



6.2.3 算法优选和阈值的确定
等级聚类算法简单易行,但至今无法确定三种算法中哪个最为优秀,对于不同的测试数据,三者表现出的性能是不确定的。所以,只能通过测试来判定采用哪种算法更适合处理财税词汇。以下试验目的在于通过测试,比较三种等级聚类算法的聚类效果,同时确定阈值以控制聚类结束条件。
(1)测试数据
选取税务公文主题词表(自2004年11月1日起执行)中财税相关概念和术语进行测试,原因是:①税务公文主题词表收集了税务领域的主要词汇,基本概括了财税领域知识,具有一定代表性;②税务公文主题词表把所有主题词归为税法、纳税人、各种税种、征收管理、行政管理、经济综合、一般综合等类,便于分析和比较聚类效果;③词量适中,便于测试。因行政管理、经济综合、一般综合类的词多为通用词汇,为避免干扰,测试时剔除这些词,同时删除在文本库中词频小于10的词,实际参加测试的词汇为300个。
(2)阈值的确定
聚类过程中,阈值D的取值非常关键,它决定了两个簇是否足够相似并进一步聚为新簇,当所有簇之间的最小距离大于D时,聚类过程停止,所以阈值最终决定聚类过程在何时停止才能得到最好的聚类效果。通常有四种方法设置阈值:①停止在预先设定的一个相似度值上,当聚类过程中两个簇的距离大于该值时,程序停止;②停止在相邻簇相似度值差别很大的点上;③设置一个函数,计算聚类的性能;④预先设定需要簇的数目。阈值的设定直接影响最终聚类结果的优劣,实际上是对给定的数据强加某种结构,也就是说,聚类划分的结果可能不是实际存在的某个结构,而是硬性划分所得。为了减轻这种影响,同时避免方法②和③中繁琐的计算,本文采用第一种做法控制聚类结束条件,并通过评价试验结果中聚类效果的优劣来选择恰当的阈值。
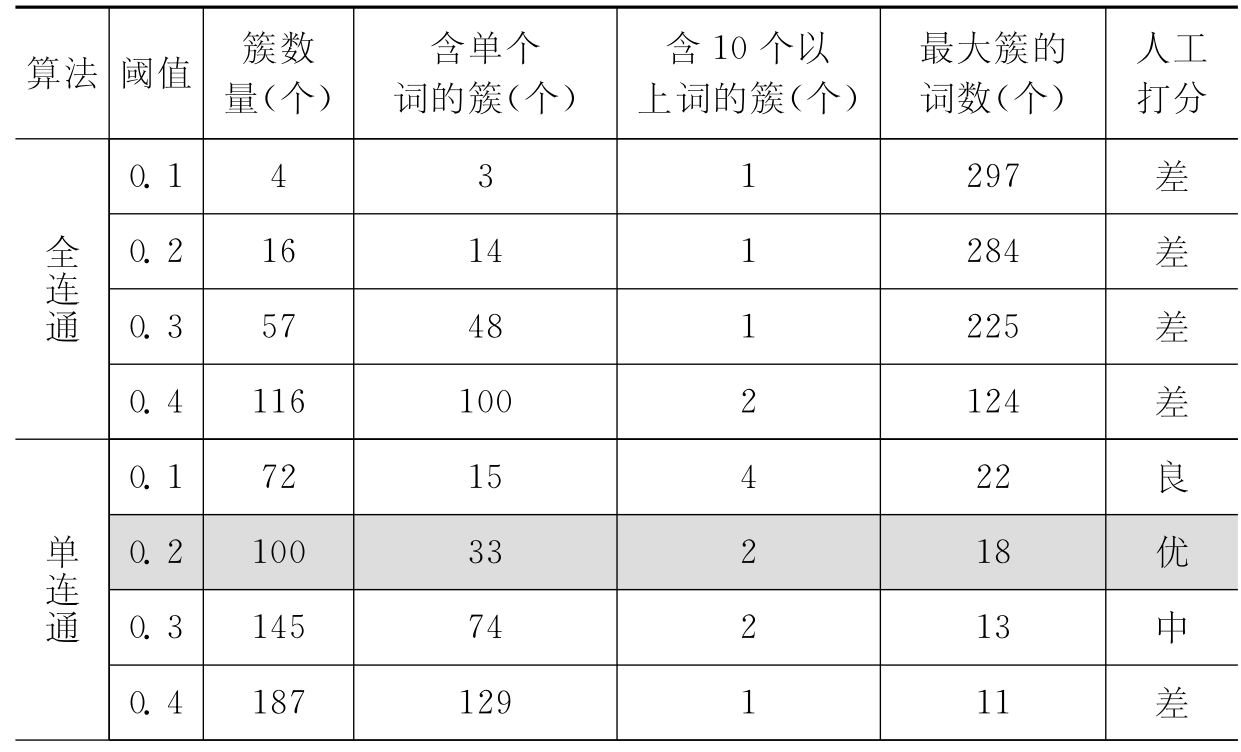
