



5.3.1 关联算法介绍
信息检索领域中有多个同现分析算法用来计算关联度,分为对称关联度算法和不对称关联度算法两种。不对称关联度算法认为两词语之间的关联程度是不相等的,即从词汇A到B的关联强度与词汇B到A之间的关联强度不同。美国学者Chen是该理论的提出者[7]。对称关联度算法则认为两词汇之间的关联度是一个统一的数值,没有方向区别。对称关联度计算方法更符合人们的习惯,也便于在已计算得出的关联度基础上对词汇关系进一步分析和研究,挖掘出更深入的信息和知识。
词语相互之间的关联度是一个0到1之间的数值,通过计算语词在文本训练库中的同现情况得出,其大小代表了词语之间的关联程度。当两词之间的关联度为0时,表示它们毫不相关,也就是从来不同时出现在同一篇文献中;当关联度接近1时,表示在文本库中,这两个词密切相关。
信息检索领域常用基于统计学习的关联算法有互信息、DICE测度、Jaccard系数、开方统计、极大似然比等方法[8],以下简要介绍其中的几种算法。
(1)互信息
互信息是一种来自信息论的方法。假设事件A和B分别出现的概率为P(A),P(B),同时出现的概率为P(A,B),那么A、B之间的互信息MI(A,B)表示为:
![]()
若MI(A,B)>0,则表示A,B是高度相关的;
若MI(A,B)=0,则表示A,B是独立的;
若MI(A,B)<0,则表示A,B是相互排斥的。
(2)DICE测度
该公式来自集合论中,设S1,S2为两个集合,则两个集合的DICE测度公式如下:
![]()
利用DICE测度可以很好地计算词与词之间的相关度。它排除了零概率事件的发生。
(3)Jaccard系数
Jaccard系数的计算公式如下:
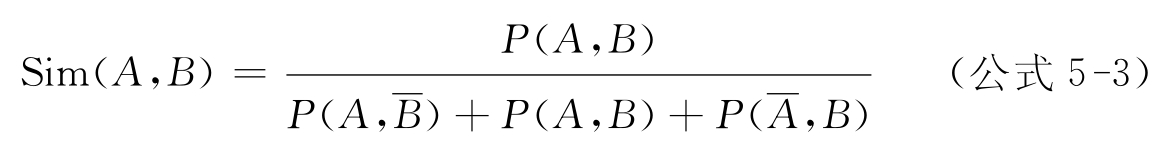
(4)极大似然比
极大似然比的计算公式如下[9]:
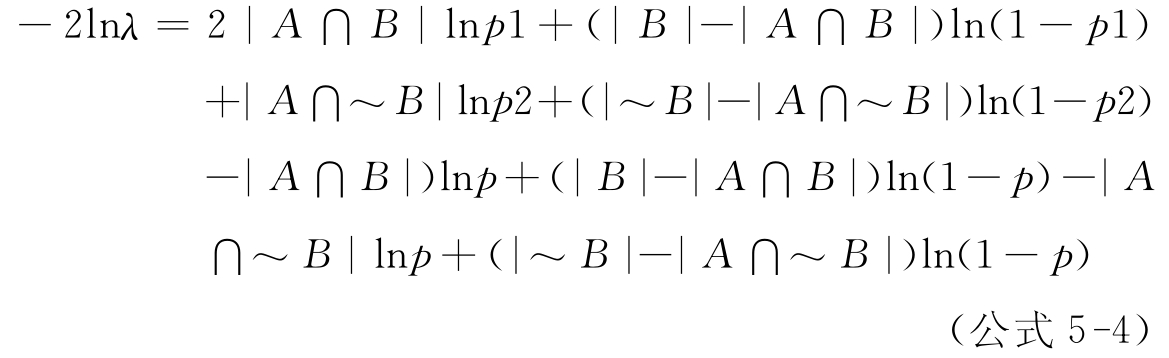
其中,A表示有词A出现的文献数,B表示有词B出现的文献数,~B表示词B不出现的文献数,A∩B表示词A和词B共现的文献数,A∩~B表示词A出现,词B不出现的文献数,P=(|A∩B|+|A∩~B|)/(|B|+|~B|),假设P(A|B)=P(A|~B)=P(A),则:P1=|A∩B|/|B|和P2=|A∩~B|/|~B|分别是P(A|B)和P(A|~B)的最大值。
各种关联算法虽然定义方式不同,但本质上都是计算合集|A∩B|对原来集合A和B的影响程度。有学者经研究得出结论:如果对上述相似性函数进行适当的归一化处理,则会发现它们提供几乎相同的检索性能[10]。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。









