特征t;
步骤2:获取树形结构的第1层所有节点,计算该层所有节点的数量特征之和T,根据每个节点t与T的比值对整个矩形屏幕进行横向分隔;
步骤3:获取第1层节点中的第1个节点v11的所有第2层节点,同样根据数量特征关系对v11所对应的矩形区域进行纵向分隔;
步骤4:依次对第1层其他节点所对应的矩形区域进行纵向分隔;
步骤5:接着,针对所有第2层节点所对应的矩形区域进行横向分隔,不断进行交替的横向、纵向分隔,直至划分后对应的矩形区域代表叶子节点为止。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。