好的聚类效果指得到较为紧凑的簇,簇内各词汇之间的相似性很大,而不同簇包含的词汇之间相似性很小。对于叙词表来说,词簇的分布一般较为均匀,且包含词汇数量较多的大词簇的数量一般很少,所以,好的聚类效果亦代表能得到分布较为均匀的簇。可以从多种途径评价聚类效果,如聚成簇的数量、簇的大小、聚成簇的内部样本之间相似程度等。本文采取的测评方法是:对测试数据分别采取三种等级聚类算法,根据设置的四个阈值等级分别进行测试,从聚类结果的外部特征即簇数量、含单个词的簇个数、含10个以上词的簇数量、最大簇含词数四个方面考察聚类效果。另外人工比较各算法在不同阈值下的聚类结果与税务公文主题词表的类目分布相符情况,并考察生成的簇的优良程度两个因素,按“优”、“良”、“中”、“差”四个等级打分。试验结果统计如表6-9所示:
表6-9 聚类测试结果表
(续表)
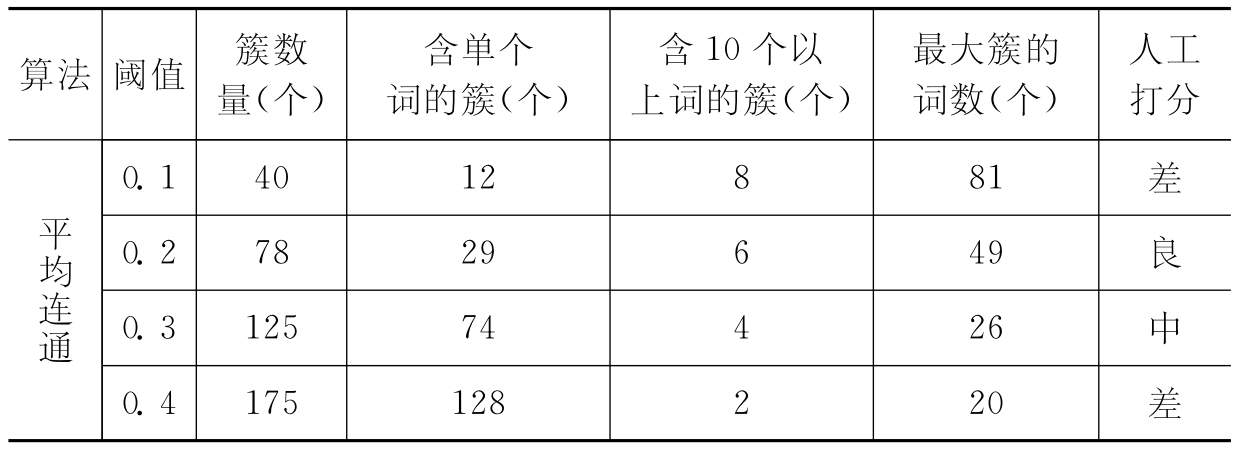
分析以上测试结果,三种等级聚类算法在阈值从0.1到0.4增长时,得到的簇的数量随之增加,含单个词汇的簇的数量也在增加。一般认为含词汇量大于10个的簇为体积较大的簇,全连通算法聚类结果的特点是:产生簇的数量很少,但簇的体积很大(含词汇量超过100个)。簇内含词量越多,簇内词汇越松散,说明该算法很难区分词汇之间的区别,簇的紧凑度难以保障。所以全连通算法聚类结果中词汇集合的分布极不均衡,不宜采用。
单连通和平均连通算法在聚类效果上均优于全连通算法。单连通算法在阈值为0.1和0.2时,平均连通算法在阈值为0.2时的聚类结果中,簇的分布较为均匀,且体积大的簇很少,基本符合自动构建叙词表的要求。经过人工审查单连通算法在阈值等于0.2时的聚类结果时,发现生成的簇内词汇之间的相似性很高,数据比较紧凑,对照税务公文主题词表的类目结构,该算法聚类结果中词汇集合的分布较为合理,相对其他算法,总体效果最优。所以,通过试验最终确定采用单连通算法对内核部分所有词汇进行聚类分析。
(3)内核主题词聚类结果分析
根据以上结论,采用单连通聚类算法,阈值设置为0.2,对内核部分1 272条词汇进行聚类分析,结果得到416个簇。簇的数量按其含词汇量的多少分布情况如表6-10、图6-7所示:
表6-10 聚类结果分析表
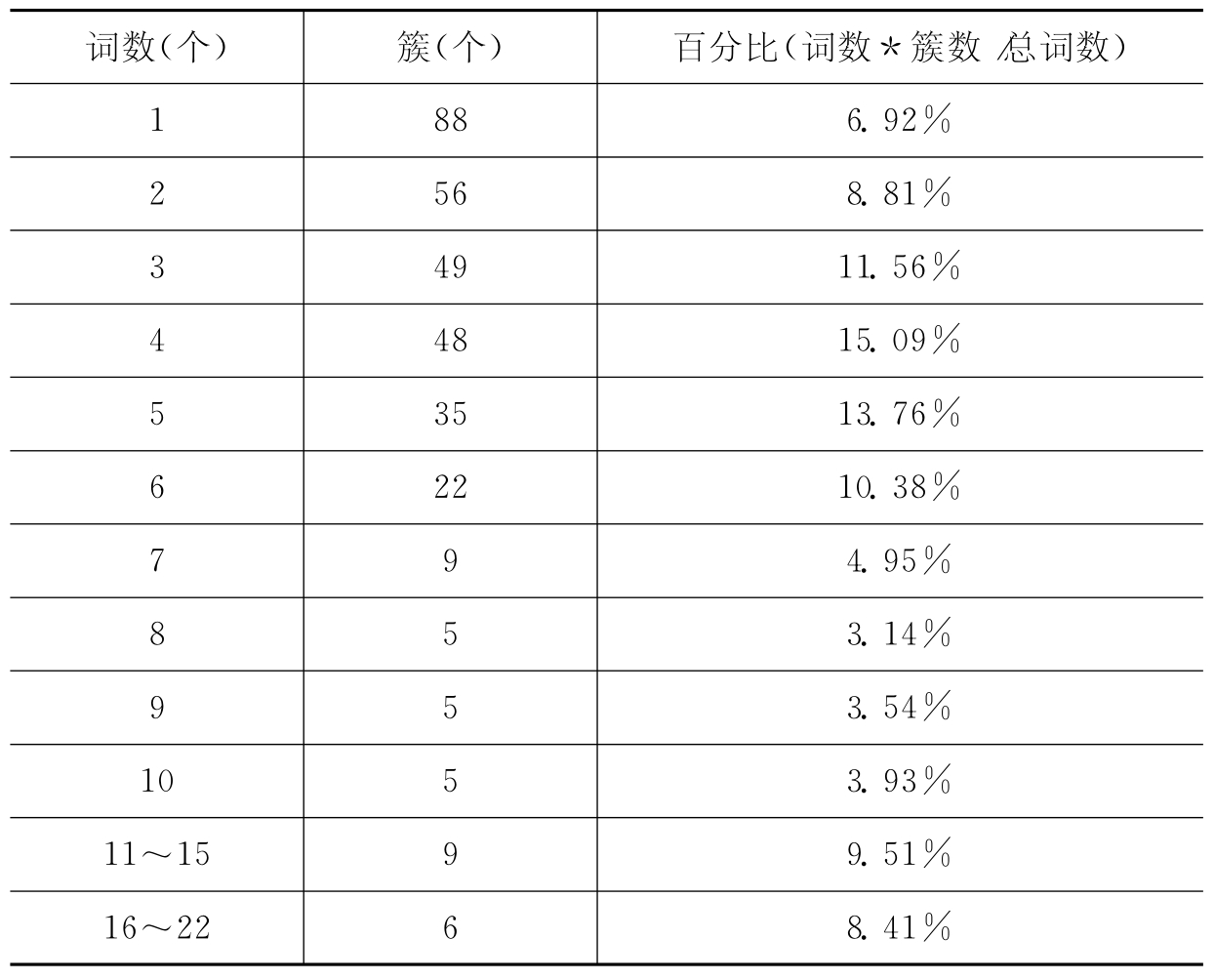
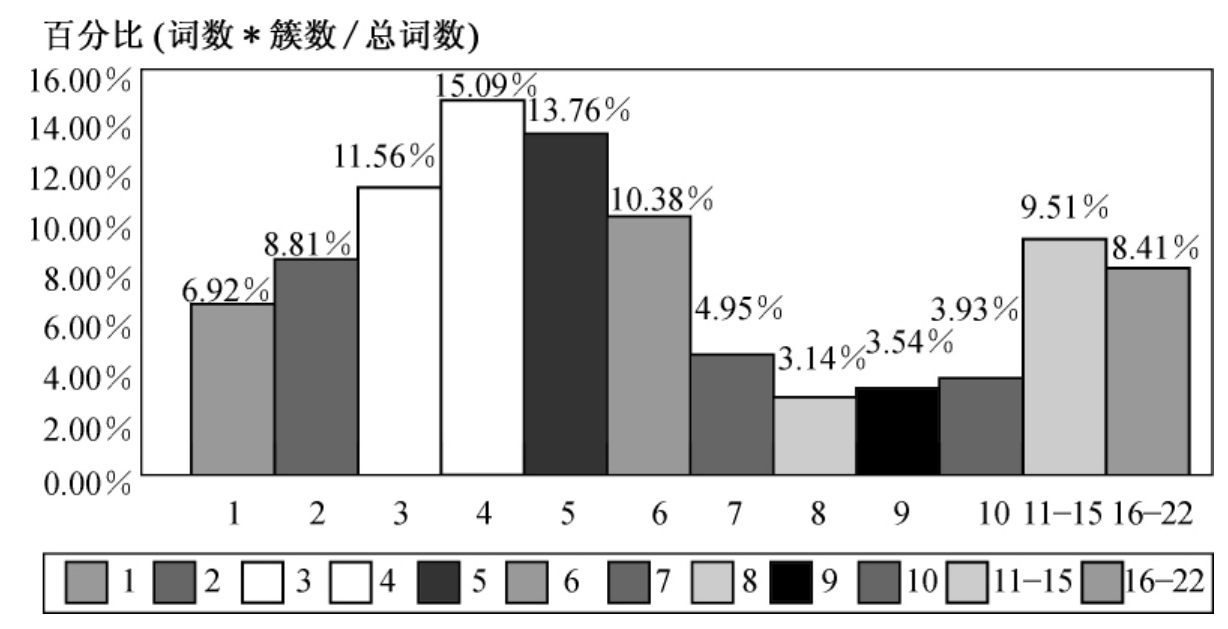
图6-7 聚类结果分析图
从图6-7聚类结果分析图看出,词汇分布较为均匀,体积较大的簇很少,最大的簇含22个词汇。从簇内词汇之间的相似性来看,生成的簇的紧凑度较高,基本上把不同概念范畴的词汇区分开来,所以聚类结果基本符合自动构建叙词表的要求。经考察同时发现,大簇内部词汇一般为词频较高的通用词,如“管理”、“规定”、“文件”等词,聚类算法对它们之间的相似性欠区分能力,考虑到通用词在词表内很少构成词族和等级关系,可以考虑事先把这部分词按词频过滤掉,专门对难以区分的专业词汇进行聚类,避免通用词在聚类过程中造成干扰,聚类速度也会有所提高。
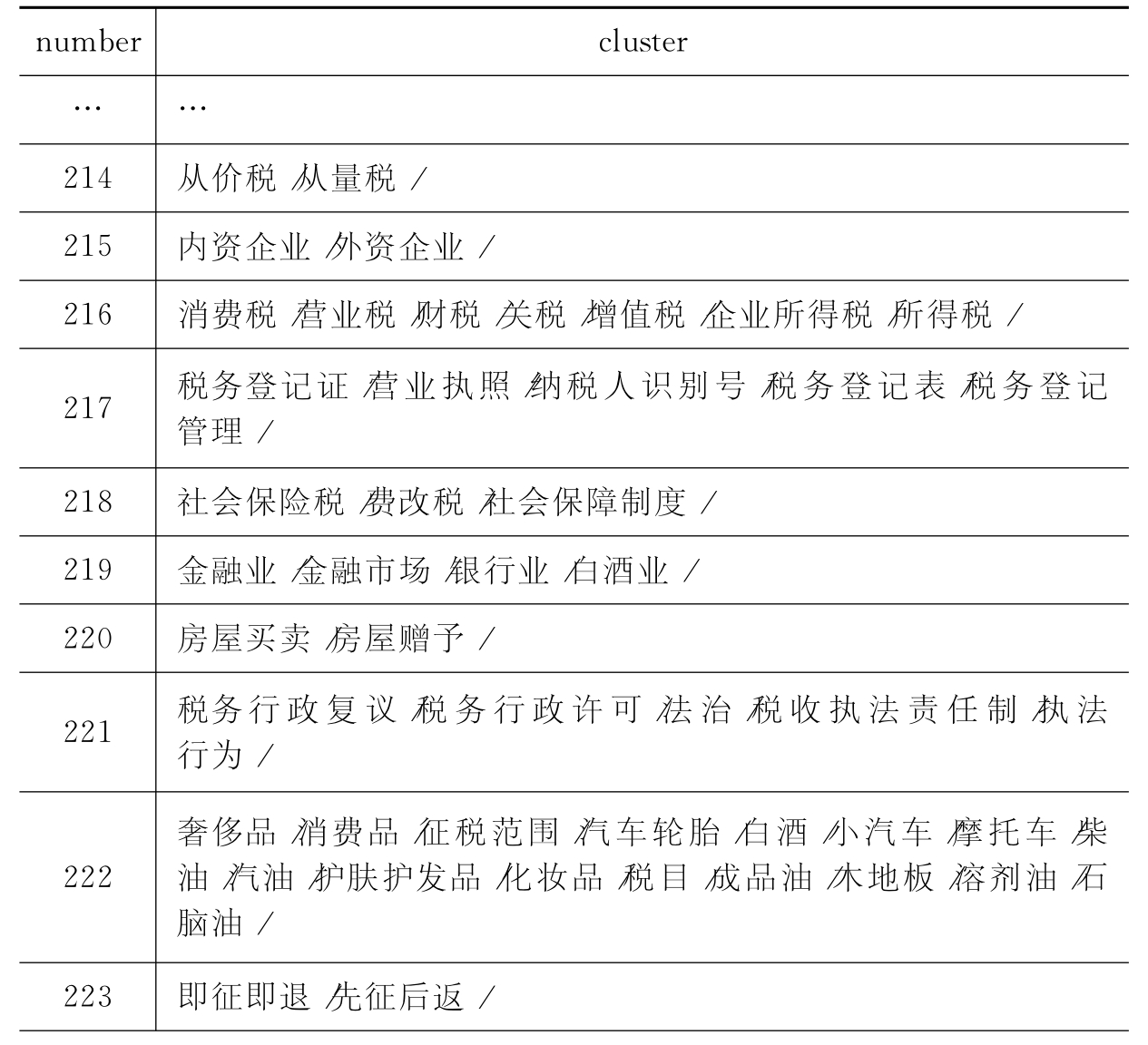
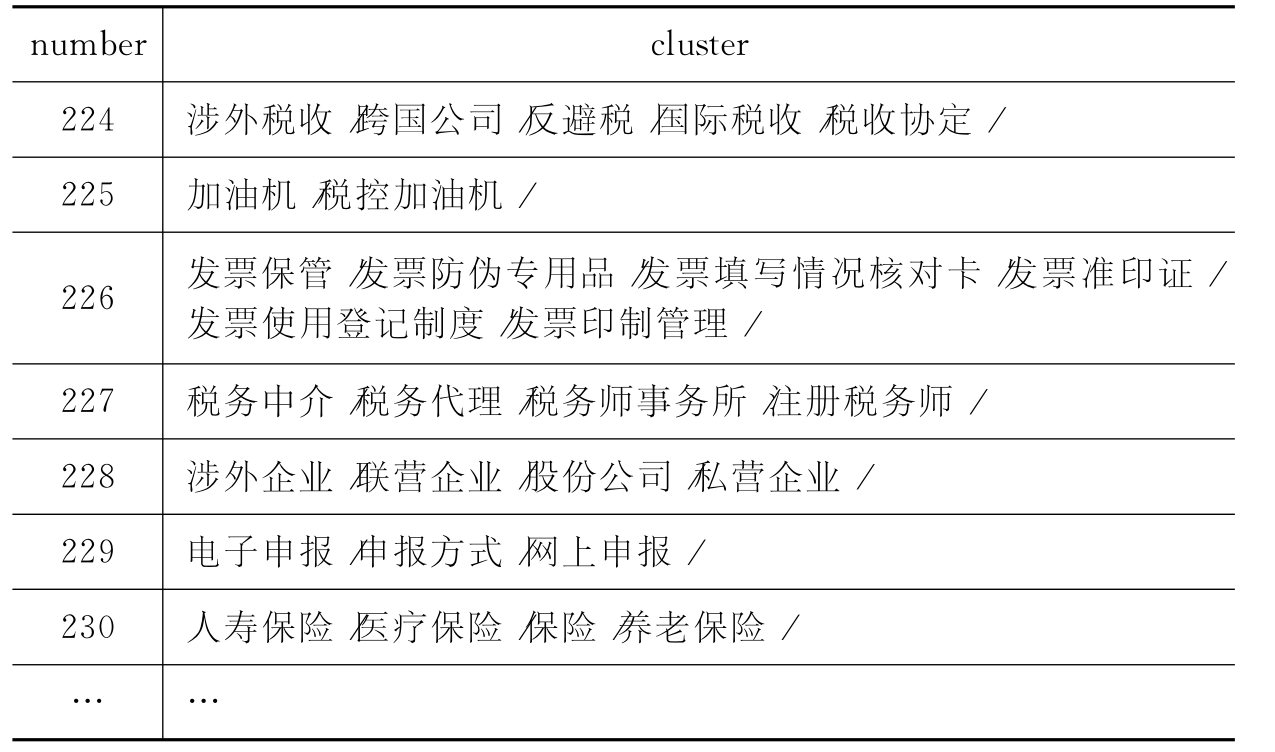
聚类结果样例如表6-11所示,其中number字段中的数字是聚类过程中生成簇的次序,cluster字段为聚类结束后得到的簇。
表6-11 聚类结果示例
(续表)
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











